
Abstract
这篇文章提出一种简单的方式用于 “do as I do” 运动迁移:给定一个人舞蹈的源视频, 我们可以在目标对象执行标注动作仅几分钟后, 迁移舞蹈到一个全新的目标。我们将这视为一个使用姿势作为中间表征的 video-to-video 翻译问题。 为了迁移运动, 我们从源主体提取姿势, 然后应用学习到的 姿势到外观 映射去生成目标主体。我们预测两个连续的帧以获得时间上连贯的视频结果,并为更真实的人脸合成引入单独的流程。尽管我们的方法非常简单,但它产生令人惊讶的令人信服的结果(请参见视频)。这激励我们也提供一种用于可靠合成内容检测的取证工具,该工具能够将我们系统合成的视频与真实数据区分开。此外,我们发布了第一个同类视频开源数据集,可合法用于训练和运动传递。
Introduction
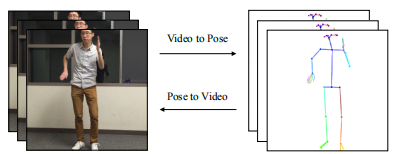
考虑图1上的两个视频序列。第一行是输入-它是执行一系列动作的芭蕾舞演员(源对象)的YouTube剪辑。最下面的一行是我们算法的输出。它对应于执行相同动作的不同人(目标对象)的帧。扭曲之处在于,目标人从未执行过与原始人相同的确切动作序列,并且实际上对芭蕾舞一无所知。取而代之的是,他在拍摄影片时执行了一系列标准动作,但没有具体提及音源的确切动作。而且,从图中可以明显看出,来源和目标是不同的性别,具有不同的身材,并穿着不同的服装。
在这项工作中,我们提出了一种简单但出乎意料的有效方法来 “Do as I Do” 视频重定向,即将运动从源自动转移到目标对象。给定两个视频(一个是我们希望合成其外观的目标人物,另一个是我们希望将其动作施加到该目标人物的源主题),我们通过学习简单的视频到视频的转换在这些主题之间传递运动。借助我们的框架,我们可以创建各种视频,使未经训练的业余人员可以像芭蕾舞演员一样旋转和旋转,表演武术踢球或像流行歌手一样充满活力地跳舞。
若要以逐帧方式在两个视频对象之间传递运动,我们必须学习两个人的图像之间的映射。因此,我们的目标是发现源和目标集之间的图像到图像的转换[16]。但是,我们没有相应的成对的两个对象的图像,它们执行相同的动作来监督学习此翻译。即使两个对象都执行相同的例程,由于每个对象唯一的身体形状和动作样式,仍然不太可能具有精确的帧到帧姿势对应。我们观察到,基于关键点的姿势会随着时间的流逝保留动作签名,同时尽可能地抽象出尽可能多的主体标识,并且可以充当任何两个主体之间的中间表示。因此,我们使用从现成的人类姿势检测器(例如OpenPose [6、34、43])获得的姿势棒图,作为帧到帧传输的中间表示,如图2所示。然后,我们学习姿势简笔画与目标人物的图像之间的图像到图像转换模型。为了将运动从源转移到目标,我们将来自源的姿势棒图形输入到训练模型中,以获取与源相同姿势的目标对象的图像。
我们的工作的核心贡献是一种令人惊讶的简单方法,可在人体运动传递中产生令人信服的结果。我们演示了从真实的野生输入视频中进行复杂的运动传递,并合成了高质量和详细的输出(示例请参见第4.3节和我们的视频)。出于高质量结果的考虑,我们引入了一种应用程序来检测视频是真实视频还是合成视频。我们坚信,对于图像合成工作而言,明确解决伪造检测问题非常重要(第5节)。此外,我们发布了一个由两部分组成的数据集:第一,我们拍摄了五段长的单舞者视频,可用于训练和评估我们的模型;第二,大量的短YouTube视频,可用于迁移和伪造检测。我们专门将单舞者数据指定为高分辨率开源数据,用于训练运动传递和视频生成方法。我们发布数据的受试者都同意允许将数据用于研究目的。有关更多详细信息,请参见我们的 项目网站https://carolineec.github.io/everybody_dance_now/。
