![Figure 1: 我们提出了一种生成对抗网络,用于从语义标签映射((a)的左下角)合成2048×1024图像。与以前的工作[5]相比,我们的结果表达了更多自然的纹理和细节。(b)我们可以更改原始标签图中的标签以创建新的场景,例如用建筑物替换树木。(c)我们的框架还允许用户编辑场景中单个对象的外观,例如 改变汽车的颜色或道路的质地。请访问我们的网站以获取更多比较以及交互式编辑演示。](https://raw.githubusercontent.com/ShawnDong98/gitimage/main/小书匠/1612446428004.png)
Abstract
我们提出了一种使用条件生成对抗网络(条件GAN)从语义标签图上合成高分辨率照片级逼真的图像的新方法。条件GAN已经有了多种应用,但结果通常仅限于低分辨率,距离实际还很远。 在这项工作中,我们以新的对抗损失以及新的多尺度生成器和判别器架构生成了2048×1024的具有吸引力的结果。此外,我们将框架扩展到具有两个附加功能的交互式视觉操作。首先,我们合并了对象实例分割信息,该信息使对象能够进行操作,例如删除/添加对象和更改对象类别。其次,我们提出一种在给定相同输入的情况下生成各种结果的方法,允许用户以交互方式编辑对象外观。人类舆论研究表明,我们的方法明显优于现有方法,从而提高了深度图像合成和编辑的质量和分辨率。
Introduction
逼真的图像渲染使用标准图形技术, 因为必须明确模拟几何形状,材料和光传输。尽管现有的图形算法可以胜任该任务,但是构建和编辑虚拟环境既昂贵又耗时。那是因为我们必须明确地建模世界的每个方面。如果我们能够使用从数据中学到的模型来渲染逼真的图像,则可以将图形渲染过程转变为模型学习和推理问题。然后,我们可以通过在新数据集上训练模型来简化创建新虚拟世界的过程。通过允许用户仅指定整体语义结构,而不是对几何图形,材质或光照进行建模,我们甚至可以使自定义环境更加容易。
在本文中,我们讨论了一种从语义标签图生成高分辨率图像的新方法。该方法具有广泛的应用范围。例如,我们可以使用它来创建用于训练视觉识别算法的综合训练数据,因为为所需场景创建语义标签比生成训练图像要容易得多。使用语义分割方法,我们可以将图像转换为语义标签域,在标签域中编辑对象,然后将其转换回图像域。此方法还为我们提供了用于更高级别图像编辑的新工具,例如,将对象添加到图像或更改现有对象的外观。
为了从语义标签合成图像,可以使用pix2pix方法,这是一种图像到图像转换框架[21],它利用条件生成对抗网络(cGANs)[16]。最近,Chen和Koltun [5]提出对抗训练可能不稳定,并且在高分辨率图像生成任务中容易失败。进而,他们采用修改后的感知损失[11、13、22]来合成图像,这些图像是高分辨率的,但通常缺少精细的细节和逼真的纹理。
在这里,我们解决上述最新方法的两个主要问题:(1)使用GAN [21]生成高分辨率图像的困难,以及(2)在以前的高分辨率下缺少细节和逼真的纹理结果[5]。我们表明,通过一个新的,强大的对抗学习目标,以及新的多尺度生成器和判别器体系结构,我们可以以2048×1024分辨率合成照片级逼真的图像,比以前的方法计算出的图像更具视觉吸引力[5,21]。我们首先仅通过对抗训练获得我们的结果,而不依靠人工的损失[44]或预训练的网络(例如VGGNet [48])来感知损失[11、22](图9c,10b)。然后,我们表明,如果存在预训练网络,则在某些情况下(图9d,10c),增加来自预训练网络的感知损失[48]可以稍微改善结果。在图像质量方面,这两个结果都大大优于以前的工作。
此外,为了支持交互式语义操纵,我们在两个方向上扩展了我们的方法。首先,我们使用实例级对象分割信息,该信息可以将同一类别内的不同对象实例分开。这样可以进行灵活的对象操作,例如添加/删除对象和更改对象类型。其次,我们提出了一种在给定相同输入标签图的情况下生成各种结果的方法,允许用户以交互方式编辑同一对象的外观。
