论文部分
Abstract
我们提出了一种自编码器,这种自编码器能充分利用学习到的表征,更好地测量数据空间的相似度。通过结合一个变分自编码器和一个生成对抗网络,我们使用GAN的Discriminator学习到的特征表征,作为VAE的重构目标的基础。因此,我们使用特征级的误差取代了像素级的误差, 当对转化提供不变性时,能够更好地捕获数据分布。我们使用我们的方式在人脸的图片上,比像素级别精确度的VAEs表现地更好。此外,我们的方式学习到一种嵌入,其中高等级抽象的特征(比如戴眼镜)可以通过简单的算法来进行修改。
Introduction
规模很大、多样的数据集,识别模型广泛的使用深度结构。然而,对于复杂的数据分布,生成模型仍然有很多问题,比如图像和音频。我们表明,当前使用的相似性指标给学习良好的生成模型增加了障碍,我们可以通过一种学习到的相似度标准提升生成模型。
当学习模型时VAE时, 相似性指标的选择至关重要,因为它提供了 训练信号的主要部分是通过重建误差目标实现的。对于这项任务,一般默认是像素级的衡量标准, 比如方差。像素级的衡量标准是简单的,但并不很适用于图片数据, 因为它们不适合模拟人类视觉感知的属性。比如,一个小的图像转化可能导致大的像素级别的误差, 然而人类却很难注意到这些变化。因此,我们提出使用更高层次的标准和充分的图像的不变性表征来衡量图像相似度。相比于人为找到一个合适的衡量标准来适应像素级别衡量标准的问题, 我们想要给这项任务学习一个函数。这个问题是如何学习这样一个相似度标准?我们发现通过结合训练一个VAE和一个生成对抗网络, 我们可以使用GAN的Discriminator来测量样本的相似度。如图,我们得到了如下的VAE和GAN的结合模型。我们让VAE的decoder和GAN的Generator共享参数并一起训练。对于VAE的训练目标, 我们用Discriminator中特征级别的衡量标准来替换传统的像素级别的重构标准。
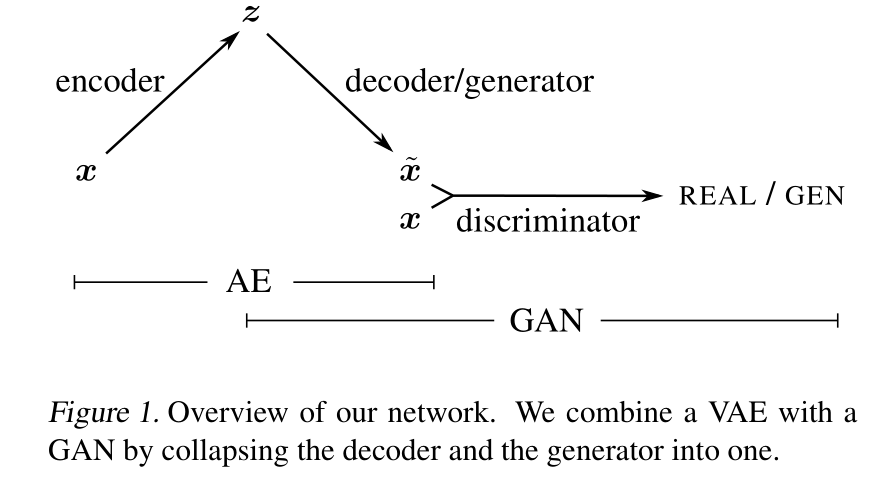
Contributions
我们的贡献如下:
-
我们结合了VAEs和GANs到一个无监督生成模型, 这个模型同时学习编码,生成和对比数据样本。
-
我们发现学习到的特征级别的衡量标准的模型生成的图像样本比像素级别的误差衡量标准的模型更好。
-
我们发现无监督训练会导致一个隐图像表征, 这个表征具有分解的变量因素。这在用视觉特征向量标记的面部图像数据集上的实验中的到了说明,在学习到的潜空间中应用简单的算法即可生成反映这些属性变化的图像。
具有学习相似度衡量标准的自编码器
在本节中,我们提供有关VAE和GAN的背景信息。 然后,我们介绍将两种方法结合起来的方法,我们称之为VAE / GAN。 就像我们将要描述的那样,我们提出的混合动力是一种改进VAE的方式,因此它依赖于一种更有意义的,基于功能的度量标准来测量训练期间的重建质量。
