Abstract
受到多模态学习和机器翻译最近发展的启发, 我们引入了一种 编码器-解码器 流程, 它学习:
- 一个图像和文本联合的embedding空间。
- 一个 从我们的空间 解码分布表征 的 新的语言模型。
我们的流程有效地将 图像-文本 embeddings 模型 与 多模态神经语言模型 结合起来。我们引入 结构-内容 神经语言模型, 该模型根据编码器产生的表征 将句子的结构与其内容分开。编码器对图像和句子进行排名, 而解码器可以从头开始生成新的描述。使用LSTM对句子进行编码,我们无需使用目标检测即可匹配Flickr8K和Flickr30K的最新性能。 当使用19层Oxford卷积网络时, 还取得了最好的结果。此外, 我们证明了使用线性编码器, 学习的embedding 空间 根据向量空间算法 捕获多模态规则, 比如 *image of a blue car* - “blue” + “red” 和red car图像接近。为800幅图像生成的示例标题可供比较。
Introduction
长期以来,为图像生成描述一直被认为是一项集视觉、学习和语言理解于一体的具有挑战性的感知任务。人们不仅需要正确识别图像中出现的内容,还需要结合空间关系和对象间交互的知识。即使有了这些信息,人们也需要生成一个相关的、语法正确的描述。随着深度神经网络的最新进展,目标识别和检测等任务仅在短时间内就取得了重大突破。描述图像的任务现在变得易于处理并且已经成熟。能够为大型图像数据库附加每个图像的准确描述,将大大提高基于内容的图像检索系统的功能。 而且,原则上,可以很好地描述图像的系统也可以进行微调以回答有关图像的问题。
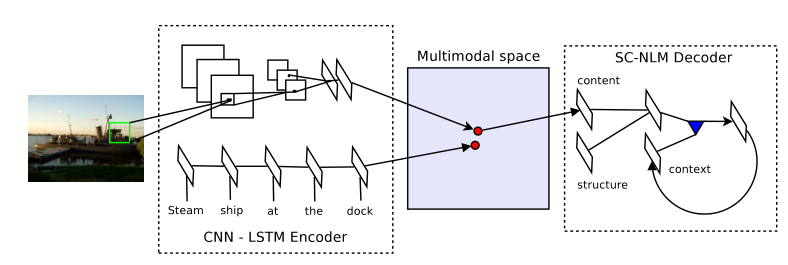
本文介绍了一种解决图像标题生成问题的新方法,并将其植入编码器-解码器模型的框架中。对于编码器,我们学习联合图像句子的embedding,其中使用长短期记忆(LSTM)递归神经网络对句子进行编码[1]。来自深度卷积网络的图像特征被投影到LSTM隐藏状态的embedding空间中。为了学习如何对图像及其描述进行排序,将成对排序损失最小化。为了进行解码,我们引入了一种新的神经语言模型,称为结构-内容神经语言模型(SC-NLM)。SC-NLM与现有模型的不同之处在于,它根据编码器产生的分布式表征,将句子的结构与其内容分离开来。我们展示了从SC-NLM中采样可以生成逼真的图像描述,大大改善了[2]生成的描述。此外,我们认为这种方法的组合很自然地适合于[3]的实验框架,也就是说,一个好的编码器可以用于对图像和描述进行排序,而一个好的解码器可以用于从零开始生成新的描述。该方法使用多模态神经语言模型(解码器阶段)有效地统一了图像-文本嵌入模型 (编码器阶段)。
虽然我们工作的应用重点是图像描述的生成和排序,但我们也定性地分析使用图像和句子学习的多模态向量空间的性质。我们证明了使用线性句子编码器,语言规则[12]也可以延续到多模态向量空间。比如, *image of a blue car* - “blue” + “red” 会产生一个与红色车辆相近的向量。 我们用主成分分析投影定性地检查了几种类型的类比和结构。因此,即使有一个全局的图像-句子训练目标,编码器仍然可以被用来检索局部(例如单个单词)。这类似于机器翻译中使用的成对排序方法[13,14]。

Multimodal representation learning
