C/C++语法
重载
重载操作符
您可以重定义或重载大部分 C++ 内置的运算符。这样,您就能使用自定义类型的运算符。
重载的运算符是带有特殊名称的函数,函数名是由关键字 operator 和其后要重载的运算符符号构成的。与其他函数一样,重载运算符有一个返回类型和一个参数列表。
1
2
3
4
5
6
bool operator<(const node &oth)const
{
if(x!=oth.x)
return x<oth.x;
return y<oth.y;
}
Vector用法
vector 说明
- vector是向量类型,可以容纳许多类型的数据,因此也被称为容器
- (可以理解为动态数组,是封装好了的类)
- 进行vector操作前应添加头文件#include <vector>
vector初始化
方式1:
1
2
3
4
//定义具有10个整型元素的向量
//(尖括号为元素类型名,它可以是任何合法的数据类型)
//不具有初值,其值不确定
vector<int>a(10);
方式2:
1
2
//定义具有10个整型元素的向量,且给出的每个元素初值为1
vector<int>a(10,1);
方式3:
1
2
//用向量b给向量a赋值,a的值完全等价于b的值
vector<int>a(b);
方式4:
1
2
//将向量b中从0-2(共三个)的元素赋值给a,a的类型为int型
vector<int>a(b.begin(),b.begin+3);
// 这种方式得到的是两个地址之间截到的的变量 vector<int> test = vector<int>(vin.begin(), vin.begin()+1);
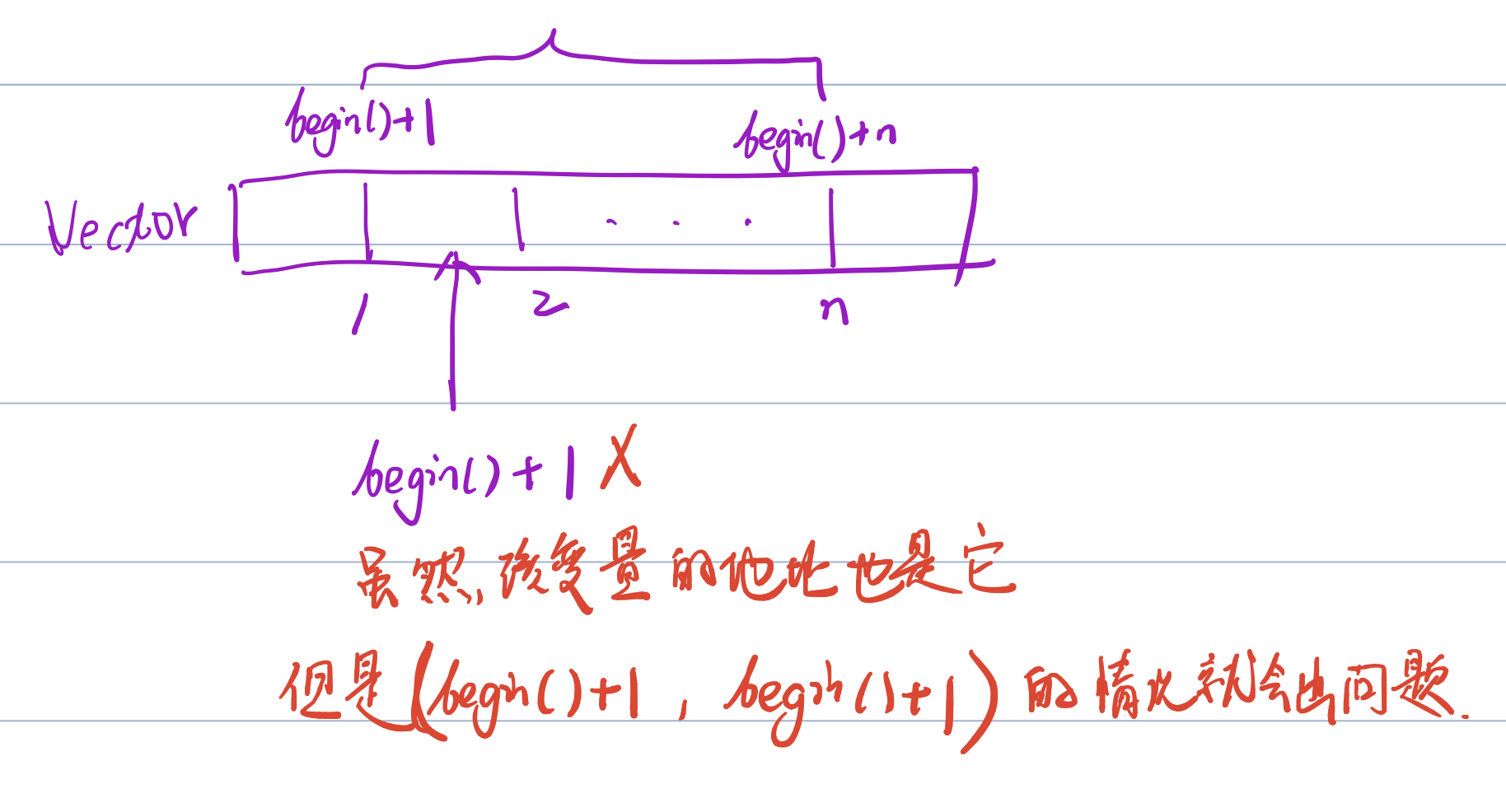
方式5:
1
2
3
//从数组中获得初值
int b[7]={1,2,3,4,5,6,7};
vector<int> a(b,b+7);
vector对象的常用内置函数使用(举例说明)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
#include<vector>
vector<int> a,b;
//b为向量,将b的0-2个元素赋值给向量a
a.assign(b.begin(),b.begin()+3);
//a含有4个值为2的元素
a.assign(4,2);
//返回a的最后一个元素
a.back();
//返回a的第一个元素
a.front();
//返回a的第i元素,当且仅当a存在
a[i];
//清空a中的元素
a.clear();
//判断a是否为空,空则返回true,非空则返回false
a.empty();
//删除a向量的最后一个元素
a.pop_back();
//删除a中第一个(从第0个算起)到第二个元素
//也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+3(不包括它)结束
a.erase(a.begin()+1,a.begin()+3);
//在a的最后一个向量后插入一个元素,其值为5
a.push_back(5);
//在a的第一个元素(从第0个算起)位置插入数值5,
a.insert(a.begin()+1,5);
//在a的第一个元素(从第0个算起)位置插入3个数,其值都为5
a.insert(a.begin()+1,3,5);
//b为数组,在a的第一个元素(从第0个元素算起)的位置插入b的第三个元素到第5个元素(不包括b+6)
a.insert(a.begin()+1,b+3,b+6);
//返回a中元素的个数
a.size();
//返回a在内存中总共可以容纳的元素个数
a.capacity();
//将a的现有元素个数调整至10个,多则删,少则补,其值随机
a.resize(10);
//将a的现有元素个数调整至10个,多则删,少则补,其值为2
a.resize(10,2);
//将a的容量扩充至100,
a.reserve(100);
//b为向量,将a中的元素和b中的元素整体交换
a.swap(b);
//b为向量,向量的比较操作还有 != >= > <= <
a==b;
顺序访问vector的几种方式,举例说明
对向量a添加元素的几种方式
- 向向量a中添加元素
1
2
vector<int>a;
for(int i=0;i<10;++i){a.push_back(i);}
- 从数组中选择元素向向量中添加
1
2
3
int a[6]={1,2,3,4,5,6};
vector<int> b;
for(int i=0;i<=4;++i){b.push_back(a[i]);}
3.从现有向量中选择元素向向量中添加
1
2
3
4
5
6
7
int a[6]={1,2,3,4,5,6};
vector<int>b;
vector<int>c(a,a+4);
for(vector<int>::iterator it=c.begin();it<c.end();++it)
{
b.push_back(*it);
}
4.从文件中读取元素向向量中添加
1
2
3
ifstream in("data.txt");
vector<int>a;
for(int i;in>>i){a.push_back(i);}
- 常见错误赋值方式
1
2
vector<int>a;
for(int i=0;i<10;++i){a[i]=i;}//下标只能用来获取已经存在的元素
从向量中读取元素
1.通过下标方式获取
1
2
3
int a[6]={1,2,3,4,5,6};
vector<int>b(a,a+4);
for(int i=0;i<=b.size()-1;++i){cout<<b[i]<<endl;}
- 通过迭代器方式读取
1
2
3
4
int a[6]={1,2,3,4,5,6};
vector<int>b(a,a+4);
for(vector<int>::iterator it=b.begin();it!=b.end();it++){cout<<*it<<" ";}
几个常用的算法
1
2
3
4
5
6
7
8
9
10
11
12
#include<algorithm>
//对a中的从a.begin()(包括它)到a.end()(不包括它)的元素进行从小到大排列
sort(a.begin(),a.end());
//对a中的从a.begin()(包括它)到a.end()(不包括它)的元素倒置,
//但不排列,如a中元素为1,3,2,4,倒置后为4,2,3,1
reverse(a.begin(),a.end());
//把a中的从a.begin()(包括它)到a.end()(不包括它)的元素复制到b中,
//从b.begin()+1的位置(包括它)开始复制,覆盖掉原有元素
copy(a.begin(),a.end(),b.begin()+1);
//在a中的从a.begin()(包括它)到a.end()(不包括它)的元素中查找10,
//若存在返回其在向量中的位置
find(a.begin(),a.end(),10);
vector的嵌套使用
1. 定义
vector<vector<int>> M;
2. 添加元素
这里是vector的嵌套使用,本质是vector元素里的每个元素也是vector类型,所以抓住本质来添加元素就比较容易理解。
我们假设外层的vector的对象为M,为外层vector对象,则M中的每一个元素也是vector类型,记为N1,N2,N3……,为内层对象
则,我们得先形成一个个的N1,N2等的vector对象,然后再将这些vector对象添加进入外层vector对象M中
这样就比较容易理解向vector<vector<int>>对象添加元素的原理了,实现如下:
如M=[[1 2 3], [4 5 6]],添加方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
vector<vector<int>> M; //外层vector对象M
vector<int> N; //内层vector对象
N.push_back(1);
N.push_back(2);
N.push_back(3); //已经形成第一个内层vector对象N1
M.push_back(N); //将形第一个内层vector对象N添加到外层vector对象M中
N.clear(); //清楚N中的元素,可以继续存放后续vector对象
N.push_back(4);
N.push_back(5);
N.push_back(6); //已经形成第一个内层vector对象N2
M.push_back(N); //将形第一个内层vector对象N添加到外层vector对象M中
N.clear(); //清楚N中的元素,可以继续存放后续vector对象
3. 访问元素
访问元素和二维数组相同,M[0][0],访问M中第一个vector对象的第一个元素,值为1;
4、长度
(1)M中vector的个数:M.size();
(2)M中第i个vector元素的长度:M[i].size();
string用法
初始化
初始化有两种方式,其中使用等号的是拷贝初始化,不使用等号的是直接初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
string str1 = "hello world"; // str1 = "hello world"
string str2("hello world"); // str2 = "hello world"
string str3 = str1; // str3 = "hello world"
string str4(str2); // str4 = "hello world"
string str5(10,'h'); // str5 = "hhhhhhhhhh"
string str6 = string(10,'h'); // str6 = "hhhhhhhhhh"
string str7(str1,6); // str7 = "world" 从字符串str1第6个字符开始到结束,拷贝到str7中
string str8 = string(str1,6); // str8 = "world"
string str9(str1,0,5); // str9 = "hello" 从字符串str1第0个字符开始,拷贝5个字符到str9中
string str10 = string(str1,0,5); // str10 = "hello"
char c[] = "hello world";
string str11(c,5); // str11 = "hello" 将字符数组c的前5个字符拷贝到str11中
string str12 = string(c,5); // str12 = "hello"
值得一提的是, 如果:
1
2
string str13 = string("hello world",5)
// str13 = "hello" 而非 " world"
此时,”hello world”应看作字符数组(参见str11),而非string对象(参见str7) 为了避免发生意外,在字符串插入、替换、添加、赋值、比较中去除了关于后一种的相关操作(参见后文)。
获取长度(length、size)
length()函数与size()函数均可获取字符串长度。
1
2
string str = "hello world";
cout << str.length() << str.size(); // 11 11
当str.length()与其他类型比较时,建议先强制转换为该类型,否则会意想之外的错误。 比如:-1 > str.length() 返回 true。
插入(insert)
基本情况为以下四种,其余变形函数自行摸索即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
string str = "hello world";
string str2 = "hard ";
string str3 = "it is so happy wow";
//s.insert(pos,n,ch) 在字符串s的pos位置上面插入n个字符ch
str.insert(6,4,'z'); // str = "hello zzzzworld"
//s.insert(pos,str) 在字符串s的pos位置插入字符串str
str.insert(6,str2); // str = "hello hard world"
//s.insert(pos,str,a,n) 在字符串s的pos位置插入字符串str中位置a到后面的n个字符
str.insert(6,str3,6,9); // str = "hello so happy world"
//s.insert(pos,cstr,n) 在字符串s的pos位置插入字符数组cstr从开始到后面的n个字符
//此处不可将"it is so happy wow"替换为str3
str.insert(6,"it is so happy wow",6); // str = "hello it is world"
替换(replace)
替换与插入对应,对比理解更为简单
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
string str = "hello world";
string str2 = "hard ";
string str3 = "it is so happy wow";
//s.replace(p0,n0,n,ch) 删除p0开始的n0个字符,然后在p0处插入n个字符ch
str.replace(0,6,4,'z'); // str = "zzzzworld"
//s.replace(p0,n0,str) 删除从p0开始的n0个字符,然后在p0处插入字符串str
str.replace(0,6,str2); // str = "hard world"
//s.replace(p0,n0,str,pos,n) 删除p0开始的n0个字符,然后在p0处插入字符串str中从pos开始的n个字符
str.replace(0,6,str3,6,9); // str = "so happy world"
//s.replace(p0,n0,cstr,n) 删除p0开始的n0个字符,然后在p0处插入字符数组cstr的前n个字符
//此处不可将"it is so happy wow"替换为str3
str.replace(0,6,"it is so happy wow",6); // str = "it is world"
添加(append)
append函数用在字符串的末尾添加字符和字符串。(同样与插入、替换对应理解)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
string str = "hello world";
string str2 = "hard ";
string str3 = "it is so happy wow";
//s.append(n,ch) 在当前字符串结尾添加n个字符c
str.append(4,'z'); // str = "hello worldzzzz"
//s.append(str) 把字符串str连接到当前字符串的结尾
str.append(str2); // str = "hello worldhard "
