文本的tokenization
概念和工具的介绍
tokenization就是通常说的分词, 分出的每一个词语我们把它称为token。
常见的分词工具:
- jieba分词: https://github.com/fxsjy/jieba
- 清华大学的分词工具THULAC: https://github.com/thunlp/THULAC-Python
中英文分词的方法
把句子转化为词语
- 比如: 我爱深度学习 可以分为 [我, 爱, 深度学习]
把句子转化为单个字
- 比如:我爱深度学习的token是 [我, 爱, 深, 度, 学, 习]
N-gram表示方法
N表示把连续的N个词作为特征。
1
2
3
4
5
6
7
8
9
import jieba
text = "深度学习(英语: deep learning)是机器学习的分支, 是一种以人工神经网络为架构, 对数据进行表征学习的算法。"
cuted = jieba.lcut(text)
print(cuted)
print([cuted[i:i+2] for i in range(len(cuted) - 1)])
1
[['深度', '学习'], ['学习', '('], ['(', '英语'], ['英语', ':'], [':', ' '], [' ', 'deep'], ['deep', ' '], [' ', 'learning'], ['learning', ')'], [')', '是'], ['是', '机器'], ['机器', '学习'], ['学习', '的'], ['的', '分支'], ['分支', ','], [',', ' '], [' ', '是'], ['是', '一种'], ['一种', '以'], ['以', '人工神经网络'], ['人工神经网络', '为'], ['为', '架构'], ['架构', ','], [',', ' '], [' ', '对'], ['对', '数据'], ['数据', '进行'], ['进行', '表征'], ['表征', '学习'], ['学习', '的'], ['的', '算法'], ['算法', '。']]
在传统的机器学习中,使用N-gram方法往往能够取得非常好的效果, 但是在深度学习中比如RNN中会自带N-gram的效果。
向量化
把文本转化为向量有两种方法:
- 转换为one-hot编码
- 转化为word embedding
one-hot编码
每一个token使用长度为N的向量表示, N表示词典的数量
例如:
| token | one-hot encoding |
|---|---|
| 深 | 1000 |
| 度 | 0100 |
| 学 | 0010 |
| 习 | 0001 |
one-hot使用稀疏的向量表示文本,占用空间多。
word embedding
word embedding使用浮点型的稠密矩阵表示token, 根据词典大小,向量使用不同的维度, 例如100, 256, 300等。 向量的初始值是随机生成的, 之后会在训练过程中进行学习而获得。
假设文本中有20000个词, 如果使用one-hot编码,那么会有20000 * 20000矩阵,大多数位置为0, 如果使用word embedding表示, 只需要 20000 * x 维度, 比如20000 * 300。
我们会把所有的文本转化为向量,把句子用向量来表示。
我们先把token用数字来表示, 再把数字使用向量来表示。
word_embedding API
1
torch.nn.Embedding(num_embeddings, embedding_dim)
参数:
- num_embdeddings: 词典的大小
- embedding_dim: embedding的维度
使用方法:
1
2
embedding = nn.Embedding(vocab_size, 300) #实例化
input_embeded = embedding(input) # 进行embedding的操作
数据的形状变化
每个batch的句子有10个词语, 经过形状为[20, 4]的word embedding之后, 句子会变为[batch_size, 10, 4]的形状
增加了一个维度, 这个维度是embedding的dim。
情感分类
思路分析
情感评分分为1-10, 可以10个类别, 这里我们选择二分类,正向情感和负向情感。
数据集
IMDB数据集, 包含5万条流行电影的评论数据, 其中训练集25000条, 测试集25000条。
http://ai.stanford.edu/~amaas/data/sentiment/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
def tokenize(content):
# filters = '!"#$%^&'
# $, . 符号是个特殊字符,需要转义
filters = ['\$','\t', '\n', '\x97', '\x96', '#', '%', '&', '\.', "<.*?>", '"']
# | 在正则里面表示或
content = re.sub("|".join(filters), " ", content)
content = re.sub("!", " !", content)
tokens = [i.strip().lower for i in content.split()]
return tokens
class ImdbDataset(Dataset):
def __init__(self, train=True):
self.train_data_path = r"./datasets/aclImdb/train"
self.test_data_path = r"./datasets/aclImdb/test"
data_path = self.train_data_path if train else self.test_data_path
temp_data_path = [os.path.join(data_path, "pos"), os.path.join(data_path, "neg")]
self.total_file_path = []
for path in temp_data_path:
file_path_list = os.listdir(path)
file_path_list = [os.path.join(path, i) for i in file_path_list]
self.total_file_path.extend(file_path_list)
def __getitem__(self, index):
file_path = self.total_file_path[index]
# 获取label
label_str = file_path.split("/")[-2]
label = 0 if label_str == "neg" else 1
# 获取内容
content = open(file_path).read()
tokens = tokenize(content)
return tokens, label
def __len__(self):
return len(self.total_file_path)
def collate_fn(batch):
"""
param batch: ([tokens, label], [tokens, label])
"""
# print(batch)
content, label = list(zip(*batch))
return content, label
def get_dataloader(train=True):
imdb_dataset = ImdbDataset(train)
data_loader = DataLoader(
imdb_dataset,
batch_size=2,
shuffle=True,
collate_fn=collate_fn)
return data_loader
文本序列化
把文本中的每个词语和其对应的数字,使用字典保存, 同时实现方法把句子通过字典映射为包含数字的列表。
实现文本序列化之前, 考虑以下几点:
- 如何使用字典把词语和数字进行对应
- 不同的词语出现的次数不尽相同, 是否需要对高频或者低频词语进行过滤, 以及总的词语数量是否需要进行限制
- 得到词典之后, 如何把句子转化为数字序列, 如何把数字序列转化为句子
- 不同句子长度不同, 每个batch的句子如何构造生相同的长度(可以对短句子进行填充, 填充特殊字符)
- 对于新出现的词语在词典中没有出现怎么办(可以用特殊字符代替)
思路分析:
- 对所有句子进行分词
- 词语存入字典, 根据次数对词语进行过滤, 并统计次数
- 实现文本转数字序列方法
- 实现数字序列转文本方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
class Word2Sequence():
UNK_TAG = "UNK"
PAD_TAG = "PAD"
UNK = 0
PAD = 1
def __init__(self):
self.dict = {
self.UNK_TAG: self.UNK,
self.PAD_TAG: self.PAD
}
self.count = {}
def fit(self, sentence):
"""
把单个句子保存到dict中
sentence: [word1, word2, word3, ...]
"""
for word in sentence:
self.count[word] = self.count.get(word, 0) + 1
def build_vocab(self, min=5, max=None, max_features=None):
"""
生成词典
min: 最小出现的次数
max: 最大的次数
max_features: 一共保留多少个词语
"""
# 删除count中词频小于min的word
if min is not None:
self.count = {word:value for word, value in self.count.items() if value>min}
# 删除词语大于max的值
if max is not None:
self.count = {word:value for word, value in self.count.items() if value<max}
# 限制保留的词语数
# items: [(key1, value1), (key2, value2), ...]
# key = lambda x:x[-1], 表示按照value进行排序
if max_features is not None:
temp = sorted(self.count.items(), key =lambda x: x[-1], reverse=True)[:max_features]
self.count = dict(temp)
# 遍历self.count里的key
for word in self.count:
# 每添加一个次到dict中后, 就用现在dict的长度来表示这个词
self.dict[word] = len(self.dict)
# 得到一个翻转的dict字典
self.inverse_dict = dict(zip(self.dict.values(), self.dict.keys()))
def transform(self, sentence, max_len=max_len):
"""
把句子转化为序列
sentence: [word1, word2, ...]
max_len: int, 对句子进行填充或者裁剪
"""
if max_len is not None:
if max_len > len(sentence):
# 填充
sentence = sentence + [self.PAD_TAG] * (max_len - len(sentence))
print(sentence)
if max_len < len(sentence):
# 裁剪
sentence = sentence[:max_len]
return [self.dict.get(word, self.UNK) for word in sentence]
def inverse_transform(self, indices):
"""
把序列转化为句子
indices: [1, 2, 3, 4, ...]
