Pandas
Series
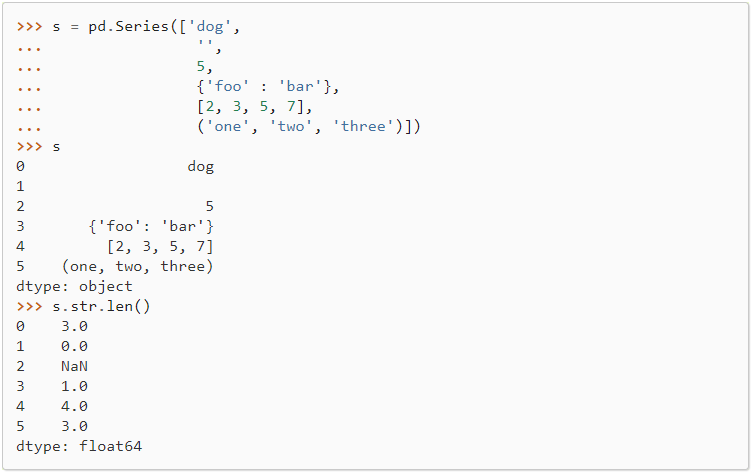
str.len
计算 Series/Index 的每个元素的长度。
元素可以是一个序列(如字符串、元组或列表)或一个集合(如字典)。
DataFrame
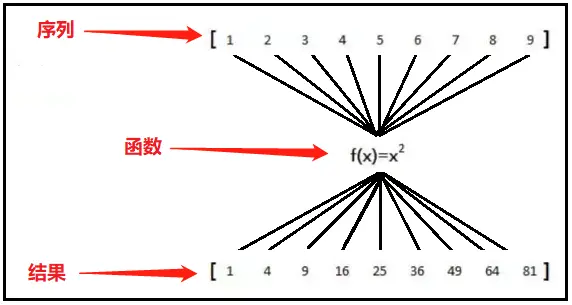
map
将序列中的每一个元素,输入函数,最后将映射后的每个值返回合并,得到一个迭代器。
sample
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
- n:要抽取的行数
- frac:抽取行的比例。 例如frac=0.8,就是抽取其中80%。
- replace:是否为有放回抽样,True:有放回抽样, False:未放回抽样
- weights:字符索引或概率数组, axis=0:为行字符索引或概率数组, axis=1:为列字符索引或概率数组
- random_state:int: 随机数发生器种子 或numpy.random.RandomState
- axis: 选择抽取数据的行还是列, axis=0:抽取行, axis=1:抽取列
hist
DataFrame.hist(data, column=None, by=None, grid=True, xlabelsize=None, xrot=None, ylabelsize=None, yrot=None, ax=None, sharex=False, sharey=False, figsize=None, layout=None, bins=10, **kwds)
- data: 一个DataFrame。
- column: 指字符串或序列。
- by:这是一个可选参数。如果通过, 它将用于形成独立组的直方图。
- grid:它也是可选参数。用于显示轴线网格线。默认值True。
- xlabelsize:指整数值。默认值无。用于指定x轴标签大小的更改。
- xrot:表示浮点值。用于旋转x轴标签。默认值无。
- ylabelsize:表示整数值。用于指定y轴标签大小的更改。
- yrot:表示浮点值。用于旋转y轴标签。默认值无。
- ax:Matplotlib轴对象。 它定义了我们需要绘制直方图的轴。默认值无。
- sharex:布尔值。如果ax为None, 则默认值为True。否则为False。对于子图, 如果value为True, 它将共享x轴并将某些x轴标签设置为不可见。其默认值为True。
mean、median、std
求均值,中位数, 标准差
unique
一共有多少出现过的元素, 多次出现的元素算一次
iloc
DataFrame.iloc选择DataFrame数据结构的行和列。
DataFrame.iloc[0:2,0:3];
表示该数据结构0:2,0-2行;
表示该数据结构0:3,0-3列;
groupby
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
使用一个 mapper 或者 a Series of columns 对 DataFrame 分组。
分组操作包括分割对象、应用函数和合并结果的一些组合。这可以用于对大量数据进行分组,并对这些分组进行计算操作。

agg
DataFrame.agg(func=None, axis=0, *args, **kwargs)
对指定的维度使用一个或多个操作进行聚合。

shift
DataFrame.shift(periods=1, freq=None, axis=0, fill_value=NoDefault.no_default)
通过想要的周期的数字移动索引, 以一种可选的时间频率。
当 freq 没有传入时, 在不重新调整数据的情况下移动索引。 如果传入 freq(在这个例子中, index 必须是 date 或者 datatime,否则会抛出 NotImplementedError) , index 使用 periods 和 freq 增加。 只要在 index 中指定了 infer 或者设置了 freq 或者 inferred_freq 属性, freq 可以被推断。
CSV
to_string
1
2
3
4
5
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,直接部分以 … 代替。
to_csv
to_csv() 方法将 DataFrame 存储为 csv 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
head()
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
1
2
3
4
5
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())
tail()
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
1
2
3
4
5
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())
info()
info() 方法返回表格的一些基本信息:
1
2
3
4
5
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
输出结果为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 458 entries, 0 to 457 # 行数,458 行,第一行编号为 0
Data columns (total 9 columns): # 列数,9列
# Column Non-Null Count Dtype # 各列的数据类型
--- ------ -------------- -----
