Python 语法
list
*list[:2]和list[:2]区别
- list[:2]:返回的还是一个list
- *list[:2]:返回的是内容
例子:
1
2
3
ll = ['lalala', 'test', 'hello world']
print(ll[0:2])
print(*ll[0:2])
输出:
[‘lalala’, ‘test’]
lalala test
拓展来讲,一个迭代器使用*返回的一串迭代结果。
如:
1
2
3
ll = ['lalala', 'test', 'hello world']
print(ll[0])
print(*ll[0])
输出:
lalala
l a l a l a
dict
get
通过dict提供的get方法,如果key不存在,可以返回None,或者自己指定的value:
1
2
3
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1
注意:返回None的时候Python的交互式命令行不显示结果。
pop
要删除一个key,用pop(key)方法,对应的value也会从dict中删除:
1
2
3
4
>>> d.pop('Bob')
75
>>> d
{'Michael': 95, 'Tracy': 85}
str
join
join():连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
startswith
str.startswith(str, beg=0,end=len(string));
- str – 检测的字符串。
- strbeg – 可选参数用于设置字符串检测的起始位置。
- strend – 可选参数用于设置字符串检测的结束位置。
Python startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
islower
str.islower()
检测是否是小写
split
str.split(str=””, num=string.count(str)).
通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
- str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num – 分割次数。默认为 -1, 即分隔所有。
strip
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
map
map(func, *iterables):第一个是函数,第二个是可迭代序列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
>>> help(map)
Help on class map in module builtins:
class map(object)
| map(func, *iterables) --> map object
|
| Make an iterator that computes the function using arguments from
| each of the iterables. Stops when the shortest iterable is exhausted.
|
| Methods defined here:
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __iter__(self, /)
| Implement iter(self).
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __next__(self, /)
| Implement next(self).
|
| __reduce__(...)
| Return state information for pickling.
map的用法:将序列的每一个元素作为函数的参数进行运算
1
2
3
4
5
>>> list(map(lambda x : x / 2 ,(1,2,3,4,5)))
[0.5, 1.0, 1.5, 2.0, 2.5]
>>> list(map(lambda x : x / 2,range(1,6)))
[0.5, 1.0, 1.5, 2.0, 2.5]
map返回的是一个迭代器
map也可以用作类型转换, 如
1
",".join(map(str, (128, 128)))
返回字符串128, 128
lambda
1
g = lambda x:x+1
lambda作为一个表达式,定义了一个匿名函数,上例的代码x为入口参数,x+1为函数体
1
2
3
4
5
6
7
8
9
>>> foo = [2, 18, 9, 22, 17, 24, 8, 12, 27]
>>>
>>> print filter(lambda x: x % 3 == 0, foo)
[18, 9, 24, 12, 27]
>>>
>>> print map(lambda x: x * 2 + 10, foo)
[14, 46, 28, 54, 44, 58, 26, 34, 64]
>>>
>>> print reduce(lambda x, y: x + y, foo)
copy

首先直接上结论: —–我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。 —–而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。
对于简单的 object,用 shallow copy 和 deep copy 没区别
复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。
assert(断言)
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。 断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况,例如我们的代码只能在 Linux 系统下运行,可以先判断当前系统是否符合条件。

random
random.sample(population, k)
返回从总体序列或集合中选择的唯一元素的 k 长度列表。 用于无重复的随机抽样。
这里的唯一元素是指每个元素只会返回一次,是不重复的。
1
2
3
style = [1, 2 ,3, 4]
t = random.sample(style, 2)
print(t)
输出:
[2, 1]
super
如果在子类中也定义了_init_()函数,那么该如何调用基类的_init_()函数:
方法一、明确指定 :
1
2
3
4
class C(P):
def __init__(self):
P.__init__(self)
print 'calling Cs construtor'
方法二、使用super()方法 :
1
2
3
4
5
6
class C(P):
def __init__(self):
super(C,self).__init__()
print 'calling Cs construtor'
c=C()
Python中的super()方法设计目的是用来解决多重继承时父类的查找问题,所以在单重继承中用不用 super 都没关系;但是,使用 super() 是一个好的习惯。一般我们在子类中需要调用父类的方法时才会这么用。
super()的好处就是可以避免直接使用父类的名字.主要用于多重继承,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class A:
def m(self):
print('A')
class B:
def m(self):
print('B')
class C(A):
def m(self):
print('C')
super().m()
C().m()
这样做的好处就是:如果你要改变子类继承的父类(由A改为B),你只需要修改一行代码(class C(A): -> class C(B))即可,而不需要在class C的大量代码中去查找、修改基类名,另外一方面代码的可移植性和重用性也更高。
另外:避免使用 super(self.__class__, self),一般情况下是没问题的,就是怕极端的情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Foo(object):
def x(self):
print 'Foo'
class Foo2(Foo):
def x(self):
print 'Foo2'
super(self.__class__, self).x() # wrong
class Foo3(Foo2):
def x(self):
print 'Foo3'
super(Foo3, self).x()
f = Foo3()
f.x()
在 Foo2 中的 super(self.__class__, self) 导致了死循环,super 永远去找 Foo3 的 MRO 中的下一个类,super 的第一个参数应该总是当前的类,Python 没有规定代码必须怎样去写,但是养成一些好的习惯是很重要,会避免很多你不了解的问题发生。
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx
call
在类中定义__call__可以像调用函数一样使用实例调用__call__这个方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class test:
def __init__(self):
super().__init__()
print("I'm in init")
@staticmethod
def apply():
t = test()
print("I'm in apply")
return t
def __call__(self):
print("I'm in call")
tt = test.apply()
tt()
输出:
I’m in init
I’m in apply
I’m in call
callable
callable() 函数用于检查一个对象是否是可调用的。如果返回 True,object 仍然可能调用失败;但如果返回 False,调用对象 object 绝对不会成功。
callable(object)
装饰器
@staticmethod@classmethod
一般来说,调用某个类的方法,需要先生成一个实例,再通过实例调用方法。Java中有静态变量,静态方法,可以使用类直接进行调用。Python提供了两个修饰符@staticmethod @classmethod也可以达到类似效果。
| @staticmethod 声明方法为静态方法,直接通过 类 | 实例.静态方法()调用。经过@staticmethod修饰的方法,不需要self参数,其使用方法和直接调用函数一样。 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#直接定义一个test()函数
def test():
print "i am a normal method!"
#定义一个类,其中包括一个类方法,采用@staticmethod修饰
class T:
@staticmethod
def static_test():#没有self参数
print "i am a static method!"
if __name__ == "__main__":
test()
T.static_test()
T().static_test()
output:
i am a normal method!
i am a static method!
i am a static method!
| @classmethod声明方法为类方法,直接通过 类 | 实例.类方法()调用。经过@classmethod修饰的方法,不需要self参数,但是需要一个标识类本身的cls参数。 |
1
2
3
4
5
6
7
8
9
10
11
class T:
@classmethod
def class_test(cls):#必须有cls参数
print "i am a class method"
if __name__ == "__main__":
T.class_test()
T().class_test()
output:
i am a class method
i am a class method
nonlocal
闭包
1
2
3
4
def line_6(k, b):
def create_y(x):
print(k * x + b)
return create_y
return 后面返回的是引用,调用的话还是在外部调用。
闭包:一个函数中嵌套着另一个函数的定义,真正使用的也是内部函数,往往内部函数又要用到外部变量。这样子内部函数和要使用的外部函数的变量共同组成的空间就构成了一个闭包。也就是说,闭包是简单的功能+数据,跟实例对象类似但是更简单,数据、内存等也更少。
nonlocal
字如其名, 声明非局部变量
使用这个关键字所要注意的点:
- 外部必须有这个量
- 在内部函数声明nonlocal变量之前不能出现同名变量
- 内部修改这个变量,在外部有这个变量的第一层函数中生效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
x = 300
def test1():
x = 200
def test2():
nonlocal x #如果没有这句话,下一句中默认在本函数中先找,找到了但是却发现在后面,之前没有定义,则报错
print("---1---x = %d" % x)
x = 100
print("---2---x = %d" % x)
return test2
t1 = test1()
t1()
#结果:
#---1---x = 200
#---2---x = 100
## zip() 函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用 list() 转换来输出列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 返回一个对象
>>> zipped
<zip object at 0x103abc288>
>>> list(zipped) # list() 转换为列表
[(1, 4), (2, 5), (3, 6)]
>>> list(zip(a,c)) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> a1, a2 = zip(*zip(a,b)) # 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式
>>> list(a1)
[1, 2, 3]
>>> list(a2)
[4, 5, 6]
>>>
Python中collections模块
这个模块实现了特定目标的容器,以提供Python标准内建容器 dict、list、set、tuple 的替代选择。
- Counter:字典的子类,提供了可哈希对象的计数功能
- defaultdict:字典的子类,提供了一个工厂函数,为字典查询提供了默认值
- OrderedDict:字典的子类,保留了他们被添加的顺序
- namedtuple:创建命名元组子类的工厂函数
- deque:类似列表容器,实现了在两端快速添加(append)和弹出(pop)
- ChainMap:类似字典的容器类,将多个映射集合到一个视图里面
defaultdict
defaultdict的一个典型用法是使用其中一种内置类型(如str、int、list或dict)作为默认工厂,因为这些内置类型在没有参数调用时返回空类型。
使用int作为default_factory的例子:
1
2
3
4
5
6
7
8
9
10
11
>>> from collections import defaultdict
>>> fruit = defaultdict(int)
>>> fruit['apple'] += 2
>>> fruit
defaultdict(<class 'int'>, {'apple': 2})
>>> fruit
defaultdict(<class 'int'>, {'apple': 2})
>>> fruit['banana'] # 没有对象时,返回0
0
>>> fruit
defaultdict(<class 'int'>, {'apple': 2, 'banana': 0})
使用list作为default_factory的例子:
1
2
3
4
5
6
7
8
>>> s = [('NC', 'Raleigh'), ('VA', 'Richmond'), ('WA', 'Seattle'), ('NC', 'Asheville')]
>>> d = collections.defaultdict(list)
>>> for k,v in s:
... d[k].append(v)
...
