Abstract
序列转换模型现在是基于复杂的循环和卷积网络的, 包括编码器和解码器。
最好表现的模型通过注意力机制连接一个编码器和解码器。
我们提出一种新的网络结构, 叫做Transformer, 仅基于注意力机制, 完全脱离了循环和卷积网络。
在WMT 2014 English-to-German翻译任务中取得了28.4的BLEU。 (BLEU (其全称为Bilingual Evaluation Understudy), 其意思是双语评估替补。所谓Understudy (替补),意思是代替人进行翻译结果的评估。尽管这项指标是为翻译而发明的,但它可以用于评估一组自然语言处理任务生成的文本。)
在WMT 2014 English-to-French翻译任务中, 单模型取得了41.0的SOTA BLEU成绩。
Introduction
First Paragraph
循环神经网络, LSTM和RRU, 建立了序列模型和转换模型。
大量的工作推动着循环语言模型和编码器-解码器结构的发展。
Second Paragraph
循环模型随着输入和输出序列的符号位置成倍增加计算成本。
每个时间步, 产生一个隐状态h_t, h_{t-1}和输入作为位置t函数的输入。
这种序列阻止了训练样本的并行, 当内存受限于整个训练样本时, 这对于长序列非常关键。
最近的工作通过factorization tricks和condition computation提升计算效率, 但是根本上仍然受到序列化计算的约束。
Third Paragraph
最近的工作通过factorization tricks和condition computation提升计算效率, 但是根本上仍然受到序列化计算的约束。
Forth Paragraph
Transformer避开了循环的结构, 而是完全依赖于注意力机制来描述输入和输出之间的全局依赖。
Transformer可以显著地并行化并且可以在翻译质量上达到新的SOTA, 在8块P100训练12小时之后。
Background
First Paragraph
Extended Neural GPU , ByteNet and ConvS2S 减少序列的计算, 它们使用卷积神经网络作为基本的块, 对所有的输入和输出位置并行地计算隐藏表征。
在这些模型中, 任意两个输入和输出位置的依赖建立所需的操作数随着距离的增加而增多, ConvS2S线性增长,ByteNet对数增加。
Transformer 将这个操作的数量减小为一个常数, 尽管由于平均注意力位置加权使得有效的分辨率降低。 我们使用Multi-Head Attention 解决这个问题。
Second Paragraph
Self-attention, 有时叫做 intra-attention, 关联一个序列的不同位置以计算这个序列的表征。
Third Paragraph
End-to-end memory network 基于一个循环注意力机制而不是一个对齐序列循环 在简单语言问答和语言模型任务上 表现良好。
Forth Paragraph
Transformer 是完全依赖自注意力而不是对齐序列的RNN或者卷积计算它的输入和输出的表征的第一个转换模型。
Model Architecture
Encoder and Decoder Stacks
Encoder
Encoder 有 N=6 个叠起来的 identical layers组成。
每层有两个子层:
- 第一层是multi-head self-attention mechanism
- 第二层是一个全连接层
每个子层使用残差连接, 然后进行规范化
\[LayerNorm(x + Sublayer(x))\]为了加速这些残差连接, 模型中所有的子层, 也就是embedding层, 产生输出维度$d_{model} = 512$
Decoder
Decoder 也由 N=6 个叠起来的 identical layers组成。
除了编码器中的两个子层, decoder还插入第三个子层, 它对所有encoder输出执行multi-head attention。
与encoder类似, 对decoder的每个子层使用残差连接, 然后跟一个layer normalization。
修改了decoder中子层的self-attention, 确保位置i的预测仅依赖于不大于i的位置的输出。
Attention
Scaled Dot-Product Attention
输入由一系列的维度为$d_k$的queries和keys以及维度为$d_v$的values组成。
计算query对所有keys的点积除以$\sqrt{d_k}$, 然后作softmax得到对values的权重。
事实上, 我们对一组query同时做attention计算, 打包成一个矩阵Q。
keys和values也一起打包成矩阵K和V。