//s.append(str,pos,n) 把字符串str中从pos开始的n个字符连接到当前字符串的结尾
str.append(str3,6,9); // str = "hello worldso happy "
//append(cstr,int n) 把字符数组cstr的前n个字符连接到当前字符串结尾
//此处不可将"it is so happy wow"替换为str3
str.append("it is so happy wow",6); // str = "hello worldit is "
赋值(assign)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
string str;
string temp = "welcome to my blog";
//s.assign(n,ch) 将n个ch字符赋值给字符串s
str.assign(10,'h'); // str = "hhhhhhhhhh"
//s.assign(str) 将字符串str赋值给字符串s
str.assign(temp); // str = "welcome to my blog"
//s.assign(str,pos,n) 将字符串str从pos开始的n个字符赋值给字符串s
str.assign(temp,3,7); // str = "come to"
//s.assaign(cstr,n) 将字符数组cstr的前n个字符赋值给字符串s
//此处不可将"it is so happy wow"替换为temp
str.assign("welcome to my blog",7); //welcome
删除(erase)
1
2
3
4
5
string str = "welcome to my blog";
//s.erase(pos,n) 把字符串s从pos开始的n个字符删除
str.erase(11,3); // str = "welcome to blog"
剪切(substr)
1
2
3
4
5
6
7
string str = "The apple thinks apple is delicious";
//s.substr(pos,n) 得到字符串s位置为pos后面的n个字符组成的串
string s1 = str.substr(4,5); // s1 = "apple"
//s.substr(pos) 得到字符串s从pos到结尾的串
string s2 = str.substr(17); // s2 = "apple is delicious"
比较(compare)
两个字符串自左向右逐个字符相比(按ASCII值大小相比较),直到出现不同的字符或遇’\0’为止。 若是遇到‘\0’结束比较,则长的子串大于短的子串,如:“9856” > “985”。 如果两个字符串相等,那么返回0,调用对象大于参数返回1,小于返回-1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
string str1 = "small leaf";
string str2 = "big leaf";
//s.compare(str) 比较当前字符串s和str的大小
cout << str1.compare(str2); // 1
//s.compare(pos,n,str) 比较当前字符串s从pos开始的n个字符与str的大小
cout << str1.compare(2,7,str2); // -1
//s.compare(pos,n0,str,pos2,n) 比较当前字符串s从pos开始的n0个字符与str中pos2开始的n个字符组成的字符串的大小
cout << str1.compare(6,4,str2,4,4); // 0
//s.compare(pos,n0,cstr,n) 比较当前字符串s从pos开始的n0个字符与字符数组cstr中前n个字符的大小
//此处不可将"big leaf"替换为str2
cout << str1.compare(6,4,"big leaf",4); // 1
交换(swap)
1
2
3
4
5
6
string str1 = "small leaf";
string str2 = "big leaf";
//或者str1.swap(str2) ,输出结果相同
swap(str1,str2); // str1 = "big leaf" str2 = "small leaf"
swap(str1[0],str1[1]); // str1 = "ibg leaf"
反转(reverse)
反转字符串。
1
2
3
string str = "abcdefghijklmn";
reverse(str.begin(),str.end()); // str = "nmlkjihgfedcba"
数值转化(sto*)
只有将p设置为0或nullptr才运行成功
1
2
3
4
5
6
7
8
9
10
to_string(val) //把val转换成string
stoi(s,p,b) //把字符串s从p开始转换成b进制的int
stol(s,p,b) //把字符串s从p开始转换成b进制的long
stoul(s,p,b) //把字符串s从p开始转换成b进制的unsigned long
stoll(s,p,b) //把字符串s从p开始转换成b进制的long long
stoull(s,p,b) //把字符串s从p开始转换成b进制的unsigned long long
stof(s,p) //把字符串s从p开始转换成float
stod(s,p) //把字符串s从p开始转换成double
stold(s,p) //把字符串s从p开始转换成long double
迭代器(iterator)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
string str = "abcdefghijklmn";
//s.begin() 返回字符串s第一个字符的位置
char a = *(str.begin()); // a
//s.end() 返回字符串s最后一个字符串的后一个位置
char b = *(str.end()-1); // n
//s.rbegin() 返回字符串s最后一个字符的位置
char c = *(str.rbegin()); // n
//s.rend() 返回字符串s第一个字符的前一个位置
char d = *(str.rend()-1); // a
查找(find)
- find函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
string str = "The apple thinks apple is delicious"; //长度34
string key = "apple";
//s.find(str) 查找字符串str在当前字符串s中第一次出现的位置
int pos1 = str.find(key); // 4
//s.find(str,pos) 查找字符串str在当前字符串s的[pos,end]中第一次出现的位置
int pos2 = str.find(key, 10); // 17
//s.find(cstr,pos,n) 查找字符数组cstr前n的字符在当前字符串s的[pos,end]中第一次出现的位置
//此处不可将"delete"替换为str2(如果定义str2 = "delete")
int pos3 = str.find("delete", 0, 2); // 26
//s.find(ch,pos) 查找字符ch在当前字符串s的[pos,end]中第一次出现的位置
int pos4 = str.find('s', 0); // 15
- rfind函数
1
2
3
4
5
6
7
8
9
10
11
12
13
//s.rfind(str) 查找字符串str在当前字符串s中最后一次出现的位置
int pos5 = str.rfind(key); // 17
//s.rfind(str,pos) 查找字符串str在当前字符串s的[0,pos+str.length()-1]中最后一次出现的位置
int pos6 = str.rfind(key, 16); // 4
//s.rfind(cstr,pos,n) 查找字符数组cstr前n的字符在当前字符串s的[0,pos+n-1]中最后一次出现的位置
//此处不可将"apple"替换为key
int pos7 = str.rfind("apple", 40, 2); // 17
//s.rfind(ch.pos) 查找字符ch在当前字符串s的[0,pos]中最后一次出现的位置
int pos8 = str.rfind('s', 30); // 24
- find_xxx_of函数
1
2
string str = "The early birds catch the warm"; //长度30
string key = "aeiou";
find_first_of
1
2
3
4
5
6
7
8
9
10
11
12
// s.find_first_of(str) 查找字符串str中的任意字符在当前字符串s中第一次出现的位置
int pos1 = str.find_first_of(key); // 2
//s.find_first_of(str,pos) 查找字符串str中的任意字符在当前字符串s的[pos,end]中第一次出现的位置
int pos2 = str.find_first_of(key, 10); // 11
//s.find_first_of(cstr,pos,n) 查找字符串str前n个任意字符在当前字符串s的[pos,end]中第一次出现的位置
//此处不可将"aeiou"替换为key
int pos3 = str.find_first_of("aeiou", 7, 2); // 17
//s.find_first_of(ch,pos) 查找字符ch在当前字符串s的[pos,end]中第一次出现的位置
int pos4 = str.find_first_of('r', 0); // 6
find_first_not_of
1
2
3
4
5
6
7
8
9
10
11
12
13
//s.find_first_not_of(str) 查找字符串str之外的任意字符在当前字符串s中第一次出现的位置
int pos1 = str.find_first_not_of(key); // 0
//s.find_first_not_of(str,pos) 查找字符串str之外的任意字符在当前字符串s的[pos,end]中第一次出现的位置
int pos2 = str.find_first_not_of(key, 10); // 10
//s.find_first_not_of(cstr,pos,n) 查找字符串str前n个之外任意字符在当前字符串s的[pos,end]中第一次出现的位置
//此处不可将"aeiou"替换为key
int pos3 = str.find_first_not_of("aeiou", 7, 2); // 7
//s.find_first_not_of(str) 查找字符ch之外任意字符在当前字符串s的[pos,end]中第一次出现的位置
int pos4 = str.find_first_not_of('r', 0); // 0
find_last_of
1
2
3
4
5
6
7
8
9
10
11
12
//s.find_last_of(str) 查找字符串str中的任意字符在当前字符串s中最后一次出现的位置
int pos1 = str.find_last_of(key); // 27
//s.find_last_of(str,pos) 查找字符串str中的任意字符在当前字符串s的[0,pos]中最后一次出现的位置
int pos2 = str.find_last_of(key, 15); // 11
//s.find_last_of(cstr,pos,n) 查找字符串str前n个任意字符在当前字符串s的[0,pos]中最后一次出现的位置
//此处不可将"aeiou"替换为key
int pos3 = str.find_last_of("aeiou", 20, 2); // 17
//s.find_last_of(str) 查找字符ch在当前字符串s的[0,pos]中最后一次出现的位置
int pos4 = str.find_last_of('r', 30); // 28
find_last_not_of
1
2
3
4
5
6
7
8
9
10
11
12
//s.find_last_not_of(str) 查找字符串str之外的任意字符在当前字符串s中最后一次出现的位置
int pos1 = str.find_last_not_of(key); // 29
//s.find_last_not_of(str,pos) 查找字符串str之外的任意字符在当前字符串s的[0,pos]中最后一次出现的位置
int pos2 = str.find_last_not_of(key, 15); // 15
//s.find_last_not_of(cstr,pos,n) 查找字符串str前n个之外任意字符在当前字符串s的[0,pos]中最后一次出现的位置
//此处不可将"aeiou"替换为key
int pos3 = str.find_last_not_of("aeiou", 20, 2); // 20
//s.find_last_not_of(str) 查找字符ch之外任意字符在当前字符串s的[0,pos]中最后一次出现的位置
int pos4 = str.find_last_not_of('r', 30); // 29
string大小写转换
将一个string转换成大写或者小写,是项目中经常需要做的事情,但string类里并 没有提供这个方法。自己写个函数来实现,说起来挺简单,但做起来总让人觉得不方便。
STL的algorithm库确实给我们提供了这样的便利,使用模板函数transform可以轻松解决这个问题,开发人员只需要提供一个函数对象,例如将char转成大写的toupper函数或者小写的函数tolower函数。
transform原型:
1
2
3
4
5
6
7
8
9
10
template < class InputIterator, class OutputIterator,
class UnaryOperator >
OutputIterator transform ( InputIterator first1, InputIterator last1,
OutputIterator result, UnaryOperator op );
template < class InputIterator1, class InputIterator2,
class OutputIterator, class BinaryOperator >
OutputIterator transform ( InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, OutputIterator result,
BinaryOperator binary_op );
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <string>
#include <algorithm>
using namespace std;
