目前企业中的常见的聊天机器人
QA BOT(问答机器人): 回答问题
- 代表:智能客服
- 比如:提问和回答
TASK BOT(任务机器人): 帮人们做事情
- 代表: siri
- 比如:设置明天早上9点的闹钟
CHAT BOT(聊天机器人): 通用、 开放聊天
- 代表:微软小冰
常见的聊天机器人怎么实现的
问答机器人的常见实现手段
信息检索、搜索(简单, 效果一般, 对数据问答对的要求高)
- 关键词:tfidf、SVM、朴素贝叶斯、RNN、CNN
知识图谱(相对复杂, 效果好, 很多论文)
- 在图形数据库中存储知识和知识间的关系、把问答转化为查询语句、能够实现推理
任务及其人的常见实现思路
- 语音转文字
- 意图识别、领域识别、文本分类
- 槽位填充: 比如买机票的机器人 使用命令识别体识别填充, 从{位置}到{位置}的票
- 回话管理、回话策略
- 自然语言生成
- 文本转语音
闲聊机器人的常见实现思路
- 信息检索(简单、能够回答的话术有限)
- seq2seq和变种(答案覆盖率高, 但是不能保证答案的通顺)
企业中的聊天机器人是如何实现的
阿里小蜜-电商智能助理是如何实现的
主要交互过程
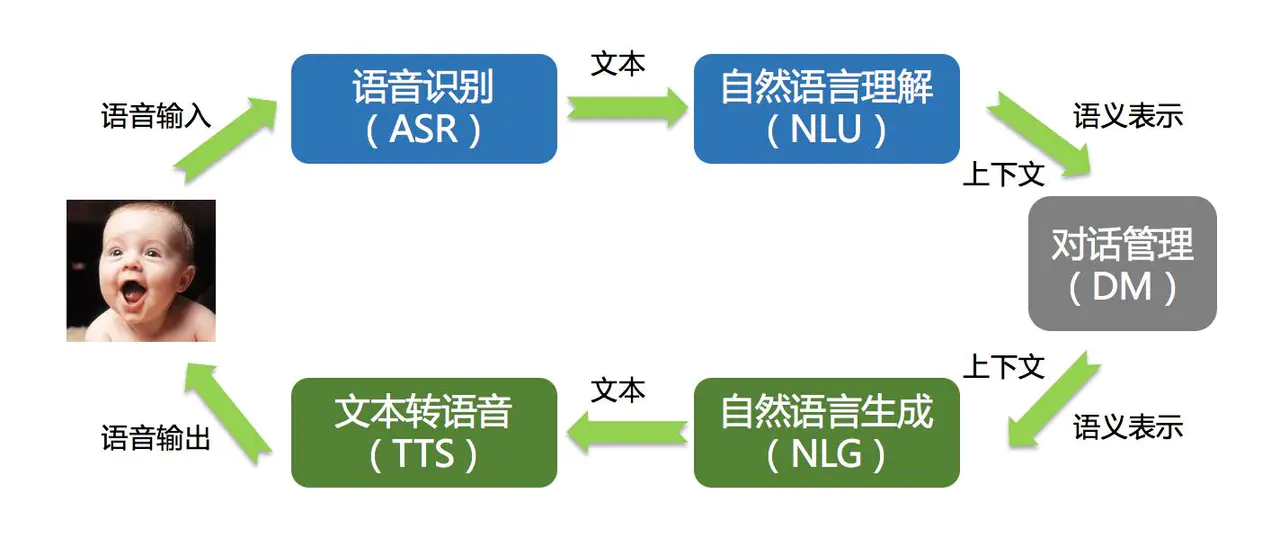
从图中可以看出:
- 输入: 语音转化为文本, 进行理解之后根据上下文得到语义的表示