在学习图像和文本的多模式表示方面,已经完成了大量工作。流行的方法包括学习联合图像词嵌入[4,5]以及将图像和句子嵌入公共空间[6,15]。我们提出的流程直接利用了这些想法。多模态学习的其他方法包括使用深度波耳兹曼机[16],对数双线性神经语言模型[2],自动编码器[17],循环神经网络[7]和主题模型[18]。基于核心CCA[3]、归一化CCA[19]和依赖树递归网络[6],提出了几种双向图像和描述排序方法。从架构的角度来看,我们的编码器-解码器模型与[20]最为相似,[20]提出了一个两步嵌入和生成的语义解析过程。
Generating descriptions of images
我们将生成方法分为三种类型,每一种都在这里详细描述:
基于模板的方法。基于模板的方法涉及基于对象检测和空间关系的结果来填充句子模板。尽管这些方法可以产生准确的描述,但它们在本质上通常更“机器人化”,不能概括为人类编写的字幕的流畅性和自然性。
基于组合的方法。 这些方法的目的是利用现有的图像标题数据库,通过提取相关标题的成分,并将它们组合在一起,生成新的描述[26,27]。这些方法的优点是,它们比基于模板的方法允许更广泛、更富表现力的描述,它们更流畅、更像人。
Neural network methods。这些方法旨在通过从条件神经语言模型中采样来生成描述。该领域的初步工作基于多模态神经语言模型[2],它通过基于深度卷积网络输出的特征向量为条件来生成描述。这些想法最近被扩展到多模态循环网络中,并得到了显著的改进[7]。本文的方法产生的描述至少在定性上与目前最先进的基于组合的方法[27]相当。
描述生成系统一直受到评估问题的困扰。虽然过去使用过Bleu 和 Rouge,但[3]认为这种自动评估方法不可靠,不符合人类判断。这些作者进而建议将图像和描述的排名问题用作生成的代理。由于任何生成系统都需要一个评分函数来访问描述和图像的匹配程度,因此优化这个任务自然会在生成过程中得到改进。许多最近的方法都使用这种方法进行评价。尽管如此,如何将排名上的改进转化为生成新的描述的问题仍然存在。我们认为,编码器-解码器方法天然适合这个实验框架。也就是说,编码器为我们提供了一种对图像和描述进行排序并开发了良好的评分函数的方法,而解码器可以使用学习到的表征来优化评分函数,作为生成和评分新的描述的一种方法。
Encoder-decoder methods for machine translation
我们提出的工作流程,虽然对描述生成是新的,但已经在神经机器翻译(NMT)方面取得了一些成功。NMT的目标是开发一个具有大型神经网络的端到端翻译系统,而不是将神经网络用作现有基于短语的系统的附加功能。NMT方法基于编码器-解码器原理。即,使用编码器将英语句子映射到分布式矢量。然后,以该向量为条件的解码器将从源文本生成法语翻译。当前的方法包括使用卷积编码器和RNN解码器[8],RNN编码器和RNN解码器[9、10]以及具有LSTM解码器[11]的LSTM编码器。尽管这些方法仍是一个新兴的研究领域,但它们已经达到了与基于短语的强大系统相当的性能,并且在用于评分的最新技术方面得到了改进。
我们认为将图像描述生成视为翻译问题是很自然的。也就是说,我们的目标是将图像转换为描述。这一观点也被[28]使用,并使我们利用机器翻译文献中的现有想法。此外,评分函数的概念(描述和图像匹配得有多好)和对齐(描述的哪些部分对应于图像的哪些部分)之间存在自然的对应关系,这些对齐可以自然地用于生成描述。
An encoder-decoder model for ranking and generation