int main()
{
string strA = "yasaken@126.com";
string strB = "LURY@LENOVO.com";
printf("Before transform:\n");
printf("strA:%s \n", strA.c_str());
printf("strB:%s \n\n", strB.c_str());
transform(strA.begin(), strA.end(), strA.begin(), ::toupper);
transform(strB.begin(), strB.end(), strB.begin(), ::toupper);
printf("After transform to toupper:\n");
printf("strA:%s \n", strA.c_str());
printf("strB:%s \n\n", strB.c_str());
transform(strA.begin(), strA.end(), strA.begin(), ::tolower);
transform(strB.begin(), strB.end(), strB.begin(), ::tolower);
printf("After transform to lower:\n");
printf("strA:%s \n", strA.c_str());
printf("strB:%s \n\n", strB.c_str());
return 0;
}
运行结果:
1
2
3
4
5
6
7
8
9
10
strA:yasaken@126.com
strB:LURY@LENOVO.com
After transform to toupper:
strA:YASAKEN@126.COM
strB:LURY@LENOVO.COM
After transform to lower:
strA:yasaken@126.com
strB:lury@lenovo.com
map
自动建立key - value的对应。key 和 value可以是任意你需要的类型。
我们通常用如下方法构造一个map:
map<int, string> mapStudent;
插入元素
1
2
3
4
5
6
7
8
9
10
11
12
// 定义一个map对象
map<int, string> mapStudent;
// 第一种 用insert函數插入pair
mapStudent.insert(pair<int, string>(000, "student_zero"));
// 第二种 用insert函数插入value_type数据
mapStudent.insert(map<int, string>::value_type(001, "student_one"));
// 第三种 用"array"方式插入
mapStudent[123] = "student_first";
mapStudent[456] = "student_second";
以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的 插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是不能在插入数据的,但是用数组方式就不同了,它可以覆盖以前该关键字对 应的值,用程序说明如下:
mapStudent.insert(map<int, string>::value_type (001, “student_one”));
mapStudent.insert(map<int, string>::value_type (001, “student_two”));
上面这两条语句执行后,map中001这个关键字对应的值是“student_one”,第二条语句并没有生效,那么这就涉及到我们怎么知道insert语句是否插入成功的问题了,可以用pair来获得是否插入成功,程序如下:
1
2
3
4
5
6
7
8
9
// 构造定义,返回一个pair对象
pair<iterator,bool> insert (const value_type& val);
pair<map<int, string>::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(map<int, string>::value_type (001, "student_one"));
if(!Insert_Pair.second)
cout << ""Error insert new element" << endl;
我们通过pair的第二个变量来知道是否插入成功,它的第一个变量返回的是一个map的迭代器,如果插入成功的话Insert_Pair.second应该是true的,否则为false。
查找元素
当所查找的关键key出现时,它返回数据所在对象的位置,如果沒有,返回iter与end函数的值相同。
1
2
3
4
5
6
7
// find 返回迭代器指向当前查找元素的位置否则返回map::end()位置
iter = mapStudent.find("123");
if(iter != mapStudent.end())
cout<<"Find, the value is"<<iter->second<<endl;
else
cout<<"Do not Find"<<endl;
刪除与清空元素
1
2
3
4
5
6
7
8
9
10
//迭代器刪除
iter = mapStudent.find("123");
mapStudent.erase(iter);
//用关键字刪除
int n = mapStudent.erase("123"); //如果刪除了會返回1,否則返回0
//用迭代器范围刪除 : 把整个map清空
mapStudent.erase(mapStudent.begin(), mapStudent.end());
//等同于mapStudent.clear()
map的大小
在往map里面插入了数据,我们怎么知道当前已经插入了多少数据呢,可以用size函数,用法如下:
int nSize = mapStudent.size();
map的基本操作函数
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数
### 遍历map映射容器 三种方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
map<int, string> m;
// 1
for (auto &v : m) {
cout<<v.first<<" "<<v.second<<endl;
}
// 2 lamda表达式
for_each(m.begin(),m.end(),[](map<int,string>::reference a){
cout<<a.first<<" "<<a.second<<endl;
});
// 3 for_each
void fun(map<int,string>::reference a) { //不要少了reference,不然会报错。
cout<<a.first<<" "<<a.second<<endl;
}
for_each(m.begin(),m.end(),fun);
### unordered_map
hash_map未加入在C++11标准中。
在VC中编译:
1
2
3
1 #include <hash_map>
2 using namespace stdext;
3 hash_map<int ,int> myhash;
在GCC中编译:
1
2
3
1 #include <ext/hash_map>
2 using namespace __gnu_cxx;
3 hash_map<int ,int> myhash;
C++ 11标准中加入了unordered系列的容器。unordered_map记录元素的hash值,根据hash值判断元素是否相同。map相当于java中的TreeMap,unordered_map相当于HashMap。无论从查找、插入上来说,unordered_map的效率都优于hash_map,更优于map;而空间复杂度方面,hash_map最低,unordered_map次之,map最大。
set
顺序容器包括vector、deque、list、forward_list、array、string,所有顺序容器都提供了快速顺序访问元素的能力。
关联容器包括set、map。
关联容器和顺序容器有着根本的不同:关联容器中的元素是按关键字来保存和访问的。与之相对,顺序容器中的元素是按它们在容器中的位置来顺序保存和访问的。
关联容器不支持顺序容器的位置相关的操作。原因是关联容器中元素是根据关键字存储的,这些操作对关联容器没有意义。而且,关联容器也不支持构造函数或插入操作这些接受一个元素值和一个数量值得操作。
关联容器支持高效的关键字查找和访问。两个主要的关联容器(associative container)类型是map和set。map中的元素是一些关键字—-值(key–value)对:关键字起到索引的作用,值则表示与索引相关联的数据。set中每个元素只包含一个关键字:set支持高效的关键字查询操作—-检查一个给定关键字是否在set中。
标准库提供set关联容器分为:
1,按关键字有序保存元素:set(关键字即值,即只保存关键字的容器);multiset(关键字可重复出现的set);
2,无序集合:unordered_set(用哈希函数组织的set);unordered_multiset(哈希组织的set,关键字可以重复出现)。
set就是关键字的简单集合。当只是想知道一个值是否存在时,set是最有用的。
在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序。set中元素的值不能直接被改变。set内部采用的是一种非常高效的平衡检索二叉树:红黑树,也称为RB树(Red-Black Tree)。RB树的统计性能要好于一般平衡二叉树。
set具备的两个特点:
- set中的元素都是排序好的
- set中的元素都是唯一的,没有重复的
set用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
begin(); // 返回指向第一个元素的迭代器
end(); // 返回指向迭代器的最末尾处(即最后一个元素的下一个位置)
clear(); // 清除所有元素
count(); // 返回某个值元素的个数
empty(); // 如果集合为空,返回true
equal_range(); //返回集合中与给定值相等的上下限的两个迭代器
erase()–删除集合中的元素
find()–返回一个指向被查找到元素的迭代器
get_allocator()–返回集合的分配器
insert()–在集合中插入元素
lower_bound()–返回指向大于(或等于)某值的第一个元素的迭代器
key_comp()–返回一个用于元素间值比较的函数
max_size()–返回集合能容纳的元素的最大限值
rbegin()–返回指向集合中最后一个元素的反向迭代器
rend()–返回指向集合中第一个元素的反向迭代器
size()–集合中元素的数目
swap()–交换两个集合变量
upper_bound()–返回大于某个值元素的迭代器
value_comp()–返回一个用于比较元素间的值的函数
priority_queue
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。
在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征。
首先要包含头文件#include<queue>, 他和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队列前面,优先出队。
优先队列具有队列的所有特性,包括队列的基本操作,只是在这基础上添加了内部的一个排序,它本质是一个堆实现的。
和队列基本操作相同:
- top 访问队头元素
- empty 队列是否为空
- size 返回队列内元素个数
- push 插入元素到队尾 (并排序)
- emplace 原地构造一个元素并插入队列
- pop 弹出队头元素
- swap 交换内容
定义:priority_queue<Type, Container, Functional>
Type 就是数据类型,Container 就是容器类型(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector),Functional 就是比较的方式。
当需要用自定义的数据类型时才需要传入这三个参数,使用基本数据类型时,只需要传入数据类型,默认是大顶堆。
1
2
3
4
5
6
//升序队列,小顶堆
priority_queue <int,vector<int>,greater<int> > q;
//降序队列,大顶堆
priority_queue <int,vector<int>,less<int> >q;
//greater和less是std实现的两个仿函数(就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了)
pair
pair是将2个数据组合成一组数据,当需要这样的需求时就可以使用pair,如stl中的map就是将key和value放在一起来保存。另一个应用是,当一个函数需要返回2个数据的时候,可以选择pair。 pair的实现是一个结构体,主要的两个成员变量是first second 因为是使用struct不是class,所以可以直接使用pair的成员变量。
两个值可以分别用pair的两个公有函数first和second访问。
静态数组不能扩容(realloc)
新分配在堆内的内存,数组定义之后不能改变大小,realloc(p,sizeof(p)+sizeof(int))函数不会改变p的值,新的内存地址是函数的返回值:
1
2
3
4
5
6
//动态分配的内存才可能扩大
int *p = (int *)malloc(4);
int *q = (int *)realloc(p, 8);
if(q==p) 只是扩大内存
if(q!=p) 重新分配内存,并拷贝数据
if(q==NULL) 函数调用失败
1
2
3
4
5
char *str = (char*)malloc(12 * sizeof(char));
str = "We Are Happy";
if(!(str = (char*)realloc(str, 13*sizeof(char)))){
cout << "out of memory" << endl;
};
这样将字符串赋值给str, 分配内存仍会失败。
C++关于结构体构造函数使用总结
三种结构体初始化方法
- 利用结构体自带的默认构造函数
- 利用带参数的构造函数
- 利用默认无参的构造函数
Note: 什么都不写就是使用的结构体自带的默认构造函数,如果自己重写了带参数的构造函数,初始化结构体时如果不传入参数会出现错误。在建立结构体数组时,如果只写了带参数的构造函数将会出现数组无法初始化的错误。
下面是一个比较安全的带构造的结构体示例
1
2
3
4
5
6
7
8
struct node{
int data;
string str;
char x;
//注意构造函数最后这里没有分号哦!