- 输出: 根据语义的表是和生成方法得到文本, 再把文本转化为语音输出
技术架构
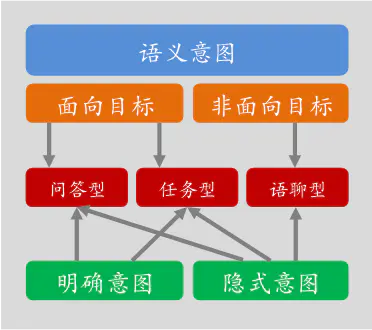
可以看出其流程为:
- 判断用户意图
- 如果意图为面向目标:可能是问答型或者是任务型
- 如果非面向目标: 可能是语聊型
检索模型流程(小蜜还用了其他的模型, 这里以此为例)
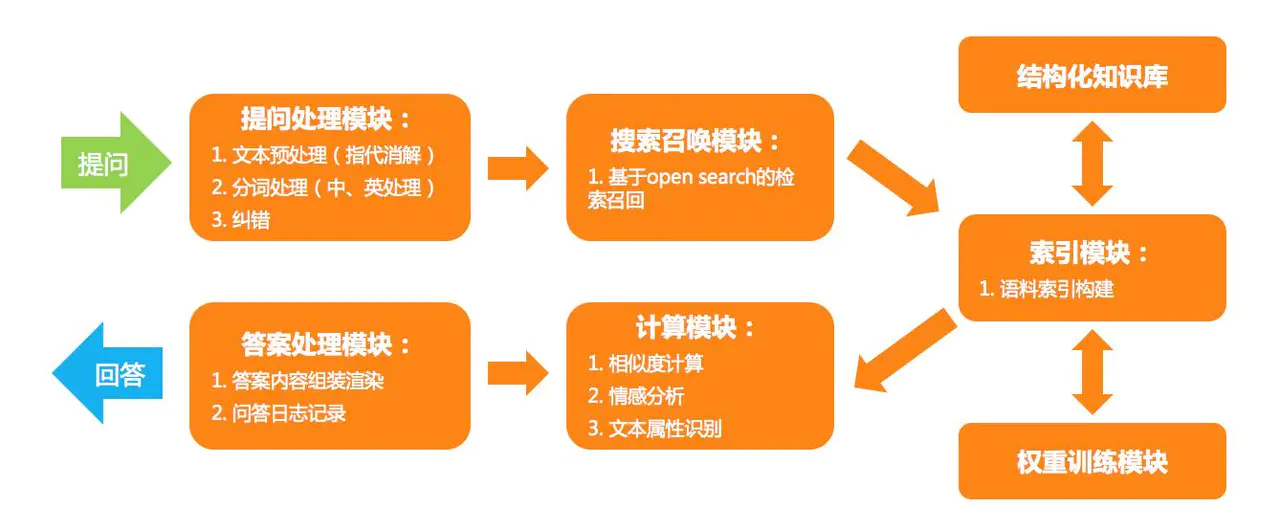
通过上图可知, 小蜜的检索式回答的流程大致为:
- 对问题进行处理
- 根据问题进行召回, 使用了提前准备的结构化的预料和训练的模型
- 对召回的结果进行组长和日志记录
- 对召回的结果进行相似度计算,情感分析和属性识别
- 返回组装的结果
58同城智能客服帮帮如何实现的
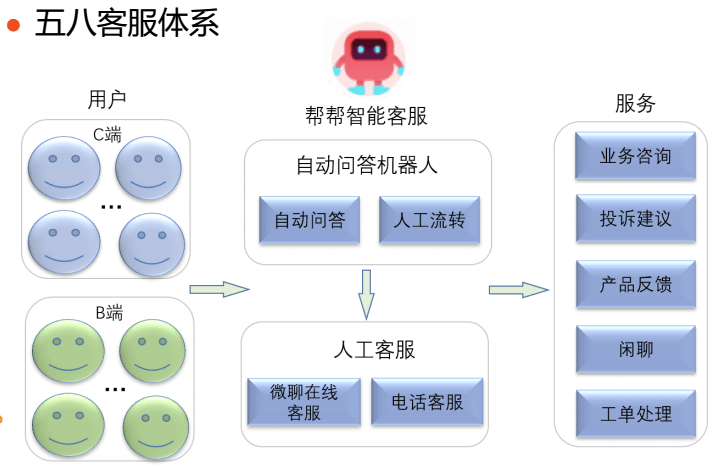
58客服体系
整体架构
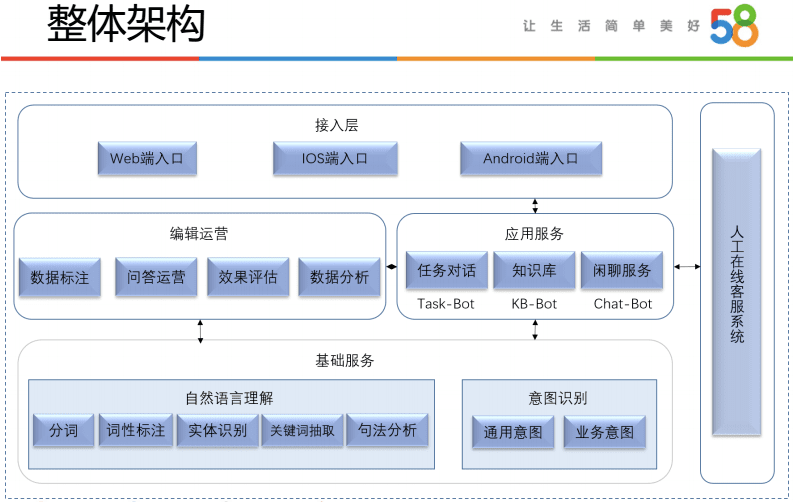
整体来看, 58的客服架构分为三个部分
- 基础服务, 实现基础的NLP的功能和意图识别
- 应用对话部分实现不同意图的模型, 同时包括编辑运营等内容
- 提供对外的接口
业务咨询服务流程
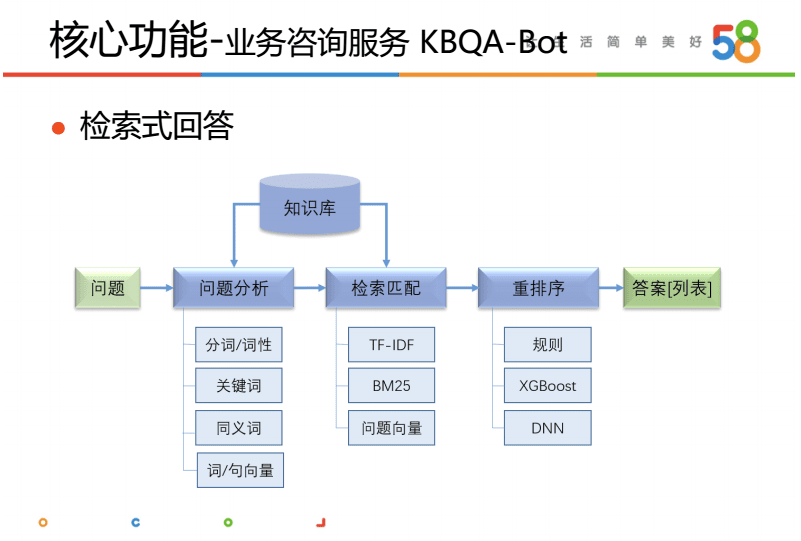
KB-bot的流程大致为:
- 对问题进行基础处理
- 对答案通过tfidf等方法进行召回