Related Work
在过去的二十年中,致力于运动传递的工作广泛。早期的方法集中在通过操纵现有的视频素材来创建新内容[5,12,31]。例如,视频重写[5]通过查找嘴巴位置与所需语音匹配的帧来创建主题视频,这些主题说出他们最初并未说出的短语。Efros等人 [12]使用光流作为描述符来匹配执行相似动作的不同主题,从而允许“Do as I do”和“Do as I say”重新定向。经典的计算机图形运动传递方法试图以3D方式执行此操作。自从在动画角色之间提出重定位问题以来[14],解决方案就包括使用反向运动学求解器[23]以及在明显不同的3D骨骼之间进行重定位[15]。我们的方法是in-the-wild的视频对象设计的, 我们学会合成新颖的动作不是操纵现有的帧,并且我们使用2D表示。
几种方法都依赖于经过校准的多摄像机设置来“扫描”目标演员,并通过合适的目标3D模型在新视频中操纵他们的动作。为了获得3D信息,Cheung等人[9]提出了一种精心设计的多视图系统,用于校准个性化运动学模型,获得3D联合估计并渲染执行新动作的人类对象的图像。Xu等人[45]使用目标对象的简单执行的多视图捕获来创建图像数据库,并通过拟合的3D骨架和目标的相应表面网格传输运动。Casas等人的工作使用4D视频纹理[7]紧凑地存储了被扫描目标人物的分层纹理表示,并使用其时间上相干的网格和数据表示来渲染执行新颖动作的目标对象的视频。相比之下,我们的方法探索2D视频对象之间的运动传递,并避免数据校准和提升到3D空间。
与我们的方法类似,最近的工作将深度学习应用于不同应用程序中的复活,并且依赖于更详细的输入表示。给定人造人的轮廓,内部人脸模型和凝视图作为输入,Kim等人[19]在人类受试者之间转移头部位置和面部表情,并将其结果呈现在详细的肖像视频中。我们的问题类似于这项工作,不同之处在于我们重新定位了全身运动,并且将模型输入为2D姿势简笔画,而不是更详细的3D表示。同样,Martin-Brualla等人[29]应用神经重渲染来增强用于VR / AR目的的人类运动捕获的渲染。这项工作的主要重点是实时渲染逼真的人类,并且类似地使用深层网络来合成他们的最终结果,但是与我们的工作不同的是,它不解决对象之间的运动传递。Villegas等人[37]专注于重新绑定骨骼之间的运动,并在没有监督数据的情况下以3D角色演示了复活。类似地,我们学习使用骨架状的中间表示来重新定位运动,但是我们在不像动画角色那样被绑定到骨骼的人类对象之间传递全身运动。
最近的方法集中于从外观上解开运动,并用新颖的运动合成视频[36,2]。MoCoGAN [36]采用无人监督的对抗训练来学习这种分离,并生成执行新颖动作或面部表情的对象的视频。这个主题在Dynamics Transfer GAN [2]中得到了延续,GAN [2]将面部表情从视频中的源主题转移到静态图像中给出的目标人物上。同样,我们将运动的表示应用于不同的目标对象以生成新的运动。但是,与这些方法相比,我们专注于合成详细的舞蹈视频。
现代方法已显示出成功地以新姿势生成人类对象的详细单幅图像的情况[3,10,11,18,22,27,28,33,38,13,46]。Ma等[27,28]和Siarohin等[33]的著作为此引入了新颖的架构和损失。此外,[39,38]已经表明,姿势是未来预测和视频生成的有效监督信号。但是,这些作品并非专门为运动传递而设计。我们对从大量的个性化视频数据中学习单个已知人物的风格并将其在详细的高分辨率视频中进行合成,而不是从单个输入图像中生成以前看不见的人物的可能视图。
与我们的工作同时,[1、4、24、40]学习视频之间的映射,并演示人脸之间以及从姿势到身体的运动传递。Wang等人[40]通过更复杂的方法和显着更多的计算资源获得了与我们相似的结果。