Variational autoencoder
VAE由两个网络组成,分别将数据样本x编码为潜在表示z并将潜在表示解码回数据空间:
\[z \thicksim Enc(x) = q(z \mid x), \tilde x \thicksim Dec(z) = p(x \mid x) \tag{1}\]VAE通过对潜在分布$p(z)$施加先验来对编码器进行规范化。VAE损失函数是负的对数似然(重建误差)的期望与先验正则项之和:
\[L_{VAE} = -E_{q(z \mid x)}[log \frac{p(x \mid z) p(z)}{q(z \mid x)}] = L_{llike}^{pixel} + L_{prior} \tag{2}\]其中:
\[L_{llike}^{pixel} = -E_{q(z \mid x)}[log p(x \mid z)] \tag{3}\] \[L_{prior} = D_{KL}(q(z \mid x) \| p(z)) \tag{4}\]Generative adversarial network
GAN由两个网络组成:生成器网络Gen(z)将潜在z映射到数据空间,而判决器网络判决x为实际训练样本的概率$y=Dis(x)\in [0, 1]$, x由模型通过$x=Gen(z), z \thicksim p(z)$生成的概率为1-y。 GAN的目标是找到二分类器,这个分类器给出真实数据和生成的数据的判决,同时使Generator尽可能地拟合真实数据分布。因此,我们的目标是最大化/最小化二分类的交叉熵:
\[L_{GAN} = log (D(x)) + log (1 - D(G(z))) \tag{5}\]超越像素级别重构误差的VAE/GAN
GAN的一个吸引人的特性是它的Discriminator网络学习到了对图像相似度非常棒的衡量标准, 以此去判决它们是否是图像。我们因此提出发掘这种现象为了去迁移图像学习的特性通过将Discriminator变成VAE的一个更抽象的重构误差。最终的结果是,一个方法结合了GAN作为一个高质量生成模型的优势, VAE作为一个产生隐空间z数据的编码器。
特别地, 因为像素级别的重构误差对于图像和其他具有不变性的信号是不足够的, 我们提出用GAN的Discriminator作为重构误差替换VAE公式(3)中的重构误差(log似然函数的期望)。为了达到这个目的,我们让$Dis_l(x)$表示判决器第l层的表征。 我们为$Dis_l(x)$引入均值为$Dis_l(\tilde x)$, 恒等协方差的高斯观测模型:
\[p(Dis_l(x) \mid z) = N(Dis_l(x) \mid Dis_l(\tilde x), 1) \tag{6}\]其中 $\tilde x \thicksim Dec(z)$是$x$的decoder的采样