- 对答案通过规则、深度神经网络等方法进行重排序
- 返回答案排序列表
使用融合的模型
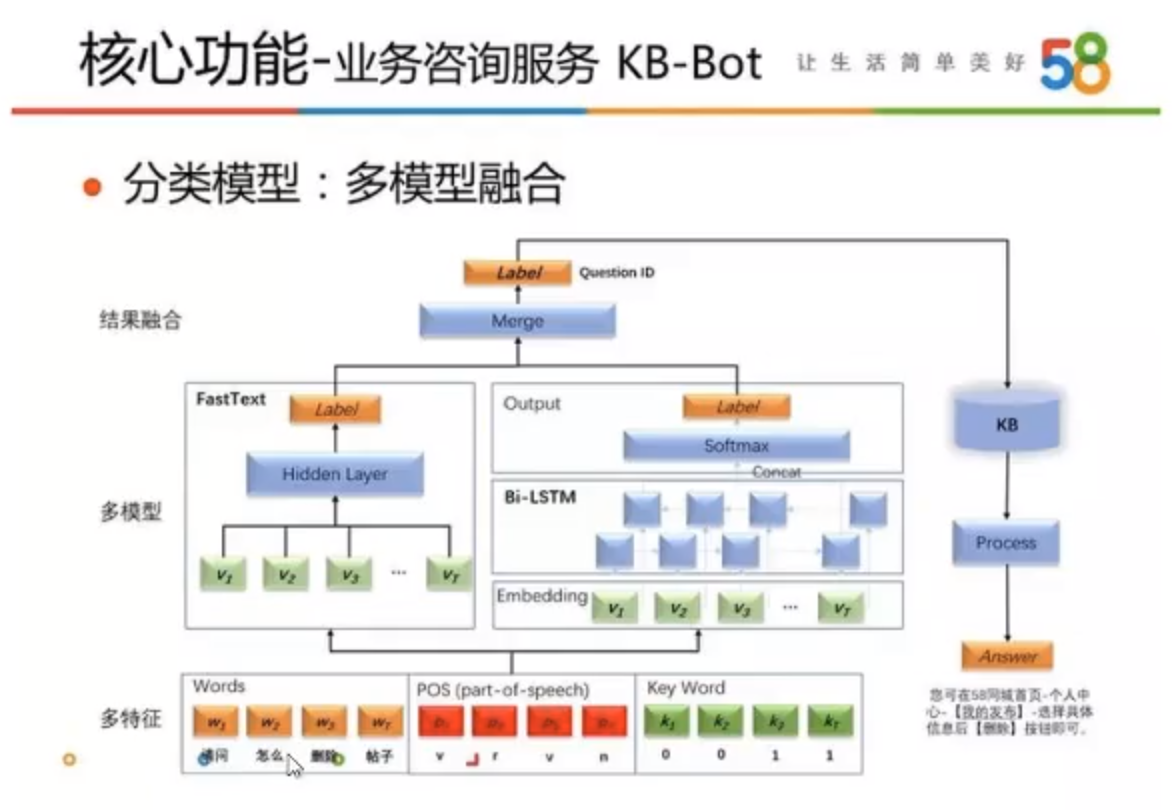
在问答模型的深度神经网络模型中使用了多套模型进行融合来获取结果:
- 在模型层应用了FastText、TextCNN和Bi-LSTM等模型
- 在特征层尝试使用了单字、词、磁性、词语属性等多种特征
通过以上两个模型来组合获取相似的问题, 返回相似问题ID对应的答案
58的闲聊机器人
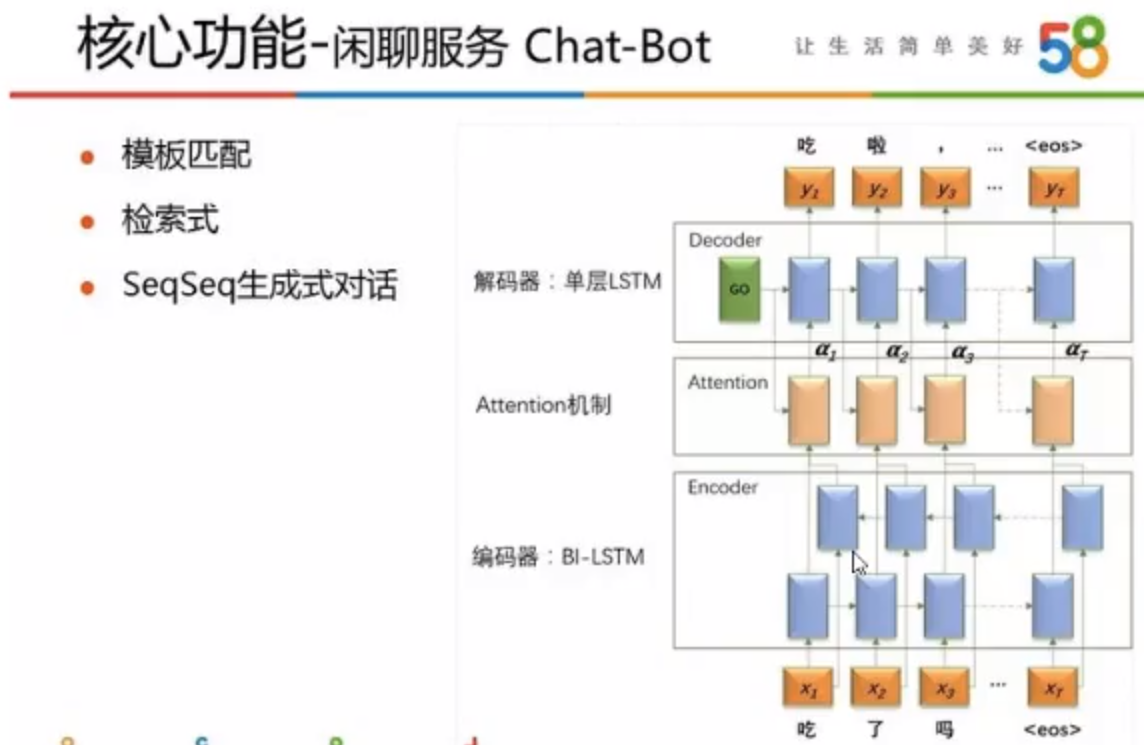
58同城的闲聊机器人使用三种方法包括:
- 基于末班匹配的方法
- 基于搜索的方法获取
- 使用seq2seq的神经网络来实现
解决不了转人工服务
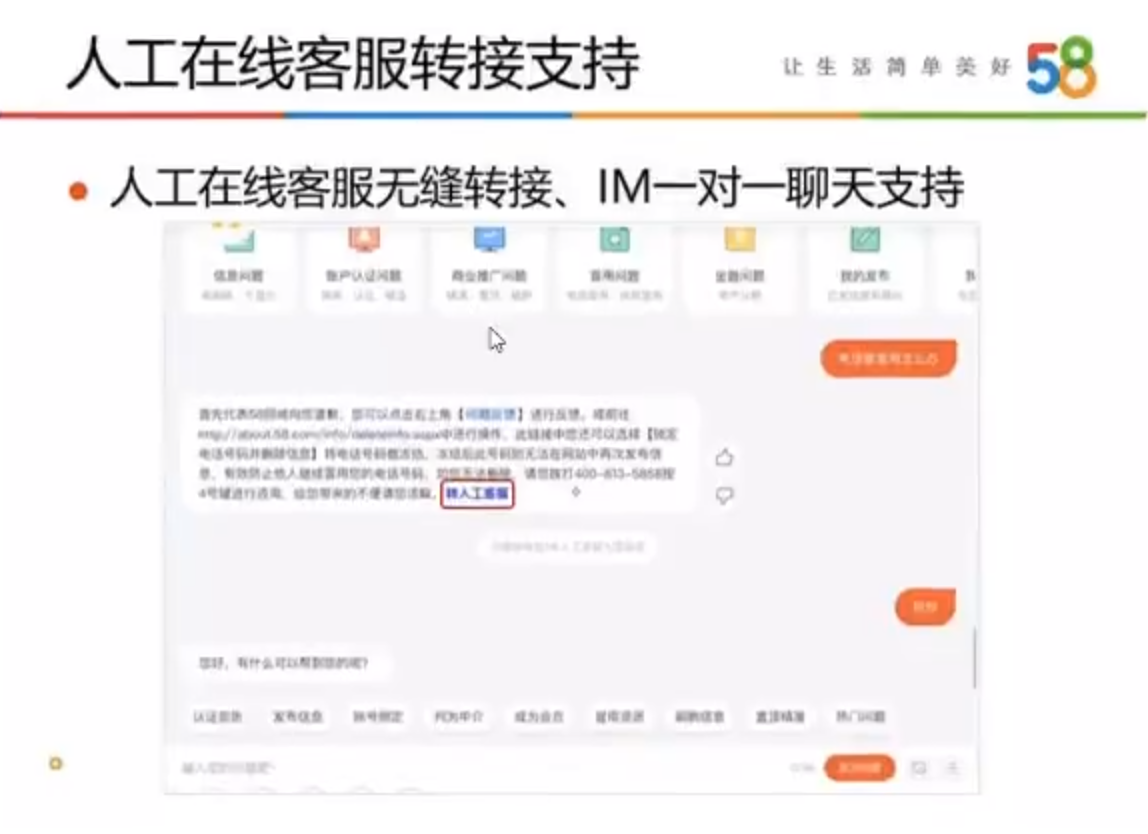
项目流程介绍
整体架构
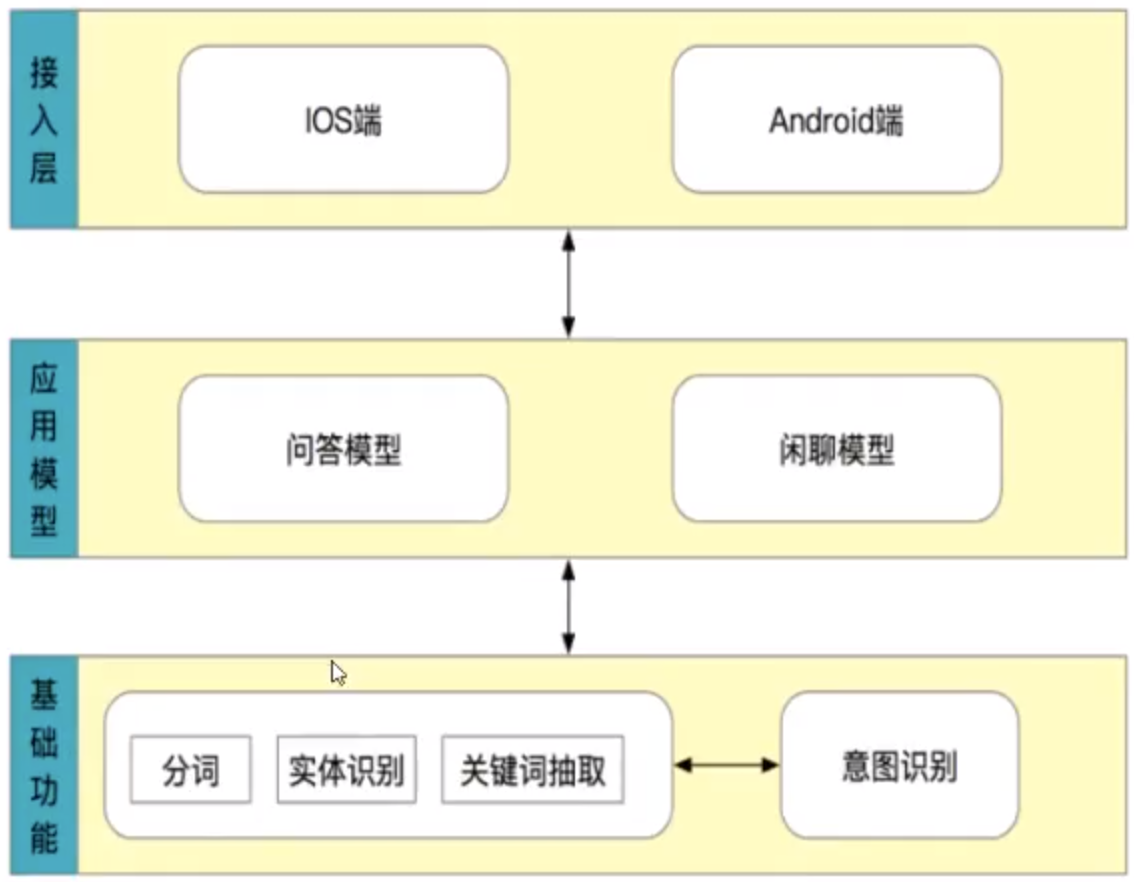
整个流程的描述如下:
- 接受用户的问题之后, 对问题进行基础的处理
- 对处理后的问题进行分类, 判断其意图
- 如果用户希望闲聊, 那么调用闲聊模型返回结果
- 如果用户希望咨询问题, 那么调用问答模型返回结果
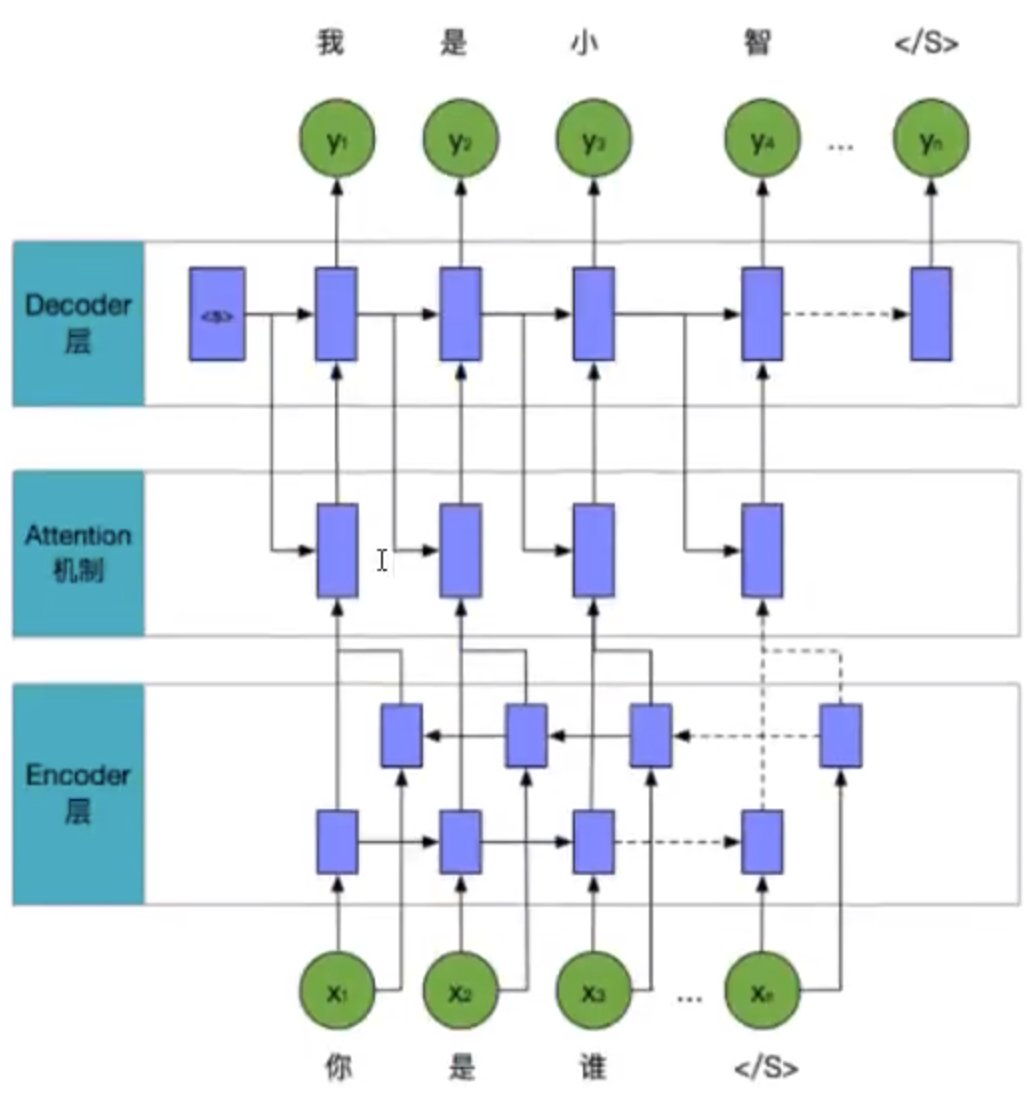
闲聊模型
