这篇文章在我刚开始做Deepfakes的时候就看过,当时不明觉厉。
经过几个月的学习与实践,这篇文章非常符合我现在的理解与认知,其中对于全连接层和pixelshuffle的理解也带给了我新的认识。
原文地址:https://www.zhihu.com/search?type=content&q=pixelshuffler
前言
Deepfake就是前一阵很火的换脸App,从技术的角度而言,这是深度图像生成模型的一次非常成功的应用,这两年虽然涌现出了很多图像生成模型方面的论文,但大都是能算是Demo,没有多少的实用价值,除非在特定领域(比如医学上),哪怕是英伟达的神作:渐进生成高清人脸PGGAN好像也是学术意义大于实用价值。其实人们一直都在追求更通用的生成技术,我想Deepfake算是一例,就让我们由此出发,看看能否从中获取些灵感。
一、基本框架
我们先看看Deepfake到底是个何方神圣,其原理一句话可以概括:用监督学习训练一个神经网络将张三的扭曲处理过的脸还原成原始脸,并且期望这个网络具备将任意人脸还原成张三的脸的能力。说了半天这好像是一个自编码模型嘛~,没错,原始版本的deepfake就是这样的,公式如下:
\(X' = Decoder(Encoder(XW)) \tag 1\) \(Loss = L1Loss(X' - X) \tag 2\)
这里的XW是经过扭曲处理过的图片,用过Deepfake的童鞋可能会有人提出质疑,“要让代码跑起来好像必须要有两个人的人脸数据吧”。没错,之所以要同时用两个人的数据并不是说算法只能将A与B互换,而是为提高稳定性,因为Encoder网络是共享的,Deocder网络是分开的,上公式:
\(A' = Decoder_A(Encoder(AW)) \tag 3\) \(B' = Decoder_B(Encoder(BW)) \tag 4\)
为了方便理解我照搬项目二(加了Gan的版本)上的说明图片:
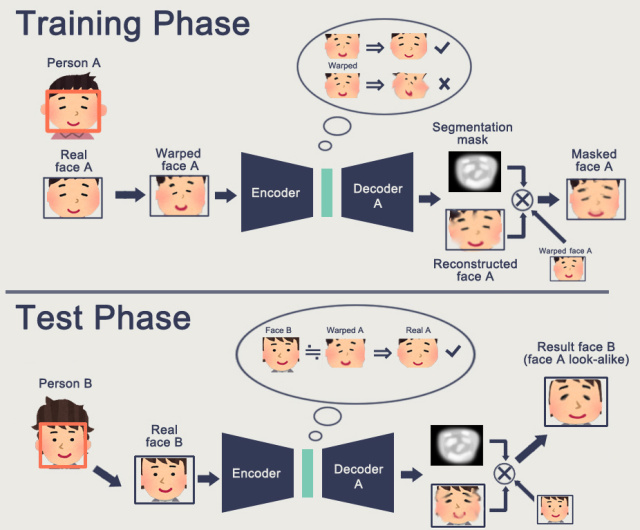
特别注意:原版是没有Mask的~
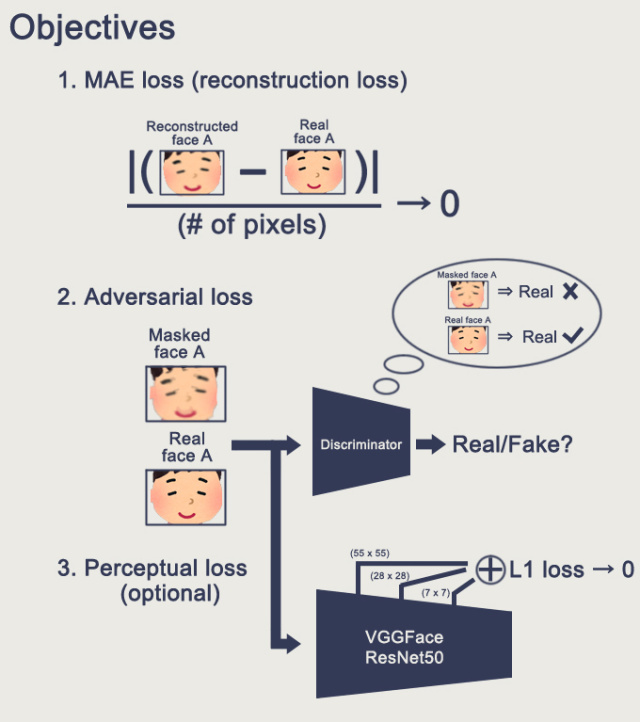
版本二我不打算讨论,仅介绍一下,简而言之就是增加了Adversarial Loss和Perceptual Loss,后者是用训练好的VGGFace网络(该网络不做训练)的参数做一个语义的比对。
二、技术细节
Deepfake的整个流程包括三步,一是提取数据,二是训练,三是转换。其中第一和第三步都需要用到数据预处理,另外第三步还用到了图片融合技术。所以我在技术上主要分三个方面来剖析:图像预处理、网络模型、图像融合。
图像预处理
从大图(或视频)中识别,并抠出人脸图像,原版用的是dlib中的人脸识别库(这个识别模块可替换),这个库不仅能定位人脸,而且还可以给出人脸的36个关键点坐标,根据这些坐标能计算人脸的角度,最终抠出来的人脸是摆正后的人
网络模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Encoder: 64x64x3->8x8x512
x = input_
x = conv(128)(x)
x = conv(256)(x)
x = conv(512)(x)
x = conv(1024)(x)
x = Dense(ENCODER_DIM)(Flatten()(x))
x = Dense(4 * 4 * 1024)(x)
x = Reshape((4, 4, 1024))(x)
x = upscale(512)(x)
Decoder:8x8x512->64x64x3
x = input_
x = upscale(256)(x)
x = upscale(128)(x)
x = upscale(64)(x)