node() :x(), str(), data(){} //无参数的构造函数数组初始化时调用
node(int a, string b, char c) :data(a), str(b), x(c){}//有参构造
}N[10];
下面我们分别使用默认构造和有参构造,以及自己手动写的初始化函数进行会结构体赋值, 并观察结果
测试代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include <iostream>
#include <string>
using namespace std;
struct node{
int data;
string str;
char x;
//自己写的初始化函数
void init(int a, string b, char c){
this->data = a;
this->str = b;
this->x = c;
}
node() :x(), str(), data(){}
node(int a, string b, char c) :x(c), str(b), data(a){}
}N[10];
int main()
{
N[0] = { 1,"hello",'c' };
N[1] = { 2,"c++",'d' }; //无参默认结构体构造体函数
N[2].init(3, "java", 'e'); //自定义初始化函数的调用
N[3] = node(4, "python", 'f'); //有参数结构体构造函数
N[4] = { 5,"python3",'p' };
//现在我们开始打印观察是否已经存入
for (int i = 0; i < 5; i++){
cout << N[i].data << " " << N[i].str << " " << N[i].x << endl;
}
system("pause");
return 0;
}
输出结果:
1
2
3
4
5
1 hello c
2 c++ d
3 java e
4 python f
5 python3 p
发现与预设的一样结果证明三种赋值方法都起了作用
C++ 指针的引用
Note:理解指针时,应该将 数据类型* p看作指针变量的类型, 而不应该看成 数据类型 *p。 我长久以来都是第二种理解方法,这是不对的,也容易陷入误区。
如
1
2
int* p //应该将 int* 理解为一个整体
int *p //不应该将 *p 理解为一个整体
我们理解时,将p理解为一个 int* 的变量, 这样就不容易陷入误区。
C++中*\&(指针引用)与*(指针)的区别
*指针是一个存放地址的变量,指针引用指的是这个存放地址的变量的引用。
C++中如果参数不是引用的话,会调用参数对象的拷贝构造函数,所以如果有需求想改变指针所指的对象即想要改变指针变量里存放的地址,就要使用指针引用。
下面用一个测试例子和过程图结合进行说明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
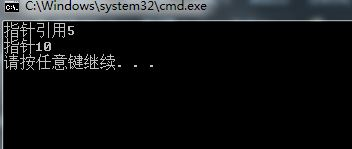
#include <iostream>
using namespace std;
struct Node {
int data;
};
void ChangeNode1(Node*& pnode) {
pnode = new Node;
pnode->data = 5;
}
void ChangeNode2(Node *pnode) {
pnode = new Node;
pnode->data = 5;
}
void Test1() {
Node *node = new Node;
node->data = 10;
ChangeNode1(node);
std::cout << "指针引用" << node->data << endl;
}
void Test2() {
Node *node = new Node;
node->data = 10;
ChangeNode2(node);
std::cout << "指针" << node->data << endl;
}
int main() {
Test1();
Test2();
return 0;
}
C/C++产生随机数
C++中没有自带的random函数,要实现随机数的生成就需要使用rand()和srand()。
不过,由于rand()的内部实现是用线性同余法做的,所以生成的并不是真正的随机数,而是在一定范围内可看为随机的伪随机数。
rand()
rand()会返回一随机数值, 范围在0至RAND_MAX 间。RAND_MAX定义在stdlib.h, 其值为2147483647。
srand()
srand()可用来设置rand()产生随机数时的随机数种子。通过设置不同的种子,我们可以获取不同的随机数序列。
可以利用srand((int)(time(NULL))的方法,利用系统时钟,产生不同的随机数种子。不过要调用time(),需要加入头文件< ctime >。
其他的随机数的范围通式
产生一定范围随机数的通用表示公式是:
要取得[0,n) 就是rand()%n 表示 从0到n-1的数
要取得[a,b)的随机整数,使用(rand() % (b-a))+ a;
要取得[a,b]的随机整数,使用(rand() % (b-a+1))+ a;
要取得(a,b]的随机整数,使用(rand() % (b-a))+ a + 1;
通用公式:a + rand() % n;其中的a是起始值,n是整数的范围。
要取得a到b之间的随机整数,另一种表示:a + (int)b * rand() / (RAND_MAX + 1)。
要取得0~1之间的浮点数,可以使用rand() / double(RAND_MAX)。
find用法
find函数主要实现的是在容器内查找指定的元素,并且这个元素必须是基本数据类型的。查找成功返回一个指向指定元素的迭代器,查找失败返回end迭代器。
例一, 在数组中查找:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <iostream>
#include <vector>
#include <algorithm>//注意要包含该头文件
using namespace std;
int main()
{
int nums[] = { 3, 1, 4, 1, 5, 9 };
int num_to_find = 5;
int start = 0;
int end = 5;
int* result = find( nums + start, nums + end, num_to_find );
if( result == nums + end )
{
cout<< "Did not find any number matching " << num_to_find << endl;
}
else
{
cout<< "Found a matching number: " << *result << endl;
}
return 0;
}
例二,在容器中查找:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main(){
vector<int> v;
int num_to_find=25;//要查找的元素,类型要与vector<>类型一致
for(int i=0;i<10;i++)
v.push_back(i*i);
vector<int>::iterator iter=std::find(v.begin(),v.end(),num_to_find);//返回的是一个迭代器指针
if(iter==v.end())
cout<<"ERROR!"<<endl;
else //注意迭代器指针输出元素的方式和distance用法
cout<<"the index of value "<<(*iter)<<" is " << std::distance(v.begin(), iter)<<std::endl;
return 0;
}
sort用法
sort(first_pointer,first_pointer+n,cmp)
参数1:第一个参数是数组的首地址,一般写上数组名就可以,因为数组名是一个指针常量。
参数2:第二个参数相对较好理解,即首地址加上数组的长度n(代表尾地址的下一地址)。
参数3:默认可以不填,如果不填sort会默认按数组升序排序。也就是1,2,3,4排序。也可以自定义一个排序函数,改排序方式为降序什么的,也就是4,3,2,1这样。
关键在于第三个cmp函数的用法,它返回一个bool类型,也就是说不管里面是怎么算的,它根据返回的True或者False进行排序。
注意cmp函数不能写在类里面。
stack用法
格式化输入输出
scanf
int scanf(char *format[,argument,…]);
scanf()函数返回成功赋值的数据项数,出错时则返回EOF。
格式化说明符:
格式字符 说明
%a 读入一个浮点值(仅C99有效)
%A 同上
%c 读入一个字符
%d 读入十进制整数
%i 读入十进制,八进制,十六进制整数
%o 读入八进制整数
%x 读入十六进制整数
%X 同上
%c 读入一个字符
%s 读入一个字符串
%f 读入一个浮点数
%F 同上
%e 同上
%E 同上
%g 同上
%G 同上
%p 读入一个指针
%u 读入一个无符号十进制整数
%n 至此已读入值的等价字符数
%[] 扫描字符集合
%% 读%符号
附加格式说明字符表
修饰符 说明
L/l 长度修饰符 输入”长”数据
h 长度修饰符 输入”短”数据
W 整型常数 指定输入数据所占宽度 \
- 星号 空读一个数据
hh,ll同上h,l但仅对C99有效
在用”%c”输入时,空格和“转义字符”均作为有效字符。
例:
scanf(“%c%c%c”,&c1,&c2,&c3);
输入:a□b□c↙
结果:a→c1,□→c2,b→c3 (其余被丢弃)
scanf()函数接收输入数据时,遇以下情况结束一个数据的输入:(不是结束该scanf函数,scanf函数仅在每一个数据域均有数据,并按回车后结束)。
① 遇空格、“回车”、“跳格”键。
② 遇宽度结束。
③ 遇非法输入。
空白字符
空白字符会使scanf()函数在读操作中略去输入中的一个或多个空白字符,空白符可以是space,tab,newline等等,直到第一个非空白符出现为止。
1
2
3
4
5
6
7
8
9
#include "stdio.h"
int main(void)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
printf("%d,%d,%d/n",a,b,c);
return 0;
}
运行时按如下方式输入三个值: 3□4□5 ↙(输入a,b,c的值) 3,4,5 (printf输出的a,b,c的值) (1) &a、&b、&c中的&是地址运算符,分别获得这三个变量的内存地址。 (2) “%d%d%d”是按十进值格式输入三个数值。输入时,在两个数据之间可以用一个或多个空格、tab键、回车键分隔。
以下是合法输入方式:
- 3□□4□□□□5↙
- 3↙ 4□5↙
- 3(tab键)4↙ 5↙
非空白字符
一个非空白字符会使scanf()函数在读入时剔除掉与这个非空白字符相同的字符。
scanf()函数不能正确接受有空格的字符串?如: I love you!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main()
{
char str[80];
char str1[80];
char str2[80];
scanf("%s",str);/*此处输入:I love you! */
printf("%s",str);
sleep(5);/*这里等待5秒,告诉你程序运行到什么地方*/
scanf("%s",str1);/*这两句无需你再输入,是对键盘盘缓冲区再扫描 */
scanf("%s",str2);/*这两句无需你再输入,是对键盘盘缓冲区再扫描 */
printf("/n%s",str1);
printf("/n%s",str2);
return 0;
}
输入:I love you!
输出:I
love
you!
scanf()扫描到”I”后面的空格就认为对str的赋值结束,并忽略后面的”love you!”.这里要注意是”love you!”还在键盘缓冲区(关于这个问题,网上我所见的说法都是如此,但是,我经过调试发现,其实这时缓冲区字符串首尾指针已经相等了,也就是说缓冲区清空了,scanf()函数应该只是扫描stdin流,这个残存信息是在stdin中)。
那么scanf()函数能不能完成这个任务?回答是:能!别忘了scanf()函数还有一个 %[] 格式控制符(如果对%[]不了解的请查看本文的上篇),请看下面的程序:
1
2
3
4
5
6
7
8
9
10
#include "stdio.h"
int main()
{
char string[50];
/*scanf("%s",string);不能接收空格符*/
scanf("%[^/n]",string);
printf("%s/n",string);
return 0;
}
键盘缓冲区残余信息问题
函数名: fflush
功 能: 清除一个流
用 法:
int fflush(FILE *stream);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <stdio.h>
int main()
{
int a;
char c;
do
{
scanf("%d",&a);
fflush(stdin);
scanf("%c",&c);
fflush(stdin);
printf("a=%d c=%c/n",a,c);
}while(c!='N');
}
如何处理scanf()函数误输入造成程序死锁或出错?
scanf()函数执行成功时的返回值是成功读取的变量数,也就是说,你这个scanf()函数有几个变量,如果scanf()函数全部正常读取,它就返回几。但这里还要注意另一个问题,如果输入了非法数据,键盘缓冲区就可能还个有残余信息问题。
cin
cin»
用法一:最常用、最基本的用法,输入一个数字:
用法二:接受一个字符串,遇“空格”、“Tab”、“回车”都结束
cin.get()
用法一:cin.get(字符变量名)可以用来接收字符
用法二:cin.get(字符数组名,接收字符数)用来接收一行字符串,可以接收空格
用法三:cin.get(无参数)没有参数主要是用于舍弃输入流中的不需要的字符,或者舍弃回车,弥补cin.get(字符数组名,接收字符数目)的不足.
cin.getline()
cin.getline() // 接受一个字符串,可以接收空格并输出
1
2
3
4
5
6
7
8
9
#include <iostream>
using namespace std;
main ()
{
char m[20];
cin.getline(m,5);
cout<<m<<endl;
}
输入:jkljkljkl
输出:jklj
接受5个字符到m中,其中最后一个为’\0’,所以只看到4个字符输出;
延伸:
cin.getline()实际上有三个参数,cin.getline(接受字符串到m,接受个数5,结束字符)
getline()
getline() // 接受一个字符串,可以接收空格并输出,需包含“#include<string>”
接受的字符串只能是string类型。
1
2
3
4
5
6
7
8
9
10
#include<iostream>
#include<string>
using namespace std;
main ()
{
string str;
getline(cin,str);
cout<<str<<endl;
}
输入:jkljkljkl
输出:jkljkljkl
输入:jkl jfksldfj jklsjfl
输出:jkl jfksldfj jklsjfl
和cin.getline()类似,但是cin.getline()属于istream流,而getline()属于string流,是不一样的两个函数
gets()
gets()// 接受一个字符串,可以接收空格并输出,需包含“#include<cstdio>”
接受的字符串只能是char类型。
1
2
3
4
5
6
7
8
9
10
11
#include<iostream>
#include<cstdio>
using namespace std;
main ()
{