闲聊模型使用了seq2seq模型实现
包含:
- 对数据的embedding
- 编码层
- attention机制的处理
- 解码层
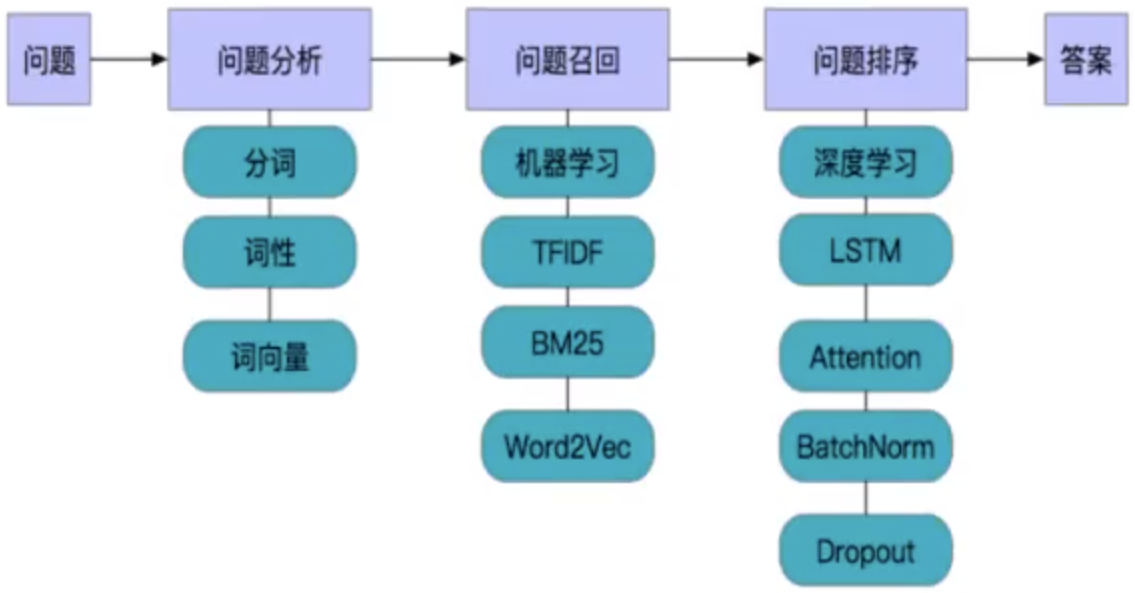
问答模型
问答模型使用了召回和排序的机制来实现, 保证获取的速度的同时保证了准确率
- 问题分析:对问题进行基础的处理, 包括分词, 词性的获取, 词向量的获取
- 问题的召回: 通过机器学习的方法进行海选, 还选出大致满足要求的相似问题的前K个
- 问题的排序: 通过深度学习的模型对问题计算准确率, 进行排序
- 设置阈值, 返回结果
语料准备
分词词典
最终的词典格式:
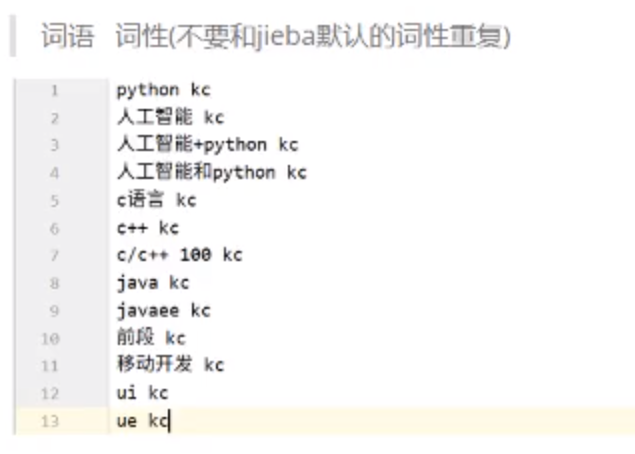
词典来源
- 各种输入法的词典
例如: https://pinyin.sogou.com/dict/cate/index/97?rf=dictindex
例如: https://shurufa.baidu.com/dict_list?cid=211
词典处理
输入法的词典都是特殊格式, 需要使用特殊的工具才能把它转化为文本格式
下载地址: https://github.com/studyzy/imewlconverter
对多个词典文件内容进行合并
下载不同平台的多个词典之后, 把所有的txt文件合并到一起供之后使用
准备停用词
什么是停用词?