在本节中,我们将描述我们的图像描述生成流程。我们首先回顾了用于句子编码的LSTM RNN,然后介绍了如何学习多模态分布式表示。然后我们回顾了log-bilinear neural language models[29]和multiplicative neaural language[30],然后介绍了我们的structure-content neural language model。
Long short-term memory RNNs
长期短期记忆[1]是一个循环神经网络, 它包含一个内置的记忆神经元来存储信息和利用长期的上下文。LSTM的记忆神经元由门控单元包围着, 他们用来读、写和重置信息。LSTMs已被用于在一些任务中实现最先进的性能,如手写识别[31],序列生成[32]语音识别[33]和机器翻译[11]等。为了防止深LSTMs的过拟合,也提出了Dropout[34]策略。[35]
用$X_t$表示在时间$t$的一个训练实例的矩阵。 在我们的例子中, $X_t$被用来表示 在训练批次中每个句子的第t个单词表示为一个词表示的矩阵。用$(I_t, F_t, C_t, O_t, M_t)$表示在时间$t$的输入, 遗忘, 神经元, 输出 和 LSTM的隐藏状态。 在本文中LSTM结构使用如下等式:
\[I_t = \sigma(X_t · W_{xi} + M_{t-1}·W_{hi} + C_{t-1}·W_{ci} + b_i) \tag{1}\] \[F_t = \sigma(X_t · W_{xf} + M_{t-1}·W_{hf} + C_{t-1}·W_{cf} + b_f) \tag{2}\] \[C_t = F_t \bullet C_{t-1} + I_t \bullet tanh(X_t · W_{xc} + M_{t-1}·W_{hc} + b_c) \tag{3}\] \[O_t = \sigma(X_t·W_{xo} + M_{t-1}·W_{ho} + C_t · W_{co} + b_o) \tag{4}\] \[M_t = O_t \bullet tanh(C_t) \tag{5}\]其中$(\sigma)$表示sigmoid激活函数, $(·)$表示矩阵乘法, $(\bullet)$表示按元素乘。
Multimodal distributed representations
假设在训练中,我们被给予图像描述对,每对图像对应一个图像和一个正确描述图像的描述。图像被表示为在ImageNet分类任务熵训练的卷积网络的顶层(在softmax之前)。
$D$是图像特征的维数(比如AlexNet中为4096), K是嵌入空间中的维数, V是词汇表中单词的数目。$W_I \in R^{K \times D}$并且$W_T \in R^{K \times V}$分别是图像嵌入矩阵和词嵌入矩阵。 给定一个图像用单词$S = {w_1, …, w_N}$描述, 让${w_1, …, w_N}, w_i \in R^K, i=1, …, n$表示与词$w_1, …, w_N$相对应的单词表示。句子v的表示 是 在时间戳N处 LSTM的隐藏状态(即向量$m_t$)。我们注意到,有已经提出了用于计算图像文本嵌入的句子表示的其他方法,包括依赖性树RNN [6]和依赖性解析包[15]。让$q \ in R^K$表示一个图像的特征向量(用于与描述S对应的图像)并且让$x = W_I · q \in R^K$表示图像的图像嵌入。
思考: 感觉feature vector 和 embedding 很像, 但是又区分不开?
