Abstraction
在多尺度表征特征对大量的计算机视觉任务是非常重要的。
本文提出一种Res2Net的CNN块, 通过在一个残差块中构造多级的类残差连接。
Res2Net为每层在granular level表征多级特征并且增加感受野的范围。
Res2Net块可以插入SOTA backbone CNN模型, 比如ResNet、ResNeXt和DLA,在CIFAR-100和ImageNet展示了表现。
Introduction
First Paragraph
第一, 物体可以在单张图像中以不同大小出现。 比如沙发和杯子是不同的大小。
第二, 一个物体的必要的上下文信息可能覆盖比物体本身大得多的区域。 比如, 我们需要依赖大的桌子作为上下文来判断放在它上面的黑色色块是一个杯子还是一个笔筒。
第三, 从不同尺度感知信息 对精细地分类和语义分割等任务 理解物体的部分 是必要的。
Second Paragraph
在视觉任务中, 获取多尺度的表征需要特征提取器使用大范围的感受野来描述不同尺度的物体/部分/上下文。
CNN通过叠加卷积操作 学习 由粗到细 的多尺度特征。
Thrid Paragraph
AlexNet和VGGNet通过堆叠卷积操作, 使得多尺度的特征学习可行。
多尺度能力的效率通过以下方式提升:
- InceptionNet通过使用不同的卷积核大小
- residual modules
- shortcut connections(DenseNet)
- hierarchical layer aggregation(DLA)
Forth Paragraph
我们不像之前的方法一样提升层级别的CNN的多尺度表征能力, 而是通过一个更granular level提升多尺度表征能力。
现在的一些工作通过利用不同分辨率的特征提升多尺度的能力, 我们提出的方法在指的是granular level的多个感受野。
使用一组更小的卷积核组替换n个通道的3x3卷积核, 每个有w个通道。
这些小的卷积核组以一种级联的类似残差的方式以增加尺度的数量。
将输入特征图分成多个组。
前面组的输出特征和另外一个输入特征一起送入下一组卷积核。
重复这个过程多次直到所有的输入特征处理完成。
最后, 从所有组得到的特征图拼接在一起然后送入另外一个1x1卷积核的组 以 融合信息。
Related Work
Backbone Networks
CNN输入信息是一种由细到粗的方式, 因此CNN具备基本多尺度特征的表征能力。
Network in Network(NIN)插入多层感知机作为小的网络到一个大的网络中提升网络的判别能力。
NIN引入的1x1卷积称为备受欢迎的融合特征的模块。
Multi-scale Representations for Vision Tasks
Object detection
R-CNN依赖于backbone网络提取多尺度的特征,比如VGGNet。
SPP-Net利用在backbone网络之后的空间金字塔池化提升多尺度的能力。
Fater R-CNN进一步提出RPN用不同的尺度生成bounding boxes。
FPN引入特征金字塔从单张图像中提取不同尺度的特征。
SSD利用不同尺度下不同阶段处理视觉信息的特征。
Semantic segmentation.
为更有效的语义分割提取物体必要的上下文信息, 需要CNN模型处理不同尺度下的特征。
FCN
DeepLab引入级联atrous 卷积模块保留空间分辨率的同时增加感受野。
PSPNet通过金字塔池化方式从基于区域的特征累计上下文信息。
Salient object detection.