x = Conv2D(3, kernel_size=5, padding='same', activation='sigmoid')(x)
整个网络并不复杂,无非就是卷积加全连接,编码->解码,但是仔细研究后发现作者其实是匠心独运的,为什么我不急着说,我们先看看con和upscale的内部实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def conv(filters):
def block(x):
x = Conv2D(filters, kernel_size=5, strides=2, padding='same')(x)
x = LeakyReLU(0.1)(x)
return x
return block
def upscale(filters):
def block(x):
x = Conv2D(filters * 4, kernel_size=3, padding='same')(x)
x = LeakyReLU(0.1)(x)
x = PixelShuffler()(x)
return x
return block
conv是中规中矩的卷积加lrelu激活函数,upscale中有个函数叫PixelShuffler,这个函数很有意思,其功能是将filter的大小变为原来的1/4,让后让高h、宽w各变为原来的两倍,这也就是为什么前面的卷积层的filtere要乘以4的原因。
经过测试对比,比如拿掉upscale换成步长为2的反卷机,或者简单resize为原来的两倍,实验的效果都大打折扣,结果是网络只能自编码,而得不到需要的人脸。虽然作者没有说这样设计是引用那篇论文的思想,笔者也未读到过直接讨论这个问题的论文,但是有一篇论文可以佐证:Deep Image Prior,包括Encoder中的全连接层都是人为打乱图像的空间依赖性,增加学习的难度,从而使网络能够更加充分地理解图像。所以Encoder中的全连接层和PixelShuffler都是必不可少的。经笔者测试,在不加Gan的情况下,去掉这两个要素,网络必定失败。
图像融合
图像融合放在技术难点分析中讨论。
三、难点分析
1. 清晰度问题
原版的人脸像素是64*64,显然偏低,但要提高人脸清晰度,并不能仅靠提高图片的分辨率,还应该在训练方法和损失函数上下功夫。众所周知,简单的L1Loss是有数学上的均值性的,会导致模糊。解决方案个人比较倾向在L1Loss的基础上加入GAN,因为强监督下的GAN具有区分更细微区别的能力,很多论文都提到这一点,比如较早的一篇超分辨率的文章。但是GAN也有很多问题,这个后面讨论。还有一个思路就是用PixelCNN来改善细节的,但经实践,这种方法不仅生成速度慢(虽然速度可以通过加入缓存机制,一定程度上优化),而且在质量上也不如GAN。
2. 人脸识别问题
由于第一个环节是对人脸做预处理,算法必须首先能识别出人脸,然后才能处理它,而dlib中的人脸检测算法,必须是“全脸”,如果脸的角度比较偏就无法识别,也就无法“换脸”。所以项目二就用了MTCNN作为识别引擎
3. 人脸转换效果问题
原版的算法人脸转换的效果,笔者认为还不够好,比如由A->B的转换,B的质量和原图A是有一定关联的,这很容易理解,因为算法本身的原因,由XW->X,中不管X如何扭曲总会有一个限度。所以导致由美女A生成美女B的效果要远远优于由丑男A生成美女B。这个问题的解决笔者认为最容易想到的还是Gan,类似Cycle-Gan这样框架可以进行无监督的语义转换。另外原版的算法仅截取了人脸的中间部分,下巴还有额头都没有在训练图片之内,因此还有较大的提高空间。
4. 图片融合问题