我们现在可以把等式(3)中VEA的误差用下面的等式替换:
\[L_{llike}^{Dis_l} = -E_{q(z \mid x)}[log p(Dis_l(x) \mid z)] \tag{7}\]我们使用三重准则训练组合模型:
\[L = L_{prior} + L_{llike}^{Dis_l} + L_{GAN} \tag{8}\]值得注意的是, 我们优化了VAE wrt。 $L_{GAN}$除了重构误差以外,还有风格误差,也可以用Gatys等人的术语将其解释为内容误差。由于Dec和Gen都从z映射到x,因此我们在两者之间共享参数(或者换句话说,在等式(5)中使用Dec而不是Gen)。
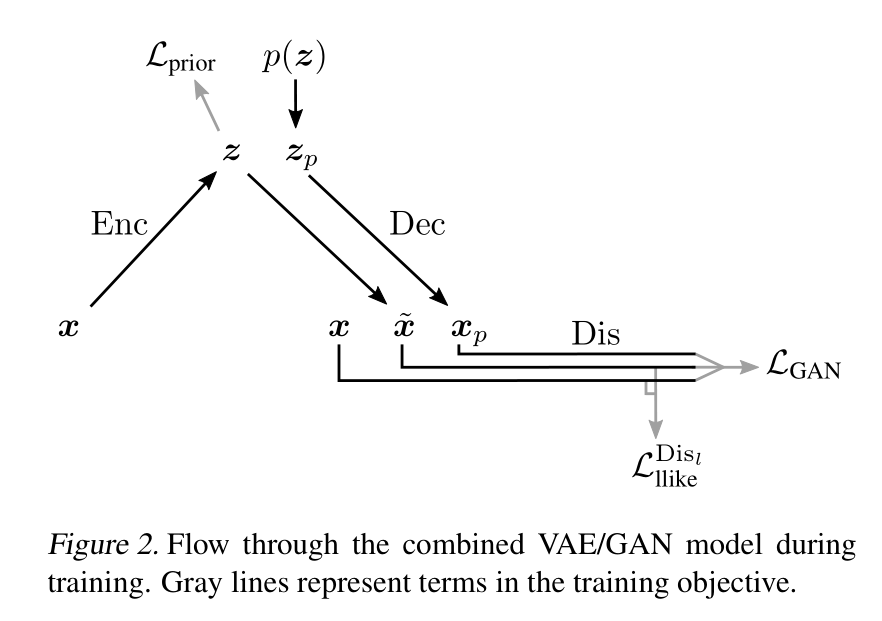
将误差信号限制在相关网络
使用等式(8)中的loss函数,我们同时训练VAE和GAN。这是可能的,因为我们不同时更新所有网络参数。特别地, Dis不应该最小化$L_{llike}^{Dis_l}$,因为这会使Discriminator坍缩至0。我们同时通过不将$L_{GAN}$的误差信号反向传播到Enc, 观测到更好的结果。
加权VAE和GAN
因为Dec同时从$L_{llike}^{Dis_l}$和$L_{GAN}$接收误差信号, 我们使用一个参数$\gamma$来加权重构的能力和骗过Discriminator的能力。这也可以被解释为加权风格和内容。相比于将$gamma$应用于整个模型(等式(8)),我们让加权仅仅在更新Dec的参数时发挥作用:
\[\theta_{Dec} \stackrel{+}{\leftarrow} - \bigtriangledown_{\theta_{Dec}}(\gamma L_{llike}^{Dis_l} - L_{GAN}) \tag{9}\]判决来自$p(z)$和$q(z \mid x)$的样本
在GAN的目标函数中除了使用先验$p(z)$外, 还使用$q(z \mid x)$(即编码器Enc)的样本, 观察到了更好的结果:
\[L_{GAN} = log (Dis(x)) + log (1 - Dis(Dec(z))) + log (1 - Dis(Dec(Enc(x))))\]注意到隐空间$L_{prior}$的规范化应该使得$p(z)$和$q_{z \mid x}$采样的样本相似。 然而, 对于任意给定的$x$, 负样本$Dec(Enc(x))$比$Dec(z)$更与$x$相似。 当根据$L_{GAN}$更新时,我们猜测相似的正样本和负样本更有利于学习信号。
相关工作
众所周知,对于像图像这样的复杂数据分布,元素级别的距离度量并不足够。在计算机视觉社区,预处理图像是一个流行的解决方案特定抖动提升健壮性。预处理的示例是对比度归一化,处理梯度图像或直方图中收集的像素统计信息。我们将这些操作视为度量工程的一种形式,以解决简单的元素级距离度量的缺点。Wang&Bovik(2009)提供了关于该主题的更详细的讨论。