对句子进行分次之后, 句子中不重要的词
停用词的准备
常用停用词下载地址: https://github.com/goto456/stopwords
手动筛选和合并
对于停用词的具体内容, 不同场景下可能需要保留和去除的词语不一样
比如: 词语 哪个 ,很多场景可以删除, 但是在判断语义的时候则不行
问答对的准备
现有问答对的样式
问答对有两部分, 一部分是整理的问答对, 一部分是excel中的问答对,
最终我们需要把问答对分别整理到两个txt文档中, 如下图(左边是问题, 右边是答案):

Excel中的问答对如下图:

相似问答对的采集
采集相似问答对的目的
后续在判断相似度的时候, 需要有语料来进行模型的训练, 输入两个句子, 输出相似度, 这个语料不好获取, 所以决定从百度直到入手, 采集百度直到上面的相似问题,如下图所示:
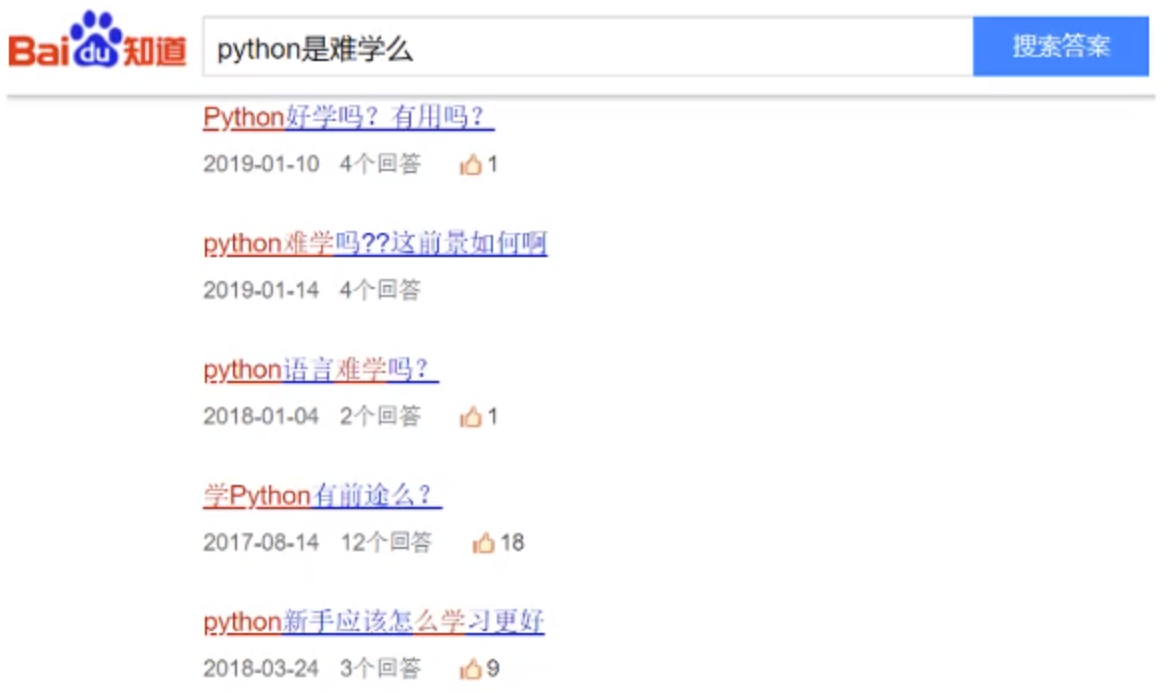
上面采集的数据会存在部分噪声, 部分问题搜索到的结果语义上并不是太相似
手动构造数据
根据前面的问答对的内容, 把问题大致分为了若干类型, 对不同类型的问题设计模板, 然后构造问题, 问题模块如下:

意图识别和文本分类
文本分类的目的
文本分类的目的就是为了 意图识别
在我们当前的项目下, 只有两种意图需要被识别出来, 所以对应的应该是2分类问题。
如果聊天机器人有多个功能, 那么需要分类的类别就有多个, 这样就是一个多分类的问题。
如果还希望聊天机器人能够播报未来某一天的天气 ,那么这个机器人就还需要增加一个信的进行分类的意图, 重新进行训练。
机器学习中常见的分类方法
步骤
- 特征工程: 对文本进行处理, 转化为能够被计算的向量来表示。 我们可以考虑使用所有词语的出现次数, 也可以考虑tfidf这种方法处理
- 对模型进行训练
- 对模型进行评估
优化
使用机器学习的方法进行文本分类的时候, 为了让结果更好,我们经常从两个角度出发
- 特征工程的过程中处理地更加细致, 比如文本中类似你、我、他这种词语可以把它提出; 某些词语出现的次数太少,可能并不具有代表意义; 某些词语出现的太多, 可能导致影响的程度过大等等都是我们可以考虑的地方
- 使用不同的算法进行训练, 获取不同算法的结果, 选择最好的, 或者是使用集成学习方法
深度学习实现文本分类
- 对文本进行embedding的操作, 转化为向量
- 之后再通过多层的神经网络进行线性和非线性的变化得到结果
- 变换后的结果和目标值进行计算得到损失函数, 比如对数似然损失等
- 通过最小化损失函数, 取更新原来模型中的参数
fastText实现文本分类
fastText的介绍
文档地址: https://fasttext.cc/docs/en/support.html
fastText是一个单词表示学习和文本分类的库。
优点: 在标准的多核CPU上,能够训练10亿级别语料库的词向量在十分钟之内, 能够在1分钟之内给30多万类别的50多万句子进行分类。
fastText模型输入一个词的序列(一段文本或者一句话), 输出这个词序列属于不同类别的概率。
安装步骤
1
2
3
4
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ make
$ python setup.py install
基本使用