我们定义一个打分函数$s(x, v) = x · v$, 其中$x$和$v$首先被单位规范化(使$s$等于余弦相似度)。让$\theta$表示所有学习到的参数($W_I$和所有LSTM的权重)。 我们优化下面的ranking loss 对:
\[\min_\theta \sum_x \sum_k max\{0, \alpha - s(x, v) + s(x, v_k)\} + \sum_v \sum_k max \{0, \alpha - s(v, x) + s(v, x_k)\} \tag{6}\]其中$v_k$是对于图像嵌入$x$对比性的句子(非描述性), $x_k$反之亦然。对于我们所有的实验,我们将词嵌入$W_T$初始化为使用连续的 bag of words 模型 预计算学习到的 $K=300$ 维的向量。从训练集中随机选择对比项,并在每个时期重新采样。
Log-bilinear neural language models
log-bilinear language model (LBL) 是一种确定性模型,可以将其视为具有单个线性隐藏层的前馈神经网络。词汇表中的每个单词$w$都被表示为$K$维实值向量$W \in R^K$(编码器中提到过)。让$R$表示一个$V \times K$的词表示向量的矩阵, 其中$V$是词汇表的大小。让$(w_1, …, w_{n-1})$是$n-1$个单词的tuple, 其中$n - 1$是文本大小。 LBL模型使下一个词的线性预测表示为:
\[\hat r = \sum_{i=1}^{n-1} C^{(i)}w_i \tag{7}\]其中$C^{(i)}, i = 1, …, n - 1$是$K \times K$上下文参数矩阵。 因此, $\hat r$是$w_n$的预测表示。 给定$w_1, …, w_{n-1}$, $w_n$条件概率$P(w_n = i \mid w_{1:n-1})$是:
\[P(w_n = i \mid w_{1:n-1}) = \frac{e^{\hat r^T r_i + b_i}}{\sum_{j=1}^V e^{\hat r^T r_j + b_j}} \tag{8}\]其中$b \in R^V$是偏置向量。 使用随机梯度下降学习。
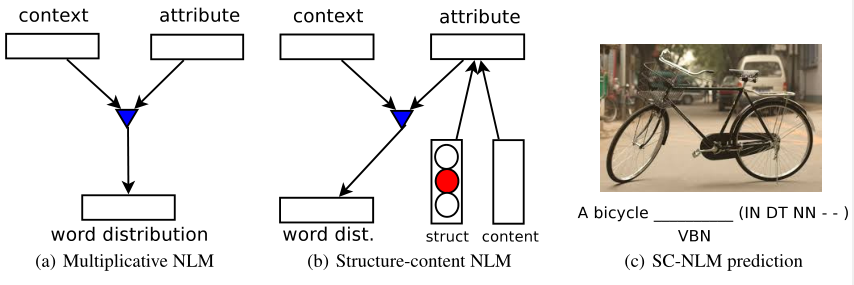
Multiplicative neural language models
假设我们现在从多模态向量空间给定一个向量$u \in R^k$, 它和一个词序列$S = {w_1, …, w_N}$相关。例如, u可以是一个由S描述的图像的嵌入表示。 Multiplicative neural language models根据给定的先前的单词和向量$u$给定上下文, 对新单词的分布$P(w_n = i \mid w_{1: n-1}, u)$建模。乘法模型还有一个额外的性质,就是用张量$\tau∈R^{V×k×G}$代替词嵌入矩阵,其中G是切片的数量。
给定$u$, 我们可以计算一个词表示矩阵作为$u$的函数$\tau^u = \sum_{i=1}^G u_i \tau^{(i)}$, 比如对于各个$u$, 词表示由$u$的各个成分$u_i$按权重线性组合计算得到。这里,切片数$G$等于$K$,$u$的维数。
通常没有必要使用完全未因子化的张量。 我们使用三个矩阵$W^{fk} \in R^{F \times K}, W^{fd} \in R^{F \times G}, W^{fv} \in R^{F \times V}$来重新表示$\tau$:
\[\tau^u = (W^{fv})^T · diag(W^{fd}·u) · W^{fk} \tag{9}\]其中 $diag(·)$ 表示其参数为于对角线上的矩阵。这些矩阵由预先选择的因子$F$参数化。 在[30]中,条件向量$u$被称为一个属性,使用单词的三阶模型可以模拟条件相似性:单词的意义如何随着它们被条件化的属性的函数而变化。
让$E = (W^{fk})^T W^{fv}$表示一个”折叠”的$K \times V$的词嵌入的矩阵。 给定上下文$w_1, …, w_{n-1}$, 下一个被预测的词表示$\hat r$:
\[\hat r = \sum_{i=1}^{n-1} C^{(i)} E(:, w_i) \tag{10}\]其中对于$w_i$的词表示$E(:, w_i)$表示$E$的列, 并且$C^{(i)}, i=1, …, n-1$是$K \times K$的上下文矩阵。给定一个预测的下一个单词表示$\hat r$, 因子输出为$f = (W^{fk} \hat r) \bullet (W^{fd} u)$,其中$\bullet$表示元素级乘。 给定$w_1, …, w_{n-1}$和$u$的条件概率:
\[P(w_n = i \mid w_{1:n-1}, u) = \frac{e^{(W^{fv}(:, i)^T f + b_i)}}{\sum_{j=1}^V e^{(W^{fv}(:. j)^Tf + b_j)}}\]其中$W^{fv}(:, i)$表示对应于单词$i$的$W^{fv}$的列。与 log-bilinear 模型相反,之前的词表示矩阵$R$被替换为我们得到的因子张量$\tau$。我们将乘法模型与加法变量[2]进行了比较,发现在大型数据集上,如SBU描述照片数据集[40],乘法变量明显优于加法变量。因此,SC-NLM是从乘法变量推导出来的。
Structure-content neural language models
我们现在来描述structure-content neural language model。假设, 连同描述$S = {w_1, …, w_N}$, 我们还给定一系列指定单词结构的变量$T = {t_1, …, t_N}$。贯穿我们的实验, 每个$t_i$对应于每个单词$w_i$的词性, 尽管也可以使用其他可能性来代替。给定一个嵌入向量$u$(内容向量), 我们的目标是从先前的单词上下文$w_{1: n-1}$和结构上下文$t_{n: n+k}$建模分布$P(w_n = i \mid w_{1:n-1}, t_{n:n+k}, u)$, 其中$k$是前向上下文的大小。
直观地, 结构变量有助于在生成短语期间引导模型, 并且可以被认为是帮助避免模型生成无意义的语法的软模版。注意到该模型与[41]的机器翻译NNJM有相似之处,其中先前的单词上下文是目标语言中的预测单词,而前向上下文是源语言中的单词。
我们的模型可以解释为一个multiplicative neural language model, 但是其中属性向量不再是$u$,而是$u$和结构变量$t$的加性函数。让${t_n, …, t_{n+k}}, t_i \in R^K, i = n, …, n+k$表示结构变量$T$的嵌入向量。这些都是从学习查找表中获得的,就像单词一样。 我们引入一系列$G \times G$结构上下文矩阵$T^{(i)}, i = n, …, n+k$, 它们与单词上下文矩阵$C^{(i)}$起相同的作用。让$T_u$表示对于多模态向量$u$的一个$G \times K$的上下文矩阵。 结合了结构和内容信息的属性向量$\hat u$被计算为:
\[\hat u = \begin{bmatrix}(\sum_{i=n}^{n+k} T^{(i)}t_i) + T^{(u)}u + b\end{bmatrix}_+ \tag{11}\]其中$[.]_+ = max{·, 0}$是一个非线性的ReLU并且b是一个偏置向量。 向量$\hat u$现在和对于先前描述的乘法模型的向量$u$扮演着相同的角色, 并且模型剩余的部分没有改变。我们的实验中使用$G = K = 300$以及系数$F = 100$。
SC-NLM是在一个图像描述的大集合上训练的(例如Flickr30K)。有几种方法可以用来表示条件向量$u$。一种选择是使用相应图像的嵌入。一个可以替换的选择, 也是我们采用的方式, 是使用LSTM计算描述S的嵌入向量为条件。这种方式的优点是SC-NLM可以单纯地在文本上训练。这允许我们使用大量的单语文本(例如,非图像描述)来提高语言模型的质量。由于S的嵌入向量与图像嵌入共享一个联合空间, 因此我们也可以在训练模型后将SC-NLM限制在图像嵌入上(例如在测试时,当没有可用的描述时)。与条件语言模型相比,这是一个显著的优势, 条件语言模型明确要求使用图像描述对进行训练并且强调多模态编码空间的强度。