char m[20];
gets(m); //不能写成m=gets();
cout<<m<<endl;
}
输入:jkljkljkl
输出:jkljkljkl
输入:jkl jkl jkl
输出:jkl jkl jkl
类似cin.getline()里面的一个例子,gets()同样可以用在多维数组里面:
getchar()
getchar()//接受一个字符,需包含“#include<cstdio>”
1
2
3
4
5
6
7
8
9
10
#include<iostream>
#include <cstdio>
using namespace std;
main ()
{
char ch;
ch=getchar(); //不能写成getchar(ch);
cout<<ch<<endl;
}
cin的条件状态
使用cin读取键盘输入时,难免发生错误,一旦出错,cin将设置条件状态(condition state)。条件状态标识符号为:
goodbit:无错误
eofbit:已到达文件尾
failbit:非致命的输入/输出错误,可挽回
badbit:致命的输入/输出错误,无法挽回
若在输入输出类里.需要加iOS::标识符号。与这些条件状态对应的就是设置、读取和判断条件状态的流对象的成员函数。他们主要有:
s.eof():若流s的eofbit置位,则返回true;
s.fail():若流s的failbit置位,则返回true;
s.bad():若流s的badbit置位,则返回true;
s.good():若流s的goodbit置位,则返回true;
s.clear(flags):清空状态标志位,并将给定的标志位flags置为1,返回void。
s.setstate(flags):根据给定的flags条件状态标志位,将流s中对应的条件状态位置为1,返回void。
s.rdstate():返回流s的当前条件状态,返回值类型为strm::iostate。strm::iostate 机器相关的整形名,由各个iostream类定义,用于定义条件状态。 \
了解以上关于输入流的条件状态与相关操作函数,下面看一个因输入缓冲区未读取完造成的条件状态位failbit被置位,再通过clear()复位的例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <iostream>
using namespace std;
int main()
{
char ch, str[20];
cin.getline(str, 5);
cout<<"flag1:"<<cin.good()<<endl; // 查看goodbit状态,即是否有异常
cin.clear(); // 清除错误标志
cout<<"flag1:"<<cin.good()<<endl; // 清除标志后再查看异常状态
cin>>ch;
cout<<"str:"<<str<<endl;
cout<<"ch :"<<ch<<endl;
system("pause");
return 0;
}
输入:12345[回车],输出结果为:
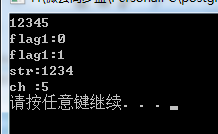
可以看出,因输入缓冲区未读取完造成输入异常,通过clear()可以清除输入流对象cin的异常状态。,不影响后面的cin»ch从输入缓冲区读取数据。因为cin.getline读取之后,输入缓冲区中残留的字符串是:5[换行],所以cin»ch将5读取并存入ch,打印输入并输出5。
如果将clear()注释,cin»ch;将读取失败,ch为空。 cin.clear()等同于cin.clear(ios::goodbit);因为cin.clear()的默认参数是ios::goodbit,所以不需显示传递,故而你最常看到的就是: cin.clear()。
cin清空输入缓冲区
从上文中可以看出,上一次的输入操作很有可能是输入缓冲区中残留数据,影响下一次的输入。那么如何解决这个问题呢?自然而然,我们想到了在进行输入时,对输入缓冲区进行清空和状态条件的复位。条件状态的复位使用clear(),清空输入缓冲区应该使用:
istream &ignore( streamsize num=1, int delim=EOF );
函数作用:跳过输入流中n个字符,或在遇到指定的终止字符时提前结束(此时跳过包括终止字符在内的若干字符)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <iostream>
using namespace std;
int main()
{
char str1[20]={NULL},str2[20]={NULL};
cin.getline(str1,5);
cin.clear(); // 清除错误标志
cin.ignore(numeric_limits<std::streamsize>::max(),'\n'); //清除缓冲区的当前行
cin.getline(str2,20);
cout<<"str1:"<<str1<<endl;
cout<<"str2:"<<str2<<endl;
system("pause");
return 0;
}
程序输入:12345[回车]success[回车],程序输出:
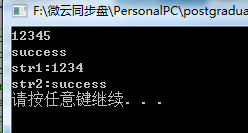
Note: (1)程序中使用cin.ignore清空了输入缓冲区的当前行,使上次的输入残留下的数据没有影响到下一次的输入,这就是ignore()函数的主要作用。其中,numeric_limits::max()不过是头文件定义的流使用的最大值,你也可以用一个足够大的整数代替它。 如果想清空输入缓冲区,去掉换行符,使用: cin.ignore(numeric_limits< std::streamsize>::max()); 清除cin里所有内容。
(2)cin.ignore();当输入缓冲区没有数据时,也会阻塞等待数据的到来。
(3)有个疑问,网上很多资料说调用cin.sync()即可清空输入缓冲区,经测试,VC++可以,但是在linux下使用GNU C++却不行,无奈之下,linux下就选择了cin.ignore()。
文件操作
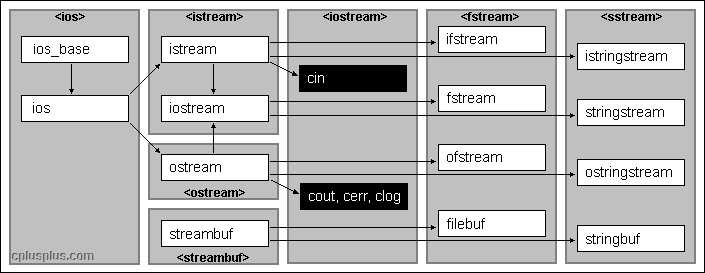
这里主要是讨论fstream的内容:
1
2
3
4
#include <fstream>
ofstream //文件写操作 内存写入存储设备
ifstream //文件读操作,存储设备读区到内存中
fstream //读写操作,对打开的文件可进行读写操作
打开文件
在fstream类中,成员函数open()实现打开文件的操作,从而将数据流和文件进行关联,通过ofstream,ifstream,fstream对象进行对文件的读写操作
函数:open()
1
2
3
4
5
6
7
8
public member function
void open ( const char * filename,
ios_base::openmode mode = ios_base::in | ios_base::out );
void open(const wchar_t *_Filename,
ios_base::openmode mode= ios_base::in | ios_base::out,
int prot = ios_base::_Openprot);
参数:
- filename: 操作文件名
- mode: 打开文件的方式
- prot : 打开文件的属性 //基本很少用到,在查看资料时,发现有两种方式
打开文件的方式在ios类(所以流式I/O的基类)中定义,有如下几种方式:
| 方式 | 功能 |
|---|---|
| ios::in | 为输入(读)而打开文件 |
| ios::out | 为输出(写)而打开文件 |
| ios::ate | 初始位置:文件尾 |
| ios::app | 所有输出附加在文件末尾 |
| ios::trunc | 如果文件已存在则先删除该文件 |
| ios::binary | 二进制方式 |
| 这些方式是能够进行组合使用的,以“或”运算(“ | ”)的方式:例如 |
1
2
ofstream out;
out.open(”Hello.txt”, ios::in|ios::out|ios::binary) //根据自己需要进行适当的选取
打开文件的属性也可以使用“或”运算和“+”进行组合使用
很多程序中,可能会碰到ofstream out(“Hello.txt”), ifstream in(“…”),fstream foi(“…”)这样的的使用,并没有显式的去调用open()函数就进行文件的操作,直接调用了其默认的打开方式,因为在stream类的构造函数中调用了open()函数,并拥有同样的构造函数,所以在这里可以直接使用流对象进行文件的操作,默认方式如下:
1
2
3
ofstream out("...", ios::out);
ifstream in("...", ios::in);
fstream foi("...", ios::in|ios::out);
当使用默认方式对文件的操作时吗,你可以使用成员函数is_open()对文件是否打开进行验证。
关闭文件
当文件读写操作完成之后,我们必须将文件关闭以使文件重新变为可访问的。成员函数close(),它负责将缓存中的数据排放出来并关闭文件。这个函数一旦被调用,原先的流对象就可以被用来打开其它的文件了,这个文件也就可以重新被其它的进程所访问了。为防止流对象被销毁时还联系着打开的文件,析构函数将会自动调用关闭函数close。
文本文件的读写
类ofstream, ifstream 和fstream 是分别从ostream, istream 和iostream 中引申而来的。这就是为什么 fstream 的对象可以使用其父类的成员来访问数据。
一般来说,我们将使用这些类与同控制台(console)交互同样的成员函数(cin 和 cout)来进行输入输出。如下面的例题所示,我们使用重载的插入操作符«:
1
2
3
4
5
6
7
8
9
10
11
12
13
// writing on a text file
#include <fiostream.h>
int main () {
ofstream out("out.txt");
if (out.is_open())
{
out << "This is a line.\n";
out << "This is another line.\n";
out.close();
}
return 0;
}
结果: 在out.txt中写入:
This is a line.
This is another line
从文件中读入数据也可以用与 cin»的使用同样的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// reading a text file
#include <iostream.h>
#include <fstream.h>
#include <stdlib.h>
int main () {
char buffer[256];
ifstream in("test.txt");
if (! in.is_open())
{ cout << "Error opening file"; exit (1); }
while (!in.eof() )
{
in.getline (buffer,100);
cout << buffer << endl;
}
return 0;
}
结果 在屏幕上输出
This is a line.
This is another line
上面的例子读入一个文本文件的内容,然后将它打印到屏幕上。注意我们使用了一个新的成员函数叫做eof ,它是ifstream 从类 ios 中继承过来的,当到达文件末尾时返回true 。
**使用vc6.0的那种#include
从 Visual C++ .NET 2003 开始,移除了旧的 iostream 库。
标准 C++ 库和以前的运行时库之间的主要差异在于 iostream 库。iostream 实现的具体细节已经更改,如果想链接标准 C++ 库,可能有必要重写代码中使用 iostream的部分。
必须移除任何包含在代码中的旧 iostream 头文件(fstream.h、iomanip.h、ios.h、iostream.h、istream.h、ostream.h、streamb.h 和 strstrea.h),并添加一个或多个新的标准 C++ iostream 头文件(<fstream>、<iomanip>、<ios>、<iosfwd>、<iostream>、<istream>、<ostream>、<sstream>、<streambuf> 和 <strstream>,所有头文件都没有 .h 扩展名)。
在新的标准 C++ iostream 库中:
- open 函数不采用第三个参数(保护参数)。
- 无法从文件句柄创建流。
- 除了几个例外,新的标准 C++ 库中的所有名称都在 std 命名空间中。有关更多信息,请参见使用 C++ 库头。
- 单独用 ios::out 标志无法打开 ofstream 对象。ios::out 标志必须在逻辑 OR 中和另一个 ios 枚举数组合;比如,和 ios::in 或 ios::app 组合。
- 因为设置了 eofbit 状态,到达文件尾后 ios::good 不再返回非零值。 除非知道当前没有设置基标志,否则 ios::setf(_IFlags)
不应和 ios::dec、ios::oct 或 ios::hex 的标志值一起使用。格式化的输入/输出函数和运算符假定只设置了一个基。改用 ios_base。
按行读取字符串,并(追加)写入另一个文件
注意:ifstream和ofstream的定义,ofstream里的ios::app,以及getline函数,“«”重定向的使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main()
{
ifstream myfile("in.txt");
ofstream outfile("out.txt",ios::app); //ios::app指追加写入
string temp;
while(getline(myfile,temp)) //按行读取字符串
{
outfile<<temp;//写文件
outfile<<endl;
}
myfile.close();
outfile.close();
return 0;
}
(重要)读取数字
!myfile.eof()和重定向符号的使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int a[1005];
int b[1005];
int main()
{
ifstream myfile("in.txt");
int i=0;
while(!myfile.eof()) //直到文件结尾
{
myfile>>a[i]>>b[i];
i++;
}
myfile.close();
cout<<a[0]<<" "<<b[0]<<endl;
return 0;
}
(重要)分段读数字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int a[1005];
int b[1005];
int main()
{
ifstream myfile("in.txt");
int N;
myfile>>N;
for(int i=0;i<N;i++)
{
myfile>>a[i]>>b[i];
}
myfile.close();
cout<<a[0]<<" "<<b[0]<<endl;
cout<<a[1]<<" "<<b[1]<<endl;
return 0;
}
friend
函数后加const
一些成员函数不改变类的数据成员,这些函数是”只读”函数, 如果把不改变数据成员的函数都加上const关键字进行标识,显然,可提高程序的可读性。
其实,它还能提高程序的可靠性,已定义成const的成员函数,一旦企图修改数据成员的值,则编译器按错误处理。
new & delete
new
在自由空间分配的内存是无名的, 因此 new 无法为其分配的对象命名, 而是返回一个指向该对象的指针:
1
int *pi = new int; // pi指向一个动态分配的、未初始化的无名对象
volatile
1
2
3
4
5
volatile int i=10;
int a = i;
...