神经网络已经以Siamese architecture的形式应用于度量学习(Bromley等,1993; Chopra等,2005)。对相似的样本, 最小化学习距离度量;对不相似的样本,最大化边际成本。但是,由于Siamese网络是在监督下进行训练的,因此我们无法将其直接应用于我们的问题。
在过去的一年中,已经提出了一些尝试来改进生成模型的元素距离。Ridgeway等,(2015年)将结构相似性指标用作灰度图像的自动编码器(AE)重建指标。Yan等, (2015年)让VAE输出两个额外的图像,以更明确地学习形状和边缘结构。Mansimov等,(2015)附加基于GAN 加快生成模型的步骤。Mathieu等, (2015年)用GAN和基于图像梯度的相似性度量补充平方误差度量,以提高视频预测的图像清晰度。尽管所有这些扩展都能产生明显更清晰的图像,但与深度学习方法相比,它们在捕获高级结构方面没有相同的潜力。
与直接为数据集样本和潜在表示之间的关系建模的AE相比,GAN学会了间接生成样本。通过优化GAN生成器以根据GAN判决器生成模仿数据集的样本,GAN可以通过构造的方式避免元素级相似性度量。如Denton等人所述,这可能是其产生高质量图像的能力的解释。 (2015); Radford等人(2015)。
最近,具有上采样的卷积网络已显示可用于从潜在表示生成图像。这激发了在图像嵌入方面的兴趣,在图像嵌入中可以使用简单的算法表达语义关系–与Mikolov等人的word2vec模型的令人惊讶的结果类似。 (2013)。
首先,Dosovitskiy等。 (2015年)使用监督训练来训练卷积网络,以根据所需椅子的高级信息生成椅子。随后,Kulkarniet al. (2015); Yan et al. (2015); Reed et al. (2015)等展示了具有解开特征表示的编码器-解码器架构, 但是它们的训练方案依赖于监督信息。Radford等。 (2015年)在训练后检查GAN的潜在空间,并找到与眼镜和微笑相对应的方向。但是,由于它们依赖纯GAN,因此无法对图像进行编码,这使得探索潜在空间具有挑战性。
我们关于学习的相似性度量的想法部分是由Gatys等人的神经艺术风格网络激发的。 (2015年)证明了深度卷积特征的表示能力。通过在预训练卷积网络中优化图像使其具有与主题图像相似的特征以及与样式图像相似的特征相关性,它们获得了令人印象深刻的结果。在我们的VAE/GAN模型中,可以将$L_{llike}^{Dis_l}$视为内容,将$L_{GAN}$视为风格。但是,我们的风格这一项,不是从特征相关性计算得来的,而是来自于尽可能地欺骗GAN中Discriminator的误差信号。
Experiments