Experiments
Image-sentence ranking
我们的主要定量结果是建立使用LSTM句子编码器对图像和描述进行排名的有效性。我们对Flickr8K[3]和Flickr30K [42]数据集执行与[15]相同的实验步骤。这些数据集分别包含8000张和30000张图片,每张图片由独立的注释者用5句话注释。与[15]一样,我们没有进行任何显式文本预处理。我们使用了两种卷积网络架构来提取4096维的图像特征:多伦多convnet5和在2014年ILSVRC分类竞赛中获得第二名的19层OxfordNet[43]。按照[15]的协议,1000张用于验证,1000张用于测试,其余的用于训练。评估是使用Recall@K来执行的,也就是在检索结果的前k位上排列正确标题的图片的平均数量(句子也一样)。我们还报告了排名列表中最接近的ground truth结果的中位数排名。我们将结果与以下每种方法进行比较:
- DeViSE. 深度视觉语义嵌入模型[5]被提出作为执行zero-shot 物体检测的一种方法,并被[15]用作baseline。在此模型中,句子表示为词嵌入的均值,优化后的目标函数与我们的匹配。
- SDT-RNN. 使用语义依赖树循环神经网络[6]学习嵌入到联合图像-句子空间中的句子表示。使用同样的目标。
- DeFrag. 深度片段嵌入[15]被提出作为嵌入全帧图像特征的替代方案,并利用了R-CNN[44]检测器的目标检测。
- m-RNN. 多模态循环神经网络[7]是最近提出的一种方法,该方法使用perplexity作为模态之间的桥梁,[2]首先提出。与所有其他方法不同,m-RNN不使用排名损失,而是优化了以图像为条件的序列中预测下一个单词的对数似然性。
我们的LSTM使用1层,每层300个单位,权重从[-0.08,0.08]统一初始化。边际$α$设置为$α= 0.2$,我们发现这在两个数据集上均表现良好。训练是使用随机梯度下降进行的,初始学习率为1,并且呈指数下降。我们在Flickr8K上使用的最小批量大小为40,在Flickr30K上使用的最小批量大小为100。没有使用动量。相同的超参数用于OxfordNet实验。
Results
表1和表2分别说明了我们在Flickr8K和Flickr30K上的结果。我们模型的性能与m-RNN相当。对于某些指标,我们优于或匹配现有结果,而在其他指标上,m-RNN优于我们的模型。m-RNN没有学习图像和句子之间的显式嵌入,而是依靠perplexity作为检索的手段。与基于困惑的检索方法相比,学习显式嵌入空间的方法具有明显的速度优势,因为检索很容易,只需将数据集中存储的嵌入向量与查询向量进行矩阵相乘即可。因此,显式嵌入方法更适合缩放到大型数据集。
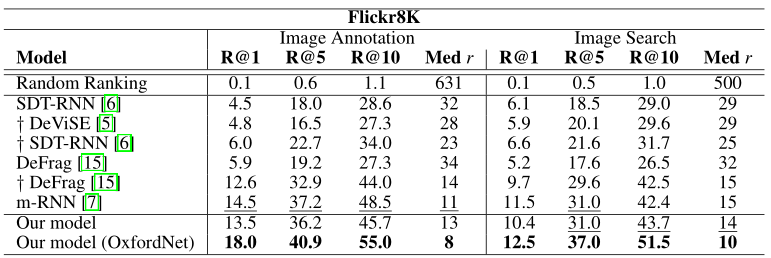
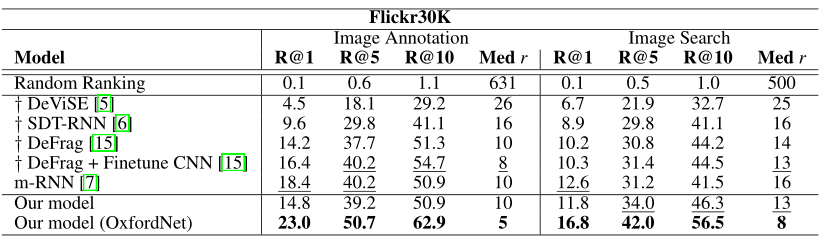
也许更有趣的是,我们的方法和m-RNN均优于集成对象检测的现有模型。这与[6]矛盾,后者的循环网络是表现最差的模型。这突出了LSTM单元对于编码描述之间的依存关系和学习有意义的分布式句子表示的有效性。与DeFrag一样,将对象检测集成到我们的框架中几乎肯定会提高性能,并允许可解释检索。
使用OxfordNet模型的图像特征可以显着提高所有指标的性能,从而为这些评估任务提供最新的最新数字。
Multimodal linguistic regularities
[12]展示了用skip-gram [37]或神经语言模型[45]学习的词嵌入,展现出语言规律性,这些规律使这些模型能够执行类比推理。例如,“男人”对“女人”就像“国王”对?可以通过找到最接近“国王”-“男人” +“女人”的向量来回答。我们自然要问的一个问题是多模态向量空间是否表现出同样的现象。*一辆蓝色汽车的图像* -“蓝色”+“红色”会在红色汽车的图像附近吗?