我们将其与最先进的视觉合成系统进行比较[5,21],并表明我们的方法在定量评估和人类感知研究方面均优于这些方法。我们还针对训练目标和实例级分割信息的重要性进行了消融研究。除了语义操纵之外,我们还在edge2photo应用上测试了我们的方法(图2,13),这表明了我们方法的可推广性。
![Figure 2: 使用CelebA-HQ [26]和互联网猫图像,使用我们的框架将边缘转换为高分辨率自然照片的示例结果。](https://raw.githubusercontent.com/ShawnDong98/gitimage/main/小书匠/1612448129337.png)
Related Work
Generative adversarial networks 生成对抗网络(GAN)[16]旨在通过强制生成的样本与自然图像无法区分来模拟自然图像分布。 GAN赋能了各种应用,例如图像生成[1、42、62],表示学习[45],图像处理[64],目标检测[33]和视频应用[38、51、54]。已经提出了各种从粗到细的方案[4] [9,19,26,57],以在无条件的情况下合成较大的图像(例如256×256)。受到其成功的启发,我们提出了一种适用于以更高的分辨率生成条件图像的新型从粗到细生成器和多尺度判别器架构。
Image-to-image translation 许多研究人员利用对抗学习进行图像到图像的翻译[21],其目标是在输入-输出图像对作为训练数据的情况下,将输入图像从一个域转换到另一个域。与通常导致图像模糊的L1损失相比[21,22],对抗损失[16]已成为许多图像间任务的流行选择[10,24,25,32,41,46,55,60,66]。原因是判别器可以学习可训练的损失函数,并自动适应目标域中生成图像和真实图像之间的差异。例如,最近的pix2pix框架[21]将图像条件GAN [39]用于不同的应用,例如将Google地图转换为卫星视图, 并根据用户草图生成猫。还提出了各种方法来在没有训练对的情况下学习图像到图像的翻译[2,34,35,47,50,52,56,65]。
最近,Chen和Koltun [5]提出,由于训练的不稳定性和优化问题,条件GAN可能难以生成高分辨率图像。为了避免这种困难,他们使用基于感知损失的直接回归目标[11,13,22]并产生了可以合成2048×1024图像的第一个模型。 生成的结果是高分辨率的,但通常缺少精细的细节和逼真的纹理。受其成功的启发,我们表明,使用新的目标函数以及新颖的多尺度生成器和判别器,我们不仅在很大程度上稳定了高分辨率图像上条件GAN的训练,而且与Chen和Koltun相比,取得了明显更好的结果[ 5]。并排比较清楚地表明了我们的优势(图1、9、8、10)。
Deep visual manipulation 最近,深度神经网络在各种图像处理任务中获得了可喜的成果,例如风格迁移[13],修复[41],着色[58]和还原[14]。但是,这些作品大多数都缺少用户调整当前结果或探索输出空间的界面。为了解决这个问题,Zhu等人[64]根据GANs的先验开发了一种用于编辑对象外观的优化方法。最近的作品[21,46,59]还提供了用于从低级提示(例如颜色和草图)创建新颖图像的用户界面。所有先前的工作都报告低分辨率图像的结果。我们的系统与过去的工作具有相同的精神,但我们专注于对象级语义编辑,使用户可以与整个场景进行交互并操纵图像中的单个对象。结果,用户可以以最小的努力快速创建新场景。我们的界面受到以前数据驱动的图形系统的启发[6,23,29]。但是我们的系统允许更灵活的操作并实时产生高分辨率结果。
Instance-Level Image Synthesis
我们提出了一个条件对抗框架,用于从语义标签图生成高分辨率的逼真图像。我们首先回顾一下基线模型pix2pix(第3.1节)。 然后,我们描述了如何通过改进的目标函数和网络设计来提高照片的逼真度和结果的分辨率(第3.2节)。接下来,我们使用附加的实例级对象语义信息来进一步提高图像质量(第3.3节)。最后,我们引入了一个实例级特征嵌入方案,以更好地处理图像合成的多模态性质,从而实现交互式对象编辑(第3.4节)。
The pix2pix Baseline