\[Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\]两个最常用的attention函数是additive attention和dot-product attention:
- Additive attention使用一个隐藏层的前馈神经网络实现
- dot-product attention和additive attention 理论上有相似的复杂度, 但是dot-product attention更快以及更有空间效率, 因为它可以被矩阵乘法代码高度优化
尽管$d_k$值很小的时候, 两种注意力机制表现相似, 但是当$d_k$很大的时候, 在没有尺度缩放的情况下 additive attention 比 dot product attention 表现更好。
对于较大的$d_k$, dot-product规模变大, 使得softmax函数产生非常小的梯度, 为了对抗这种影响,我们将dot-product乘以$\frac{1}{\sqrt{d_k}}$缩放尺度。
Multi-Head Attention
相比于使用$d_{model}$维度的key, value, queries单个注意力函数, 发现将query, keys和values投影到$d_k$, $d_k$和$d_v$维度学习不同的线性投影 投影 h次 更有益。
对每个投影后的queries, keys和values并行执行attention函数, 产生d_v维的输出values。
多个attention的输出结果concatenate之后再次投影, 产生最后的结果。
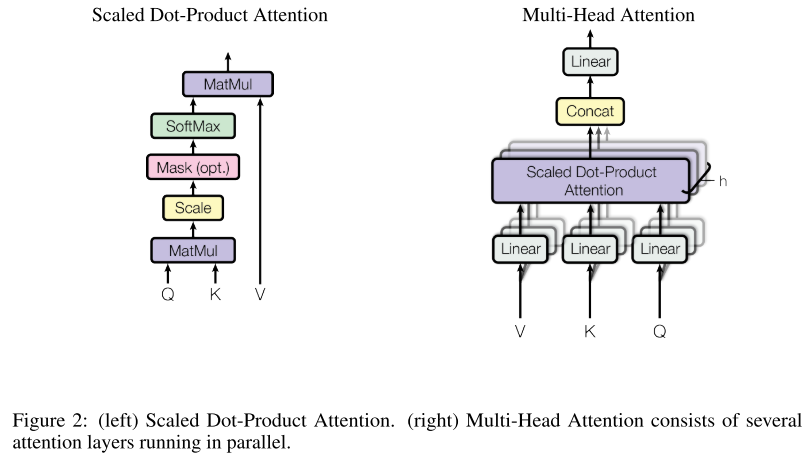
Multi-head attention 使得模型可以从不同位置的不同子空间表征共同处理信息。
\[MultiHrad(Q, K, V) = Concat(head_1, ..., head_h)W^O \\ where \quad head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)\]其中投影参数矩阵$W_i^Q \in R^{d_{model} \times d_k}$, $W_i^K \in R^{d_{model} \times d_k}$, $W_i^V \in R^{d_{model} \times d_v}$和$W^O \in R^{hd_v \times d_{model}}$。
本文中使用 h=8 并行 attention 层, $d_k = d_w = d_{model/h} = 64$。
Applications of Attention in our Model
对encoder-decoder attention 层:
- queries来自于前面的decoder层, key和values来自于encoder的output
- 这使得decoder的每个位置处理输入序列的所有位置的信息
- 这使得decoder的每个位置处理输入序列的所有位置的信息
encoder包含self-attention层:
- self-attention层中所有keys, values和queries来自于同一位置, 在本文中,来自于encoder前面层的输出
- encoder的每个位置处理encoder当前位置前面所有层的位置
类似地,decoder中的自注意力处理该位置前的所有位置, 我们通过将非法位置的softmax输出的值masking out(设为$-\infty$)实现。
Position-wise Feed-Forward Networks
除了注意力子层, 编码器和解码器每层包含一个全连接网络, 它有两个线性变化组成,两个线性变换之间有一个ReLU激活。
\[FFN(x) = max(0, xW_1 + b_1)W_2 + b_2\]输入和输出的维度是$d_{model} = 512$, 层内的维度$d_{ff} = 2048$。
Embeddings and Softmax
用学习到的embeddings将输入token和输出tokens转换为$d_{model}$维度的向量。
用学习的线性变换和softmax函数将decoder的输出转换为预测next-token的概率。
两个embedding层之间和pre-softmax 线性变换 共享权重。
embedding layers乘以权重 $\sqrt{d_{model}}$。
Positional Encoding
为了让模型利用序列的位置信息, 我们必须插入序列中tokens的相对和绝对位置信息。
我们在encoder和decoder栈的底部插入positional encoding到输入embeddings。 positional encodings和embeddings一样有相同的维度$d_{model}$, 因此它们两个可以相加。