衡量生成模型的质量具有挑战性,因为当前的评估方法对于较大的自然图像存在问题(Theis等,2015)。在这项工作中,我们使用尺寸为64x64的图像,并着重于定性评估,因为传统的对数似然度量无法捕获视觉保真度。事实上,确实,我们在训练VAE / GAN模型并使用剩余的VAE计算基于像素的对数似然之后,尝试丢弃GAN判决器。 结果与普通的VAE模型(在CIFAR-10数据集上)相比,远远没有竞争力。
在本节中,我们研究不同生成模型的性能:
-
具有元素级高斯观测的朴素VAE模型。
-
具有学习距离的VAE(${VAE}_{Dis_l}$)。我们首先训练GAN,并将判决器网络用作学习的相似性度量。我们选择一个层l,根据$Dis_l$来测量相似度。l的选择是这样的,即在对卷积编码器进行3次采样(每个采样的系数为2)后进行比较。
-
组合的VAE / GAN模型。该模型类似于$VAE_{Dis_l}$,但我们也优化了Dec wrt, $L_{GAN}$。
-
GAN。这种模型最近被证明是有能力的生成高质量图像(Radford et al., 2015)。
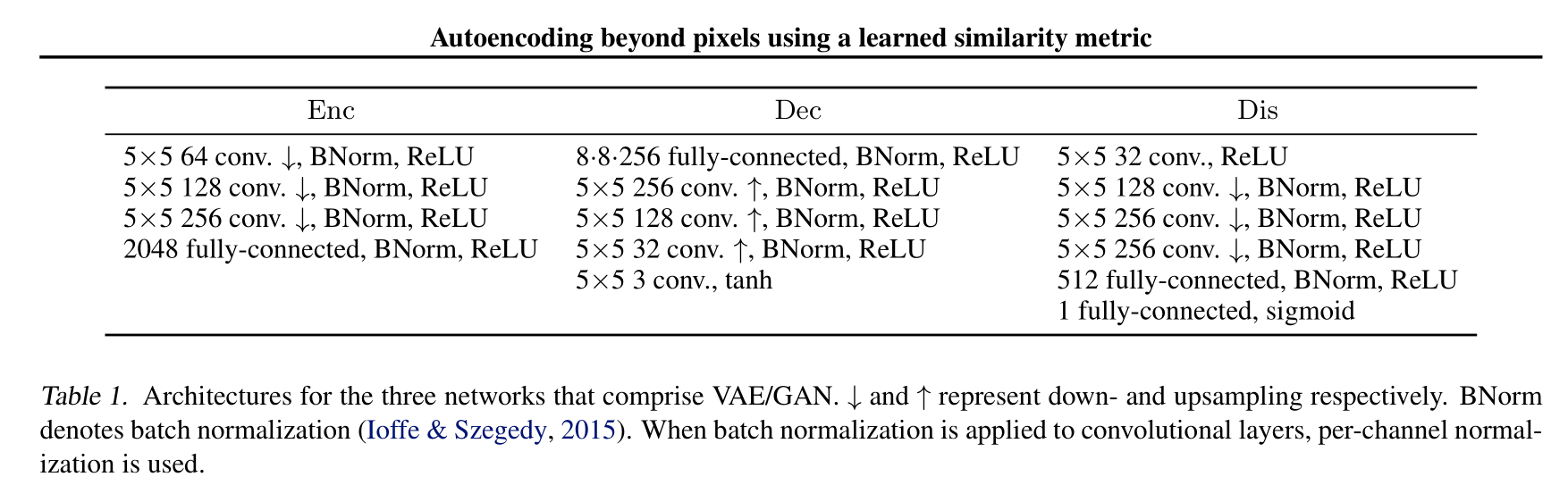
所有的模型对Enc、Dec、Dis共享相同的结构。在我们所有的实验中,我们使用了卷积架构和反向卷积(aka. fractional striding)。在Dec中使用步长为2的反卷积来扩大图像。反向卷积同反转卷积的方向实现上采样。我们的模型使用RMSProp进行训练,学习率为0.0003,批量大小为64。
CelebA face images
我们将我们的方法应用于CelebA数据集 (Liu et al., 2015)。这个数据集由202,599张图片组成,注释了40个二进制属性,如眼镜、刘海、苍白的皮肤等。我们将图像缩放和裁剪到64×64像素,并且只使用图像(而不是属性)进行无监督训练。
经过训练,我们从p(z)中抽取样本,通过Dec进行传播,生成如图3所示的新图像。一般的VAE可以将脸部的正面画得很清晰,但是如果偏离中心,图像就会变得模糊。这是因为该数据集使用正面标志对面部进行对齐。当我们离对齐的部分太远时,由于不能假定像素对应,识别模型就会崩溃。$VAE_{Dis_l}$产生了更清晰的图像,即便是偏离中心,因为重建误差使用特征级而不是像素级。然而,我们看到严重的人工噪音,我们认为这是由于苛刻的下采样方案造成的。相比之下,VAE/GAN和pure GAN可以生成更清晰的图像,具有更自然的纹理和面部特征。
此外,我们使用VAEs重构了一些图像,这些图像来自于一个单独的测试集。重构不可能是一个GAN模型,因为它缺乏一个编码器网络。结果如图4所示,我们的结论与随机样本的观察结果相似。


注意到$VAE_{Dis_l}$在一些重构中产生了嘈杂的蓝色图案。我们怀疑基于GAN的相似性度量在某些情况下会崩溃为0(比如我们观察到的模式),这鼓励Dec生成这样的模式。