最近在两个不同方向上的快速发展使我们的工作成为可能:稳健的姿态估计和逼真的图像到图像转换。包括OpenPose [6,34,43]和DensePose [32]在内的现代姿势检测系统可在各种情况下提供令人惊讶的可靠且快速的姿势提取。同时,最近出现了图像到图像转换模型pix2pix [16],Co-GAN [26],UNIT [25],CycleGAN [48],DiscoGAN [20],Cascaded Refinement Networks [8], 和pix2pixHD [41]使得能够生成高质量的单图像。我们通过使用姿势检测作为中间表示并在单图像生成上扩展以合成时间相干来构建这两个构建块,生成令人惊讶的逼真的视频。
Method
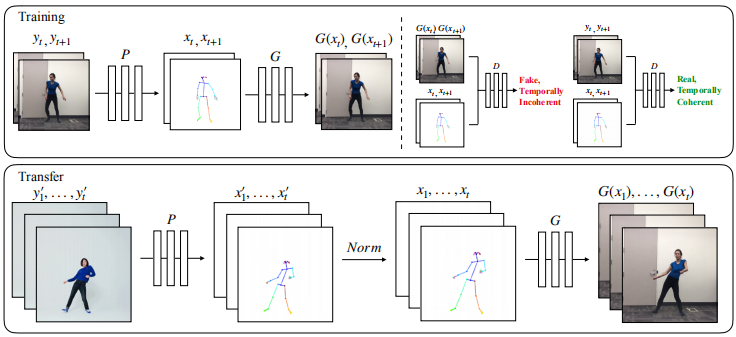
给定源人物和目标人物的视频,我们的目标是生成与源人物动作相同的目标的新视频。为了完成此任务,我们将流程分为三个阶段–姿势检测,全局姿势归一化以及从归一化的姿势简笔画到目标对象的映射。有关我们的流程的概述,请参见图3。在姿势检测阶段,我们使用预训练的最新姿势检测器在源视频给定帧的情况下创建姿势简笔画。全局姿势归一化阶段考虑了源和目标身体形状以及帧内位置之间的差异。最后,我们设计了一个系统来使用对抗训练来学习从姿势简笔画到目标人物图像的映射。接下来,我们描述系统的每个阶段。
Pose Encoding and Normalization
Encoding body poses 为了对对象图像的身体姿势进行编码,我们使用了经过预先训练的姿势检测器P(OpenPose [6,34,43]),它可以准确地估算2D x,y关节坐标。然后,我们通过以下方式创建彩色姿势简笔画在连接的关节之间绘制关键点和绘制线,如图2所示。
Global pose normalization 在不同的视频中,拍摄对象的肢体比例可能不同,或者彼此之间比相机更近或更远。因此,当将两个对象之间的运动重新定位时,可能有必要变换来源人员的姿势关键点,以使其根据目标人员的身体形状和位置而出现,如图3的 “Transfer” 部分中所示。我们通过分析每个对象的姿势的高度和脚踝位置并在两个视频中最靠近和最远的脚踝位置之间使用线性映射,来找到这种变换。收集这些位置后,我们根据其相应的姿势检测为每个帧计算比例和平移。有关此过程的详细信息,请参见第8.5节。
Pose to Video Translation
我们的视频合成方法基于Wang等[41]提出的对抗性单帧生成过程。在原始的条件GAN设置中,生成器网络G参与了针对多尺度鉴别器 $D =(D1,D2,D3)$ 的minimax游戏。生成器必须合成图像,以欺骗鉴别器,该鉴别器必须在生成器生成的“真实”图像和“伪”图像之间进行区分。这两个网络被同时训练并互相推动以改善-G学习合成更详细的图像以欺骗D,D进而学习生成的输出和真实数据之间的差异。出于我们的目的,G会合成给定姿势的人的图像。这种单帧图像到图像的转换方法不适合视频合成,因为它们会产生时间伪像,并且无法生成对感知人类运动非常重要的精细细节。因此,我们添加了一个学习的时间相干模型以及一个用于高分辨率人脸生成的模块。