pix2pix方法[21]是用于图像到图像翻译的条件GAN框架。它由生成器G和判别器D组成。对于我们的任务,生成器G的目的是将语义标签映射转换为逼真的图像,而判别器D的目的是将真实图像与翻译后的图像区分开。该框架在受监督的环境中运行。换句话说,训练数据集作为一组对应的图像{($s_i,x_i$)}给出,其中 $s_i$ 是语义标签图,而 $x_i$ 是对应的自然照片。条件GAN旨在通过以下minimax游戏在给定输入语义标签映射的情况下对真实图像的条件分布进行建模:
\[\min_G \max_D L_{GAN}(G, D) \tag{1}\]其中目标函数$L_{GAN}(G, D)$:
\[E_{(s, x)}[log D(s, x)] + E_s [log (1 - D(s, G(s)))] \tag{2}\]pix2pix方法采用U-Net [43]作为生成器,并采用基于小块的全卷积网络[36]作为判别器。判别器的输入是语义标签图和相应图像的通道拼接。但是,在Cityscapes [7]上生成的图像的分辨率最高为256×256。我们直接将pix2pix框架应用于生成高分辨率图像进行了测试,但发现训练不稳定并且生成的图像质量不令人满意。因此,在下一部分中,我们将描述如何改进pix2pix框架。
Improving Photorealism and Resolution
我们通过使用从粗到细的生成器,多尺度判别器体系结构和强大的对抗学习目标函数来改进pix2pix框架。
Coarse-to-fine generator 我们将生成器分解为两个子网络:$G_1$和$G_2$。我们将$G_1$称为全局生成器网络,将$G_2$称为局部增强器网络。然后,生成器由元组$G = {G_1,G_2}$给出,如图3所示。全局生成器网络以1024×512的分辨率运行,局部增强器网络输出的图像分辨率为前一个图像输出大小的4倍(每个图像维度为2倍)。为了以更高的分辨率合成图像,可以使用其他局部增强器网络。例如,生成器 $G = {G_1,G_2}$的输出图像分辨率为 2048×1024,而 $G = {G_1,G_2,G_3}$的输出图像分辨率为 4096×2048。
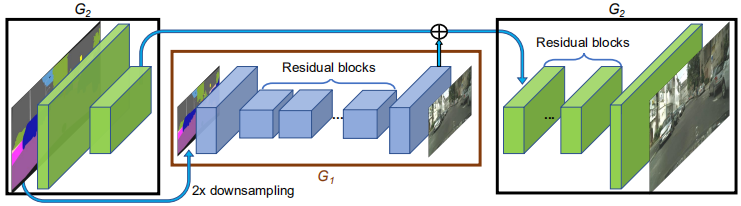
我们的全局生成器基于Johnson等人提出的架构[22],这已被证明可以成功地在高达 512×512 的图像上进行神经风格迁移。它由3个组件组成:卷积前端 $G^{(F)}_1$,一组残差块 $G^{(R)}_1$ [18]和转置卷积后端 $G^{(B)}_1$。依次将分辨率为1024×512的语义标签图通过这三个组件,以输出分辨率为1024×512的图像。
本地增强器网络还包括3个组件:卷积前端 $G^{(F)}_2$,一组残差块 $G^{(R)}_2$ 和转置的卷积后端 $G^{(B)}_2$。输入标签映射到 $G_2$ 的分辨率为 2048×1024。与全局生成器网络不同,残差块 $G^{(R)}_2$ 的输入是两个特征图的按元素求和:$G^{(F)}_2$ 的输出特征图和全局生成器网络后端的最后一个特征图 $G^{(B)}_1$ 的总和。这有助于整合从$G_1$ 到 $G_2$ 的全局信息。
在训练过程中,我们首先训练全局生成器,然后按照其分辨率顺序训练局部增强器。然后,我们共同微调所有网络。我们使用此生成器设计为图像合成任务有效地聚合全局和局部信息。我们注意到,这种多分辨率流程是计算机视觉中公认的实践[4],而两尺度通常就足够了[3]。在最近的无条件GAN [9,19]和有条件的图像生成[5,57]中可以找到相似的想法,但结构不同。
Multi-scale discriminators 高分辨率图像合成对GAN判别器设计提出了重大挑战。为了区分高分辨率的真实图像和合成图像,判别器需要具有较大的感受野。这将需要更深的网络或更大的卷积内核,这两者都将增加网络容量并可能导致过拟合。同样,这两种选择都需要较大的内存占用空间进行训练,而对于高分辨率图像生成而言,这已经是一种稀缺资源。