在一张图像中精确地定位salient object区域需要同时理解用于确定object saliency的大尺度的上下文信息和精确定位object边界的小尺度特征
Concurrent Works
Big-Little Net由不同卷积复杂度分支组成的是一个多分支网络。
Octave Conv在不同频率将标准的卷积分成两种分辨率取处理特征。
MSNet利用高分辨率网络学习高频率残差, 这些残差通过低分辨网络学习到的特征上采样得到。
HRNet在网络中引入高分辨率表征并且通过重复执行多尺度融合以增强高分辨率表征。
Res2Net Block 在一个残差块模块中 hierarchical 类残差的连接 使得不同的感受野在一个granular level捕获细节和全局特征。
Res2Net
Res2Net Module
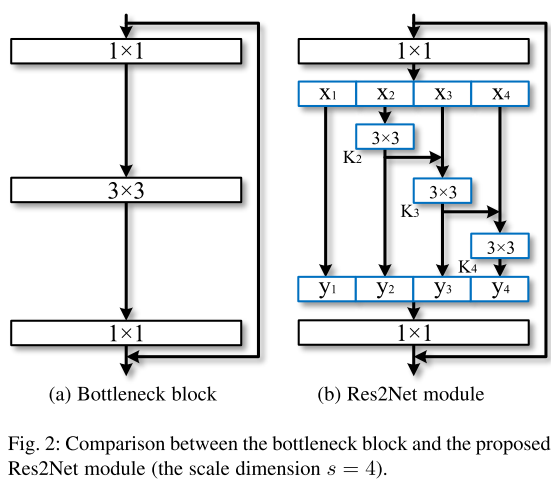
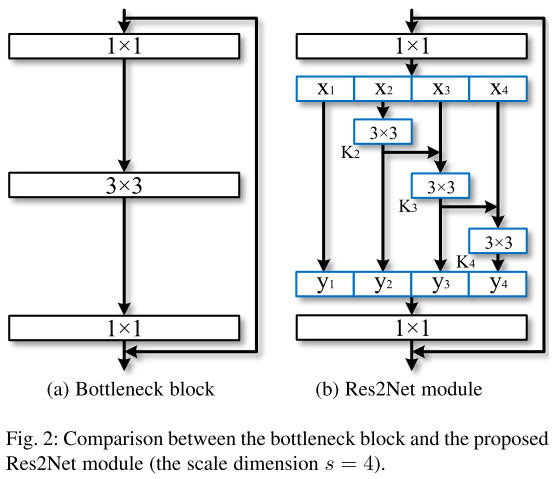
Fig.2(a) 是ResNet、ResNeXt、DLA的基本块:
- 没有在bottleneck block中使用一组3x3的卷积核提取特征
- 将一组3x3的卷积核和替换成更小的多组卷积核, 连接不同卷积核组以一种hierarchical类残差的形式
Fig.2 展示了 bottleneck block 和 Res2Net 的不同:
- 在1x1卷积之后, 我们将特征图分成s个特征图子集, 表示为x_i, 其中 i \in {1, 2, …, s}
- 每个特征子集x_i有相同的空间尺寸, 但是通道数只有1/s输入特征图的通道数
- 除了x_1, 每个x_i有一个3x3卷积,表示为K_i()
- 用y_i表示K_i()的输出
- 特征子集x_i加上K_{i-1}()的输出送入K_i()中
- 为了增加s的同时减少参数,对x_1省略了3x3的卷积
K_i()的每个3x3卷积操作可以感受到所有分块特征{x_j, j<=i}的特征信息.