>>> d
defaultdict(<class 'list'>, {'NC': ['Raleigh', 'Asheville'], 'VA': ['Richmond'], 'WA': ['Seattle']})
OrderedDict
python中的字典是无序的,因为它是按照hash来存储的。
python中有个模块collections(英文,收集、集合),里面自带了一个子类OrderedDict,实现了对字典对象中元素的排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import collections
print "Regular dictionary"
d={}
d['a']='A'
d['b']='B'
d['c']='C'
for k,v in d.items():
print k,v
print "\nOrder dictionary"
d1 = collections.OrderedDict()
d1['a'] = 'A'
d1['b'] = 'B'
d1['c'] = 'C'
d1['1'] = '1'
d1['2'] = '2'
for k,v in d1.items():
print k,v
输出:
Regular dictionary
a A
c C
b B
Order dictionary
a A
b B
c C
1 1
2 2
可以看到,同样是保存了ABC等几个元素,但是使用OrderedDict会根据放入元素的先后顺序进行排序。所以输出的值是排好序的。
介绍python函数传参
-
Python不允许程序员选择采用传值还是传引用。Python参数传递采用的肯定是“传对象引用”的方式。实际上,这种方式相当于传值和传引用的一种综合。如果函数收到的是一个可变对象(比如字典或者列表)的引用,就能修改对象的原始值——相当于通过“传引用”来传递对象。如果函数收到的是一个不可变对象(比如数字、字符或者元组)的引用,就不能直接修改原始对象——相当于通过“传值”来传递对象。
-
当人们复制列表或字典时,就复制了对象列表的引用同,如果改变引用的值,则修改了原始的参数。
-
为了简化内存管理,Python通过引用计数 机制实现自动垃圾回收功能,Python中的每个对象都有一个引用计数,用来计数该对象在不同场所分别被引用了多少次。每当引用一次Python对象,相应的引用计数就增1,每当消毁一次Python对象,则相应的引用就减1,只有当引用计数为零时,才真正从内存中删除Python对象。
上面也就是说,当我们传的参数是int、字符串(string)、float、(数值型number)、元组(tuple) 时,无论函数中对其做什么操作,都不会改变函数外这个参数的值;
当传的是字典型(dictionary)、列表型(list)时,如果是重新对其进行赋值,则不会改变函数外参数的值,如果是对其进行操作,则会改变。
即变量中存储的是引用 , 是指向真正内容的内存地址 , 对变量重新赋值 , 相当于修改了变量副本存储的内存地址 , 而这时的变量已经和函数体外的变量不是同一个了, 在函数体之外的变量 , 依旧存储的是原本的内存地址 , 其值自然没有发生改变 。
简单来说 :
- 函数体传入的参数 , 为函数体外变量引用的副本 .
- 在函数体中改变变量指向的堆中的值 , 对函数外变量有效.
- 在函数体中改变变量的引用 , 对函数外变量无效
参数带星号的说明
F(*arg1)
有时候会不确定有多少个参数,它以一个*加上形参名的方式来表示这个函数 的实参个数不定,可能为0个也可能为n个。注意一点是,不管有多少个,在函数内部都被存放在以形参名为标识符的tuple中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
>>> def a(*x):
if len(x)==0:
print 'None'
else:
print x
>>> a(1)
(1,) #存放在元组中
>>> a()
None
>>> a(1,2,3)
(1, 2, 3)
>>> a(m=1,y=2,z=3)
Traceback (most recent call last):
File "<pyshell#16>", line 1, in -toplevel-
a(m=1,y=2,z=3)
TypeError: a() got an unexpected keyword argument 'm
F(**arg1)
形参名前加俩个*表示,参数在函数内部将被存放在以形式名为标识符的dictionary中,这时调用函数的方法则需要采用arg1=value1,arg2=value2这样的形式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
>>> def a(**x):
if len(x)==0:
print 'None'
else:
print x
>>> a()
None
>>> a(x=1,y=2)
{'y': 2, 'x': 1} #存放在字典中
>>> a(1,2) #这种调用则报错
Traceback (most recent call last):
File "<pyshell#25>", line 1, in -toplevel-
a(1,2)
TypeError: a() takes exactly 0 arguments (2 given)
Python3 函数参数列表单独一个星号 * 的作用
《Effective Python》第 21 条:用只能以关键字形式指定的参数来确保代码明晰
Python 3 中可以定义一种只能以关键字形式来指定的参数,从而确保调用该函数的代码读起来会比较明确。这些参数必须以关键字的形式提供,而不能按位置提供。
例如下面这个 safe_division 函数,带有两个只能以关键字形式来指定的参数,参数列表里的 * 星号,标志着位置参数的就此终结,之后的那些参数,都只能以关键字形式来指定。
1
2
3
4
5
6
7
8
9
10
11
12
13
def safe_division(number, divisor, *,ignore_overflow = False, ignore_zero_division = False):
try:
return number/divisor
except OverflowError:
if ignore_overflow:
return 0
else:
raise
except ZeroDivisionError:
if ignore_zero_division:
return float('inf')
else:
raise
优先级:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def test0(arg, *args):
print(arg)
print(args)
def test1(*args, arg):
print(arg)
print(args)
def test2(*args, arg=None):
print(arg)
print(args)
test0(1, 2, 3, 4)
test1(1, 2, 3, 4)
test2(1, 2, 3, 4)
打印结果分别为:
1
(2, 3, 4)
TypeError: test1() missing 1 required keyword-only argument: ‘arg’
None
(1, 2, 3, 4)
因此当arg在*args前时,依次填入参数
当*args在arg前,且arg没有默认值,且送入函数的值没有keywords, 报错。
当*args在arg前,arg有默认参数,且送入函数的值没有keywords,参数全为*args, arg为默认值。
glob
glob 文件名模式匹配,不用遍历整个目录判断每个文件是不是符合。
1、通配符
星号(*)匹配零个或多个字符
1
2
3
import glob
for name in glob.glob('dir/*'):
print (name)
1
2
3
4
5
6
dir/file.txt
dir/file1.txt
dir/file2.txt
dir/filea.txt
dir/fileb.txt
dir/subdir
列出子目录中的文件,必须在模式中包括子目录名:
1
2
3
4
5
6
7
8
9
10
import glob
#用子目录查询文件
print ('Named explicitly:')
for name in glob.glob('dir/subdir/*'):
print ('\t', name)
#用通配符* 代替子目录名
print ('Named with wildcard:')
for name in glob.glob('dir/*/*'):
print ('\t', name)
1
2
3
4
Named explicitly:
dir/subdir/subfile.txt
Named with wildcard:
dir/subdir/subfile.txt
2、单个字符通配符
用问号(?)匹配任何单个的字符。
1
2
3
4
import glob
for name in glob.glob('dir/file?.txt'):
print (name)
1
2
3
4
dir/file1.txt
dir/file2.txt
dir/filea.txt
dir/fileb.txt
3、字符范围
当需要匹配一个特定的字符,可以使用一个范围
1
2
3
import glob
for name in glob.glob('dir/*[0-9].*'):
print (name)
1
2
3
dir/file1.txt
dir/file2.txt
setattr()、getattr()、hasattr()
在动态检查对象是否包含某些属性(包括方法〉相关的函数有如下几个:
- hasattr(object,name):检查 object 对象是否包含名为 name 的属性或方法。
- getattr(object,name,default=None):获取 object 对象中名为 name 的属性的属性值(属性和函数都叫做属性)。
- setattr(object,name,value):将 object 对象的 name 属性设为 value。
python字符串前加r、f、u、l 的区别
字符串前加 “f”
f-strings 是指以 f 或 F 开头的字符串,其中以 {} 包含的表达式会进行值替换。(目前支持python3.6版本)
下面看下 f-strings 的使用方法
基本使用(作用:替换值)
1
2
3
4
5
6
7
>>>name = 'hoxis'
>>> age = 18
>>> f"hi, {name}, are you {age}"
#结果如下
'hi, hoxis, are you 18'
>>> F"hi, {name}, are you {age}"
'hi, hoxis, are you 18'
字符串前加 “r”
在字符串前加r可防止字符串转义
字符串前加 “u”
u/U:表示unicode字符串
不是仅仅是针对中文, 可以针对任何的字符串,代表是对字符串进行unicode编码。
一般英文字符在使用各种编码下, 基本都可以正常解析, 所以一般不带u;但是中文, 必须表明所需编码, 否则一旦编码转换就会出现乱码。
建议所有编码方式采用utf8
字符串前加 “l”