假设我们用线性编码器训练一个嵌入模型,对词向量$w_i$和句子向量$v$, 也就是$v = \sum_{i=1}^N w_i$(其中v和图像嵌入都归一化到单位长度)。使用我们上面提到的例子, 让$v_{blue}$, $v_{red}$和$v_{car}$分别表示词嵌入 蓝、红和车。让$I_{bcar}$和$I_{rcar}$表示蓝色和红色车图像的嵌入。 在训练一个先行编码器后, 模型有了属性$v_{blue} + v_{car} \approx I_{bcar}$以及$v_{red} + v_{car} \approx I_{rcar}$。
\[v_{car} \approx I_{bcar} - v_{blue} \tag{12}\] \[v_{red} + v_{car} \approx I_{bcar} - v_{blue} + v_{red} \tag{13}\] \[I_{rcar} \approx I_{bcar} - v_{blue} + v_{red} \tag{14}\]因此给定一个查询图像$q$, 一个负单词$w_n$和一个正单词$w_p$(都是单位话的), 我们寻找一个图像$x^*$:
\[x^* = arg \max_x \frac{(q - w_n + w_p)^T x}{\| q - w_n + w_p\|} \tag{15}\]补充材料包含定性证据,上述证据适用于几种类型的规律性和图像。在我们的示例中,我们考虑检索前4个最接近的图像。偶尔我们会观察到,在好成绩的前4名中,会出现较差的成绩。我们发现了一个去除这些情况的简单策略,即首先检索最接近的N幅图像,然后根据它们到N幅图像均值的距离对这些图像重新排序。
值得注意的是,使用LSTM编码器无法很好地观察到此类规律性,因为句子不再仅仅是其单词的总和。线性编码器大致相当于表1和表2中的baseline,它们在检索时的性能明显比LSTM编码器差。因此,虽然这些规律是有趣的,但学习的多模态向量空间并不适合对句子和图像进行排序。
Image caption generation
我们从SBU带描述的照片数据集[40]中为大约800张图片生成了图像描述。这些是基于当前最新的基于合成的方法TreeTalk [27]用来显示结果的相同图像。我们的LSTM编码器和SC-NLM解码器是通过将Flickr30K数据集与最近发布的Microsoft COCO数据集[46]结合在一起进行训练的,这些数据组合在一起为我们提供了100,000多个图像和500,000多个描述。SBU数据集包含一百万个图像,每个图像都有一个描述,并由[27]用于训练其模型。尽管SBU数据集更大,但带标注的描述却更加嘈杂且更具个性化。
生成的结果可以在以下位置找到:http://www.cs.toronto.edu/~rkiros/lstm_scnlm.html。对于每个图像,我们都显示原始描述,训练集中最近的邻居句子,模型中生成的前5个样本以及TreeTalk生成的最佳结果。显示最近的邻居句子,以表明我们的模型不是简单地学会复制训练数据。我们生成的描述可以说是迄今为止最好的。
Discussion
