论文部分
Abstract
人脸检测和对其在没有限制的环境中通常是具有挑战性的由于各种各样的姿势、光影和遮挡。 最近的研究表明深度学习方式能够在这两个任务上取得很好的表现。 在这篇文章中,我们提出一种深度级联多任务框架, 它利用了它们之间继承的关系去加速它们的表现。 特别地, 我们的框架采用了一种级联的结构, 它有三个精心设计的深度卷积神经网络, 这些网络以一种从粗到细的方式预测人脸和五官的位置。此外, 在学习的过程中, 我们提出了一种新的在线硬采样发掘策略, 这种策略能够在没有人工采样筛选的情况下, 自动地提升表现。 我们的方法在FDDB和WIDER人脸检测基准上,以及AFLW人脸对齐基准上相比于最领先的技术取得了更高的准确率, 同时保留了实时的表现。
Introduction
人脸检测和对齐是很必要的对于很多人脸应用, 比如人脸识别和面部表情分析。 然而, 大量的面部变化, 比如遮挡, 大量的姿势变化以及极致的光纤, 给这些任务带来了极大的挑战在真实世界的应用中。
有Viola和Jones提出的级联的人脸检测器利用了类似于Haar特征和AdaBoost去训练级联的分类器, 它在实时性能上取得了很好的表现。然而,有一些工作指出这种检测器可能在真实世界的应用中会显著地变差,由于人脸的大量视觉变化, 即便是用上更先进的特征和分类器。 除了级联的结构, 一些文章引入了一种可变形的部分模型(DPM)用于人脸检测并且取得了很好的表现。然而,它们需要高计算成本, 并且在训练阶段需要标注成本。最近, 卷积神经网络(CNNs)在大量的计算机视觉任务取得了很大的进步, 比如图像分类和人脸识别。 受到这些在计算机视觉任务具有良好表现得CNNs的启发, 一些基于CNNs的人脸检测方式近年来被提出。Yang等人为人脸特征识别训练深度卷积神经网络去获得人脸区域的响应, 它产生更多人脸的候选窗口。然而, 由于复杂的CNN结构, 这种方式实际中非常耗时。 Li等人将级联的CNNs用于人脸检测, 但是它需要用额外的计算成本从人脸检测中bounding box校准, 并且忽视了在人脸五官位置的继承联系以及bounding box回归。
人脸对齐也吸引了广泛的兴趣。基于回归的方式和模板拟合方式是两种受欢迎的策略。 最近, Zhang等人提出使用人脸特征识别作为辅助任务去提升人脸对齐的性能, 这个人脸特征识别使用了深度卷积神经网络。
然而, 大多数可用的人脸检测和人脸对齐方式忽视了这两个人物之间的继承联系。 尽管存在几个任务尝试同时解决它们, 在这些任务中仍然存在限制。 比如, Chen等人同时指导对齐和检测, 使用随机森林并且使用了像素值差异的特征。但是,使用人工的特征限制了它的表现。 Zhang等人使用了多任务CNN提升多视角人脸检测的准确性, 但是检测的准确率有限,由于初始检测窗口有一个虚弱的人脸检测器产生。
另一方面, 在训练的过程中,在训练中的发掘硬采样对加强检测的能力是至关重要的。 然而, 传统的硬采样发掘通常使用一种离线的方式, 它会显著地增加人工操作。 设计一个在线的硬采样发掘方式用于人脸检测和对齐是必要的, 它能够自适应当前的训练过程。
在这篇文章中, 我们提出一种新的框架通过多任务学习使用统一的级联CNNs集成了这两个任务。我们提出地CNNs由三个阶段组成。 在第一阶段, 它通过一个粗浅地CNN快速地产生候选窗口。 然后, 它通过一个更复杂一些的CNN精修这些窗口, 拒绝大量的没有人脸的窗口。 最后, 它使用了一个更加强大的CNN去精修结果,并且输出人脸五官的位置。 由于这种多任务的学习框架, 算法的性能能够显著地提升。 这篇文章的主要贡献总结如下:
- 我们提出了一种新的级联基于CNNs的框架用于多人脸得检测和对齐, 并且精心设计了轻量的CNN结构用以实时表现
- 我们提出了一种有效的方式知道在线硬采样发掘以提升表现
- 在benchmark上进行了广泛的实验, 表明我们提出的方法在人脸检测和人脸对齐任务上相比与其他最先进的技术有显著的提升
Approach
在这一部分, 我们将会描述我们对于多人脸检测和对齐的方法
Overall Framework
我们方法的总体流程如表1所示。给定一张图像, 我们开始缩放它到不同尺度建立一个图像金字塔, 这些图像金字塔作为接下来三阶段的级联框架的输入:
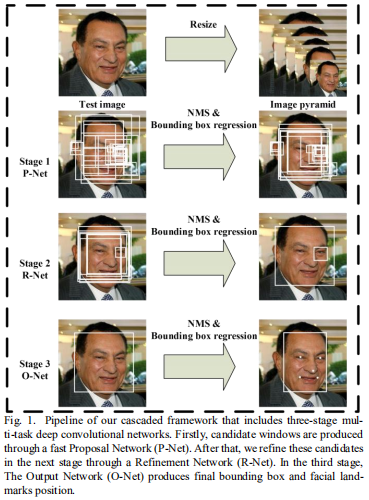
Stage 1: 我们使用了一个全卷积网络, 叫做Proposal Network(P-Net), 去得到候选窗口并且以一种与Multi-view face detection using deep convolutional neural networks相似的方式回归它们的boudning box向量。 然后我们使用预测的bounding box回归向量标定候选。 在那之后, 我始终 non-maximum supperssion(NMS)去合并高度重叠的候选框。
Stage2:所有的候选框送入另一个CNN, 叫做Refine Network(R-Net), 它进一步拒绝大量的错误候选框, 用boudning box回归标定并且用NMS 候选框合并。
Stage3:这一阶段和第二阶段相似, 但是在这一阶段我们目标是在细节上更多地藐视人脸。特别地, 网络将会输出五个人脸标志位置。
CNN Architectures
多个CNNs可以被用来设计人脸检测。 然而, 我们注意到它的表现可能被下面的因素限制:
- 一些filter缺乏权重的多样性, 这可能限制它们去产生判别的描述。
- 相比于其它的多类目标检测和分类任务, 人脸检测是一个二分类任务, 因此它可能需要更少数量的filters, 但是更多的它们的描述。
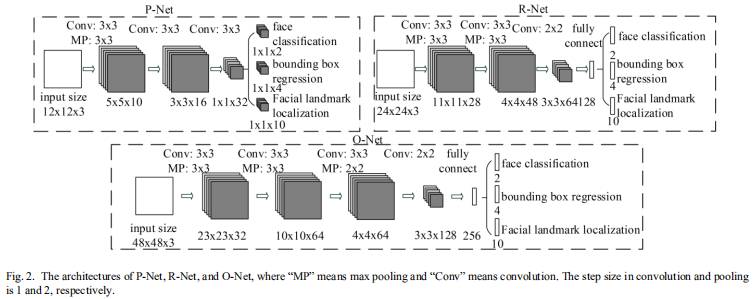
因此, 我们减少了filters的数量并且改变$5 \times 5$ filter为一个$3 \times 3$filter以减少计算, 同时增加深度以得到更好的表现。 在有这些改进后, 相比于之前的结构, 我们在用更少的运行时间的同时, 拥有更好的表现(结果如表1所示。为了公平比较,我们为两种方法使用相同的数据)。 我们的CNN结构如图2所示。
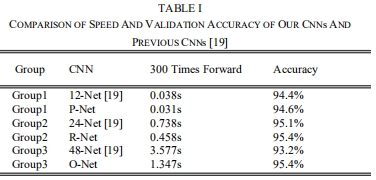
Training
我们使用三个任务去训练我们的CNN检测器: face/non-face 分类, bounding box回归, 以及脸部标志位置。
1)Face classification: 学习的目标是一个二分类问题。 对于每个采样$x_i$, 我们使用交叉熵损失:
\[L_i^{det} = -(y_i^{det} log(p_i) + (1 - y_i^{det})(1 - log(p_i))) \tag{1}\]其中$p_i$是由网络产生的概率, 它表明一个采样是人脸的概率。 记号$y_i^{det} \in {0, 1}$表示真实标签。
2)Bounding box regression: 对于每个候选窗口,我们预测了在它和它最接近的ground-truth的误差(比如bounding boxes的左、上, 高和宽)。 学习的目标是一个回归问题, 我们可以使用为每个采样$x_i$使用欧几里得损失:
\[L_i^{box} = \|\hat{y}_i^{box} - y_i^{box}\|_2^2 \tag{2}\]其中$\hat{y}_i^{box}$是从网络中获得的回归目标, $y_i^{box}$是候选的真实坐标。有四个候选坐标, 包括左、上、高和宽, 因此$y_i^{box} \in R^4$。
3)Facial landmark localization 与bounding box回归任务相似, 面部标志检测是一个回归问题, 我们最小化欧几里得损失:
\[L_i^{landmark} = \|\hat{y}_i^{landmark} - y_i^{landmark}\|_2^2 \tag{3}\]其中$\hat{y}_i^{landmark}$是从网络中得到的人脸标志坐标, $y_i^{landmark}$是真实坐标。有五个人脸标志, 包括左眼、右眼、鼻子、左嘴角、右嘴角, 因此$y_i^{landmark} \in R^{10}$
4)Multi-source training 因为我们在每个CNNs使用不同的任务, 在学习的过程中有不同类型的训练图像, 比如人脸、非人脸和部分对齐的人脸。 在这种情况下, 一些损失函数(比如公式(1)-(3))不能使用。 例如, 采样到背景区域,我们仅计算$L_i^{det}$, 并且其他两种损失设置为0。 这可以用一个采样类型的指示器来直接执行。 然后总的学习目标如下:
\[min \sum_{i=1}^{N} \sum_{j \in \{det, box, landmark\}} \alpha_i \beta_i^j L_i^j \tag{4}\]其中N是训练采样的数量。 $\alpha_j$表示任务的重要性。 我们在P-Net和R-Net中使用($\alpha_{det} = 1, \alpha_{box}=0.5, \alpha_{landmark}=0.5$), 同时为了更准确的人脸标志坐标, 在O-Net中使用($\alpha_{det}=1, \alpha_{box}=0.5, \alpha_{landmark}=1$)。 $\beta_i^j \in {0, 1}$是采样类型指示器。 在这个例子中, 很自然地想到使用随机梯度下降训练CNNs。
5) Online Hard sample mining 与在原始的分类器训练后执行传统硬采样发掘不同, 我们在人脸分类任务中使用在线的硬采样发掘去适应训练过程。
特别地, 在每一个mini-batch, 我们在前向传播阶段从所有的采样排序计算的损失, 并且选取最大的70%作为硬采样。然后我们在反向传播阶段仅计算由硬采样得到的梯度。 这意味着我们忽视了在训练过程中那些对于加强检测器帮助不大的简单采样。 实验表明这种策略在没有人工采样选择的情况下产生了更好的表现。 它的有效性在第三部分展示。
Experiments
在这一部分,我们首先评估了我们提出的硬采样发掘策略的有效性。 然后我们比较了我们的人脸检测器和对齐相比于领先的方式在人脸检测数据集和Benchmark(FDDB)、WIDER(AFLW)benchmark。 FDDB数据集包含2845张图片5171张人脸的标注。 WIDER FACE数据集包含在32203张图片中393703标注了的人脸bounding boxes, 其中50%根据图片的困难程度划分了三个子集来测试, 40%用于训练以及剩下的用于校验。AFLW包含了24386张人脸的人脸标志位置, 我们使用和Facial landmark detection by deep multi-task learning相同的测试子集。
Training Data
因为我们同时执行人脸检测和对齐, 我是用四种不同的数据标注在我们的训练过程中:
- 负样本:相比于所有的真实人脸坐标, 交并比(IoU)小于0.3。
- 正样本: 相对于真实人脸坐标, 交并比大于0.65
- 部分人脸: 相比于真实人脸坐标, 交并比在0.4到0.65
- 人脸标志: 标有5个人脸位置的人脸。
正样本和负样本用于人脸分类任务, 正样本和部分人脸用于bounding box回归任务, 人脸标志用于人脸标志定位。 训练数据对1每个网络可以描述如下:
1) P-Net: 我们从WIDER FACE中随机裁剪几块来收集正样本、负样本和部分人脸。 然后, 我们从CelebA裁剪人脸作为人脸标志。
2) R-Net 我们使用我们的框架第一阶段从WIDER FACE数据集检测人脸来收集正样本、负样本和部分人脸, 同时从CelebA检测人脸标志。
3) O-Net 与R-Net相似来收集数据,但是我们用我们框架的前两阶段检测人脸。
The effectiveness of online hard sample mining
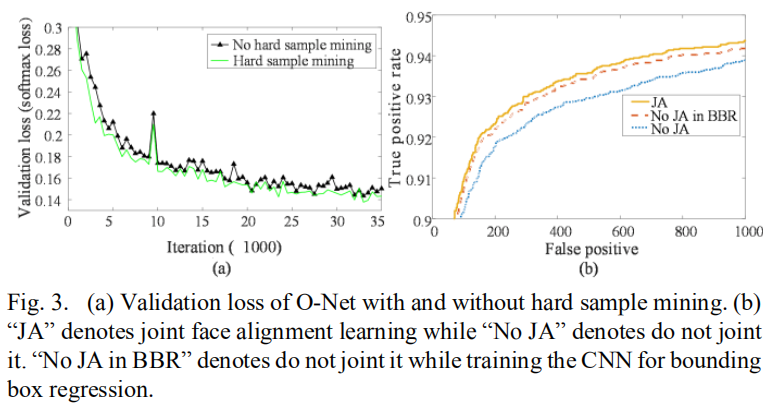
为了评估我们提出的在线硬采样发掘策略的贡献, 我们训练了两个O-Net(使用/不使用在线硬采样发掘)并比较了它们的损失曲线。 为了更直接比较, 我们仅训练O-Net用于分类任务。 所有的训练参数包括网络初始化对这两个O-Nets都是相同的。为了更容易地比较, 我们使用固定地学习率。 图3(a)展示了两种不容训练方式的损失曲线。 很明显硬采样发掘表现得到了提升。
The effectiveness of joint detection and alignment
为了评估我们的人脸检测方式的贡献,我们在FDDB数据集上评估了两个不同O-Nets的表现 (加入人脸标志回归任务/不加入)。我们也比较了这两个O-Nets的bounding box回归表现。 图3(b)表明加入人脸标志定位任务学习有利于人脸分类和bounding box的回归任务。
Evaluation on face detection
为了评估我们的人脸检测方式的表现, 我们将我们的方式和最先进的技术在FDDB数据集上和WIDER FACE进行了比较。图4(a)-(d)展示了我们方式大幅超出了之前方式的表现。我们也在一些有挑战性的照片上测试了我们的方式。
人脸对齐的评估
在这一部分, 我们比较了我们的方式和以下方式人脸对齐的表现: RCPR、TSPM、Luxand face SDK, ESR, CDM, SDM以及TCDCN。 在测试阶段, 有13张图片我们的方式没能检测出人脸。 因此我们裁剪这13张图的中心区域,让它们作为O-Net的输入。 平局误差由估计的标志和真实坐标的距离测量, 并且规范化各自的眼间距离。图4(e)展示了我们的方式大幅度超出最先进的方法。
Runtine Efficiency
由于级联的结构, 我们方法能够在同时检测和对齐人脸中取得非常快的速度。 在2.6GHz的CPU上可以达到16fps, 在GPU(Nvidia Titan Black)上可以达到99fps。 我们的执行现在基于未优化的MATLAB代码上。
CONCLUSION
在这篇文章中,我们提出了一个多任务级联的基于CNNs的框架用于同事的人脸检测和对齐。 实验结果展示了我们的方法相比于其他最先进的方法在几个benchmarks(包括FDDB和WIDER FACE benchmarks用于人脸检测, AFLW benchmarks用于人脸对齐)在保留实施时间的表现同时, 大幅度地超出它们地表现。 在未来, 我们将会利用人脸洁厕和其他人脸分析任务地继承联系, 进一步提升表现。