论文部分
Abstract
在本文中,我们提出了自注意力生成对抗网络(SAGAN),它允许对图像生成任务进行注意力驱动的, 长范围依赖建模。传统的卷积GAN生成高分辨率细节,仅作为低分辨率特征图中空间上局部点的函数。 在SAGAN中,可以使用来自所有特征位置的提示来生成细节。 此外,判决器可以检查图像远部分的高度细节特征是否相互一致。此外,最近的工作表明,生成器的条件会影响GAN性能。 利用这一见解,我们将谱规范化应用于GAN生成器,并发现这改善了训练动态过程。 我们提出的SAGAN性能优于先前的工作,将最佳发表的Inception评分从36.8提高到52.52,并在具有挑战性的IMagenet数据集上将Frechet Inception距离从27.62降低到18.65。 注意力层的可视化表明,生成器利用对应于对象形状的邻域,而不是固定形状的局部区域。
1. Introduction
图像合成是计算机视觉中的一个重要问题。 随着生成对抗性网络(GANs)(Goodfellow等人,2014年)的出现,这一方向取得了显著进展,尽管仍存在许多悬而未决的问题(Odena,2019年)。基于深卷积网络的GAN(Radford等人,2016年;Karras等人,2018年;Zhang等人) 已经特别成功了。然而,细心地检查这些模型中生成的样本, 我们可以观察到,卷积GANS(Odena等人,2017年;Miyato等人,2018年;Miyato&Koyama,2018年)在建模某些图像类方面比其他图像类更困难,因为它们是在多类的数据集(例如,ImageNet(Russakovsky等人,2015年))上训练的。 例如,最先进的图像网络GAN模型(Miyato&Koyama,2018)擅长合成结构约束很少的图像类(例如海洋、天空和景观类, 这些通常通过纹理而不是几何形状辨别的), 它不能捕捉在某些类别中一贯出现的几何或结构模式( 例如,狗通常是用真实的皮毛纹理绘制的,但没有明确定义的独立的脚)。 一个可能的解释是,以前的模型在很大程度上依赖于卷积来模拟不同图像区域之间的依赖关系。 由于卷积算子具有局部感受野,所以只有经过几个卷积层后才能处理长距离依赖关系。阻止学习长距离依赖关系的原因有多种: 小模型可能无法表示它们, 优化算法可能很难发现参数值, 这些参数值仔细协调多层以捕获这些依赖, 并且当输入是之前没有见过的时, 这些参数值在统计意义上时脆弱的且容易失败。 增加卷积核的大小可以增加网络的表示能力,但这样做也会失去局部卷积结构的计算和统计效率 。 另一方面,自注意力(Cheng等人,2016年;Parikh等人,2016年;Vaswani等人,2017年)在远依赖关系建模能力与计算能力以及统计效率之间表现出更好的平衡 。 自注意模块将一个位置上的响应计算为所有位置特征的加权和, 其中,权重-或注意力向量-只用很小的计算成本计算。
在本工作中,我们提出了自注意生成对抗网络(SAGANs),它在卷积GAN中引入了一种自注意机制。 自注意模块是卷积的补充,并有助于建模跨图像区域的长距离,多层次的依赖。 在自注意的情况下,生成器可以绘制图像,在这些图像中,每个位置的精细细节都与图像远部分的精细细节仔细协调。此外, 判决器也能够更准确地在全局的图像结构上施加复杂的几何限制。
除了自注意力外,我们还纳入了最近关于网络条件与GAN性能的见解。 由(Odena等人,2018年)的工作表明,条件良好的生成器往往表现更好。 我们提出使用以前仅应用于判决器的谱规范化技术对GAN生成器进行良好的调节(Miyato等人,2018年)。
我们在ImageNet数据集上进行了广泛的实验,以验证所提出的自注意机制和稳定技术的有效性。通过将已经报导的Inception score从36.8提高到了52.52,以及将 Frechet Inception distance从27.62减小到了18.65, SAGAN在图像合成方面显著地超越了之前的工作。注意力层的可视化表明,生成器利用对应于对象形状的邻域,而不是固定形状的局部区域。

2. Related Work
生成对抗网络。 GANs在各种各样的图像生成任务中已经取得了巨大的成功, 包括图像到图像的翻译, 图像超分辨率, 以及文本到图像的合成。 尽管取得了这种成功,但众所周知,GANS的训练是不稳定的,并且对超参数的选择很敏感。 几项工作试图稳定GAN的训练过程,并通过设计新的网络结构提升样本多样性, 修改学习目标, 增加正则化方法,以及引入启发式技巧。最近,Miyato等人提出限制判决器中权重矩阵的谱范数,以限制判决器函数的Lipschitz常数。 结合基于投影的判决器(Miyato&Koyama,2018),谱规范化模型大大提高了ImageNet上的类-条件图像生成。