VISUAL ATTRIBUTE VECTORS
在学习嵌入的尝试中,语义概念可以用简单的算术来表达(Mikolov et al., 2013),受此启发,我们检查了训练过的VAE/GAN模型的潜空间。其思想是在图像空间,找出潜空间中与特定视觉特征相对应的方向。
我们使用数据集的二进制属性来提取可视化属性向量。对于所有的图像,我们使用编码器来计算潜在的向量表示。 对于每个属性,我们分别计算具有该属性的图像的均值向量和不具有该属性的图像的均值向量。然后计算两个均值向量之差作为视觉属性向量。这是一种非常简单的计算视觉属性向量的方法,这种方法将会遇到高度相关的视觉属性的问题,比如浓妆浓抹和涂口红。在图5中,我们展示了人脸图像,以及将不同的视觉属性向量添加到潜在表征后的重构。虽然不完美,但我们清楚地看到属性向量捕捉语义概念,如眼镜、刘海等。如。当刘海被添加到脸上时,头发的颜色和发质都与原来的脸相匹配。我们还发现,男性的特征与胡子高度相关,这是由数据集中的属性相关性造成的。
Attribute similarity, Labeled faces in the wild
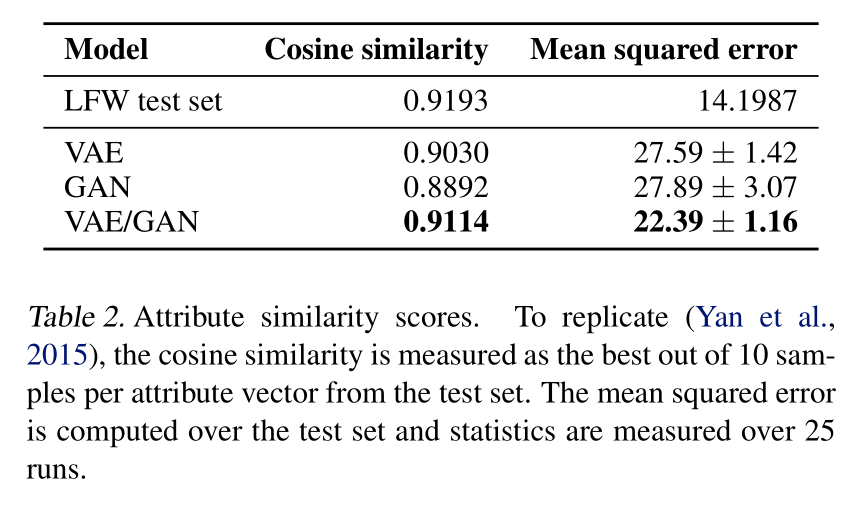
受Yan等人(2015)属性相似度实验的启发,我们寻求对生成的图像进行更定量的评估。这个想法是学习基于面部属性的面部图像生成模型。在测试时,我们通过检索所选择的属性配置来生成人脸图像,并让一个单独训练的回归网络来预测所生成图像的属性。一个好的生成模型应该能够生成被回归模型正确识别的视觉属性。为了模仿最初的实验,我们使用带有属性的野生标记人脸(LFW)图像(Huang et al., 2007) (Kumar et al., 2009)。我们根据地标对齐面部图像(Zhu et al., 2014)。此外,我们裁剪和调整图像大小为64×64像素和使用公共操作增加数据集。同样,我们在网上参考我们的实现以获得更多的细节。我们通过将属性向量连接到Enc、Dec和Dis中输入的向量表示来构建条件VAE、GAN和VAE/GAN模型(Mirza & Osindero, 2014)。对于Enc和Dis,将属性向量连接到顶层全连接层的输入。我们的回归网络具有与Enc几乎相同的架构。我们使用LFW训练集进行训练,在测试期间,我们限定测试集的面部属性和面部样本通过回归网络进行反向传播。图6显示了对测试集中的属性向量进行条件设置所生成的面部。我们在表2中报告了回归器性能数据。与一般的VAE相比,VAE/GAN模型在视觉上具有更好的属性,使得识别误差更小。GAN网络的表现令人吃惊的差,我们怀疑这是由于训练过程中的不稳定性造成的(由于极小极大目标函数,GAN模型很难可靠地训练)。请注意,我们的结果与Yan等人(2015)的结果并不具有直接可比性,因为我们无法获得他们的预处理方案或回归模型。