// 其他代码,并未明确告诉编译器,对 i 进行过操作
int b = i;
volatile 指出 i 是随时可能发生变化的,每次使用它的时候必须从 i的地址中读取,因而编译器生成的汇编代码会重新从i的地址读取数据放在 b 中。而优化做法是,由于编译器发现两次从 i读数据的代码之间的代码没有对 i 进行过操作,它会自动把上次读的数据放在 b 中。而不是重新从 i 里面读。这样以来,如果 i是一个寄存器变量或者表示一个端口数据就容易出错,所以说 volatile 可以保证对特殊地址的稳定访问。
foreach
c++中的 for_each 函数
for_each()事实上是個 function template
1
2
3
4
5
template<typename InputIterator, typename Function>
Function for_each(InputIterator beg, InputIterator end, Function f) {
while(beg != end)
f(*beg++);
}
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// for_each example
#include <iostream> // std::cout
#include <algorithm> // std::for_each
#include <vector> // std::vector
void myfunction (int i) { // function:
std::cout << ' ' << i;
}
struct myclass { // function object type:
void operator() (int i) {std::cout << ' ' << i;}
} myobject;
int main () {
std::vector<int> myvector;
myvector.push_back(10);
myvector.push_back(20);
myvector.push_back(30);
std::cout << "myvector contains:";
for_each (myvector.begin(), myvector.end(), myfunction);
std::cout << '\n';
// or:
std::cout << "myvector contains:";
for_each (myvector.begin(), myvector.end(), myobject);
std::cout << '\n';
return 0;
}
结果:
1
2
myvector contains: 10 20 30
myvector contains: 10 20 30
C++11之for循环的新用法
C++使用如下方法遍历一个容器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
遍历vector容器
#include<iostream>
#include<vector>
int main()
{
std::vector<int> arr;
arr.push_back(1);
arr.push_back(2);
for (auto it = arr.begin(); it != arr.end(); it++)
{
std::cout << *it << std::endl;
}
return 0;
}
其中auto用到了C++11的类型推导。同时我们也可以使用std::for_each完成同样的功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include<algorithm>
#include<iostream>
#include<vector>
void func(int n)
{
std::cout << n << std::endl;
}
int main()
{
std::vector<int> arr;
arr.push_back(1);
arr.push_back(2);
std::for_each(arr.begin(), arr.end(), func);
return 0;
}
现在C++11的for循环有了一种新的用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include<iostream>
#include<vector>
int main()
{
std::vector<int> arr;
arr.push_back(1);
arr.push_back(2);
for (auto n : arr)
{
std::cout << n << std::endl;
}
return 0;
}
上述方式是只读,如果需要修改arr里边的值,可以使用for(auto& n:arr),for循环的这种使用方式的内在实现实际上还是借助迭代器的,所以如果在循环的过程中对arr进行了增加和删除操作,那么程序将对出现意想不到的错误。
swap
C++提供了一个swap函数用于交换
swap 包含在命名空间std 里面
1
2
3
4
5
6
7
8
9
10
#include<iostream>
using namespace std;
int main()
{
float a = 3.123456,b = 1234567.000000;
swap(a,b);
cout<<fixed;
cout<<a<<"->"<<b<<endl;
return 0;
}
switch case
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <iostream>
using namespace std;
int main()
{
char choice;
cout << "Enter A, B, or C: ";
cin >> choice;
switch (choice)
{
case 'A' :
cout<< "You entered A. \n";
break;
case 'B' :
cout << "You entered B. \n";
break;
case 'C' :
cout << "You entered C.\n";
break;
default:
cout << "You did not enter A, B, or C!\n";
}
return 0;
}
注意, 每个case后 需要 break 出去, 否则会将所有case全部执行。
运算符的优先级

位运算
求二进制 最靠近右边的第一个 1
x \& ~x 表示 二进制 x 最靠近右边的第一个 1。
1
2
3
4
5
6
7
8
9
10
-x 的表示是 x 的补码 ~x + 1
x = 11010101000
-x = 00101011000
x & -x = 00000001000
x & -x 表示 二进制最靠右边的第一个1
如果x为2的整数次幂 那么 x & -x == x
如果x不为2的整数次幂 那么 x & -x < x
统计二进制中 1 的个数
1
2
3
// 循环右移, 统计i中 1 的个数
int s = 0;
for (int k = i; k; k >>= 1) s += k & 1;
异或运算的性质
1
2
a ^ a = 0
0 ^ a = a
异或运算为不进位加法运算, 它满足交换律和结合律。
accumulate
accumulate定义在#include<numeric>中,作用有两个,一个是累加求和,另一个是自定义类型数据的处理
累加求和
1
int sum = accumulate(vec.begin() , vec.end() , 42);
accumulate带有三个形参:头两个形参指定要累加的元素范围,第三个形参则是累加的初值。
accumulate函数将它的一个内部变量设置为指定的初始值,然后在此初值上累加输入范围内所有元素的值。accumulate算法返回累加的结果,其返回类型就是其第三个实参的类型。
可以使用accumulate把string型的vector容器中的元素连接起来:
1
string sum = accumulate(v.begin() , v.end() , string(" "));
这个函数调用的效果是:从空字符串开始,把vec里的每个元素连接成一个字符串。
自定义数据类型的处理
C++ STL中有一个通用的数值类型计算函数— accumulate(),可以用来直接计算数组或者容器中C++内置数据类型,例如:
1
2
3
4
#include <numeric>
int arr[]={10,20,30,40,50};
vector<int> va(&arr[0],&arr[5]);
int sum=accumulate(va.begin(),va.end(),0); //sum = 150
但是对于自定义数据类型,我们就需要自己动手写一个回调函数来实现自定义数据的处理,然后让它作为accumulate()的第四个参数,accumulate()的原型为
1
2
3
4
5
6
7
8
9
template<class _InIt,
class _Ty,
class _Fn2> inline
_Ty _Accumulate(_InIt _First, _InIt _Last, _Ty _Val, _Fn2 _Func)
{ // return sum of _Val and all in [_First, _Last), using _Func
for (; _First != _Last; ++_First)
_Val = _Func(_Val, *_First);
return (_Val);
}
例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <vector>
#include <string>
using namespace std;
struct Grade
{
string name;
int grade;
};
int main()
{
Grade subject[3] = {
{ "English", 80 },
{ "Biology", 70 },
{ "History", 90 }
};
int sum = accumulate(subject, subject + 3, 0, [](int a, Grade b){return a + b.grade; });
cout << sum << endl;
system("pause");
return 0;
}
1
2
3
4
5
6
7
class Solution {
public:
int minElements(vector<int>& nums, int limit, int goal) {
long long sum = accumulate(nums.begin(), nums.end(), 0ll);
return (abs(sum - goal) + limit - 1) / limit;
}
};
这里的 0ll 后面是 l 不是 1, 表示是个long long型的数。
多线程
OpenMP
编译报错
1
2
OpenMP_1.cpp:(.text+0x1c): undefined reference to `omp_get_num_threads'
OpenMP_1.cpp:(.text+0x24): undefined reference to `omp_get_thread_num'
需要再编译命令后加 -fopenmp
g++ -program.c -o obj -fopenmp
With gcc, you need to compile and link with -fopenmp to enable OpenMP. Other compilers have different options; with intel it’s -openmp, with pgi it’s -mp, etc.
OpenMP计时函数
- clock()函数
原型:clock_t clock();
MSDN中的定义:Returns the processor time consumed by the program,返回的是处理器执行的时间,也就是说,只要内核中有程序在cpu中运行,时间就会增加,使用多核并行化技术并不能并行地计算使用的时间,仍然是进行叠加
返回值:返回时钟周期,要转化成时间需要除以常量宏CLOCKS_PER_SEC
1
2
3
4
5
clock_t time_start = clock();
clock_t time_end = clock();
cout << "OMP time use: " << 1000 * (time_end - time_start) / (double)CLOCKS_PER_SEC << "ms" << endl;
- omp_get_wtime()函数
原型:double omp_get_wtime();
MSDN中的定义:Returns a value in seconds of the time elapsed from some point,返回的是一个观察点的时间值,这个时间将一直在程序运行时持续,也就是说,在程序运行前使用和程序运行结束使用,这个时间差是整个程序运行的时间,而不是clock得到的cpu运行的时间
返回值:返回一个绝对时间值,单位是秒
1
2
3
4
5
double time_start = omp_get_wtime();
double time_end = omp_get_wtime();
cout << "OMP time use: " << (time_end - time_start) << " s" << endl;
pthread
pthread_create
函数简介
pthread_create是UNIX环境创建线程函数
头文件
#include
函数声明
1
int pthread_create(pthread_t *restrict tidp,const pthread_attr_t *restrict_attr,void*(*start_rtn)(void*),void *restrict arg);
返回值
若成功则返回0,否则返回出错编号
参数
第一个参数为指向线程标识符的指针。
第二个参数用来设置线程属性。
第三个参数是线程运行函数的地址。
最后一个参数是运行函数的参数。
注意
在编译时注意加上-lpthread参数,以调用静态链接库。因为pthread并非Linux系统的默认库。
pthread_join
函数简介
函数pthread_join用来等待一个线程的结束。
函数原型为:
1
extern int pthread_join __P (pthread_t __th, void **__thread_return);
参数:
第一个参数为被等待的线程标识符
第二个参数为一个用户定义的指针,它可以用来存储被等待线程的返回值。
注意
这个函数是一个线程阻塞的函数,调用它的函数将一直等待到被等待的线程结束为止,当函数返回时,被等待线程的资源被收回。如果执行成功,将返回0,如果失败则返回一个错误号。
MPI
ubuntu安装mpi
1
sudo apt-get intall mpich
MPI_Init
使用 MPI_Init 函数初始化并行计算环境;
MPI_Comm_size
使用 MPI_Comm_size 函数返回指定通信器中进程的数目;
MPI_Comm_rank
使用 MPI_Comm_rank 函数返回指定通信器中本进程的进程号;
MPI_Finalize
使用 MPI_Finalize 退出并行计算环境,并行程序结束;
点对点通信(point to point communication)
阻塞型: MPI_Send 和 MPI_Recv。