- 把数据准备为需要的格式
- 进行模型的训练、保存和加载、预测
1
fastText的模型框架
fastText的架构有三层: 输入层、隐藏层、输出层(Hierarchical Softmax)
输入层: 是对文档embedding之后的向量, 包含有N-gram特征
隐藏层: 是对数据的求和平均
输出层: 是文档对应标签
如下图所示:
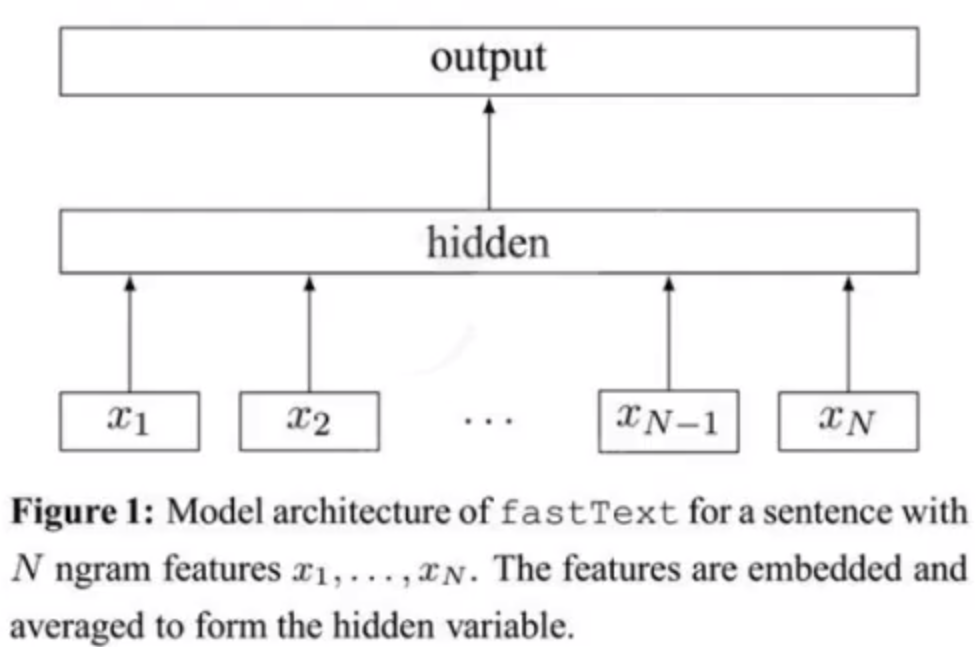
N-gram的理解
bag of word
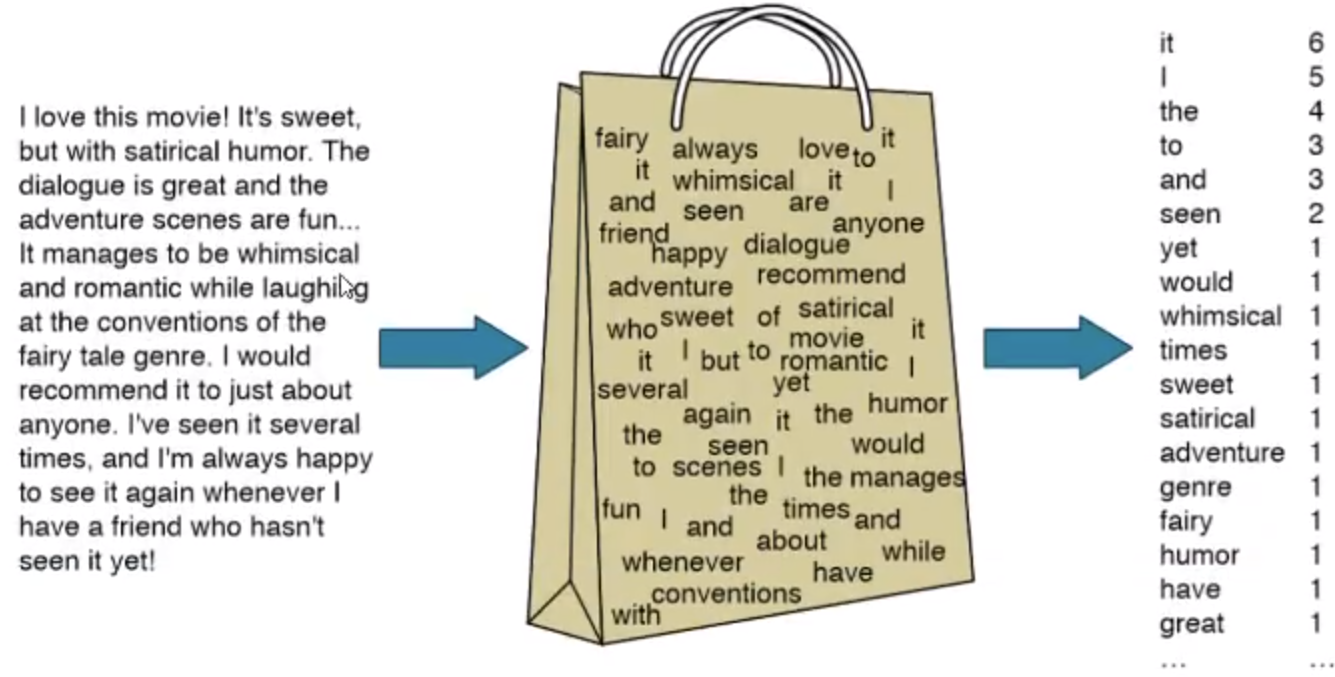
bag of word 又称为 bow, 称为词袋。 是一种只统计词频的手段。
例如: 在机器学习的课程中使用朴素贝叶斯来预测文本的类别,我们学习的countVectorizer和TfidVectorizer都可以理解为一种bow模型。
N-gram模型
很多情况下,词袋模型不满足我们的需求。
例如: 我爱她 和 她爱我 在词袋模型下面, 概率完全相同, 但是含义差别非常大。
为了解决这个问题, 就有了N-gram模型, 它不仅考虑词频, 还会考虑当前词前面的词语, 比如我爱, 她爱。
N-gram模型的描述是: 第n个词出现与前n-1个词相关, 而与其他任何次不相关。
例如: I love deep learning 这个句子, 在n=2的情况下可以表示为: {i love}, {love deep}, {deep learning}, n=3的情况下, 可以表示为{I love deep}, {love deep learning}。
在n=2的情况下, 这个模型被称为Bi-gram(二元n-gram模型)
在n=3的情况下, 这个模型被称为Tri-gram(三元n-gram模型)
所以在fasttext的输入层, 不仅有分词之后的词语, 还包含有N-gram的组合词语一起作为输入。
fastText模型中层次化的softmax
为了提高效率, 在fastText中计算分类标签的概率的时候, 不再是使用传统的softmax来进行多分类的计算, 而是使用的哈夫曼树, 使用层次化的softmax(Hierarchical softmax)来进行概率的计算。
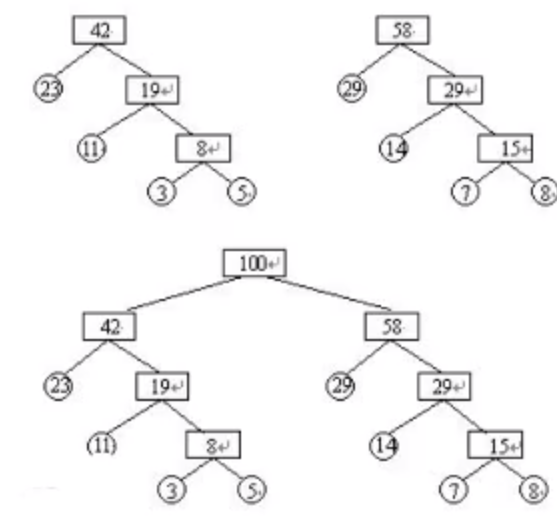
哈夫曼树: 给定n个权值作为n个叶子节点, 构造一颗二叉树, 若该树的带权路径长度达到最小, 这样的二叉树为最优二叉树, 也称为哈夫曼树。哈夫曼树是带权路径长度最短的树, 权值较大的节点离根较近。
节点的权及带权路径长度: 节点的带权路径长度为: 从根节点到该节点的路径长度与该节点的权的乘积
树的带权路径长度:树的带权路径长度规定为所有叶子节点的带权路径长度之和
树的高度: 树中节点的最大层次。包含n个节点的二叉树的高度至少为 $log_2(n+1)$
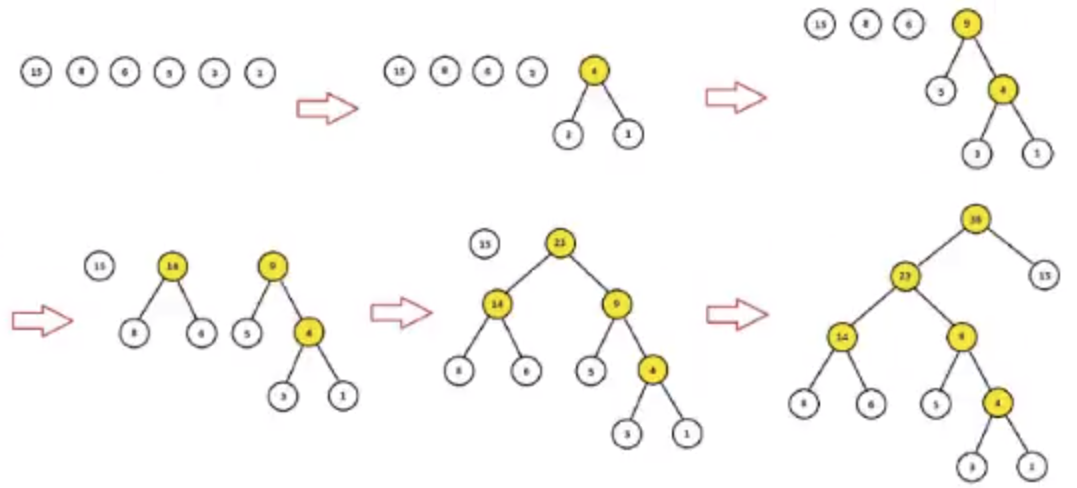
- 权重越大, 距离根节点越近
- 叶子的个数为n, 构造哈夫曼树中新增节点的个数为n-1
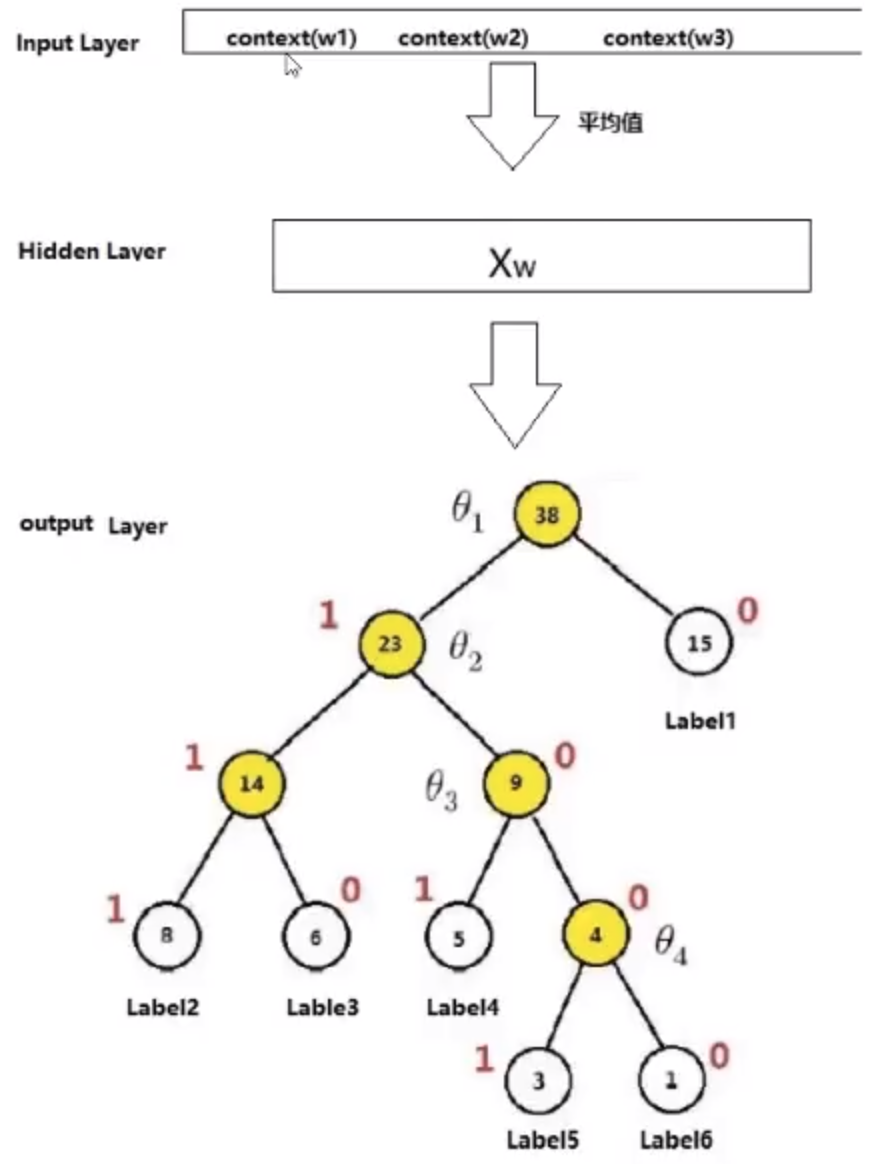
上图中, 红色为哈夫曼编码, 即label5的哈夫曼编码为1001, 那么此时如何定义条件概率$P(Label5 \mid context)$呢?