表示宽字符,unicode字符( unicode字符集是两个字节组成的。L告示编译器使用两个字节的 unicode 字符集) 如 L”我的字符串” 表示将ANSI字符串转换成unicode的字符串,就是每个字符占用两个字节。
1
2
3
4
5
6
不加时占用字节
strlen("asd") = 3;
加之后占用字节
strlen(L"asd") = 6;
time、timeit、 datatime
datatime
base64编码
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。可查看RFC2045~RFC2049,上面有MIME的详细规范。 Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读。
Base64由于以上优点被广泛应用于计算机的各个领域,然而由于输出内容中包括两个以上“符号类”字符(+, /, =),不同的应用场景又分别研制了Base64的各种“变种”。为统一和规范化Base64的输出,Base62x被视为无符号化的改进版本。
将url编码成base64
1
2
3
4
5
6
7
# 想将字符串转编码成base64,要先将字符串转换成二进制数据
url = "https://www.cnblogs.com/songzhixue/"
bytes_url = url.encode("utf-8")
str_url = base64.b64encode(bytes_url) # 被编码的参数必须是二进制数据
print(str_url)
b'aHR0cHM6Ly93d3cuY25ibG9ncy5jb20vc29uZ3poaXh1ZS8='
解码base64
1
2
3
4
5
6
7
# 将base64解码成字符串
import base64
url = "aHR0cHM6Ly93d3cuY25ibG9ncy5jb20vc29uZ3poaXh1ZS8="
str_url = base64.b64decode(url).decode("utf-8")
print(str_url)
'https://www.cnblogs.com/songzhixue/'
socketio
创建一个Socket.IO server
socketio.Server()
Socket.IO协议是基于事件的。 当一个客户端想要和服务器通信时,它会发出一个事件。每个事件都有一个名字和一系列参数。
服务器使用 socketio.Server.event() 或者 socketio.Server.on() 装饰器注册事件句柄。
@sio.on(‘telemetry’)
Connect事件是执行用户身份验证, 以及应用程序中的用户实体与分配给客户机的 sid 之间的必要映射。
environ参数是一个标准 WSGI 格式的字典,包含请求信息,包括 HTTP 头。 在检查请求之后,连接事件处理句柄可以返回 False 以拒绝与客户端的连接。
@sio.on(‘connect’)
1
2
3
4
@sio.on('connect')
def connect(sid, environ):
print("connect ", sid)
send_control(0, 0)
服务器可以在任何时候将事件发送到其连接的客户机
sio.emit
1
sio.emit('my event', {'data': 'foobar'})
有时,服务器可能只想将事件发送到特定的客户端。 这可以通过在 emit 调用中添加一个 room 参数来实现:
1
sio.emit('my event', {'data': 'foobar'}, room=user_sid)
Socket.IO server 是 socketio.Server 的一个实例。 通过使用 socketio.WSGIApp 类包装这个实例,可以将其转换为标准的 WSGI 应用程序:
1
2
3
4
5
6
7
import socketio
# create a Socket.IO server
sio = socketio.Server()
# wrap with a WSGI application
app = socketio.WSGIApp(sio)
对于基于异步的服务器, socketio.AsyncServer类提供了相同的功能, 但是是以协同程序友好的格式。如果需要,socketio.ASGIApp 类可以将服务器转换为标准的 ASGI 应用程序:
1
2
3
4
5
# create a Socket.IO server
sio = socketio.AsyncServer()
# wrap with ASGI application
app = socketio.ASGIApp(sio)
这两个包装器还可以充当中间件,将不打算发送到 Socket.IO 服务器的任何流量转发到另一个应用程序。 这使得 Socket.IO 服务器可以轻松地集成到现有的 WSGI 或 ASGI 应用程序中:
1
2
from wsgi import app # a Flask, Django, etc. application
app = socketio.WSGIApp(sio, app)
什么是 WSGI
Web服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI)是为Python语言定义的Web服务器和Web应用程序或框架之间的一种简单而通用的接口。自从WSGI被开发出来以后,许多其它语言中也出现了类似接口。
Python web开发中,服务端程序可分为2个部分:
- 1、服务器程序(用来接收、整理客户端发送的请求)
- 2、应用程序(处理服务器程序传递过来的请求)
在开发应用程序的时候,我们会把常用的功能封装起来,成为各种框架,比如Flask,Django,Tornado(使用某框架进行web开发,相当于开发服务端的应用程序,处理后台逻辑)但是,服务器程序和应用程序互相配合才能给用户提供服务,而不同应用程序(不同框架)会有不同的函数、功能。 此时,我们就需要一个标准,让服务器程序和应用程序都支持这个标准,那么,二者就能很好的配合了
WSGI 是 python web 开发的标准,类似于协议。它是服务器程序和应用程序的一个约定,规定了各自使用的接口和功能,以便二和互相配合
WSGI应用程序的部分规定
- 应用程序是一个可调用的对象
可调用的对象有三种:
1)、一个函数
2)、一个类,必须实现call()方法
3)、一个类的实例 \ - 这个对象接收两个参数
这两个参数是environ, start_response. 以可调用对象为一个类为例:
1
2
3
class application:
def __call__(self, environ, start_response):
pass
- 可调用对象需要返回一个可迭代的值。以可调用对象为一个类为例:
1
2
3
class application:
def __call__(self, environ, start_response):
return [xxx]
WSGI服务器程序的部分规定
服务器程序需要调用应用程序
1
2
3
4
5
6
7
8
9
def run(application): #服务器程序调用应用程序
environ = {} #设定参数
def start_response(xxx): #设定参数
pass
result = application(environ, start_response) #调用应用程序的__call__函数(这里应用程序是一个类)
def write(data):
pass
def data in result: #迭代访问
write(data)
Middleware
middleware是介于服务器程序和应用程序中间的部分,middleware对服务器程序和应用程序是透明的。
- 对于服务器程序来说,middleware就是应用程序,middleware需要伪装成应用程序,传递给服务器程序
- 对于应用程序来说,middleware就是服务器程序,middleware需要伪装成服务器程序,接受并调用应用程序
eventlet
Eventlet 主要是用于网络并发的库,专注于代码运行逻辑。
eventlet.listen(addr, family=2, backlog=50)
创建套接字,可以用于 serve() 或一个定制的 accept() 循环。设置套接字的 SO_REUSEADDR 可以减少打扰。
参数: \
- addr:要监听的地址,比如对于 TCP 协议的套接字,这是一个(host, port) 元组。
- family:套接字族。
- backlog:排队连接的最大个数,至少是1,上限由系统决定。
返回:
监听中的“绿色”套接字对象。
eventlet.wsgi.server(sock, site, log=None, environ=None, max_size=None, …)
创建一个WSGI服务器
- sock: 服务器套接字,必须绑定一个端口监听
- site:+WSGI应用函数
- log:应写入日志的日志记录器实例或类似文件的对象。 如果提供了 Logger 实例,消息将被发送到 INFO 日志级别。 如果未指定,则使用 sys.stderr。
- environ:每个请求的 environ 字典中的附加参数。
- max_size: 此服务器在任何时候打开的客户端连接的最大数量。默认值为1024。
sorted
sorted() 函数对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
sorted(iterable, key=None, reverse=False)
argparse
创建解析器对象
class argparse.ArgumentParser(prog=None, usage=None, description=None, epilog=None, parents=[], formatter_class=argparse.HelpFormatter, prefix_chars=’-‘, fromfile_prefix_chars=None, argument_default=None, conflict_handler=’error’, add_help=True, allow_abbrev=True)
添加参数
ArgumentParser.add_argument(name or flags…[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
- name or flags - 一个命名或者一个选项字符串的列表,例如 foo 或 -f, –foo
- choices - 可用的参数的容器, 参数值只能从几个选项里面选择, 如choices=[‘alexnet’, ‘vgg’]。
- required - 此命令行选项是否可省略 (仅选项可用)。
- metavar - 在使用方法消息中使用的参数值示例。
- dest - 设置参数在代码中的变量名。
- action - add_argument中默认action=’store‘,直接保存从运行终端或程序中传入的变量。如果想修改为常量,需要修改action=’store_const’,然后指定const。
1
parser.add_argument('--foo', action='store_const', const=42)
store_true/false - 如果需要存储True或者False,只要指定action=’store_true/false’
1
2