0 Name 457 non-null object
1 Team 457 non-null object
2 Number 457 non-null float64
3 Position 457 non-null object
4 Age 457 non-null float64
5 Height 457 non-null object
6 Weight 457 non-null float64
7 College 373 non-null object # non-null,意思为非空的数据
8 Salary 446 non-null float64
dtypes: float64(4), object(5) # 类型
non-null 为非空数据,我们可以看到上面的信息中,总共 458 行,College 字段的空值最多。
cut
pd.cut( x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates=’raise’, )
- x : 一维数组
- bins :整数,标量序列或者间隔索引,是进行分组的依据,
apply 和 applymap
applymap用于DataFrame中的元素级别,就是对所有元素应用某个方法;apply用于Series或DataFrame的列。
h5py
一个 HDF5 文件是存储两类对象的容器,这两类对象分别为:
- dataset:类似数组的数据集合;
- group: 类似目录的容器,其中可以包含一个或多个 dataset 及其它的 group。
一个 HDF5 文件从一个命名为 “/” 的 group 开始,所有的 dataset 和其它 group 都包含在此 group 下,当操作 HDF5 文件时,如果没有显式指定 group 的 dataset 都是默认指 “/” 下的 dataset,另外类似相对文件路径的 group 名字都是相对于 “/” 的。
HDF5 文件的 dataset 和 group 都可以拥有描述性的元数据,称作 attribute。
用 h5py 操作 HDF5 文件,我们可以像使用目录一样使用 group,像使用 numpy 数组一样使用 dataset,像使用字典一样使用属性,非常方便和易用。
Quick Start
Core concepts
HDF5文件是两种对象的容器: datasets(类似数组的数据集合) 和 groups (类似文件夹的容器,保存 datasets 和其他 group)。使用h5py时最基本的要记住的是:
Groups 的工作方式类似于字典,而 datasets 的工作方式类似于 NumPy 数组
假设你有一个 HDF5 文件 mytestfile.hdf5。 您需要做的第一件事是打开文件以便读取:
1
2
>>> import h5py
>>> f = h5py.File('mytestfile.hdf5', 'r')
File 对象是您的起点。这个文件中存储了什么? 记住 h5py.File 表现就像 Python 的字典, 因此我们可以检查 keys:
1
2
>>> list(f.keys())
['mydataset']
根据我们的观察,在文件中有一个数据集 mydataset。 让我们将数据集设为 Dataset 对象进行检查:
1
>>> dset = f['mydataset']
我们得到的对象不是一个数组, 而是一个 HDF5 dataset。 就像 Numpy 数组,dataset 也有 shape 和 data type:
1
2
3
4
>>> dset.shape
(100,)
>>> dset.dtype
dtype('int32')
它们还支持数组风格的切片。这就是从文件中的 dataset 读取和写入数据的方法:
1
2
3
4
5
6
7
>>> dset[...] = np.arange(100)
>>> dset[0]
0
>>> dset[10]
10
>>> dset[0:100:10]
array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
Groups and hierarchical organization
“HDF” 表示 “Hierarchical Data Format” 。 HDF5 文件中每个对象都有一个 name, 它们使用 / 操作符以 POSIX 风格的层级结构安排:
1
2
>>> dset.name
'/mydataset'
这个系统中的 “folders” 叫做 groups。 我们创建的 File 对象本身就是一个 group, 在这个 root group 中, name 是 /:
1
2
>>> f.name
'/'
通过 create_group 创建一个 subgroup。 但是我们需要首先以追加模式打开文件:
1
2
>>> f = h5py.File('mydataset.hdf5', 'a')
>>> grp = f.create_group("subgroup")
所有 Group 对象也像 File 一样有 create_* 方法:
1
2
3
>>> dset2 = grp.create_dataset("another_dataset", (50,), dtype='f')
>>> dset2.name
'/subgroup/another_dataset'
顺便说一下, 你不必手动创建所有的中间 group。你只需要指定完整路径即可:
1
2
3
>>> dset3 = f.create_dataset('subgroup2/dataset_three', (10,), dtype='i')
>>> dset3.name
'/subgroup2/dataset_three'
Group 支持大多数Python字典风格的接口。您可以使用元素检索语法在文件中检索目标:
1