注意力模型。 最近,注意机制已成为 必须捕获全局依赖关系的模型 的一个组成部分。 尤其是自注意力, 也称为内注意,通过处理同一序列中的所有位置来计算序列中一个位置的响应。Vaswani等人 (Vaswani等人,2017年)证明,机器翻译模型可以通过仅仅使用自我注意模型来实现最先进的结果。Parmar等人 (Parmar等人,2018年)提出了一种图像迁移模型,将自注意添加到图像生成的自回归模型中。 Wang等人 (Wang等人,2018年)将自我注意形式化为一种非局部操作,以建模视频序列中的时空依赖关系。 尽管取得了这一进展,自注意力还没有在GANs的背景下被探索。SAGAN学会了在图像的内部表示中有效地找到全局的,长期的依赖关系。
3. Self-Attention Generative Adversarial Networks
大多数基于GAN的图像生成模型都是使用卷积层构建的。 卷积处理局部邻域中的信息,因此单独使用卷积层对于图像中的长距离依赖关系建模计算效率低。 在这一部分中,我们采用(Wang等人,2018)的非局部模型向GAN框架引入自注意力,使生成器和判决器都能有效地对广泛分离的空间区域之间的关系进行建模。 我们将所提出的方法称为自注意生成对抗网络(SAGAN),因为它的自注意模块(见图2)。
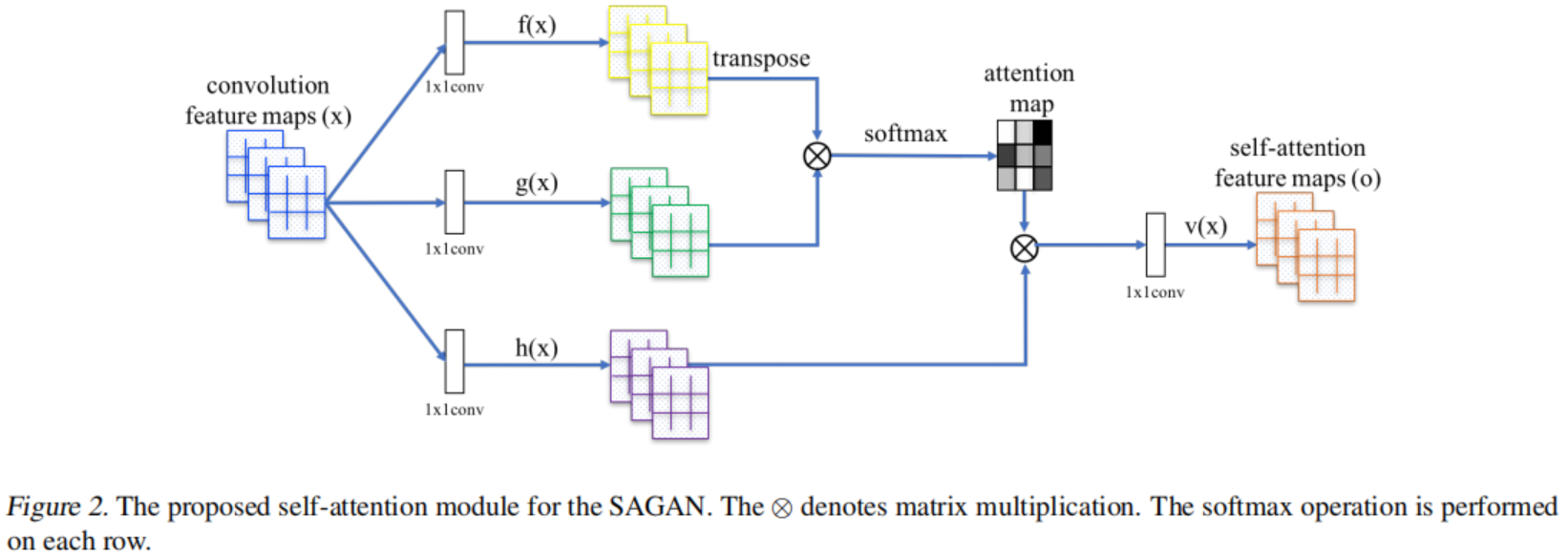
来自于前一隐藏层的图像特征$x \in R^{C \times N}$首先被转化为两个特征空间$f, g$来计算注意力, 其中$f(x) = W_f x, g(x) = W_g x$
\[\beta_{j, i} = \frac{exp(s_{ij})}{\sum_{i=1}^N exp(s_{ij})}, where s_{ij} = f(x_i)^T g(x_j) \tag 1\]$\beta_{j, i}$表示当合成第j块区域的时候, 模型倾向于第i层位置的程度。这里, C是通道的数量, N是来自上一个隐藏层的特征的特征位置的数目。注意力层的输出是$o = (o_1, o_2, …, o_j, …, o_N) \in R^{C \times N}$, 其中
\[o_j = v(\sum_{i=1}^N \beta_{j, i}h(x_i)), h(x_i) = W_h x_i, v(x_i) = W_v x_i \tag 2\]在上面的公式中,$W_g \in R^{\bar C \times C}$, $W_f \in R^{\bar C \times C}$, $W_h \in R^{\bar C \times C}$, 以及$W_v \in R^{\bar C \times C}$是学习到的权重矩阵, 它是用$1 \times 1$卷积实现的。 因为当我们把$\bar C$的通道数目减为$C/k$时,其中$k = 1, 2, 4, 8$, 在ImageNet几个epotch之后并没有观察到显著的性能下降。 为了存储效率,在我们所有的实验中选择$k = 8$(例如$\bar C = C/8$)。
此外,我们还进一步将注意力层的输出乘以比例参数,并将输入特征映射加上。因此,我们最后输出为:
\[y_i = \gamma o_i + x_i \tag 3\]其中$\gamma$是可学习的系数, 并且它被初始化为0。 引入可学习的参数$\gamma$允许网络首先依赖于局部邻近的提示——因为这更容易—— 然后逐渐学会将更多的权重分配给非局部证据。我们这样做的意图是直接的:我们想先学习简单的任务,然后逐步增加任务的复杂性。 在SAGAN中,所提出的注意模块已经应用于生成器和判决器,它们通过最小化对抗损失的hinge版本来交替训练。
\[L_D = -E_{(x, y) \thicksim p_{data}}[min(0, -1 + D(x, y))] \\ -E_{z \thicksim p_z, y \thicksim p_data}[min(0, -1 - D(G(z), y))] \\ L_G = -E_{z \thicksim p_z, y \thicksim p_{data}}D(G(z), y) \tag 4\]4. Techniques to Stabilize the Training of GANs