parser.add_argument('--foo', action='store_true')
parser.add_argument('--foo', action='store_false')
需要注意的是,如果指定action为store_const或者store_true,则参数不可再进行赋值
append - 同一参数,需要多个值时候,需要指定action=’append’
1
2
3
4
parser.add_argument('--foo', action='append')
D:\desktop>python argparseLearn.py --foo 1 --foo 2
Namespace(foo=['1', '2'])
version - 需要指定action=’version’,打印version后会自动退出
1
2
3
4
parser.add_argument('--version',action='version',version='PROG 2.0')
D:\desktop>python argparseLearn.py --version
PROG 2.0
写入和读取 csv 文件
写入
1
2
3
4
5
6
7
with open ("test.csv", "w", newline='') as f : #newline参数控制行之间是否空行
f_csv = csv.writer(f)
f_csv.writerow(headers) # headers为表头属性名组成的数组
f_csv.writerows(csvlists) #csvlists为多维数组,每个元素都是对应属性的一行内容
读取
获取每一行
读取csv文件,用的是csv.reader()这个方法。返回结果是一个_csv.reader的对象,我们可以对这个对象进行遍历,输出每一行,某一行,或某一列。代码如下:
1
2
3
4
5
6
7
import csv
with open('data.csv', 'r') as f:
reader = csv.reader(f)
print(type(reader))
for row in reader:
print(row)
以列表的形式输出每一行,如下:
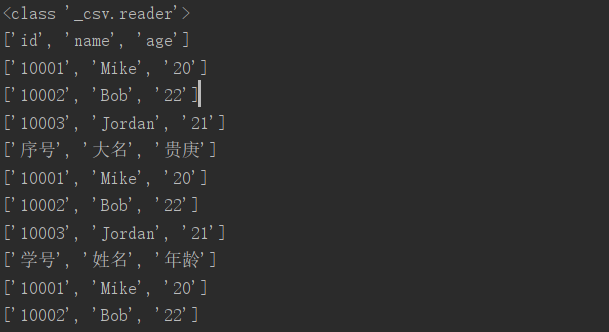
capitalize()
Python capitalize()将字符串的第一个字母变成大写,其他字母变小写。
capitalize()方法语法:
1
str.capitalize()
ABC (Abstract Base Class)
由于python 没有抽象类、接口的概念,所以要实现这种功能得abc.py 这个类库
抽象基类的作用
- 用于判定某个对象的类型,例如 instance 函数
- 强制子类必须实现某些方法,相当于确定ABC类的派生类的基本方法
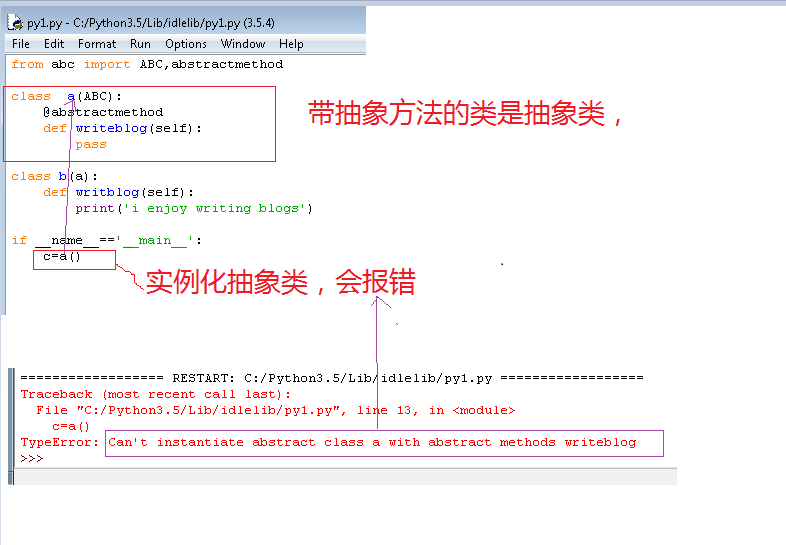
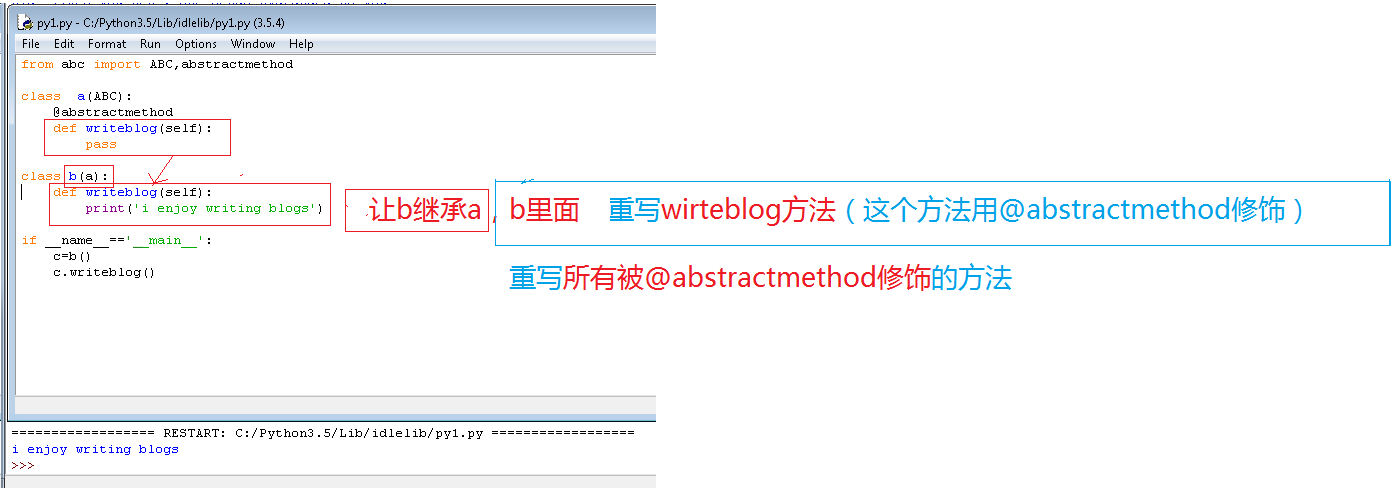
@abstractmethod特点
@abstractmethod:抽象方法,含abstractmethod方法的类不能实例化,继承了含abstractmethod方法的子类必须复写所有abstractmethod装饰的方法,未被装饰的可以不重写
举个反面栗子(实例化抽象类)
举个正常栗子
class abc.ABCMeta
functools
functools,用于高阶函数:指那些作用于函数或者返回其它函数的函数,通常只要是可以被当做函数调用的对象就是这个模块的目标。
在Python 2.7 中具备如下方法,
cmp_to_key,将一个比较函数转换关键字函数;(Python 3 不支持)
partial,把一个函数的某些参数设置默认值,返回一个新的函数,调用这个新函数会更简单。;
reduce,与python内置的reduce函数功能一样;
total_ordering,在类装饰器中按照缺失顺序,填充方法;
update_wrapper,更新一个包裹(wrapper)函数,使其看起来更像被包裹(wrapped)的函数;
wraps,可用作一个装饰器,简化调用update_wrapper的过程;
partial
把一个函数的某些参数设置默认值,返回一个新的函数,调用这个新函数会更简单。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
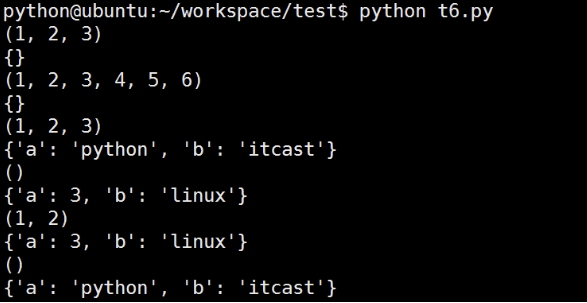
import functools
def showarg(*args, **kw):
print(args)
print(kw)
p1=functools.partial(showarg, 1,2,3)
p1()
p1(4,5,6)
p1(a='python', b='itcast')
p2=functools.partial(showarg, a=3,b='linux')
p2()
p2(1,2)
p2(a='python', b='itcast')
warp
定义一个最简单的装饰器
1
2
3
4
5
def user_login_data(f):
def wrapper(*args, **kwargs):
return f(*args, **kwargs)
return wrapper
用装饰器装饰以下两个函数
1
2
3
@user_login_data
def num1():
print("aaa")
1
2
3
@user_login_data
def num2():
print("bbbb")
1
2
3
if __name__ == '__main__':
print(num1.__name__)
print(num2.__name__)
以上代码的输出结果为:
1
2
3
wrapper
wrapper
由此函数使用装饰器时,函数的函数名即 __name__已经被装饰器改变.
一般定义装饰器的话可以不用考虑这点,但是如果多个函数被两个装饰器装饰时就报错,因为两个函数名一样,第二个函数再去装饰的话就报错.
解决方案就是引入 functools.wraps ,以上代码的解决如下:
1
2
3
4
5
6
def user_login_data(f):
@functools.wraps(f)
def wrapper(*args, **kwargs):
return f(*args, **kwargs)
return wrapper
增加@functools.wraps(f), 可以保持当前装饰器去装饰的函数的 __name__ 的值不变
以上输出结果就是:
1
2
3
num1
num2
vars
vars() 函数返回对象object的属性和属性值的字典对象。
itertools
groupby
1
itertools.groupby(iterable,key=None)
这个函数的有两个参数,第一个是可迭代对象,第二个是key。
groupby可以将相邻的重复元素挑出来放在一起:
1
2
3
4
5
6
7
8
9
for key,group in itertools.groupby('AAAABBBBCCAA'):
print(key,list(group)
输出如下:
A ['A', 'A', 'A', 'A']
B ['B', 'B', 'B', 'B']
C ['C', 'C']
A ['A', 'A']
ord
ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
pprint
print()和pprint()都是python的打印模块,功能基本一样,唯一的区别就是pprint()模块打印出来的数据结构更加完整,每行为一个数据结构,更加方便阅读打印输出结果。特别是对于特别长的数据打印,print()输出结果都在一行,不方便查看,而pprint()采用分行打印输出,所以对于数据结构比较复杂、数据长度较长的数据,适合采用pprint()打印方式。当然,一般情况多数采用print()。
all
python模块中的 __all__ ,用于模块导入时限制,如:from module import *
此时被导入模块若定义了 __all__ 属性,则只有 __all__ 内指定的属性、方法、类可被导入;若没定义,则导入模块内的所有公有属性,方法和类。
eval
eval() 官方文档里面给出来的功能解释是:将字符串string对象转化为有效的表达式参与求值运算返回计算结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
>>> s='8*8'
>>> eval(s)
64
>>> eval('2+5*4')
22
>>> x=1
>>> y=4
>>> eval('x+y')
5
>>> eval('98.9')
98.9
>>> eval('9.9\n')
9.9
>>> eval('9.9\n\t\r \t\r\n')
9.9
最有用的一个是 eval 可以将字符串转换成字典,列表,元组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
>>> l = "[2,3,4,5]"
>>> ll=eval(l)
>>> ll
[2, 3, 4, 5]
>>> type(ll)
<type 'list'>
>>> d="{'name':'python','age':20}"
>>> dd=eval(d)
>>> type(dd)
<type 'dict'>
>>> dd
{'age': 20, 'name': 'python'}
>>> t='(1,2,3)'
>>> tt=eval(t)
>>> type(tt)
<type 'tuple'>
>>> tt
(1, 2, 3)
eval() 函数功能强大,但也很危险,若程序中有以下语句:
1
2
s=input('please input:')
print (eval(s))
下面举几个被恶意用户使用的例子:
运行程序,如果用户恶意输入:
1
please input:__import__('os').system('ls')
则 eval() 之后,当前目录文件都会展现在用户前面。
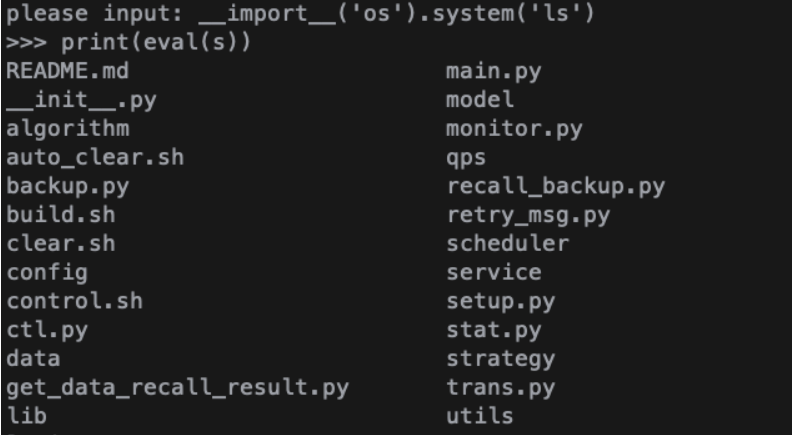
运行程序,如果用户恶意输入:
1
please input: open('xxx.py').read()
如果,当前目录中恰好有一个文件,名为 data.py,则恶意用户变读取到了文件中的内容。
运行程序,如果用户恶意输入:
1
please input:__import__('os').system('del test.txt /q')
如果,当前目录中恰好有一个文件,名为test.txt,则恶意用户删除了该文件。/q :指定静音状态。不提示您确认删除。
ast.literal_eval
ast.literal_eval 是python针对 eval 方法存在的安全漏洞而提出的一种安全处理方式。
简单点说 ast 模块就是帮助 Python应用来处理抽象的语法解析的。而该模块下的 literal_eval() 函数:则会判断需要计算的内容计算后是不是合法的Python类型,如果是则进行运算,否则就不进行运算。
比如下面查看系统文件的操作就会被拒绝,而只会执行合法的python类型,从而大大降低了系统的危险性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import ast