以label5为例, 从根节点到label中间经历了4次分支, 每次分支都可以认为是进行了依次2分类, 根据哈夫曼编码,可以把路径中的每个非叶子节点0认为是负类, 1认为是正类。
由sigmoid函数进行二分类的过程中, 一个节点被分为正类的概率是$\delta(X^T\theta) = \frac{1}{1+e^{-X^{T}\theta}}$, 被分为负类的概率是$1 - \delta(X^T \theta)$, 其中$\theta$就是图中非叶子节点对应的参数$\theta$。
从根节点出发, 到达label5一共经历4次二分类, 将每次分类结果的概率写出来就是:
- 第一次: $P(1 \mid X, \theta_1) = 1 - \delta(X^T\theta_1)$, 即从根节点到23节点的概率实在知道$X$和$\theta_1$的情况下取值为1的概率
- 第二次: $P(0 \mid X, \theta_2) = \delta(X^T\theta_2)$
- 第三次: $P(0 \mid X, \theta_3) = \delta(X^T\theta_3)$
- 第四次: $P(1 \mid X, \theta_4) = 1 - \delta(X^T\theta_4)$
但是我们需要求的是$P(Label \mid context)$, 它等于前4次的概率的乘积, 公式如下($d_j^w$是第$j$个节点的哈夫曼编码)
\[P(Label \mid context) = \prod_{j=2}^5 P(d_j \mid X, \theta_{j-1})\]其中:
\[P(d_j \mid X, \theta_{j-1}) = \begin{cases} \delta(X^T \theta_{j-1}), & d_j = 1 \\ 1 - \delta(X^T \theta_{j-1}) & d_j = 0 \end{cases}\]或者也可以写成一个整体:
\[P(d_j \mid X, \theta_{j-1}) = [\delta(X^T \theta_{j-1})]^d_j · [1 - \delta(X^T \theta_{j - 1}))]^{1- d_j}\]在机器学习中的逻辑回归中, 我们经常把二分类的损失函数定义为对数似然损失, 即:
\[L = -\frac{1}{M} \sum_{label \in labels} log P(label \mid context)\]式子中, 求和符号表示的是使用样本的过程中, 每一个label对应的概率取对数后的和, 之后求均值。
代入前面对$P(label \mid context)$的定义得到:
\[\begin{aligned} l &= \frac{1}{M} \sum_{label \in labels} log \prod_{j=2}\{[\delta(X^T\theta_{j-1})]^{d_j} · [1 - \delta(X^T \theta_{j-1})]^{1-d_j}\} \\ &= -\frac{1}{M} \sum_{label \in labels} \sum_{j=2} \{d_j · log[\delta(X^T \theta_{j-1})] + (1 - d_j) · log[1- \delta(X^T \theta_{j-1})]\} \end{aligned}\]层次化softmax的好处: 传统的softmax的时间复杂度为L(labels的数量), 但是使用层次化的softmax之后的时间复杂度为$log(L)$(二叉树的高度和宽度近似), 从而在多酚类的场景力高了效率。
负采样(negative sampling)
negative sampling, 每次从除当前label外的其他label中选择几个作为负样本, 作为出现负样本的概率加到损失函数中。
好处:
- 提高训练速度
- 改进效果, 增加部分负样本, 能够模拟真实场景下的噪声情况, 能够让模型的稳健性更强
例如:
假设 句子1 对应的类别有Label1, Label2, Label3, Label4, Label5 5个类别, 假设句子1属于label2, 那么我们的目标就是让$P(Label2 \mid 句子1)$这个概率最大, 但是我们得同时计算其他四类的概率, 并在利用反向传播进行优化的时候需要对所有的词向量都进行更新。 这样计算量很大。
但是我们换个方式考虑: 使用负采样的时候, 把Label2认为是正样本, 其他认为是负样本,那么只需要计算$P(D=1 \mid 句子1, Label2)$和$P(D=0 \mid 句子1, Label2)$, 那么只需要计算之前$\frac{5}{2}$倍的参数, 同时负采样每次让一个训练样本仅仅更新一小部分的权重, 这样就会降低梯度下降过程中的计算量。
意图识别准备
数据准备
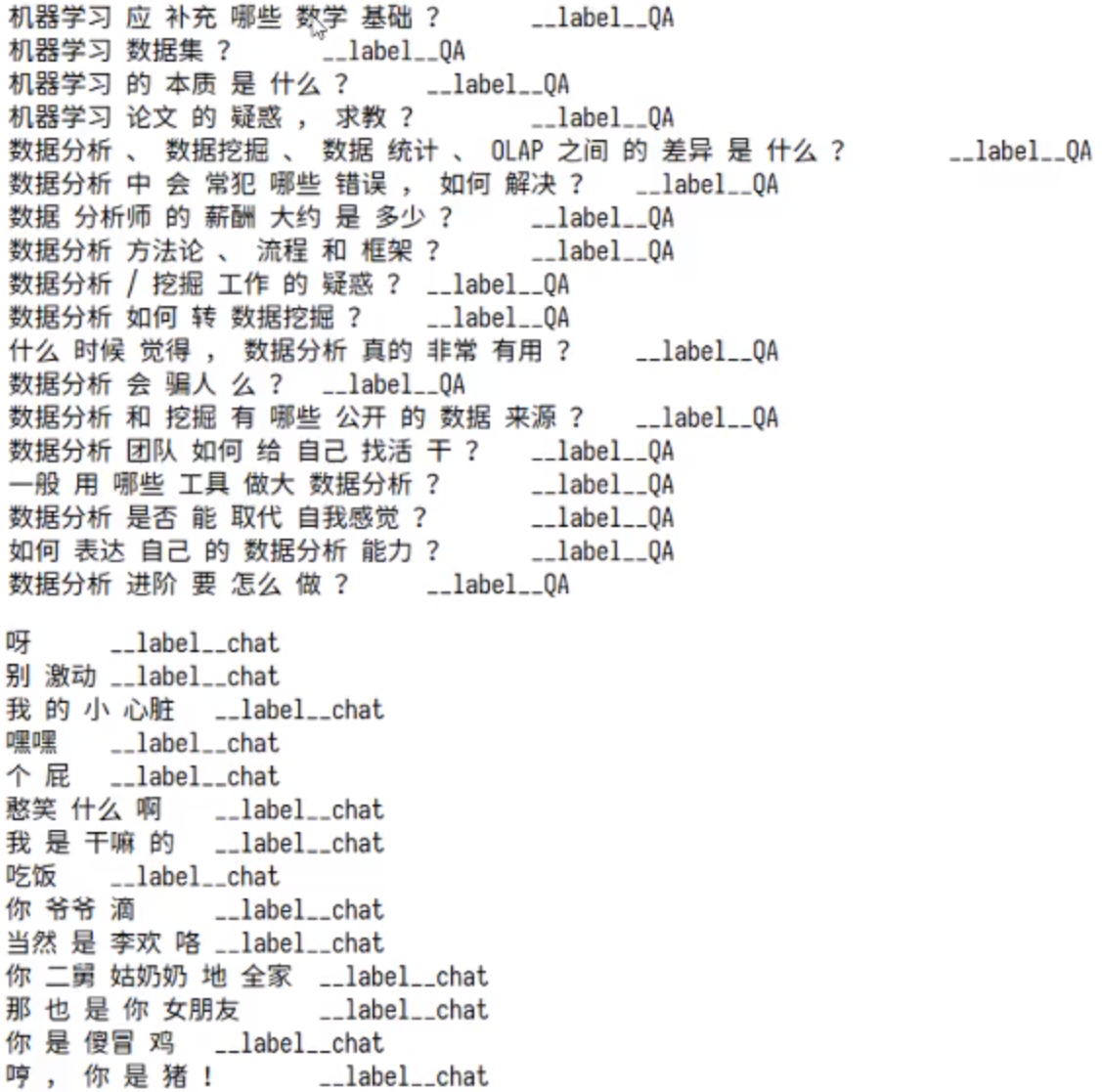
以上格式是fastText要求的格式, 其中chat、QA字段可以自定义, 就是目标值, __label__之前的为特征值, 需要使用\t进行分割, 特征值需要进行分词, __label__后面的是目标值。
准备特征文本
使用之前的模板构造的样本和通过爬虫抓取的百度上的相似问题
准备闲聊文本
使用小黄鸡的预料, 地址https://github.com/fateleak/dgk_lost_conv/tree/master/results
把文本转换为需要的格式
对两部分的文本进行分词、合并、转化为需要的格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
flags = [0, 0, 0, 0, 1] # 按4:1的比例分割为训练集和测试集
def keyword_in_line(line):
# 判断line中是否存在不符合要求的词
keywords_list = ["c++", "java", "python", "人工智能", "AI"]
for word in line:
if word in keywords_list:
return True
else:
return False
def process_xiaohuangji(f_train, f_test):
"""处理小黄鸡的语料"""
flag = 0
num_train = 0
num_test = 0
for line in tqdm(open(xiaohuangji_path).readlines(), desc="xiaohuangji"):
# TODO 句子长度为1, 考虑删除
if line.startswith("E"):
flag = 0
continue
elif line.startswith("M"):
if flag==0: # 第一个M出现
line = line[1:].strip()
flag=1
else:
continue # 不需要第二个出现M开头的句子
line_cuted = cut(line)
if not keyword_in_line(line_cuted):
line_cuted = " ".join(line_cuted) + "\t" + "__label__chat"
if random.choice(flags) == 0:
num_train += 1
f_train.write(line_cuted + "\n")
else:
num_test += 1
f_test.write(line_cuted + "\n")
return num_train, num_test
def process_byhand_data(f_train, f_test):
"""处理手动构造的数据"""
total_lines = json.loads(open(byhand_path).read())