"""
return [self.inverse_dict.get(idx) for idx in indices]
def __len__(self):
return len(self.dict)
循环神经网络(RNN)
普通的神经网络中,信息的传递是单向的。
现实任务中,网络的输出不仅和当前时刻的输入相关, 也和过去一段时间的输出有关。
普通网络难以处理时序数据, 比如视频、语音、文本等, 时序数据的长度一般是不固定的, 而前馈神经网络要求输入和输出的维度都是固定的。
因此,当处理这类和时序相关的问题时,就需要一种能力更强的模型。
循环神经网络(Recurrent Neural Network, RNN)是一类具有短期记忆能力的神经网络。 在循环神经网络中, 神经元不但可以接受其它神经元的信息, 也可以接受自身的信息, 形成具有环路的网络结构。 神经元的输出可以在下个时间步直接作用到自身(作为输入)。
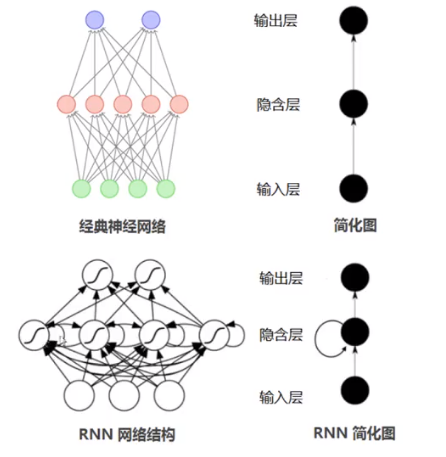
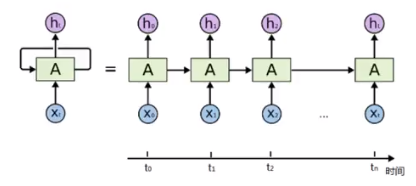
- 时间步: time step, 不同时刻(把输入展开, 每个输入是一个不同时间步上的)
- 循环: 下一个时间步上, 输入不只有当前的时间步的输入, 还有上一时间步的输出
- RNN:具有短期记忆的网络结构, 把之前的输出作为下一个时间步的输入
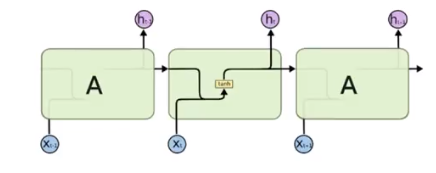
在不同的时间步, RNN的输入都和之前的时间状态有关, $t_n$时刻网络的输出结果是该时刻的输入和所有历史共同的结果, 这就达到了对时间序列建模的目的。
RNN的不同表示和功能可以通过下图看出:
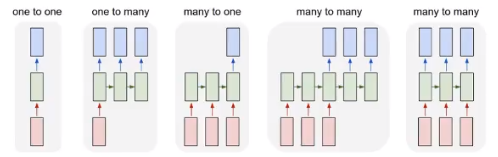
- one-to-one :图像分类
- one-to-many:图像转文字
- many-to-one: 文本分类
- 异步的many-to-many: 文本翻译
- 同步的many-to-many: 视频分类
长短期记忆(Long Short-Term Memory,LSTM)
LSTM基础介绍
LSTM可以学习长期依赖信息。
一个LSTM的单元就是下图中一个绿色方框中的内容:
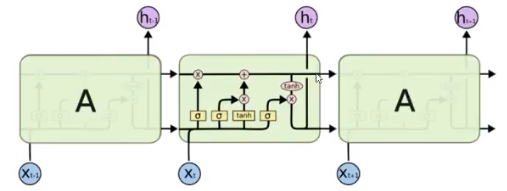
LSTM的核心
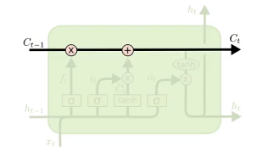
LSTM的核心在于单元(细胞)中的状态, 也就是上图中最上面的那根线。
但是如果只有那一根线, 没有办法实现信息的增加或删除, 所以在LSTM是通过门的结构实现,门可以选择让信息通过或者不通过。
这个门通过sigmoid和点乘(point-wise multiplication)实现
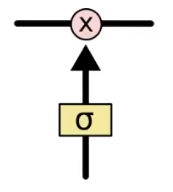
逐步理解LSTM
遗忘门
遗忘门通过simoid函数决定哪些信息会被遗忘
下图就是$h_{t-1}$和$x_t$进行concat之后乘上权重和偏置,通过sigmoid函数, 输出0~1之间的一个值, 这个值会和前一次的细胞状态$C_{t-1}$进行点乘, 从而决定遗忘或者保留
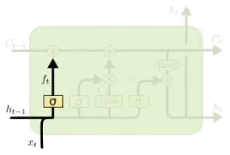
输入门
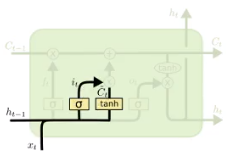
下一步就是决定哪些新的信息会被保留, 这个过程有两步:
- 一个被称为输入门的sigmoid层决定哪些信息会被更新
- tanh会创造一个新的候选向量$\tilde C_t$, 后续可能会被添加到细胞状态中
例如:
我昨天吃了苹果, 今天我想吃菠萝, 在这个句子中,通过遗忘门可以遗忘苹果, 同时更新新的宾语为菠萝。
现在就可以更新旧的细胞状态$C_{t-1}$为新的$C_t$了:
- 旧的细胞状态和遗忘门的结果相乘
- 然后加上 输入门和tanh相乘的结果
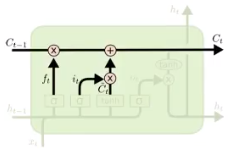
输出门
最后, 我们需要决定什么信息会被输出。
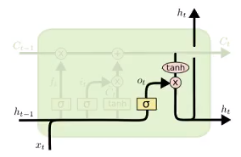
- 前一次的输出和当前时间不的输入concat结果通过sigmoid函数进行处理得到$O_t$
- 更新后的细胞状态$C_t$会经过tanh层的处理, 把数据转化到(-1, 1)的区间
- tanh处理后的结果和$O_t$进行相乘,把结果输出同时传到下一个LSTM的单元
LSTM的输入和输出
- 输入:hidden_state, $X_t$, $C_{t-1}$
- 输出:$H_t$, $H_t$, $C_t$
双向LSTM
单向的RNN, 是根据前面的信息推出后面的,单有时只看前面的词是不够的, 可能需要预测的词语和后面的内容也相关, 此时需要一种机制,能够让模型不仅能够从前王后的具有记忆, 还需要从后往前需要记忆, 此时双向LSTM可以解决这个问题。
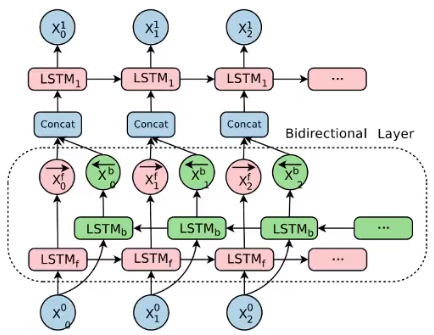
由于是双向LSTM, 所以每个方向都会有一个输出,最终的输出会有两个部分, 所以往往需要concat操作。
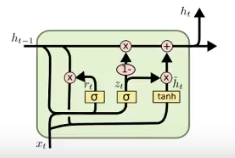
GRU
GRU(Gated Recurrent Unit)是一种LSTM的变形版本, 它将遗忘门和输入门组合成一个“更新门”, 它还合并了单元状态和隐藏状态, 并进行了一些其他更改, 由于他的模型比LSTM简单, 所以越来越受欢迎。