res = ast.literal_eval('1 + 1')
print(res)
# 2
res = ast.literal_eval('[1, 2, 3, 4]')
print(type(res))
# <class 'list'>
print(res)
# [1, 2, 3, 4]
res = ast.literal_eval("__import__('os').system('ls')")
# 报错如下:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/didi/.pyenv/versions/3.6.4/lib/python3.6/ast.py", line 85, in literal_eval
return _convert(node_or_string)
File "/Users/didi/.pyenv/versions/3.6.4/lib/python3.6/ast.py", line 84, in _convert
raise ValueError('malformed node or string: ' + repr(node))
ValueError: malformed node or string: <_ast.Call object at 0x10e63ca58>
所以出于安全考虑,对字符串进行类型转换的时候,最好使用 ast.literal_eval()
try except else
使用 else 包裹的代码,只有当 try 块没有捕获到任何异常时,才会得到执行;反之,如果 try 块捕获到异常,即便调用对应的 except 处理完异常,else 块中的代码也不会得到执行。
1
2
3
4
5
6
7
8
9
10
try:
result = 20 / int(input('请输入除数:'))
print(result)
except ValueError:
print('必须输入整数')
except ArithmeticError:
print('算术错误,除数不能为 0')
else:
print('没有出现异常')
print("继续执行")
1
2
3
4
请输入除数:4
5.0
没有出现异常
继续执行
os
os.listdir
os.listdir(path)
返回指定目录下的所有文件和目录名。
os.walk
os.walk(top, topdown=True, οnerrοr=None, followlinks=False)
- top 是你所要便利的目录的地址
- topdown 为真,则优先遍历top目录,否则优先遍历top的子目录(默认为开启)
- onerror 需要一个 callable 对象,当walk需要异常时,会调用
- followlinks 如果为真,则会遍历目录下的快捷方式(linux 下是 symbolic link)实际所指的目录(默认关闭)
os.walk 的返回值是一个生成器(generator),也就是说我们需要不断的遍历它,来获得所有的内容。
os.path常用方法:
os.path.join
os.path.join(path1[, path2[, …]])
将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.split
os.path.split(path)
将path分割成目录和文件名, 以二元组返回。
os.path.splitext()
os.path.splitext() 将文件名和扩展名分开
os.path.expanduser
os.path.expanduser(‘~’)
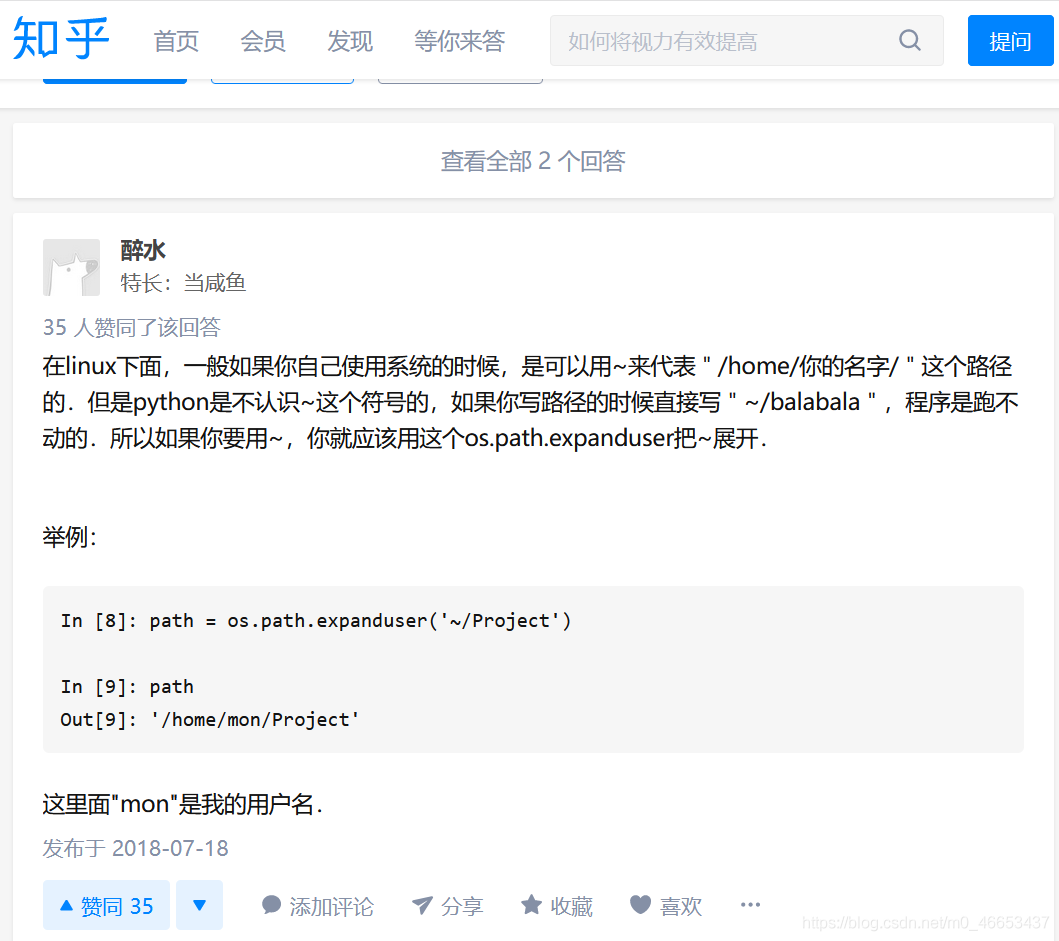
os.path.dirname
os.path.dirname(path)
去掉文件名,返回目录
1
2
3
print(os.path.dirname("E:/Read_File/read_yaml.py"))
#结果:
E:/Read_File
os.getcwd
os.getcwd()
得到当前工作目录,即当前Python脚本工作的目录路径。
获取当前路径
1
2
3
4
5
print("===获取当前文件目录===")
# 当前脚本工作的目录路径
print(os.getcwd())
# os.path.abspath()获得绝对路径
print(os.path.abspath(os.path.dirname(__file__)))
获取上层路径
1
2
3
4
5
6
print("=== 获取当前文件上层目录 ===")
print(os.path.abspath(os.path.dirname(os.path.dirname(__file__))))
print(os.path.abspath(os.path.dirname(os.getcwd())))
print(os.path.abspath(os.path.join(os.getcwd(), "..")))
print(os.path.dirname(os.getcwd()))
# os.path.join()连接目录名与文件或目录
os.environ
可用于设置可用GPU
os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘0, 2, 3, 4’
os.getenv
os.getenv(key, default = None)
- key:表示环境变量名称的字符串
- default (可选):表示 key 不存在时默认值的字符串。如果省略,则默认设置为“无”。
sys
sys.path
返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
比如就是我们在python源文件中import引入模块的时候就会在sys.path的目录中查找相应的模块,如果在这里面的目录中没有找到你要倒入的模块则会报错。
返回值是一个list则我们如果想导入一个自定义模块下面的的包或者是模块则可以使用list的append方法在PYTHONPATH环境变量中增加相应的路径。
1
2
3
4
5
6
import os
import sys
path=os.path.dirname(__file__) #os.path.dirname通俗的讲是返回上一级文件夹绝对路径的意思,多套一层就多返回一层
sys.path.append(path) #将路径添加到python的搜索路径中
#import 你想导入的文件
sys.modules
1
2
3
import sys
module = sys.modules[__name__]
getattr(sys.modules[__name__], func_name)的含义是找到当前文件下名称为func_name的对象(类对象或者函数对象)。
有时我们需要将一个文件的信息(类、函数及变量)保存到文件,我们不能直接保存函数对象,而是将其转化为fn.__name__,问题来了,当我们想通过读取文件的形式重新配置这些类、函数时,该如何把这些字符串转换为对应的函数对象呢?
1
2
3
4
5
6
7
8
9
10
# test.py
def fn():
print('hello world')
func_name = fn.__name__ ####这个可能是从url中获取的字符串
fn_obj = getattr(sys.modules[__name__], func_name)
# 根据函数名(func_name),获得函数对象
fn_obj()
# hello world
print(sys.modules[__name__])
# <module '__main__' from '**/test.py'>
numpy语法
numpy 模块的 size,shape, len的用法
size的用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import numpy as np
X=np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,12]])
number=X.size # 计算 X 中所有元素的个数
X_row=np.size(X,0) #计算 X 一行元素的个数
X_col=np.size(X,1) #计算 X 一列元素的个数
print("number:",number)
print("X_row:",X_row)
print("X_col:",X_col)
<<
number: 12
X_row: 3
X_col: 4
shape的用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import numpy as np
X=np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,12]])
X_dim=X.shape # 以元组形式,返回数组的维数
print("X_dim:",X_dim)
print(X.shape[0]) # 输出行的个数
print(X.shape[1]) #输出列的个数
<<
X_dim: (3, 4)
3
4
注意返回的是个元组
len的用法
1
2
3
4
5
6
7
8
9
10
import numpy as np
X=np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,12]])
length=len(X) #返回对象的长度 不是元素的个数
print("length of X:",length)
<<
length of X: 3
np.stack
numpy.stack(arrays, axis=0)
沿着新轴连接数组的序列。
np.vstack
vstack 表示将数组在第一维进行堆叠(即最外层的方括号),可将 arr1 和 arr2 第一维内的部分视为一个整体
np.hstack
hstack 表示将数组在第二维进行堆叠(即第二层方括号),可将 arr 第二层括号里面的东西视为一个整体
np.dstack
dstack 表示将数组在第三维进行堆叠(即第三层方括号),可将 arr 第三层括号里面的东西视为一个整体
np.ravel
numpy.ravel(a, order=’C’)
返回一个连续的、拉平的数组。
返回一个一维的数组, 包含输入的元素。 只有在必要的情况返回一个副本。
- a:输入的数组
- order {‘C’,’F’, ‘A’, ‘K’}, optional : a的元素按照这个索引顺序读取。’C’意味着按行索引元素, ‘F’意味着按列索引元素。
np.mgrid
np.mgrid[start:end:step]
1
mgrid[[1:3:3j, 4:5:2j]]
- 3j:3个点
- 步长为复数表示点数,左闭右闭
- 步长为实数表示间隔,左闭右开
例如1D结构(array),如下:
1
2
3
4
5
>>> import numpy as np
>>> x=np.mgrid[-5:5:5j]
>>> x
array([-5. , -2.5, 0. , 2.5, 5. ])
>>>
例如2D结构 (2D矩阵),如下:
1
2
3
4
5
6
7
8
9
10
11
>>> import numpy as np
>>> x,y=np.mgrid[-5:5:3j,-2:2:3j]
>>> x
array([[-5., -5., -5.],
[ 0., 0., 0.],
[ 5., 5., 5.]])