为了解决这个问题,我们提出使用多尺度判别器。我们使用3个判别器,它们具有相同的网络结构,但以不同的图像尺度运行。我们将判别器称为 $D_1$ ,$D_2$ 和 $D_3$。具体来说,我们以 系数2和4 对真实和合成的高分辨率图像进行下采样,以创建3个尺度的图像金字塔。然后训练判别器 $D1$,$D2$ 和 $D3$ 分别区分3个不同比例的真实和合成图像。尽管判别器具有相同的架构,但以最粗糙的尺度的判别器具有最大的感受野。它具有更全局的图像视图,并且可以引导生成器生成全局一致的图像。另一方面,最精细的判别器器会鼓励生成器生成更精细的细节。这也使训练从粗到细的生成器变得更加容易,因为将低分辨率模型扩展到更高的分辨率仅需要在最精细的级别上添加一个判别器,而不是从头开始进行重新训练。没有多尺度判别器,我们观察到许多重复的模式经常出现在生成的图像中。
有了判别器,等式(1)中的学习问题就变成了一个多任务学习问题。
\[\min_G \max_{D_1, D_2, D_3} \sum_{k = 1, 2, 3} L_{GAN}(G, D_k) \tag{3}\]在相同图像尺度上使用多个GAN判别器已经在无条件GANs上提出。Iizuka等[20]在条件GAN上添加了全局图像分类器,以合成用于修补的全局一致内容。在这里,我们将设计扩展到不同图像比例的多个判别器,以对高分辨率图像进行建模。
Improved adversarial loss 我们通过结合基于判别器的特征匹配损失来改善等式(2)中的GAN损失。这种损失使训练稳定了,因为生成器必须生成多个尺度的自然统计数据。具体来说,我们从判别器的多层提取特征,并从实际图像和合成图像中学习匹配这些中间表示。为了便于表示,我们将判别器 $D_k$ 的第 $i$ 层特征提取器表示为 $D^{(i)}k$(从输入到 $D_k$ 的第 $i$ 层)。然后特征匹配损失 $L{FM}(G,D_k)$计算为:
\[L_{FM}(G, D_k) = E_{(s, x)} \sum_{i=1}^T \frac{1}{N_i}[\|D_{k}^{(i)}(s, x) - D_k^{(i)}(s, G(s))\|_1] \tag{4}\]其中 $T$ 是层的总数,$N_i$ 表示每层中的元素数。我们的GAN判别器特征匹配损失与感知损失[11,13,22]相关,已证明对图像超分辨率[32]和风格迁移[22]有用。在我们的实验中,我们讨论了如何将判别器特征匹配损失和感知损失一起用于进一步改善性能。我们注意到,在VAE-GAN中使用了类似的损失[30]。我们的完整目标结合了GAN损失和特征匹配损失,如下所示:
\[\min_G ((\max_{D_1, D_2, D_3} \sum_{k=1, 2, 3} L_{GAN}(G, D_k)) + \lambda \sum_{k=1, 2, 3}L_{FM}(G, D_k) \tag{5}\]其中 $\lambda$ 控制这两项的重要性。请注意,对于特征匹配损失$L_{FM}$,$D_k$仅用作特征提取器,不会使损失 $L_{FM}$ 最大化。
Using Instance Maps
现有的图像合成方法仅利用语义标签图[5,21,25],该图像中的每个像素值代表像素的对象类别。该映射不会区分相同类别的对象。另一方面,实例级语义标签图包含每个单独对象的唯一对象ID。为了合并实例映射,可以将其直接传递到网络中,或将其编码为一个独热向量。但是,由于不同的图像可能包含相同种类的不同数量的对象,因此在实践中很难实现这两种方法。或者,可以为每个类别预先分配固定数量的通道(例如10个),但是当数量设置得太小时,此方法会失败,而如果数量太大,则会浪费内存。
进而,我们认为实例图提供的最关键的信息(在语义标签图中不可用)是对象边界。例如,当同一类的对象彼此相邻时,仅查看语义标签图就无法区分它们。如图4a所示,因为许多停放的汽车或步行的行人经常彼此相邻,所以对于街道场景尤其如此。但是,使用实例图,分离这些对象变得更加容易。