Temporal smoothing 为了创建视频序列,我们修改了单个图像生成设置,以增强相邻帧之间的时间连贯性,如图3(右上图)所示。代替生成单独的帧,我们预测两个连续的帧,其中第一个输出 $G(x_{t-1})$取决于其相应的姿态棒图$x_{t- 1}$和零图像 $z$(占位符,因为在时间$t - 2$之前没有预先生成的帧)。第二输出 $G(x_t)$取决于其相应的姿态棒图 $x_t$ 和第一输出 $G(x_{t-1})$ 。因此, 现在判决其的任务是判断假序列$(x_{t-1}, x_t, G(x_{t-1}), G(x_t))$ 和 真是序列 $(x_{t-1}, x_t, y_{t-1}, y_t)$ 的时间相干差异。时间平滑变化现在反映在更新的GAN目标中:
\[L_{smooth}(G, D) = E_{(x, y)}[log D(x_t, x_{t+1}, y_t, y_{t+1})] + E_x[log (1 - D(x_t, x_{t+1}, G(x_t), G(x_{t+1})))] \tag{1}\]Face GAN 我们添加了专门的GAN设置,以向面部区域添加更多细节和真实感,如图4所示。在使用主生成器G生成完整的场景图像后, 我们输入图像一个小的面部区域(比如128 x 128在鼻子关键点的周围小块),并且输入姿势棒图同样的方式的区域, x_F, 到另一个生成器$G_f$, 它产生一个残差 $r = G_f(x_F, G(x)_F)$。最终的合成面部区域是主生成器$r + G(x)_F$的面部区域与残差的加法。一个判决器$D_f$判别假脸对 $(x_F, r + G(x)_F)$ 和真脸对 $(x_F, y_F)$, 和原始pix2pix的目标函数类似:
\[L_{face}(G_f, D_f) = E_{(x_F, y_F)}[log D_f(x_F, y_F)] + E_{x_F}[log (1 - D_f(x_F, G(x)_F + r))] \tag{2}\]这里$x_F$是原始姿势棒图 $x$ 的面部区域 以及 $y_F$ 是真实目标图像 $y$ 的面部区域。 与整幅图像相似, 我们增加了一个感知重构损失在比较最终的人脸 $r + G(x)_F$ 和 真实目标人脸 $y_F$。
Full Objective
我们分阶段进行训练,在此阶段中,与专业面部GAN分开优化了整个图像GAN。首先,我们训练主要的生成器和判别器$(G,D)$,在此期间,整个目标是:
\[\min_G((\max_{D_i} \sum_{k_i} L_{smooth}(G, D_k)) + \lambda_{FM} \sum_{k_i} L_{FM}(G, D_k) \\ + \lambda_P (L_P(G(x_{t - 1}), y_{t - 1}) + L_P (G(x_t), y_t))) \tag{3}\]其中 $i = 1, 2, 3$, 这里, $L_{GAN}(G, D)$ 是原始pix2pix论文中单张图像的对抗损失:
\[L_{GAN} = E_{(x, y)}[log D(x, y)] + E_x[log (1 - D(x, G(x)))] \tag{4}\]$L_{FM}(G, D)$是pix2pixHD中的判决器特征匹配损失, $L_P(G(x), y)$是感知重构损失。
在这个阶段之后, 固定整幅图像的GAN权重, 我们用以下目标优化面部GAN:
\[\min_{G_f}((\max_{D_f} L_{face}(G_f, D_f)) + \lambda_P L_P (r + G(x)_F, y_F)) \tag{5}\]Appendix
Implementation Details
我们的生成器和判别器体系结构已从pix2pixHD [41]修改为时间相干。我们遵循来自pix2pixHD的渐进式学习计划,并在第一(全局)阶段学习以512×256进行合成,然后在第二(局部)阶段将其上采样 1024×512。为了预测人脸残差,我们使用pix2pixHD的全局生成器和单个70×70 Patch GAN鉴别器[16]。 我们设置超参数 $\lambda_P = 5$ 以及 $\lambda_{VGG} = 10$ 在训练全局和局部阶段。对于在第4.1节中收集的数据集,我们训练了5个epoch的全局阶段,30个epoch的局部阶段和5个epoch的面部GAN。