>>> y
array([[-2., 0., 2.],
[-2., 0., 2.],
[-2., 0., 2.]])
>>>
其中x沿着水平向右的方向扩展(即是:每列都相同),y沿着垂直的向下的方向扩展(即是:每行都相同)。
np.prod
np.prod()
用来计算所有元素的乘积,对于有多个维度的数组可以指定轴,如axis=1指定计算每一行的乘积。
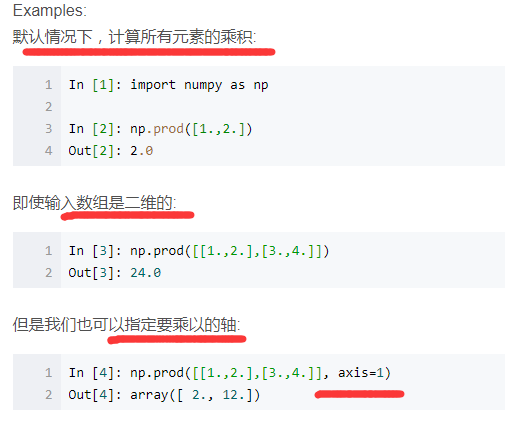
np.where
np.where(condition, x, y)
满足条件(condition),输出x,不满足输出y。
1
2
3
4
5
>>> aa = np.arange(10)
>>> np.where(aa,1,-1)
array([-1, 1, 1, 1, 1, 1, 1, 1, 1, 1]) # 0为False,所以第一个输出-1
>>> np.where(aa > 5,1,-1)
array([-1, -1, -1, -1, -1, -1, 1, 1, 1, 1])
np.where(condition)
只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的坐标 (等价于numpy.nonzero)。这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
1
2
3
4
5
6
7
8
>>> a = np.array([2,4,6,8,10])
>>> np.where(a > 5) # 返回索引
(array([2, 3, 4]),)
>>> a[np.where(a > 5)] # 等价于 a[a>5]
array([ 6, 8, 10])
>>> np.where([[0, 1], [1, 0]])
(array([0, 1]), array([1, 0]))
np.all()
np.all()
返回的是一个布尔类型的值
例子:
1
2
3
np.all([[True,False],[True,True]])
False
默认为对数组里的每个元素进行与运算
1
2
3
np.all([[True,False],[True,True]], axis=0)
array([ True, False], dtype=bool)
当给定axis的值时,则是按照给定方向进行与运算
np.random.normal()
numpy.random.normal(loc=0.0, scale=1.0, size=None)
参数的意义为:
loc:float
概率分布的均值,对应着整个分布的中心center
scale:float
概率分布的标准差,对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高
size:int or tuple of ints
输出的shape,默认为None,只输出一个值
我们更经常会用到np.random.randn(size)所谓标准正太分布(μ=0, σ=1),对应于np.random.normal(loc=0, scale=1, size)
numpy.random.randint
numpy.random.randint(low, high=None, size=None, dtype=’l’)
- low: int 生成的数值最低要大于等于low。 (hign = None时,生成的数值要在[0, low)区间内)
- high: int (可选) 如果使用这个值,则生成的数值在[low, high)区间。
- size: int or tuple of ints(可选) 输出随机数的尺寸,比如size = (m * n* k)则输出同规模即m * n* k个随机数。默认是None的,仅仅返回满足要求的单一随机数。
- dtype: dtype(可选): 想要输出的格式。如int64、int等等
np.random.choice
numpy.random.choice(a, size=None, replace=True, p=None)
从a(只要是ndarray都可以,但必须是一维的)中随机抽取数字,并组成指定大小(size)的数组
size可以是list或者tuple
replace:True表示可以取相同数字,False表示不可以取相同数字
数组p:与数组a相对应,表示取数组a中每个元素的概率,默认为选取每个元素的概率相同。
np.maximum、 np.minimum
np.max 与 np.maximum
np.max(a, axis=None, out=None, keepdims=False)
- 求序列的最值
- 最少接收一个参数
- axis:默认为列向(也即 axis=0),axis = 1 时为行方向的最值;
np.maximum:(X, Y, out=None)
- X 与 Y 逐位比较取其大者;
- 最少接收两个参数
- 带有广播机制
np.minimum:(X, Y, out=None)
- 与maximum基本一致,只不过取小者
1
2
3
4
5
6
7
import numpy as np
>>> np.maximum([1,2,3,4,5],2)
array([2, 2, 3, 4, 5])
>>> np.minimum([2, 3, 4], [1, 5, 2])
array([1, 3, 2])
np.expand_dims
np.expand_dims:用于扩展数组的形状
原始数组:
1
2
3
4
5
6
7
import numpy as np
In [12]:
a = np.array([[[1,2,3],[4,5,6]]])
a.shape
Out[12]:
(1, 2, 3)
np.expand_dims(a, axis=0)表示在0位置添加数据,转换结果如下:
1
2
3
4
5
6
7
8
9
10
11
In [13]:
b = np.expand_dims(a, axis=0)
b
Out[13]:
array([[[[1, 2, 3],
[4, 5, 6]]]])
In [14]:
b.shape
Out[14]:
(1, 1, 2, 3)
np.expand_dims(a, axis=1)表示在1位置添加数据,转换结果如下:
1
2
3
4
5
6
7
8
9
10
11
In [15]:
c = np.expand_dims(a, axis=1)
c
Out[15]:
array([[[[1, 2, 3],
[4, 5, 6]]]])
In [16]:
c.shape
Out[16]:
(1, 1, 2, 3)
np.expand_dims(a, axis=2)表示在2位置添加数据,转换结果如下:
1
2
3
4
5
6
7
8
9
10
11
In [17]:
d = np.expand_dims(a, axis=2)
d
Out[17]:
array([[[[1, 2, 3]],
[[4, 5, 6]]]])
In [18]:
d.shape
Out[18]:
(1, 2, 1, 3)
np.expand_dims(a, axis=3)表示在3位置添加数据,转换结果如下:
1
2
3
4
5
6
7
8
In [19]:
e = np.expand_dims(a, axis=3)
e
In [20]:
e.shape
Out[20]:
(1, 2, 3, 1)
能在(1,2,3)中插入的位置总共为4个,再添加就会出现以下的警告,要不然也会在后面某一处提示AxisError。
1
2
3
4
In [21]:
f = np.expand_dims(a, axis=4)
D:\ProgramData\Anaconda3\envs\dlnd\lib\site-packages\ipykernel_launcher.py:1: DeprecationWarning: Both axis > a.ndim and axis < -a.ndim - 1 are deprecated and will raise an AxisError in the future.
"""Entry point for launching an IPython kernel.
axis = -1 也就是相当于在最后插入
1
2
3
a = np.array([[[1,2,3],[4,5,6]]])
b = np.expand_dims(a,axis=-1)
print(b.shape)
输出:\
(1, 2, 3, 1)
numpy.broadcast_to
numpy.broadcast_to(array, shape, subok)
将array广播成shape的形状
numpy.rollaxis
numpy.rollaxis(arr, axis, start)
- arr:数组
- axis:要向后滚动的轴,其它轴的相对位置不会改变
- start:默认为零,表示完整的滚动。会滚动到特定位置。
np.corrcoef
numpy.corrcoef(x, y=None, rowvar=True, bias=<no value>, ddof=<no value>)
返回Pearson乘积矩相关系数。
\[R_{ij} = \frac{C_{ij}}{\sqrt{C_{ii} * C_{jj}}}\]- x: 包含多个变量和观测值的1-D或2-D数组。 x的每一行代表一个向量, 每一列都是对所有这些变量的单一观察。
- y:另一组变量和观察。 y与x具有相同的形状。
- rowvar: 如果rowvar为True(默认值), 则每行代表一个向量, 并在列中显示。 否则, 转换关系: 每列代表一个变量, 而行包含观察。
返回:
- R:变量得相关系数矩阵
np.arange()
np.arange()函数分为一个参数,两个参数,三个参数三种情况
- 一个参数时,参数值为终点,起点取默认值0,步长取默认值1。
- 两个参数时,第一个参数为起点,第二个参数为终点,步长取默认值1。
- 三个参数时,第一个参数为起点,第二个参数为终点,第三个参数为步长。其中步长支持小数
np.cov
numpy.cov(m, y=None, rowvar=True)
- m:array_like 包含多个变量和观测值的1-D或2-D数组。 m的每一行代表一个变量,每一列都是对所有这些变量的单一观察。
- y:array_like,可选。 另外一组变量和观察。 y具有与m相同的形式。
- rowvar:布尔值,可选。 如果rowvar为True(默认值),则每行代表一个变量X,另一个行为变量Y。否则,转换关系:每列代表一个变量X,另一个列为变量Y。
np.loadtxt
numpy.loadtxt(fname, dtype=, comments=’#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0)
- fname要读取的文件、文件名、或生成器。
- dtype数据类型,默认float。
- comments注释。
- delimiter分隔符,默认是空格。
- skiprows跳过前几行读取,默认是0,必须是int整型。
- usecols:要读取哪些列,0是第一列。例如,usecols = (1,4,5)将提取第2,第5和第6列。默认读取所有列。
- unpack如果为True,将分列读取。
np.meshgrid
二维坐标系中,X轴可以取三个值1,2,3, Y轴可以取三个值7,8, 请问可以获得多少个点的坐标?
显而易见是6个:
(1,7)(2,7)(3,7) (1,8)(2,8)(3,8)
np.meshgrid()就是干这个的!