API介绍
LSTM
torch.nn.LSTM(input_size, hidden_size, num_layers, batch_first, dropout, bidirectional)
- input_size: 输入数据的形状, 即embedding_dim
- hidden_size: 隐藏层的数量,即一层有多少个LSTM单元
- num_layer: 即RNN中LSTM单元的层数
- batch_first: 默认值为False, 输入的数据需要[seq_len, batch, feature], 如果为True, 则为[batch, seq_len, feature]
- dropout: 随机失活, 只会在最后一层进行dropout, 也就是num_layer不为1时才有效, 如果num_layer为1会报warning
- bidirectional: 是否使用LSTM, 默认是False
实例化LSTM之后, 不仅需要传入数据,还需要传入前一次的$h_0$(前一次的隐藏状态), 还需要传入$c_0$(前一次的memory)
即:lstm(input, (h_0, c_0))
LSTM的默认输出为output, (h_n, c_n)
- output: (seq_len, batch, num_directions * hidden_size)
- h_\n: (num_layers * num_directions, batch, hidden_size)
- c_n:(num_layers * num_directions, batch, hidden_size)
一层LSTM中只有1个LSTM单元, 它的输出向量为hidden_size维, 每个单词都会进入这个单元, 所以能画成一个细胞不断循环的表现形式。
LSTM中hidden_state既作为当前时间步的隐藏状态,又作为当前时间步的输出, c仅起记忆细胞保存信息的作用, 因此输出的最后一个时间步,也就是最后一个词的输出, 就等于最后一个时间步在最后一层输出的隐藏状态。
隐藏状态仅保留每层最后一个时间步的输出, 不保存中间时间步的隐藏状态。
LSTM的使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import torch
import torch.nn as nn
import torch.nn.functional as F
batch_size = 10
seq_len = 20
vocab_size = 100
embedding_dim = 30
hidden_size = 18
num_layer = 1
input = torch.randint(low=0, high=100, size=[batch_size, seq_len])
embedding = nn.Embedding(vocab_size, embedding_dim)
input_embeded = embedding(input)
lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, num_layers=num_layer, batch_first=True)
output, (h_n, c_n) = lstm(input_embeded)
print(output.size())
print("*" * 100)
print(h_n.size())
print("*" * 100)
print(c_n.size())
双向LSTM
如果需要使用双向LSTM, 则在实例化LSTM的过程中,需要把LSTM中的bidirectional设置为True,同时h_0和c_0使用num_layer * 2。
双向LSTM中:
- output: 按照正反计算的结果顺序在第2个维度进行拼接,正向第一个拼接反向的最后一个输出
- hidden state: 按照得到的结果在第0个维度进行拼接, 正向第一个之后接着是反向第一个
前向的LSTM中,最后一个time step的输出的第前hidden_size个和最后一层向前传播h_1的输出相同。
LSTM和GRU的使用注意点。
第一次调用前, 需要初始化隐藏状态, 如果不初始化, 默认创建全为0的隐藏状态。
往往会使用LSTM or GRU的输出的最后一维的结果, 来代表LSTM、GRU对文本的处理的结果, 其形状为[batch、 num_directions * hidden_size]
- 并不是所有模型都会使用最后一维的结果
- 如果实例化LSTM的过程中, batch_first=False, 则output[-1] or output[-1, :, :]可以获取最后一维
- 如果实例化LSTM的过程中, batch_first=True, 则output[:, -1, :]可以获取最后一维
如果结果是(seq_len, batch_szie, num_directions * hidden_size), 需要把它转换为(batch_size, seq_len, num_directions * hidden_size)的形状, 不能够使用view等变形的方法, 往往使用output.permute(1, 0, 2)来实现上述效果。
使用双向LSTM的时候, 往往会使用每个方向最后一次的output, 作为当前数据经过双向LSTM的结果