对于感知损失$L_p$, 我们比较了 $conv1_1, conv2_1, conv3_1, conv4_1$ 以及 $conv5_1$ VGG-19 的输出。
我们的生成器和判别器架构遵循Wang等[41]提出的架构。伪检测器架构则为将判决器的架构加上最终的全连接层。
Global Pose Normalization Details
在本节中,我们描述归一化方法以匹配源和目标之间的姿势。考虑一种情况,即源被摄对象的镜框高度明显高于目标,或略微高于目标被摄对象的框位置。如果我们直接将未修改的姿势输入到我们的系统中,则可能会生成与场景不一致的目标人的图像。在此示例中,目标人物可能相对于背景或周围物体显得较大,并且由于输入的姿势将脚放在地板上方,因此看起来好像在悬浮。另外,当从与比例成比例非常不同的姿势生成图像并在训练中合理放置姿势时,预计合成的整体质量会下降。因此,我们设计了一种方法,可以通过在源姿势和目标姿势之间找到合适的变换来合理地匹配姿势。我们根据应用于给定帧的所有姿势关键点的比例和平移因子来参数化此变换。
为了找到合适的迁移因子,我们需要确定两个主题在其各自框架内的位置。我们首先在视频中找到源主体远离摄像机的最接近位置 $s_{close}$ 和最远的位置 $s_{far}$。同样,我们分别通过确定 $t_{close}$和 $t_{far}$ 对目标执行相同的操作。然后,目标是将源的近距离和远距离映射到目标对象的近距离和远距离,以匹配两个对象的位置,即 $s_{far}→t_{far}$ 和 $s_{close}→t_{close}$。给定一个源在位置y处的帧,然后我们通过以下方式垂直转换源的姿势:
\[translation = t_{far} + \frac{y - s_{far}}{s_{close} - s_{far}}(t_{close} - t_{far})\]实际上,我们使用受试者脚踝的y坐标的平均值来确定给定帧内的位置。
为了合理地缩放源姿势,我们确定每个对象在其视频中最接近和最远位置的高度-将这些量分别表示为 $h_{s_{close}},h_{s_{far}}$(针对源)和 $h_{t_{close}},h_{t_{far}}$(针对目标对象)。然后,我们确定由 $c_{close} = \frac{h_{t_{close}}}{h_{s_{close}}}$ 给出的接近位置的单独比例, 相似的由 $c_{far} = \frac{h_{t_{far}}}{h_{s_{far}}}$确定远端的位置。 给定源在y位置的帧时,我们通过以下方式缩放源的姿态(在x,y方向上):
\[scale = c_{far} + \frac{y - s_{far}}{s_{close} - s_{far}}(c_{close} - c_{far}) \tag{8}\]我们将平均脚踝位置与给定姿势的鼻子关键点之间的欧式距离作为给定帧中对象的身高。在确定了给定源姿势的平移和比例因子之后,我们将平移添加到所有关键点,然后应用比例因子,以使脚踝y位置保持不变(即地面是x轴)。
-
Previous
【深度学习】SSD: Single Shot MultiBox Detector -
Next
【深度学习】Pix2Pix:Image-to-Image Translation with Conditional Adversarial Networks