1
2
3
4
5
6
7
8
9
10
#coding:utf-8
import numpy as np
# 坐标向量
a = np.array([1,2,3])
# 坐标向量
b = np.array([7,8])
# 从坐标向量中返回坐标矩阵
# 返回list,有两个元素,第一个元素是X轴的取值,第二个元素是Y轴的取值
res = np.meshgrid(a,b)
#返回结果: [array([ [1,2,3] [1,2,3] ]), array([ [7,7,7] [8,8,8] ])]
同理还可以生成更高维度的坐标矩阵
np.random.multivariate_normal
def multivariate_normal(mean, cov, size=None, check_valid=None, tol=None)
其中mean和cov为必要的传参而size,check_valid以及tol为可选参数。
- mean:mean是多维分布的均值, 维度为1;
- cov:协方差矩阵(,注意:协方差矩阵必须是对称的且需为半正定矩阵;
- size:指定生成的正态分布矩阵的维度(例:若size=(1, 1, 2),则输出的矩阵的shape即形状为 1X1X2XN(N为mean的长度))。
- check_valid:这个参数用于决定当cov即协方差矩阵不是半正定矩阵时程序的处理方式,它一共有三个值:warn,raise以及ignore。当使用warn作为传入的参数时,如果cov不是半正定的程序会输出警告但仍旧会得到结果;当使用raise作为传入的参数时,如果cov不是半正定的程序会报错且不会计算出结果;当使用ignore时忽略这个问题即无论cov是否为半正定的都会计算出结果。
- tol:检查协方差矩阵奇异值时的公差,float类型。
np.random.multivariate_normal方法用于根据实际情况生成一个多元正态分布矩阵
np.unique()
对于一维数组或列表,unique()返回的是一个无元素重复的数组或列表。
1
2
3
4
5
>>> a=np.random.randint(0,5,8)
>>> a
array([2, 3, 3, 0, 1, 4, 2, 4])
>>> np.unique(a)
array([0, 1, 2, 3, 4])
c,s=np.unique(b,return_index=True)
return_index=True表示返回新列表元素在旧列表中的位置,并以列表形式储存在s中
1
2
3
4
5
>>> c,s=np.unique(b,return_index=True)
>>> c
array([0, 1, 2, 3, 4])
>>> s
array([3, 4, 0, 1, 5])
np.less
numpy.less(x1,x2 [,out]):检查x1是否小于x2
np.full
full(shape, fill_value, dtype=None, order=’C’)
np.full 构造一个数组,用指定值填充其元素
np.tile
np.tile(A, reps)
np.titl() 重复 A 元素 reps[0] 行, reps[1]列
完整打印矩阵
np.set_printoptions 设置打印选项,这些选项决定显示浮点数、数组和其他NumPy对象的方式。
numpy.set_printoptions(precision=None, threshold=None, edgeitems=None, linewidth=None, suppress=None, nanstr=None, infstr=None,
np.set_printoptions(threshold = 1e6) #设置打印数量的阈值,1e6 = 1000000.0此方法为设置一较大值
npy文件ndarray转list
np.load(‘./saved_models/pnet.npy’)[()]
在后面加上[()]
tqdm
关于tqdm对于range的封装
1
2
3
4
5
6
7
from tqdm import tqdm
import time
pbar = tqdm(range(3_000))
for i in pbar:
time.sleep(0.01)

set_description
1
2
3
4
5
6
7
8
from tqdm import tqdm
import time
pbar = tqdm(range(3_000))
for i in pbar:
time.sleep(0.01)
pbar.set_description(f"Now get {i}")

logging
和assert比,logging不会抛出错误,而且可以输出到文件:
1
2
3
4
5
6
7
import logging
logging.basicConfig(level=logging.INFO)
s = '0'
n = int(s)
logging.info('n = %d' % n)
print(10 / n)
输出:
1
2
3
4
5
6
$ python err.py
INFO:root:n = 0
Traceback (most recent call last):
File "err.py", line 8, in <module>
print(10 / n)
ZeroDivisionError: division by zero
logging允许你指定记录信息的级别,有debug,info,warning,error等几个级别,当我们指定level=INFO时,logging.debug就不起作用了。同理,指定level=WARNING后,debug和info就不起作用了。这样一来,你可以放心地输出不同级别的信息,也不用删除,最后统一控制输出哪个级别的信息。
logging的另一个好处是通过简单的配置,一条语句可以同时输出到不同的地方,比如console和文件。
cProfile
run(command, filename=None, sort=-1)
第一种情况:
1
2
3
import cProfile
import re
cProfile.run('re.compile("aaa")')
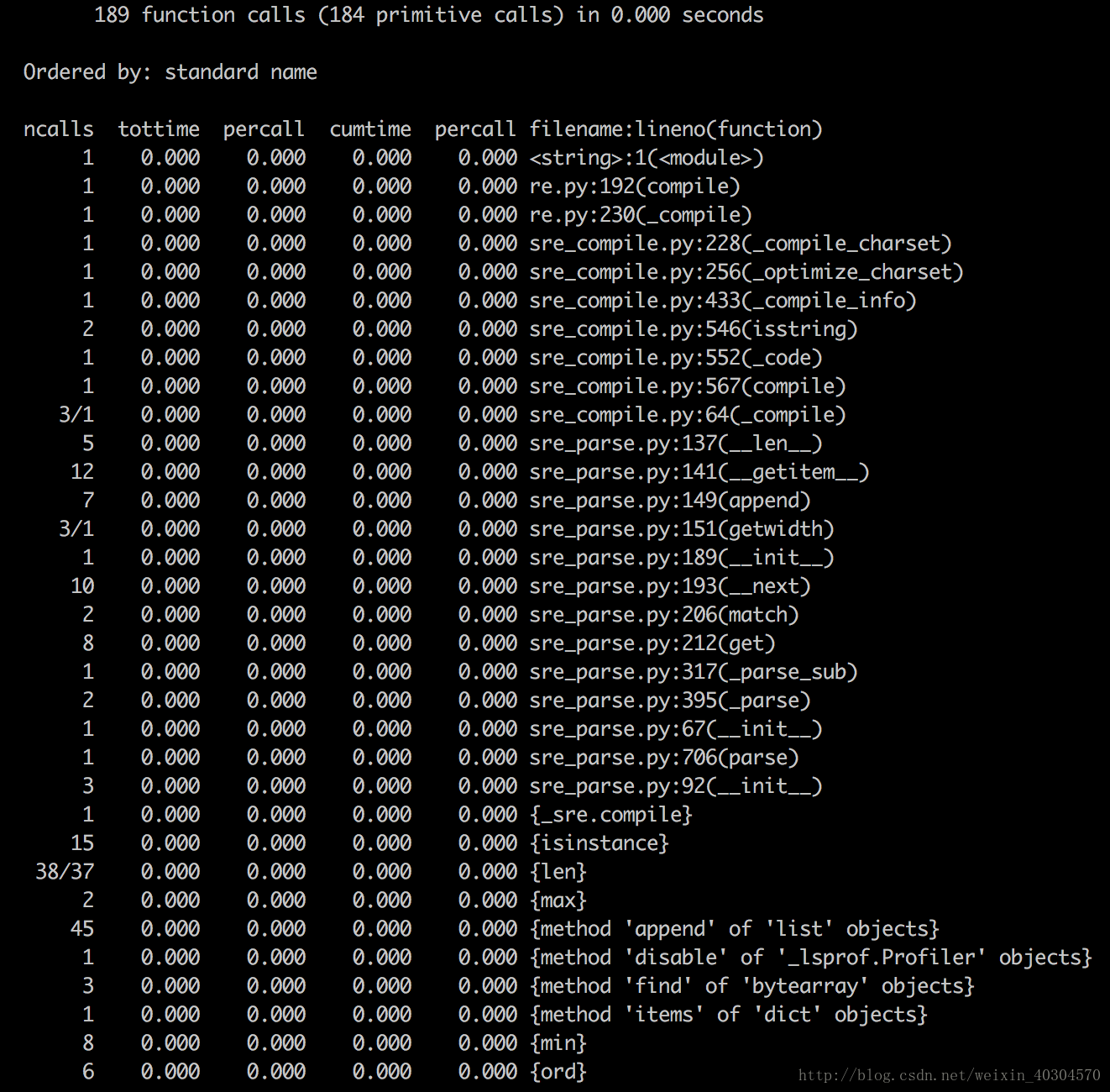
- 第一行:189个函数调用被监控,其中184个是原生调用(不涉及递归)
- ncalls:函数被调用的次数。如果这一列有两个值,就表示有递归调用,第二个值是原生调用次数,第一个值是总调用次数。
- tottime:函数内部消耗的总时间。(可以帮助优化)
- percall:是tottime除以ncalls,一个函数每次调用平均消耗时间。
- cumtime:之前所有子函数消费时间的累计和。
- filename:lineno(function):被分析函数所在文件名、行号、函数名。
第二种情况:
1
2
3
import cProfile
import re
cProfile.run('re.compile("aaa|bbb")', 'stats', 'cumtime')
如果你去运行该代码,你会发现没有结果输出,但是生成了一个stats文件,里面是二进制数据。想读取文件,请见后面内容。
runctx(command, globals, locals, filename=None)
run和runtx之间的区别:globals和locals是两个字典参数。
1
2
3
4
5
6
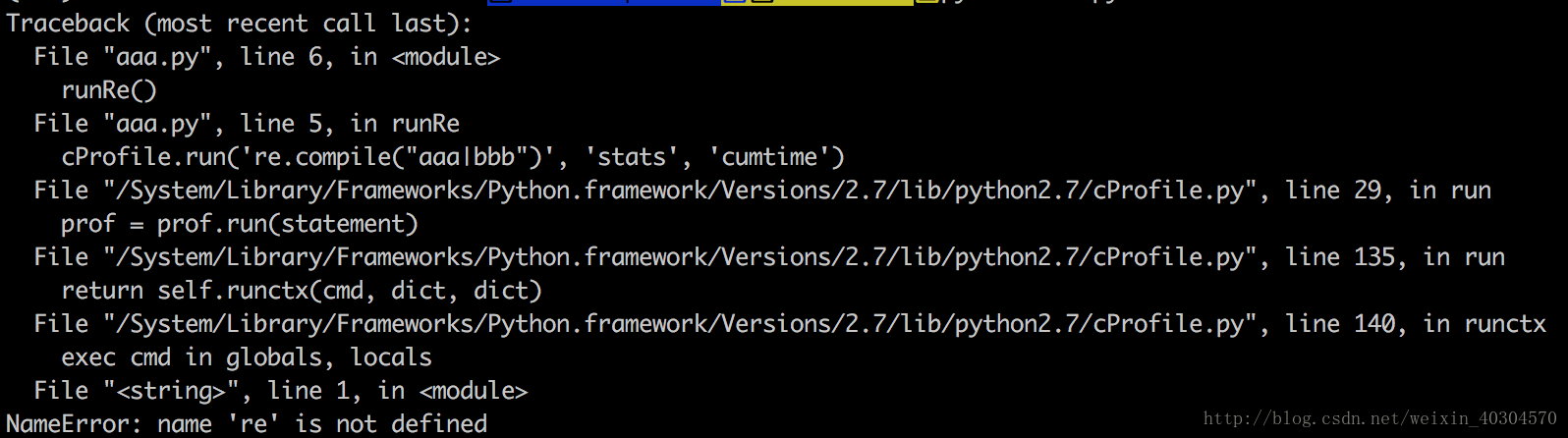
import cProfile
def runRe():
import re
cProfile.run('re.compile("aaa|bbb")')
runRe()
运行结果:
1
2
3
4
5
6
import cProfile
# 这样才对
def runRe():
import re
cProfile.runctx('re.compile("aaa|bbb")', None, locals())
runRe()
Profile(custom_timer=None, time_unit=0.0, subcalls=True, builtins=True)
- custom_timer:是一个自定义参数,可以通过与默认函数不同的方式测量时间。
- 如果custom_timer返回的是一个整数,time_unit是单位时间换成秒数。
返回方法:
- enable():开始收集性能分析数据。
- disable():停止收集性能分析数据。
- create_stats():停止收集数据,并为已经收集数据创建stats对象。
- print_stats(sort=-1):创建一个stats对象,打印结果。
- dump_stats(filename):把当前性能分析的内容写入一个文件。
- run(command):和之前的一样。
- runctx(command, golabls, locals):和以前一样。
- runcall(func, *args, **kwargs):收集被调用函数func的性能分析信息。
1
2
3
4
5
6
7
8
9
10
11
from cProfile import Profile
def runRe():
import re
re.compile("aaa|bbb")
prof = Profile()
prof.enable()
runRe()
prof.create_stats()
prof.print_stats()
Bugs
NameError:name ‘xrange’ is not defined
在Python 3中,range()与xrange()合并为range( )。 我的python版本为python3.5。
将xrange( )函数全部换为range( )。
python3出现module “importlib._bootstrap” has no attribute “SourceFileLoader”
有时候python或者pycharm会报出这个工具错误,此时使用如下命令重新安装工具包即可。 python3 -m ensurepip –upgrade python会重新安装setuptools工具包
UserWarning: Boolean Series key will be reindexed to match DataFrame index
1
sample_df[sample_df['money']<=10][(sample_df['money']>0]
布尔型系列键将索引匹配获得对应的索引
意思就是这里有两个布尔值,就会语义不明,所以报错
方法
1
sample_df[(sample_df['money']<=10)&(sample_df['money']>0)]
Python Tricks
将20W张图片分别存放在100个文件夹中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import os