>>> dataset_three = f['subgroup2/dataset_three']
对一个 group 进行迭代可获得其成员的 name
1
2
3
4
5
>>> for name in f:
... print(name)
mydataset
subgroup
subgroup2
成员测试也使用 names:
1
2
3
4
>>> "mydataset" in f
True
>>> "somethingelse" in f
False
你也可以使用完整路径的 name:
1
2
>>> "subgroup/another_dataset" in f
True
group 也有相似的方法, 比如 keys(), values(), items() 和 iter() 以及 get()。
因为对一个 group 迭代仅产生与它直接相连的成员, 对整个文件迭代使用 visit() 和 visititems() 方法:
1
2
3
4
5
6
7
8
>>> def printname(name):
... print(name)
>>> f.visit(printname)
mydataset
subgroup
subgroup/another_dataset
subgroup2
subgroup2/dataset_three
Attributes
HDF5最好的特性之一是可以将元数据存储 和 描述它的数据 存储在一起。所有的 groups 和 datasets 支持 attribute。
Atrributes 通过 attrs 代理对象获取, 它又实现了字典接口:
1
2
3
4
5
>>> dset.attrs['temperature'] = 99.5
>>> dset.attrs['temperature']
99.5
>>> 'temperature' in dset.attrs
True
Groups
Datasets
Attributes
tricks
打开/创建文件
1
class File(name, mode=None, driver=None, libver=None, userblock_size=None, **kwds)
打开或创建一个 HDF5 文件,name 为文件名字符串,mode 为打开文件的模式,driver 可以指定一种驱动方式,如需进行并行 HDF5 操作,可设置为 ‘mpio’,libver 可以指定使用的兼容版本,默认为 ‘earliest’,也可以指定为 ‘latest’,userblock_size 以字节为单位指定一个在文件开头称作 user block 的数据块,一般不需要设置。返回所打开文件的句柄。
创建 group
1
create_group(self, name, track_order=False)
创建一个新的 group。以类似目录路径的形式指明所创建 group 的名字 name,如果 track_order 为 True,则会跟踪在当前 group 下的 group 和 dataset 创建的先后顺序。该方法可以在打开的文件句柄(相当于 “/” group)或者一个存在的 group 对象上调用,此时 name 的相对路径就是相对于此 group 的。
创建 dataset
1
create_dataset(self, name, shape=None, dtype=None, data=None, **kwds)
创建一个新的 dataset。以类似文件路径的形式指明所创建 dataset 的名字 name,shape 以一个 tuple 或 list 的形式指明创建 dataset 的 shape,用 “()” 指明标量数据的 shape,dtype 指明所创建 dataset 的数据类型,可以为 numpy dtype 或者一个表明数据类型的字符串,data 指明存储到所创建的 dataset 中的数据。如果 data 为 None,则会创建一个空的 dataset,此时 shape 和 dtype 必须设置;如果 data 不为 None,则 shape 和 dtype 可以不设置而使用 data 的 shape 和 dtype,但是如果设置的话,必须与 data 的 shape 和 dtype 兼容。
使用技巧
读取csv文件
pandas.read_csv(filepath_or_buffer, sep=’, ‘, delimiter=None, header=’infer’, encoding=None, …)
-
filepath_or_buffer : 路径 URL 可以是http, ftp, s3, 和 file.
-
sep: 指定分割符,默认是’,’C引擎不能自动检测分隔符,但Python解析引擎可以
-
delimiter: 同sep
-
delimiter_whitespace: True or False 默认False, 用空格作为分隔符等价于spe=’\s+’如果该参数被调用,则delimite不会起作用
-
header: 指定第几行作为列名(忽略注解行),如果没有指定列名,默认header=0; 如果指定了列名header=None
-
encoding: 编码方式
iloc
iloc按位置进行提取, 按索引提取区域行数值
df_inner.iloc[0:5]
loc
loc函数按标签值进行提取, 按索引提取单行的数值
df_inner.loc[3]
ix
ix可以同时按标签和位置进行提取。
df_inner.ix[:’2013-01-03’,:4] #2013-01-03号之前,前四列数据
pd.merge
1
2
3
4
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
参数:
- left: 拼接的左侧DataFrame对象
- right: 拼接的右侧DataFrame对象
- on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。