MPI_Send 函数返回时表明数据已经发出或已被MPI系统复制,随后对发送缓冲区的修改不会影响所发送的数据。而MPI_Recv 返回时,则表明数据已经接收到并且可以立即使用。阻塞型函数的操作是非局部的,它的完成可能需要与其他进程进行通信。
非阻塞型: MPI_Isend 和 MPI_Irecv。
非阻塞型函数调用总是立即返回,而实际操作则由MPI 系统在后台进行。在调用了 一 个 非 阻 塞 型 通 信 函 数 后 , 用 户 必 须 随 后 调 用 其 他 函 数 , 如 MPI_Wait 或MPI_Test 等,来等待操作完成或查询操作的完成情况。
聚合通信(collective communication)
- 一对多通信: 广播 MPI_Bcast
- 多对一通信:数据收集 MPI_Gather
- 多对多通信:全交换 MPI_Alltoall

- 从一个进程到本组内的所有进程的播送broadcast
- 从本组所有进程收集数据到一个进程gather
- 从一个进程分散数据到本组内的所有进程sactter
- 求和,最大值,最小值及用户定义的函数等的reduce操作
编译
C语言:
1
mpicc cpi.c -o cpi
C++:
1
mpicxx cpi.cpp -o cpi
运行
1
mpirun -np 2 ./cpi
cuda
将cuda程序命名为 “xxx.cu”
编译:
1
nvcc -o helloworld helloworld.cu
概念
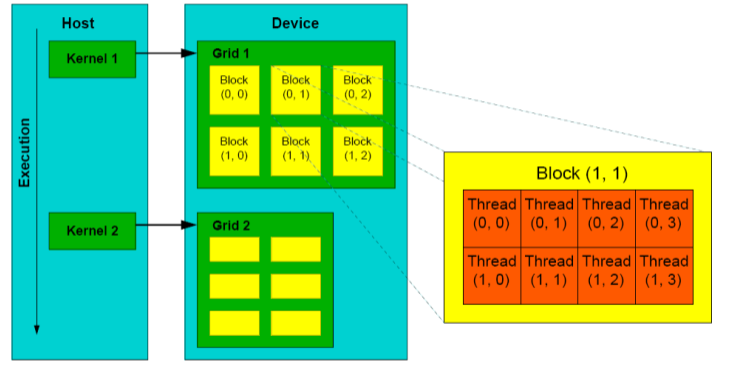
Host 的 Kernel 对应 Device 的Grid, Grid中有许多Block, 每个Block里有诸多线程
程序员设计Tread Block:
- 一个Block有512(1024, 2048)个线程
- Block的形状可以是1D, 2D或者3D
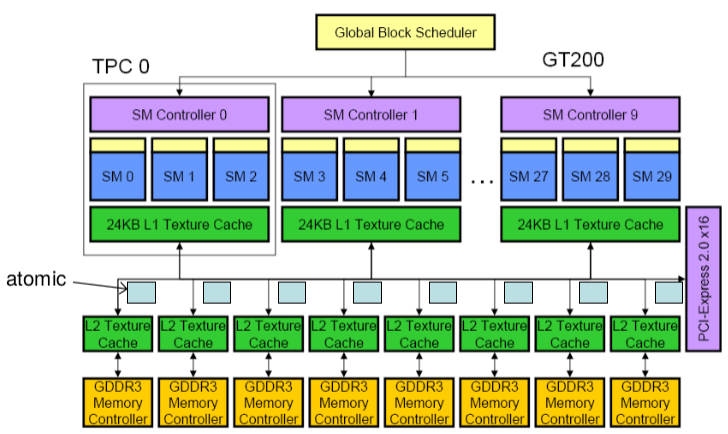
SP(Streaming Processor):流处理器, CUDA Core
SPA(Streaming Processor Array): 流处理器阵列
SM:
- Streaming Multiprocessor (32 SP)
- Multi-threaded processor core
- Fundamental processing unit for CUDA thread block
TPC/GPC:
- Texture (Graphics) Processor Cluster
- 3 SM + TEX

Streaming Multiprocessor(SM)有32个流处理器SP, 4个Super Fuction Units(SFU)
多线程指令调度:
- 1 对应512(1024, 2048)活跃线程
- 每32个线程共享指令
64K共享内存/L1 Cache
从硬件上看:
- SP: 最基本的处理单元,streaming processor,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
- SM: 多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。
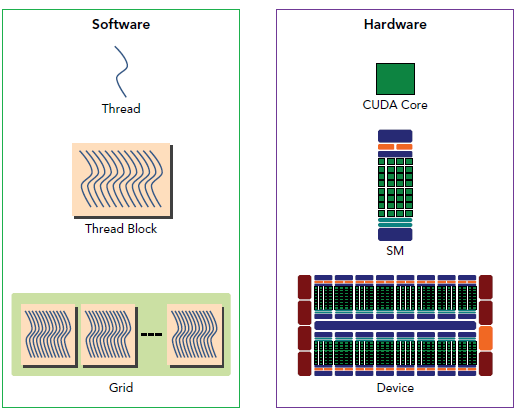
从软件上看:
- thread:一个CUDA的并行程序会被以许多个threads来执行
- block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
- grid:多个blocks则会再构成grid。
- warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMT。
对应关系:
- 从软件上看,SM更像一个独立的CPU core。SM(Streaming Multiprocessors)是GPU架构中非常重要的部分,GPU硬件的并行性就是由SM决定的。
GPU中每个sm都设计成支持数以百计的线程并行执行,并且每个GPU都包含了很多的SM,所以GPU支持成百上千的线程并行执行。当一个kernel启动后,thread会被分配到这些SM中执行。大量的thread可能会被分配到不同的SM,同一个block中的threads必然在同一个SM中并行(SIMT)执行。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread。
一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是调度和运行的基本单元。warp中所有threads并行的执行相同的指令。一个warp需要占用一个SM运行,多个warps需要轮流进入SM。由SM的硬件warp scheduler负责调度。目前每个warp包含32个threads(Nvidia保留修改数量的权利)。所以,一个GPU上resident thread最多只有 SM*warp个。
SIMT和SIMD:
CUDA是一种典型的SIMT架构(单指令多线程架构),SIMT和SIMD(Single Instruction, Multiple Data)类似,SIMT应该算是SIMD的升级版,更灵活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通过将同样的指令广播给多个执行官单元来实现并行。一个主要的不同就是,SIMD要求所有的vector element在一个统一的同步组里同步的执行,而SIMT允许线程们在一个warp中独立的执行。SIMT有三个SIMD没有的主要特征:
- 每个thread拥有自己的instruction address counter
- 每个thread拥有自己的状态寄存器
- 每个thread可以有自己独立的执行路径
前面已经说block是软件概念,一个block只会由一个sm调度,程序员在开发时,通过设定block的属性,“告诉”GPU硬件,我有多少个线程,线程怎么组织。而具体怎么调度由sm的warps scheduler负责,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个blocks,但需要序列执行。下图显示了软件硬件方面的术语对应关系:
需要注意的是,大部分threads只是逻辑上并行,并不是所有的thread可以在物理上同时执行。例如,遇到分支语句(if else,while,for等)时,各个thread的执行条件不一样必然产生分支执行,这就导致同一个block中的线程可能会有不同步调。另外,并行thread之间的共享数据会导致竞态:多个线程请求同一个数据会导致未定义行为。CUDA提供了cudaThreadSynchronize()来同步同一个block的thread以保证在进行下一步处理之前,所有thread都到达某个时间点。
同一个warp中的thread可以以任意顺序执行,active warps被sm资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以该新调度的warp的状态已经存储在SM中了。不同于CPU,CPU切换线程需要保存/读取线程上下文(register内容),这是非常耗时的,而GPU为每个threads提供物理register,无需保存/读取上下文。
函数修饰符 和 变量修饰符
函数修饰符:
__global__,只能在GPU上运行,可以从CPU或者GPU调用
__device__,只能在GPU上运行,只能从GPU调用
变量修饰符:
__device__,存放在GPU的全局存储器,同一个grid里面的所有线程都可以直接访问,CPU端需要调用库函数来访问
__managed__,可以从CPU、GPU访问
cuda程序层次结构
grid 和 block 都是定义为dim3类型的变量。
dim3可以看成是包含三个无符号整数$(x, y, z)$成员的结构体变量, 在定义时,缺省值初始化为1。
grid和block可以灵活地定义为1-dim, 2-dim以及3-dim结构。
kernel在调用时也必须通过执行配置«<grid, block»>来指定kernel所使用的线程数及结构。
不同的GPU架构,grid和block的维度有限制。
cuda程序调用:
1
2
3
4
5
6
7
8
9
10
11
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<<grid, block>>>(prams...);
dim3 grid(128);
dim3 block(256);
kernel_fun<<<grid, block>>>(prams...);
dim3 grid(100, 120, 32);
dim3 block(16, 16, 4);
kernel_fun<<<grid, block>>>(prams...);
一个线程需要两个内置的坐标变量(blockIdx, threadIdx) 来唯一标识, 它们都是dim3类型变量, 其中blockIdx指明线程所在grid中的位置, 而threadIdx指明线程所在block中的位置
threadIdx包含三个值: threadIdx.x, threadIdx.y, trheadIdx.z
blockIdx同样包含三个值: blockIdx, blockIdx.y, blockIdx.z
逻辑顺序: x>y>z
cuda 程序执行与硬件映射
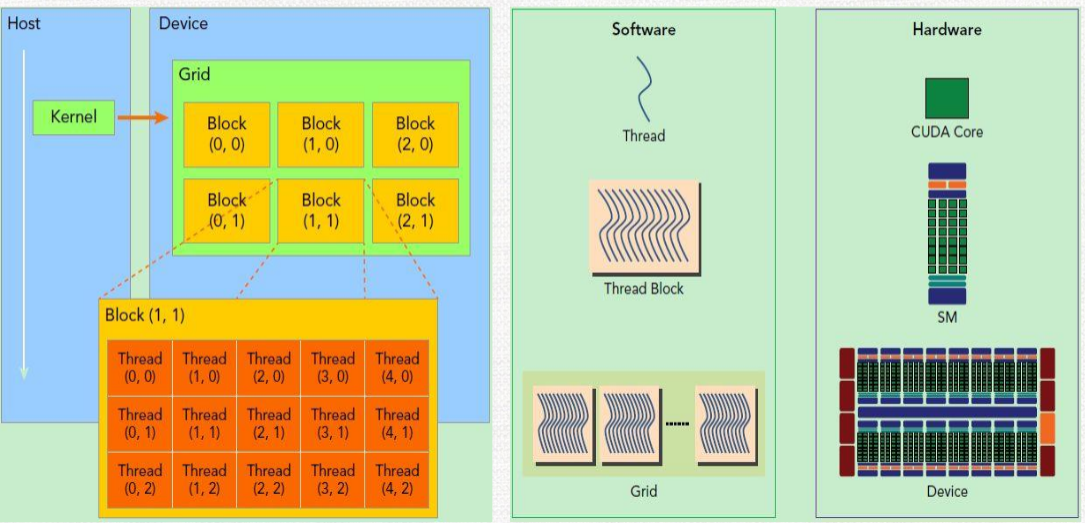
kernel 的线程组织层次, 那么一个kernel实际上会启动很多线程, 这些线程是逻辑上并行的, 但是在物理层却并不一定。
GPU硬件的一个核心组件是SM。
SM的核心组件包括CUDA核心,共享内存,寄存器等, SM可以并发地执行数百个线程,兵法能力就取决于SM所拥有的资源数。
当一个kernel被执行时, 它的grid中的线程块被分配到SM上, 一个线程块只能在一个SM上被调度。
SM一般可以调度多个线程块。 那么有可能一个kernel的各个线程块被分配多个SM, 所以grid只是逻辑层, 而SM才是执行的物理层。
WARP技术细节
SM采用的是SIMT(Single-Instruction Multi-Thread, 但指令多线程)架构, 基本的执行单元是线程数(warp), 线程束包含32个线程。
线程同时执行相同的指令, 但是每个线程都包含自己的指令地址计数器和寄存器状态, 也有自己独立的执行路径。
程数中的线程同时从同一程序地址执行,但是可能具有不同的行为, 比如遇到了分支结构, 一些线程可能进入这个分支, 但是另外一些有可能不执行,它们只能死等。
GPU规定线程束中所有线程在同一周期执行相同的指令, 线程束分化会导致性能下降。
极小化命令的分化。
性能优化
当线程块被划分到某个SM上时, 它将进一步划分为多个线程束(warp), 它才是SM的基本执行单元。
因为资源限制, 一个SM同时并发的线程束数是有限的。SM要为每个线程块分配共享内存, 而也要为每个线程束中的线程分配独立的寄存器。所以SM的配置会影响其所支持的线程块和线程束并发数量。
网格和线程块只是逻辑划分, 一个kernel的所有线程其实在物理层是不一定同时并发的。
kernel的grid和block的配置不同,性能会出现差异。 由于SM的基本执行单元是包含32线程的线程束, 所以block大小一般要设置为32的倍数。
GPU内存
每个线程都有自己的私有本地内存(Local Memory)。
每个线程块有包含共享内存(Shared Memory), 可以被线程块中所有线程共享, 其生命周期与线程块一致。
所有的线程都可以访问全局内存(Global Memory)
访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)
L1 cache, L2 cache
共享内存是块内线程可见的,所以有竞争问题的存在, 可以使用同步语句:
1
void __syncthreads();
但是,频繁使用__syncthreads会影响内核执行效率.
共享内存分成相同大小的内存块, 实现高速并行访问
bank:是一种划分方式。 在cpu中, 访存是访问某个地址, 获得地址上的数据, 但是在这里, 是一次性访问banks数量的地址, 获得这些地址上的所有数据, 并逻辑映射到不同的bank上。类似内存读取的控制。
为了实现内存高带宽的同时访问, shared memory被划分称了可以同时访问的等大小内存块(banks)。 因此, 内存读写n个地址的行为则可以以b个独立的bank同时操作的方式进行, 这样有效带宽就提高到了一个bank的b倍。
如果多个线程请求的内存地址被映射到了同一个bank上, 那么这些请求就变成了穿行的(serialized)。硬件将把这些请求分成x个没有冲突的请求序列, 带宽就降成了原来的x分之一。 但是如果一个warp内的所有线程都访问同一内存地址的话, 会产生一次广播(broadcast), 这些请求会一次完成。 计算能力2.0及以上的设备也具有组播(multicast)能力, 可以同时响应同一个warp内访问同一个内存地址的部分线程的请求。
内存分配:
1
cudaError_t cudaMallocHost(void **devPtr, size_t size)
内存释放:
1
cudaError_t cudaFreeHost(void *devPtr)
统一(Unified)内存分配释放
内存分配
1
cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flags=cudaMemAttachGlobal)
- flags = cudaMemAttachGlobal: 内存可以被任意处理器访问(CPU、GPU)
- flag = cudaMemAttatchGHost: 只可以被CPU访问
内存释放:
1
cudaError_t cudaFree(void *devPtr)
CPU与GPU内存同步拷贝
1
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, cudaMemcpyKind kind)
kind: cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice, or cudaMemcpyDefault
CPU与GPU内存异步拷贝
1
cudaError_t cudaMemcpyAsync(void *dst, const void *src, size_t count, cudaMemcpyKind kind, cudaStream_t steam = 0)
kind: cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice, or cudaMemcpyDefault
共享内存
1
2
3
4
5
6
7
8
9
10
11
12
// Size Known at compile time
__global__ void kernel(...){
...
__shared__float sData[256];
...
}
int main(void){
...
kernel<<<nBlocks.blockSize>>>(...);
...
}
1
2
3
4
5
6
7
8
9
10
11
12
13
// Size known at kernel launch
__global__ void kernel(...){
...
extern __shared__float sData[];
...
}
int main(void){
...
smBytes = blockSize * sizeof(float);
kernel<<<nBlocks, blockSize, smBytes>>>(...);
...