由于生成出来的是一个正方形,如何与原图融合就是一个问题了,原始项目有很多种融合方法,包括直接覆盖,遮罩覆盖,还有就是泊松克隆“Seamless cloning”,从效果上而言,遮罩覆盖的效果与泊松克隆最好,二者各有千秋,遮罩覆盖边缘比较生硬,泊松克隆很柔和,其的单图效果要优于遮罩覆盖,但是由于泊松克隆会使图片发生些许位移,因此在视频合成中会产生一定的抖动。图片融合问题的改进的思路,笔者认为还是要从生成图片本身着手,项目二引入了遮罩,是一个非常不错的思路,也是一个比较容易想到的思路,就是最终生成的是一个RAGB的带通明度的图片。笔者还尝试过很多方法,其中效果比较好的是,在引入Gan的同时加入非常小的自我还原的L1Loss,让图片“和而不同”。经测试,这种方法能够使图片的边缘和原图基本融合,但是这种方法也有弊端,那就是像脸型不一样这样的比较大的改动,网络就不愿意去尝试了,网络更趋向于小修小补,仅改变五官的特征。
5. 视频抖动问题
视频抖动是一个很关键的问题。主要源自两点,第一点是人脸识别中断的问题,比如1秒钟视频的连续30帧的图片中间突然有几帧由于角度或是清晰度的问题而无法识别产生了中断。第二点是算法本身精确度问题会导致人脸的大小发生变化。这是由算法本身带来的,因为总是让XW->X,而XW是被扭曲过的,当XW是被拉大时,算法要由大还原小,当XW被缩小时,要由小还原大。也就是说同一张人脸图片,让他合成大于自己的或小于自己的脸都是有道理的,另外当人脸角度变化较大时,这种抖动就会更明显。视频抖动目前尚未有很好的解决方案,唯有不断提高算法的精确度,同时提高人脸识别和人脸转换的精确度。
四、关于Gan改进版的Deepfake
在原始版本上加入Gan,项目二是这么做的,笔者也进行过较深入的研究。
Gan的优点是能比较快进行风格转换,相同参数下Gan训练2w次就生成比较清晰目标人脸,而原始算法大概需要5w以上,Gan生成的人脸较清晰,而且能减少对原图的依赖等,同时加入Gan之后,可以减少对特定网络模型的依赖,完全可以去掉原网络中的FC和Shuffer。
Gan的缺点也很突出,其训练难以把控,这是众所周知的。Gan会带来许多不可控的因子。比如一个人的肤色偏白,则生成的人脸也会变白,而忘记要与原图的肤色保持一致,比如有的人有流海,训练数据中大部分都是有刘海的图片,则Gan也会认为这个人必须是有刘海的,而不考虑原图是否有刘海。即使加入了Condition,Gan这种“主观臆断”和“自以为是”的特点也无法得到根除,总而言之,加入Gan以后经常会“过训练”。 这种情况在笔者之前做的字体生成项目中也出现过,比如在由黑体字合成宋体字时,Gan经常会自以为是地为“忄”的那一长竖加上一钩(像“刂”一样的钩)。另外Gan有一个最大的弊端就是他会过分趋近训练集的样本,而不考虑表情因素,比如原图的人是在大笑,但是训练集中很少有这类图片,因此生成的图片也许只是在微笑。我不禁联想到了Nvidia的那篇论文,没有条件的Gan虽然可以生成高清的图片,但是没法人为控制随机因子z,无法指定具体要生成生成什么样的脸,而有条件的Gan样本又过于昂贵。Gan的这一大缺点会使生成的视频中人物表情很刻板,而且画面抖动的情况也更剧烈,即使加入了强监督的L1Loss,GAN还是会有上述弊端。总之在原版的基础上加入Gan还需要进一步地研究,2017年Gan的论文很多,但没有多少令人眼前一亮的东西,Google甚者发了一篇论文说,这么多改进的版本与原版的差别并不显著,经测试,笔者得到的结论是Gan困最难的地方是抖动较大,合成视频时效果不太好,也许是Gan力量太强的原故。
五、结束语
单纯从技术的层面上来看,Deepfake是一个很不错的应用,笔者更期望它能用在正途上,能在电影制作,录制回忆片,纪录片中发挥作用,真实地还原历史人物的原貌,这可能是无法仅由演员和化妆师做到的,笔者也期望在2018年,基于图像的生成模型能涌现出更多可以落地的应用。