每次一个特征分块x_j穿过一个3x3的卷积操作, 输入结果能够获得一个比x_j更大的感受野。
因为它们的组合, Res2Net模块的输出包含不同数量和不同感受野大小的组合。
Res2Net拆分以一种多尺度的方式, 这有利于同时提取全局和局部的信息。
为了更好地融合不同尺度的信息, 我们拼接所有的拆分并把他们传入1x1的卷积。
为了减少参数量,省略了第一个分块的卷积, 它也可以看做一种特征复用。
Integration with Modern Modules
Dimension cardinality: dimension cardinality 表示 一个卷积核 组 的 数量, 这种卷积核从单个分支到多个分支的维度变化提升CNN模型的表征能力。
SE block: SE block 通过建模通道间的相互依赖自适应地重新校准通道级别的特征。
Integrated Models
因为Res2Net不需要指定所有网络结构的要求, 并且多尺度的能力与层级的CNN模型特征不相关, 因此我们可以将Res2Net模块融合到SOTA模型中。
提出的scale dimension与先前工作的cardinality dimension和width dimension不相关。
scale 确定之后, 调整cardinality和with来维持整个网络的复杂度。
EXPERIMENTS
Implementation Details
图像从一个re-size图像中随机裁剪出224x224像素。
SGD, 权重衰减0.0001, 动量0.9. 四块titan Xp 256 batch size。
learning rate 0.1 开始, 每 30 epochs 除以 10。
ImageNet
Performance gain
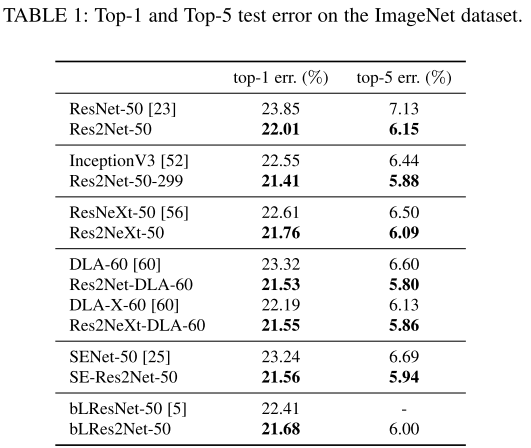
Table.1 所有Res2Net模块的尺度s=4。
Res2Net50比ResNet50 top-1 错误率提升 1.84%。
Res2NeXt50比ResNeXt50 top-1 错率率提升 0.85%。
Res2Net-DLA-60 比 Res2Net-DLA-60 top-1 错误率提升0.64%。
SE-Res2Net-50 比 SENet-50 top-1 错误率提升1.68%。
bLRes2Net-50 比 bLRes2Net-50 错误率提升0.73%。
输入图像为299像素时, Res2Net-50-299 比 Inception V3 top-1 错误率 提升 1.14%。
Going deeper with Res2Net
Res2Net-101 比 ResNet-101 top-1 错误率 提升 1.82%。
Res2Net-50 比 ResNet-50 top-1 错误率 提升 1.84%。
Res2Net-101 比 DenseNet-161 top-1 错误率 提升 1.54%。
Effectiveness ofscale dimension
Res2Net-50 14w x 8s 比 ResNet-50 top-1 错误率提升1.99%, 保持复杂度, K_i()宽度减少, 尺度增大。
Res2Net-50 26w x 8s 比 ResNet-50 top-1 错误率提升3.05%。
Res2Net-50 18w x 4s 比 ResNet-50 top-1 错误率提升0.93%, 但是仅有69%的FLOPs。
特征被分成了{y_i},由于这种层级的连接, 它们需要按顺序地计算特征, 但是Res2Net模块引入的额外的计算时间通常可以忽略。
CIFAR
ResNeXt-29 8c x 64w 用作baseline model。
Res2NeXt-29 6c x 24w x 6s 比 baseline 提升 1.11%。
Res2NeXt-29 6c x 24w x 4s 比 ResNext-29 16c x 64w 表现更好, 但是只有它 35% 的参数量。
我们在有更少的参数的情况下, 相比于DenseNet-BC(k = 40)取得了更好的表现。
scale维度与width和cardinality是不相关的。
将SE block 加入结构中,用更少的参数, 仍然比 ResNeXt-29, 8c x 64w - SE baseline表现更好 。
Scale Variation
通过增加CNN的维度, 包括cardinality, depth和scale, 来提升 baseline model 的性能。 固定其他维度, 调整一个维度来增加模型的容量。
baseline model 的 depth、 cardinality和scale分别为 29, 6, 1。
结果表明scale是有效提升模型表现的维度, 它比其他的维度更加有效率。
当模型的scale 为 5 和 6时, 只有有效的表现提升, 我们认为这可能是因为32x32的图像对于很多尺度来说太小了。