Unsupervised pretraining for supervised tasks
为了完整性,我们报告说,我们已经尝试在半监督的设置中评估VAE/GAN,通过非监督的预训练,然后使用少量带标签的示例进行finetuning(针对CIFAR-10和STL-10数据集)。不幸的是,我们还不能达到与最先进的技术相竞争的结果(Rasmus et al., 2015;赵等,2015)。我们推测,对于VAE-GAN模型来说,类内的变化可能太高了,无法很好地概括不同的对象类。
Discussion
元素方面的距离度量的问题在文献中是众所周知的,许多尝试都试图超越像素—通常使用人工设计的度量。本着深度学习的精神,我们认为相似性度量是另一个组件,它可以被一个能够捕获与数据分布相关的高级结构的学习模型所取代。在这项工作中,我们的主要贡献是一个学习和应用这种距离测量的无监督方案。通过学习距离测量,我们可以训练一个图像编码-解码器网络,生成我们实验中显示的图像的无损视觉保真度。此外,我们证明我们的网络能够解开输入数据分布中的变化的因素,并在潜空间的高层表征中发现视觉属性。原则上,我们可以使用一组大的未标记图像进行训练,并使用一组小的标记图像来发现潜在空间中的特征。
我们认为我们的方法是VAE框架的扩展。但是,必须指出的是,我们生成的图像的高质量是由于Dec作为VAE解码器和GAN发生器的联合训练。这使得我们的方法更像是VAE和GAN的混合,或者,我们的方法更像是GAN的扩展,其中p(z)受到附加网络的约束。
GAN的判别器网络在为不同的任务进行训练时提供了有用的相似性度量,即能够区分生成的样本和真实的样本,这一点并不明显。然而,令人惊讶的是,卷积特征通常非常适合于迁移学习,正如我们所展示的,在我们的例子中,它足以改善图像的元素距离。如果距离测量中更好的特征能改善模型,这将是一件有趣的事情,例如,通过使用训练人脸的Siamese网络提供的相似性测量,尽管在实践中Siamese网络并不适合我们的方法,因为它们需要标记数据。或者可以研究使用预先训练的前馈网络来测量相似性的效果。
综上所述,我们已经证明了编码-解码器模型的无监督学习和相似性度量的首次尝试。我们的结果表明,我们的方法的视觉保真度是有竞争力的GAN,在这方面被认为是最先进的。因此,我们认为学习相似性度量是将生成模型扩展到更复杂的数据分布的一个有前途的步骤。
实现部分
Reference
- Larsen A B L, Sønderby S K, Larochelle H, et al. Autoencoding beyond pixels using a learned similarity metric[J]. arXiv preprint arXiv:1512.09300, 2015.
- https://github.com/a514514772/Pytorch-VAE-GAN/blob/master/VAE-GAN.ipynb