}
CUDA线程索引计算
用公式表示:最终的线程Id = blockId * blockSize + threadId
- blockId :当前 block 在 grid 中的坐标(可能是1维到3维)
- blockSize :block 的大小,描述其中含有多少个 thread
- threadId :当前 thread 在 block 中的坐标(同样从1维到3维)
grid 中 含有若干个 blocks,其中 blocks 的数量由 gridDim.x/y/z 来描述。某个 block 在此 grid 中的坐标由 blockIdx.x/y/z 描述。
blocks 中含有若干个 threads,其中 threads 的数量由 blockDim.x/y/z 来描述。某个 thread 在此 block 中的坐标由 threadIdx.x/y/z 描述。
接着一个多维的坐标如何用一维数据表达呢?这里大家想一想两位数和三位数,就是很好的例子。数字 = 百位数字 * 100 + 十位数字 * 10 + 个位数字。
当我们得知每个维度上的大小时,就可以利用这样的进制将三维坐标转换为1维坐标。
一般来说坐标(x, y, z)分别所在的维度大小是(Dx, Dy, Dz),一般会把 z 看成高纬度,接着是 y ,最后是 x。
高维度坐标转一维坐标公式 $id = Dx * Dy * z + Dx * y + x$
指令分化问题(warp divergent)
因为32个线程为一个warp, 如果32个warp中指令不相同的话,会导致串行的计算,降低计算效率。
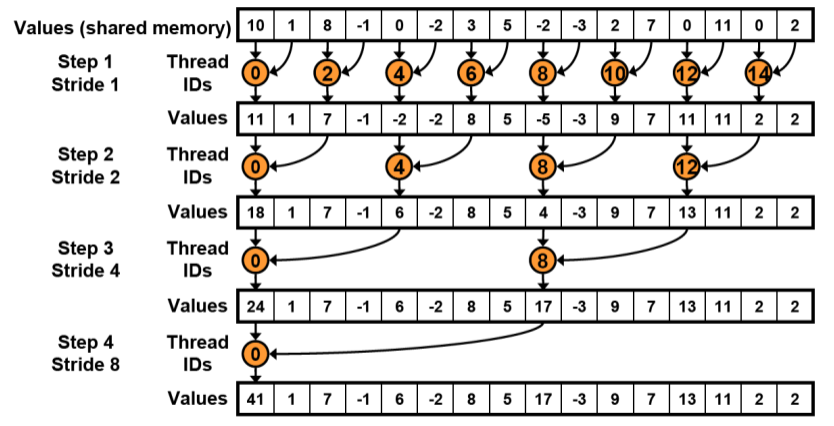
这种情况线程是跳着的,会导致warp的指令不同, 分化产生。
共享内存访问冲突
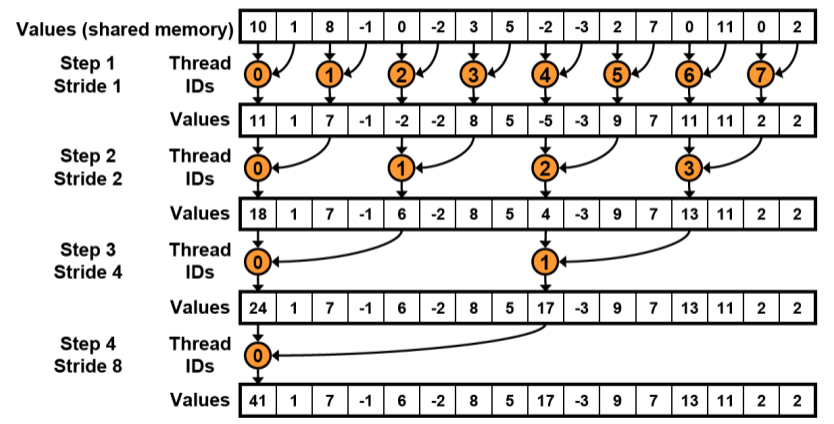
这种情况,当前的线程访问的内存可能不在对应的bank, 比如16线程访问的是31和32的内存。
在共享内存中,连续的32-bits字被分配到连续的32个bank中,这就像电影院的座位一样:一列的座位就相当于一个bank,所以每行有32个座位,在每个座位上可以“坐”一个32-bits的数据(或者多个小于32-bits的数据,如4个char型的数据,2个short型的数据);而正常情况下,我们是按照先坐完一行再坐下一行的顺序来坐座位的,在shared memory中地址映射的方式也是这样的

其中0-31为bank编号,如果申请一个共享内存数组__shared__ int cache[64],int 恰好为4个字节,那么cache[0]访问bank[0][0], cache[1]访问bank[0][1],…,cache[31]访问bank[0][31],cache超过32时,cache就会去访问下一行的bank,即cache[32]就会访问bank[1][0],以此类推。
bank冲突就是在这样的条件下产生,即如果一个warp的多个线程访问同一个bank的不同字段时(注:不同字段如bank[0][0],bank[1][0],…,bank[n][0]),那么就发生了bank冲突,因为不同bank可以同时访问,而当如果多个线程请求的内存地址被映射到了同一个bank上,那么这些请求就变成了串行的。
如果 half-warp 请求访问的多个地址位于同一个 bank 中,就出现了 bank conflic。
bank 的组织方式是:每个 bank 的宽度固定为 32bit,相邻的 32bit 字被组织在相邻的 bank中,每个 bank 在每个时钟周期可以提供 32bit 的带宽。
对于计算能力 1.x 设备,每个 warp 大小都是 32 个线程,而一个 SM 中的 shared memory 被划分为 16 个 bank(按 0~15 编号)。一个 warp 中的线程对共享存储器的访问请求会被划分为两个 half-warp 的访问请求, 只有处于同一 half-warp 内的线程才可能发生 bank conflict,而一个 warp 中位于前 half-warp 的线程与位于后 half-warp 的线程间则不会发生 bank conflict。
1
2
__shared__ float shared[32];
float data = shared[BaseIndex + s * tid];
在这段代码中,如果 s*n 是 m(m 是 bank 数)的倍数,或者 n 是 m/d (其中 d 是 m 和 s 的最大公约数)的倍数,就会发生 bank conflict。因此,只要 half-warp 小于或者等于 m/d,就不会发生 bank conflict。对于计算能力 1.x 的硬件,当 d=1 或者 s 为奇数(因为 m 是 2 的幂)时,就可以避免 bank conflict 的发生。
如果每个线程访问的数据大小不是 32bit 时,也会发生 bank conflict。例如以下对 char 数组的访问会造成 4-way bank conflict:
1
2
__shared__ char shared[32];
char data = shared[BaseIndex + tid];
因为此时 shared[0]、shared[1]、shared[2]、shared[3]属于同一个 bank。对同样的数组,按下面的形式进行访问,则可以避免 bank conflict 问题:
1
char data = shared[BaseIndex + 4 * tid];
又如,对 double 数组进行访问时存在 2-way 冲突,此时访存请求会被编译为两个独立的32bit 请求:
1
2
__shared__ double shared[32];
double data = shared[BaseIndex + tid];
计时函数
chrono
要使用chrono库,需要#include<chrono>,其所有实现均在std::chrono namespace下。注意标准库里面的每个命名空间代表了一个独立的概念。
chrono是一个模版库,使用简单,功能强大,只需要理解三个概念:duration、time_point、clock
一 、时钟-CLOCK chrono库定义了三种不同的时钟:
std::chrono::system_clock: 依据系统的当前时间 (不稳定)
std::chrono::steady_clock: 以统一的速率运行(不能被调整)
std::chrono::high_resolution_clock: 提供最高精度的计时周期
这三个时钟有什么区别呢?
system_clock就类似Windows系统右下角那个时钟,是系统时间。明显那个时钟是可以乱设置的。明明是早上10点,却可以设置成下午3点。
steady_clock则针对system_clock可以随意设置这个缺陷而提出来的,他表示时钟是不能设置的。
high_resolution_clock则是一个高分辨率时钟。
这三个时钟类都提供了一个静态成员函数now()用于获取当前时间,该函数的返回值是一个time_point类型,
system_clock除了now()函数外,还提供了to_time_t()静态成员函数。用于将系统时间转换成熟悉的std::time_t类型。
得到了time_t类型的值,在使用ctime()函数将时间转换成字符串格式,就可以很方便地打印当前时间了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include<iostream>
#include<vector>
#include<string>
#include<ctime>//将时间格式的数据转换成字符串
#include<chrono>
using namespace std::chrono;
using namespace std;
int main()
{
//获取系统的当前时间
auto t = system_clock::now();
//将获取的时间转换成time_t类型
auto tNow = system_clock::to_time_t(t);
//ctime()函数将time_t类型的时间转化成字符串格式,这个字符串自带换行符
string str_time = std::ctime(&tNow);
cout<<str_time;
return 0;
}
时间精度其实也就是时间分辨率。抛开时间量纲单论分辨率,其实就是一个比率。如:1000/1、10/1、1/1 、1/10、1/1000。
这些比率加上距离量纲就变成距离分辨率,加上时间量纲就变成时间分辨率了。为此,C++11定义了一个新的模板类ratio,用于表示比率,定义如下:
std::ratio<intmax_t N, intmax_t D >表示时钟周期,是用秒表示的时间单位,
ratio是一个分数类型的值,其中N表示分子(秒),D表示分母(周期)
常用的时间单位已经定义好了
1
2
3
4
5
6
ratio<3600, 1> hours (3600秒为一个周期,表示一小时)
ratio<60, 1> minutes
ratio<1, 1> seconds
ratio<1, 1000> millisecond
ratio<1, 1000000> microseconds
ratio<1, 1000000000> nanosecons
注意,我们自己可以定义Period,比如ratio<1, -2> r, 一个 r 表示单位时间是-0.5秒。
二、持续的时间 - duration
std::chrono::duration<int,ratio<60,1» ,表示持续的一段时间,这段时间的单位是由ratio<60,1>决定的,int表示这段时间的值的类型,函数返回的类型还是一个时间段duration
std::chrono::duration<double,ratio<60,1»
由于各种时间段(duration)表示不同,chrono库提供了duration_cast类型转换函数。
duration_cast用于将duration进行转换成另一个类型的duration。
duration还有一个成员函数count(),用来表示这一段时间的长度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include<iostream>
#include<string.h>
#include<chrono>
using namespace std::chrono;
using namespace std;
int main()
{
auto start = steady_clock::now();
for(int i=0;i<100;i++)
cout<<"nice"<<endl;
auto end = steady_clock::now();
auto tt = duration_cast<microseconds>(end - start);
cout<<"程序用时="<<tt.count()<<"微秒"<<endl;
return 0;
}
三、时间点 - time_point
std::chrono::time_point 表示一个具体时间,如上个世纪80年代、你的生日、今天下午、火车出发时间等,只要它能用计算机时钟表示。鉴于我们使用时间的情景不同,这个time point具体到什么程度,由选用的单位决定。一个time point必须有一个clock计时。
设置一个时间点:
time_point
1
2
//设置一个高精度时间点
time_point<high_resolution_clock> high_resolution_clock::now();
C/C++ Trick
按照日期进行排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
#include <iostream>
#include <set>
#include <algorithm>
#include <iterator>
using namespace std;
class Date{
private:
int year;
int month;
int day;
public:
Date(int y=0,int m=0,int d=0):year(y),month(m),day(d){}
friend bool operator<(const Date & a,const Date &b) //重载<运算符 因为SET容器排序需要用到
{
if(a.year==b.year)
{
if(a.month==b.month)
return a.day<b.day;
else
return a.month<b.month;
}
else return a.year<b.year;
}
friend ostream &operator<<(ostream &os,Date d){ //重载>>运算符 因为ostream迭代器 需要调用
os<<d.year<<"/"<<d.month<<"/"<<d.day;
return os;
}
};
int main()
{ int y,m,d,n;
multiset <Date> date;
cin>>n; //multiset 容器 输入时间可重复
cin>>y>>m>>d;
while(n)
{
date.insert(Date(y,m,d));
n--;
if(n!=0) cin>>y>>m>>d;
}
copy(date.begin(),date.end(),ostream_iterator <Date,char>(cout,"\n")); //遍历输出容器
return 0;
}
初始化vector<string>
1
2
3
4
5
6
string strs[4] = {"d1/","../","../","../"};
vector<string> logs(strs, strs+4);
for(int i=0; i<logs.size(); ++i){
cout << logs[i] << endl;
}
编译器
GCC(GNU Compiler Collection)
Clang
Cygwin
Visual Studio插件
make
make工具相当于一个智能的批处理工具,本身没有编译和链接的功能,而是用类似于批处理的方式通过调用makefile文件中用户指定的命令来进行编译和链接。
cmake
CMake本身不执行Make过程,而是根据不同平台的特性,生成对应平台的Makefie,这样我们每个工程只要写一个CMake文件即可了,其余的交给不同平台的处理器来产生不同的Makefile文件即可。
Reference
- C++_vector操作
- C++ 中vector的嵌套使用
- c++中string的用法
- 静态数组不能扩容(realloc),动态的才可以(如何创建动态数组)
- C++ - 结构体构造函数使用总结
- C++ 结构体(struct)最全详解
- C++中指针*与指针引用*&的区别说明
- C++产生随机数
- C语言scanf函数详细解释
- C++中输入字符串的几种方法
- C++中cin的详细用法
- C++文件读写详解(ofstream,ifstream,fstream)
- C++读取txt文件
- vs++2010 编译说找不到 fstream.h 解决方法
- C++ find()函数用法(一般用于vector的查找)
- C++ 中的sort()排序函数用法
- C++ map用法总结(整理)
- c++ 在函数后加const的意义:
- GCC ,Clang 与 make,cmake 一览
- 编译器、Make和CMake之间的关系
- Undefined reference to `omp_get_max_threads_'
- 关于利用Openmp中使用的时间函数
- linux创建线程之pthread_create
- C++11计时器:chrono库介绍
- c++使用mpich库编写并行程序
- 在ubuntu下利用cuda的GPU编程之旅(1)
- CUDA编程(九)并行矩阵乘法
- CUDA矩阵相乘
- CUDA编程——GPU架构,由sp,sm,thread,block,grid,warp说起
- CUDA线程索引计算
- cuda 共享内存bank conflict详解
- c++中的那些foreach循环
- 详细介绍C++STL:unordered_map
- C++ string的大小写转换
- c++优先队列(priority_queue)用法详解
- C++ pair的基本用法总结(整理)
- C++ switch case详解
- C++运算符优先级表