num_train = 0
num_test = 0
# 返回dict, key:value
for key in total_lines:
# value为两层list, 第一层list
for lines in tqdm(total_lines[key], desc="byhand"):
# 第二层list
for line in lines:
line_cuted = cut(line)
line_cuted = " ".join(line_cuted) + "\t" + "__label__QA"
if random.choice(flags) == 0:
num_train += 1
f_train.write(line_cuted + "\n")
else:
num_test += 1
f_test.write(line_cuted + "\n")
return num_train, num_test
def process_crawled_data(f_train, f_test):
"""处理抓取的数据"""
num_train = 0
num_test = 0
for line in tqdm(open(crawled_path).readlines(),desc="crawled data"):
line_cuted = cut(line)
line_cuted = " ".join(line_cuted) + "\t" + "__label__QA"
if random.choice(flags) == 0:
num_train += 1
f_train.write(line_cuted + "\n")
else:
num_test += 1
f_test.write(line_cuted + "\n")
return num_train, num_test
def process():
f_train = open(config.classify_corpus_train_path, "a")
f_test = open(config.classify_corpus_test_path, "a")
# 处理小黄鸡
num_chat_train, num_chat_test = process_xiaohuangji(f_train, f_test)
# 处理手动构造的句子
num_QA_train, num_QA_test = process_byhand_data(f_train, f_test)
# 处理抓取的句子
_a, _b = process_crawled_data(f_train, f_test)
num_QA_train += _a
num_QA_test += _b
f_train.close()
f_test.close()
print("训练集和测试集: {}, {}".format(num_chat_train+num_QA_train, num_chat_test+num_QA_test))
print("QA语料和chat语料的数据量: {}. {}".format(num_chat_train+num_chat_test, num_QA_train+num_QA_test))
模型的训练
闲聊机器人的介绍
Seq2Seq的介绍
Sequence to Sequence是由encoder(编码器)和decoder(解码器)两个RNN组成。 其中encoder负责对输入句子的理解, 转化为context vector, decoder负责对理解后的句子的向量进行处理, 解码, 获得输出。
在encoder过程中得到的context vector作为decoder的输入, 怎么能够得到多个输出呢?
其实就是当前一步的输出, 作为下一单元的输入, 然后得到结果
1
2
3
4
outputs = []
while True:
output = decoder(output)
outputs.apped(output)
那么循环什么时候停止?
在训练数据集中,在输出的最后面添加一个结束符<END>, 如果遇到该结束符, 则可以终止循环
1
2
3
4
outputs = []
while output != "<END>":
output = decoder(output)
outputs.append(output)
这个结束符只是一个标记, 很多人也会使用<EOS>(End of Sequence)
总之: Seq2Seq模型中的encoder接受一个长度为M的序列, 得到1个context vector, 之后decoder把这一个context vector转化为长度为N的序列作为输出, 从而构成一个 M to N 的模型, 能够处理很多不定长输入输出的问题, 比如: “文本翻译, 问答, 文章摘要, 关键字写诗等等”。
Seq2Seq模型的实现
实现流程
- 文本转换序列(数字序列,torch.LongTensor)
- 使用序列, 准备数据集, 准备Dataloader
- 完成编码器
- 完成解码器
- 完成seq2seq模型
- 完成模型训练的逻辑, 进行训练
- 完成模型评估的逻辑, 进行模型评估
文本转化为序列
- 把字符串对应为数字
- 把数字对应为字符串
准备编码器
我们使用Embedding + GRU的结构来使用, 使用最后一个time step的输出(hidden state)作为句子的编码结果
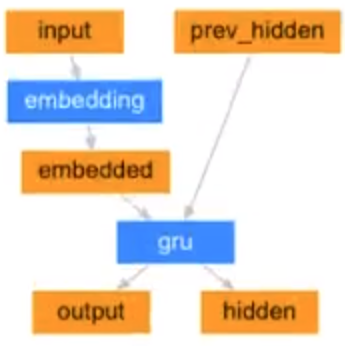
注意点:
- Embedding和GRU的参数, 我们让GRU中batch放在前面
- 输出结果的形状
- 在LSTM和GRU中, 每个time step的输入会进行计算, 得到结果, 整个过程是一个和句子长度相关的一个循环, 手动实现速度较慢
-
- pytorch中实现了nn.utils.rnn.pack_padded_sequence对padding后的句子进行打包的操作能够更快获得LSTM or GRU的结果
-
- 同时实现了的nn.utils.rnn.pad_packed_sequence对打包内容进行解包的操作
- nn.utils.rnn.pack_padded_sequence使用过程中需要对batch中的内容按照句子的长度降序排序
实现解码器
- 使用什么样的损失函数, 预测值需要是什么格式的
-
- 我们可以理解为当前的问题是一个分类的问题, 即每次的输出其实对选择一个概率最大的词
-
- 真实值的形状是[batch_size, max_len], 从而我们直到输出的结果需要是一个[batch_size, max_len, vocab_size]的形状
-
- 即预测值的最后一个维度进行计算log_softmax, 然后和真实值进行相乘, 从而得到损失
- 如何把编码结果[1, batch_size, max_len]进行操作, 得到预测值。 解码器也是一个RNN,即也可以使用LSTM or GRU的结构, 所以在解码器中:
-
- 通过循环, 每次计算的一个time step的内容
-
- 编码器的结果作为初始的隐层状态, 定义一个[batch_size, 1]的全为SOS的数据作为最开始的输入, 告诉解码器, 要开始工作了
-
- 通过解码器预测一个输出[batch_size, hidden_size], 把这个输出作为输入再使用解码器进行解码
-
- 上述是一个循环, 循环次数就是句子的最大长度,那么就可以得到max_len个输出
-
- 把所有输出的结果进行concat, 得到[batch_size, max_len, vocab_size]
- 在RNN的训练过程中, 使用前一个预测的结果作为下一个step的输入, 可能会导致一步错, 步步错的结果, 如何提高模型的收敛速度?