import shutil
import traceback
def move_file(src_path, dst_path, file):
print('from : ',src_path)
print('to : ',dst_path)
try:
# cmd = 'chmod -R +x ' + src_path
# os.popen(cmd)
f_src = os.path.join(src_path, file)
if not os.path.exists(dst_path):
os.mkdir(dst_path)
f_dst = os.path.join(dst_path, file)
shutil.move(f_src, f_dst)
except Exception as e:
print('move_file ERROR: ',e)
i = 0
j = 0
for i in range(200000):
move_file(("./data/img_align_celeba/"),\
("./data/"+str(j)+"/"), (str(i).rjust(6,'0')+".jpg"))
if (((i+1) % 2000) == 0):
j = j + 1
判断一个数是不是2的n次幂
1
assert latent_size!=0 and (latent_size & (latent_size - 1)) == 0), "latent size is not power of 2"
拼接多张图为一个网格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 18, 19, 20, 22, 34
l = [18, 19, 20, 22, 34]
pic = []
for i in l:
if i<=11:
img = cv2.imread("show_{}.png".format(i))
else:
img = cv2.imread("show{}.png".format(i))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (265, 800))
img = loader(img).unsqueeze(0)
print(img.shape)
pic.append(img)
pics = torch.cat(pic, dim=0)
pics = unloader(make_grid(pics, nrow=pics.size(0)))
pics.save("./processed_pic/merge_1.jpg")
导入当前路径
1
2
3
4
import sys
import os
path = os.path.abspath(os.path.dirname(__file__))
sys.path.append(path)
引用不同目录下的包
import 上级目录
有时候我们可能需要import另一个路径下的python文件,例如下面这个目录结构,我们想要在_train.py里import在networks目录下的_lstm.py和上级目录下的_config.py。
1
2
3
4
5
6
_config.py
networks
_lstm.py
_cnn.py
pipelines
_train.py
- 在networks文件夹下创建空的__init__.py文件
1
2
3
4
5
6
7
_config.py
networks
__init__.py
_lstm.py
_cnn.py
pipelines
_train.py
- 使用sys库添加路径
1
2
3
4
import sys
sys.path.append("..")
from networks._lstm import *
from _config import *
生成 requirements
1
2
3
4
5
生成requirements.txt文件
pip freeze > requirements.txt
安装requirements.txt依赖
pip install -r requirements.txt
multiprocessing
pathos
pathos 包提供了一些基本工具,使最终用户更容易访问并行和分布式计算。pathos 的目标是让用户通过最小的重构将自己的代码扩展为并行和分布式计算。
pathos 提供了配置、启动、监控和控制远程主机上服务的方法。pathos 最基本的特性之一是能够在远程主机上配置和启动基于 rpc 的服务。pathos 使用 portpicker 脚本向远程主机发送种子,该脚本允许远程主机通知本地主机可用的端口。
除了建立 RPC 服务然后提交请求的能力之外,还有并行启动代码的能力。与在节点级别执行的并行计算(通常使用MPI)不同,pathos 允许用户跨异构分布式资源并行启动作业。pathos 提供了分布式映射和管道算法,可以选择本地处理器和分布式工作器的混合。pathos 还提供了一个非常基本的自动负载平衡服务,以及用户直接选择资源的能力。
hight-level pool.map 接口,生成一个对用户隐藏 RPC 内部信息的 map 实现。pool.Map,用户可以并行启动他们的代码,并且作为一个分布式服务,使用标准的python,而不需要编写一行服务器或并行批处理代码。
众所周知,RPC服务器和通信通常是不安全的。然而,pathos 并没有试图使RPC通信本身安全,而是提供了在 ssh 隧道中自动包装任何分发服务或通信的能力。ssh 是一种普遍可信的方法。使用 ssh-tunnel, pathos 已经在国家实验室集群上启动了几次分布式计算,并且迄今为止已经利用多个国家实验室集群与用户笔记本电脑之间的节点到节点通信进行了测试计算。pathos 允许用户在非常原子化的层次上配置和启动。
在类中使用 multiprocessing
python多进程死锁
结论:python多进程间用Queue通信时,如果子进程操作Queue满了或者内容比较大的情况下,该子进程会阻塞等待取走Queue内容(如果Queue数据量比较少,不会等待),如果调用join,主进程将处于等待,等待子进程结束,造成死锁
解决方式:在调用join前,及时把Queue的数据取出,而且Queue.get需要在join前
https://cloud.tencent.com/developer/article/1773574
Reference
- python 字符串补全填充固定长度(补0)的三种方法
- Python3 菜鸟教程
- np.prod() 函数计算数组元素乘积等
- H5文件简介和使用
- python:函数传参是否会改变函数外参数的值
- python字符串前加r、f、u、l 的区别
- Python图像库PIL的类Image及其方法介绍
- Python的Tqdm模块——进度条配置
- python3 sys模块
- np.max 与 np.maximum
- np.maximum vs np.minimum
- Numpy知识点补充:np.expand_dims()&np.argmax()
- python setattr()、getattr()、hasattr() 函数用法介绍
- Python的map()
- python中join()函数的使用方法
- Python lambda介绍
- python中copy()和deepcopy()详解
- Python中的super()用法
- Python super() 函数
- Python @staticmethod@classmethod用法
- random — 生成伪随机数
- Python的Tqdm模块——进度条配置
- python中os的常用方法
- python中os.walk的用法详解
- 【NumPy】 print 打印全部 np.set_printoptions
- Seaborn常见绘图总结
- python笔记:numpy中mgrid的用法
- Python怎么导入上一级文件,使用相对路径,被导入文件,导入自己路径下文件,就报不能导入此模块名?
- python:获取当前目录、上层目录路径
- numpy.where() 用法详解
- python闭包与nonlocal简单注意点
- matplotlib.pyplot中cla()、cls()、close()区别详解
- NameError:name ‘xrange’ is not defined
- python3出现module “importlib._bootstrap” has no attribute “SourceFileLoader”
- python中的base64加密解密
- Python eventlet 模块笔记
- pd.read_csv用法
- pandas用法总结
- argparse简要用法总结
- python 导入同级目录文件、上级目录文件以及下级目录数据集和模块包
- Python 生成requirement 使用requirements.txt
- numpy vstack hstack dstack 区别
- python,numpy中np.random.choice()的用法详解及其参考代码
- subplots()使用方法举例说明
- python中用matplotlib画多幅图时出现图形部分重叠的解决方案
- matplotlib可视化篇hist()–直方图
- 错误解决1:UserWarning: Boolean Series key will be reindexed to match DataFrame index
- np.arange()用法
- Numpy中 cov() 的使用方法
- numpy.loadtxt()
- Matplotlib之设置x,y坐标轴的位置
- Matplotlib:mpl_toolkits.mplot3d工具包
- 3分钟理解np.meshgrid()
- 3D绘图&ax.plot_surface()
- matplotlib.pyplot contourf()函数的使用
- Linux服务器没有GUI的情况下使用matplotlib绘图
- np.random.multivariate_normal方法浅析
- Matplotlib入门-4-plt.legend( )创建图例
sys.modules[__name__]- python读取csv文件
- python @abstractmethod
- python3 functools
- itertools中groupby的学习
- os.path.expanduser(path)使用举例
- python学习——print和pprint两者的区别
- python装饰器中functools.wraps的作用详解
- eval和ast.literal_eval方法
- multiprocessing在类中使用问题记录
- python多进程假死
- Python3 函数参数列表单独一个星号 * 的作用