我们还研究了两种技术来稳定GANs在具有挑战性的数据集上的训练。首先,我们在生成器和判决器中使用谱规范化(Miyato等人,2018年)。 第二,我们确认两个时间尺度更新规则(TTUR)(Heusel等人,2017年)是有效的,我们提出使用它来解决正则化判决器中学习缓慢的问题。
4.1. Spectral normalization for both generator and discriminator
Miyato等人(Miyato等人,2018年)最初提出通过将谱规范化应用于判决器网络来稳定GAN的训练。 这样做通过限制每个层的谱范数来约束判决器的Lipschitz常数。 与其它规范化技术相比,谱规范化不需要额外的超参数微调(将所有权重层的谱范数设置为1,在实践中表现良好 )。 此外,计算成本也相对较小。
我们认为,生成器也可以受益于光谱规范化,根据最近的证据,生成器的条件是GANs的表现一个重要的影响因素(Odena等, 2018年)。 生成器中的谱规范化可以防止参数规模的升高,避免不寻常的梯度。 我们从实验中发现,生成器和判决器的谱规范化使得每个生成器更新使用更少的判决器更新成为可能,从而大大减少了训练计算成本。 该方法还显示出更稳定的训练表现。
4.2. Imbalanced learning rate for generator and discriminator updates
在以前的工作中,判决器的正则化(Miyato等人,2018年;Gulrajani等人,2017年)经常减慢GANS的学习过程。在实践中,使用正则化判决器的方法通常需要在训练期间生成器每更新一次, 判决器更新多次(例如,5次)。 独立地,Heusel等人(Heusel等人,2017年)主张对生成器和判决器使用单独的学习速率。 我们建议特别使用TTUR来补偿正则化判决器中学习缓慢的问题,使生成器每更新一次使用较少的鉴别器更新次数成为可能。 使用这种方法,给定相同的时间, 我们能够产生更好的结果。
实现部分
自注意力机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class Self_Attn(nn.Module):
def __init__(self, in_dim, activation):
super(Self_Attn, self).__init__()
self.channel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
'''
inputs:
x : input feature maps(B x C x W x H)
returns:
out: self attention value + input feature
attention: B x N x N(N is Width*Height)
'''
m_batchsize, C, width, height = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1) # B x N x C
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height) # B x C x N
energy = torch.bmm(proj_query, proj_key) # batch矩阵的乘法
# dim=-1, 对列做softmax
attention = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height) # B x C x N
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, width, height)
out = self.gamma*out + x
return out, attention

Reference
- Zhang H, Goodfellow I, Metaxas D, et al. Self-attention generative adversarial networks[J]. arXiv preprint arXiv:1805.08318, 2018.
- heykeetae/Self-Attention-GAN
- GAN系列 - 自注意力生成对抗网络SAGAN