当生成一个描述时,通常情况下在任何给定时间只有一个小区域是相关的。我们正在开发一种基于注意力的模型,该模型可以联合学习将描述与图像的部分对齐,并使用这些对齐来确定下一步要关注的位置,从而动态地修改用于调节解码器的向量。我们还计划试验LSTM解码器以及深度和双向LSTM编码器。
Supplementary material: Additional experimentation and details
Multimodal linguistic regularities

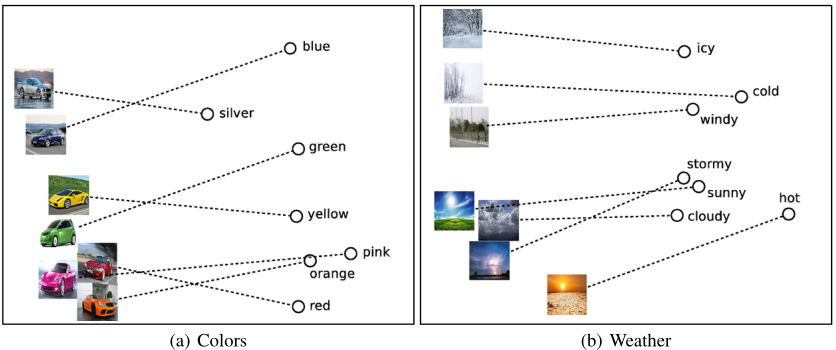
图4解释了使用在SBU数据集上训练的模型得到的示例结果。所有查询均在线下载,检索到的图像来自用于训练的SBU图像。需要注意的是,生成的图像高度依赖于用于查询的图像。例如,搜索单词“night”会检索夜间拍摄的任意图像。另一方面,以建筑物为主要焦点的图像在减去“ day”并添加“night”后将返回夜间图像。以猫,碗和盒子为例,也会发生类似的现象。作为额外的可视化,我们计算了汽车及其对应颜色的PCA投影,以及图5中出现的图像和天气。这些结果为用线性编码器训练的多模态向量空间中明显的规律提供了有力的证据。当然,只有当(a)图像的内容被正确识别,(b)减法词与图像相关,以及(c)存在一幅图像,该图像对于相应的查询是可感知的,才有可能得到合理的结果。
Image description generation
SC-NLM是根据Flickr30K和Microsoft COCO的训练句子拼接进行训练的。 给定一个图像,我们首先将其映射到多模态空间中。通过此嵌入,我们为SC-NLM定义了2组候选条件向量:
Image embedding. 嵌入图像本身。注意,SC-NLM不是用图像训练的,但是由于嵌入空间是多模态的,所以可以对图像进行条件设置。
top-N nearest words and sentences. 首先计算图像嵌入后,利用余弦相似度得到最接近的n个近邻词和训练句子。这些检索被视为一个“概念包”,我们计算每个概念的平均值的嵌入向量。我们所有的结果都使用N = 5。
除了候选条件向量,我们还计算SC-NLM使用的候选POS序列。为此,我们从长度在4到12之间的训练集中获得一组POS序列。描述是通过首先对条件向量进行采样,然后对POS序列进行采样,然后通过SC-NLM计算MAP估计来生成的。我们生成一个候选描述的大列表(在我们的结果中每个图像1000),并使用评分函数对这些候选进行排名。我们的评分函数由两个特征函数组成:
Translation model. 候选描述使用LSTM嵌入到多模态空间中。然后,我们将翻译得分计算为图像嵌入和候选描述的嵌入之间的余弦相似度。这对候选内容与图像的相关程度进行了评分。对于在描述中频繁出现的非停止词,我们也增加一个乘法惩罚到这个分数。
Language model. 我们在一个大型语料库上训练了一个Kneser-Ney三元模型,并计算了该模型下候选人的对数概率。这可以衡量考生的英语句子是否合理。
描述的总得分是翻译模型和语言模型的加权和。由于定量评估生成的描述存在挑战,因此我们仅根据定性结果手动调整权重。所有候选描述均按其得分排名,并返回前5个描述。