- 即: torch.cat([h_1[-2, :, :], h_1[-1, :, :]], dim=-1)
- 最后的表示的size是:[batch_size, hidden_size * 2]
上述在GRU中同理。
使用LSTM完成文本情感分类
为了达到更好的效果, 对之前的模型作如下修改
- MAX_LEN = 200
- 构建dataset的过程,把数据转化为2分类的问题, pos为1, neg为0
- 在实例化LSTM的时候使用dropout=0.5, 在model.eval()的过程中,dropout自动会为0
修改模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
class IMDBLSTMModel(nn.Module):
def __init__(self):
super(IMDBLSTMModel, self).__init__()
self.embedding = nn.Embedding(len(ws), 100)
self.lstm = nn.LSTM(input_size=100, hidden_size=lib.hidden_size, num_layers=lib.num_layers, batch_first=True, bidirectional=lib.bidirectional, dropout=lib.dropout)
self.fc = nn.Linear(lib.hidden_size * 2, 2)
def forward(self, x):
# 进行embedding操作, 形状: [batch_szie, max_len, 100]
x = self.embedding(x)
# x: [batch_size, max_len, 2 * hidden_size], h_n, c_n: [2 * 2, batch_size, hidden_size]
x, (h_n, c_n) = self.lstm(x)
# 获取两个方向最后一次的output进行concat操作
output_fw = h_n[-2, :, :] # 正向最后一次输出
output_bw = h_n[-1, :, :] # 反向最后一次输出
output = torch.cat([output_fw, output_bw], dim=-1) # [batch_size, hidden_size * 2]
out = self.fc(output)
return F.log_softmax(out, dim=-1)
model = IMDBLSTMModel().to(lib.device)
optimizer = torch.optim.Adam(model.parameters(), 0.001)
if os.path.exists("./saved_models/model.pkl"):
model.load_state_dict(torch.load("./saved_models/model.pkl"))
optimizer.load_state_dict(torch.load("./saved_models/optimizer.pkl"))
def train(epoch):
for idx, (input, target) in enumerate(get_dataloader(train=True)):
input = input.to(lib.device)
target = target.to(lib.device)
output= model(input)
loss = F.nll_loss(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, idx, loss.item())
if idx % 100 == 0:
torch.save(model.state_dict(), "./saved_models/model.pkl")
torch.save(optimizer.state_dict(), "./saved_models/optimizer.pkl")
def eval():
loss_list = []
acc_list = []
for input, target in tqdm(get_dataloader(train=False), total=len(get_dataloader(train=False)), ascii=True, desc="test: "):
input = input.to(lib.device)
target = target.to(lib.device)
with torch.no_grad():
output = model(input)
cur_loss = F.nll_loss(output, target)
loss_list.append(cur_loss.cpu().item())
pred = output.max(dim=-1)[-1]
cur_acc = pred.eq(target).float().mean()
acc_list.append(cur_acc.cpu().item())
print("total loss, acc: ", np.mean(loss_list), np.mean(acc_list))
if __name__ == "__main__":
# for i in range(10):
# train(i)
eval()