因此,要提取此信息,我们首先计算实例边界图(图4b)。在我们的实现中,如果实例边界图中的像素与其4个邻居中的任何一个都不相同,则实例边界图中的像素为1,否则为0。然后将实例边界图与语义标签图的独热向量表示拼接起来,并喂入生成器网络。类似地,向判别器的输入是实例边界图,语义标签图和真实/合成图像的通道级拼接图像。图5b显示了一个示例,该示例演示了通过使用对象边界进行的改进。我们在第四部分的研究还显示了使用实例边界图训练的模型,渲染了更多逼真的对象边界。

Learning an Instance-level Feature Embedding
语义标签图的图像合成是一对多的映射问题。理想的图像合成算法应该能够使用相同的语义标签图生成各种逼真的图像。最近,一些作品学习在给定相同输入的情况下产生固定数量的离散输出[5,15]或合成由对整个图像进行编码的隐编码控制的各种模式[66]。尽管这些方法解决了多模态图像合成问题,但它们不适合我们的图像处理任务,主要有两个原因。首先,用户无法直观地控制模型将生成哪种类型的图像[5,15]。其次,这些方法着眼于全局颜色和纹理更改,并且不允许对生成的内容进行对象级控制。
为了生成各种图像并允许实例级别的控制,我们建议添加其他低维特征通道作为生成器网络的输入。我们证明,通过操纵这些功能,我们可以灵活地控制图像合成过程。此外,请注意,由于特征通道是连续量,因此我们的模型原则上可以生成无限多的图像。
为了生成低维特征,我们训练一个编码器网络 $E$ 来找到一个低维特征向量,该向量对应于图像中每个实例的真实目标。我们的特征编码器架构是标准的编码器-解码器网络。为了确保每个实例中的特征一致,我们在编码器的输出中添加了一个实例平均池化层,以计算对象实例的平均特征。然后将平均特征广播到实例的所有像素位置。图6可视化了编码特征的示例。
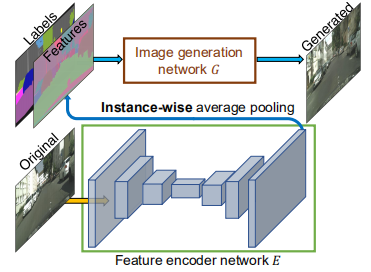
我们用等式(5)中的 $G(s,E(x)$ 替换 $G(s)$,并与生成器和判别器一起训练编码器。编码器训练后,我们在训练图像中的所有实例上训练它,并记录获得的特征。然后,我们针对每个语义类别对这些特征执行K-均值聚类。因此,每个群集对特定风格的特征进行编码,例如,道路的沥青或鹅卵石纹理。在推论时,我们随机选择一个聚类中心,并将其用作编码特征。这些特征与标签映射拼接在一起,并用作生成器的输入。我们试图在特征空间上强制使用Kullback-Leibler损失[28],以进行更好的测试时间采样,如最近的工作[66]所示,但发现用户直接调整每个对象的隐向量非常麻烦。进而,对于每个对象实例,我们提供K种模式供用户选择。
Results
我们首先提供与4.1部分中领先方法的定量比较。然后,我们在4.2节中报告了一项主观的人类感知研究。 最后,我们在Sec4.3中显示了一些交互式对象编辑结果的示例。
Implementation details 我们使用LSGAN [37]进行稳定训练。在所有实验中,我们设置权重 $λ= 10$(等式(5)),而 $K = 10$ 表示K均值。我们使用3维向量为每个对象实例编码特征。我们尝试增加感知损失 $\lambda \sum_{i = 1}^N \frac{1}{M_i}[|F^{(i)}(x) -F^{(i)}(G(s)) |_1]$ 到我们的目标 (等式5), 其中 $\lambda = 10$ 以及 $F^{(i)}$ 表示 VGG 网络的有 $M_i$个元素 的 第 $i$ 层。我们观察到这种损失会稍微改善结果。请在附录中找到更多训练和体系结构详细信息。
Datasets 我们对Cityscapes数据集[7]和NYU Indoor RGBD数据集[40]进行了广泛的比较和消融研究。我们在ADE20K数据集[63]和Helen Face数据集[31,49]上报告了其他定性结果。
Baselines 我们将我们的方法与两种最新算法进行比较:pix2pix [21]和CRN [5]。我们使用默认设置在高分辨率图像上训练pix2pix模型。我们通过作者的公开模型制作高分辨率CRN图像。
Quantitative Comparisons
我们从以前的图像到图像的翻译工作中采用了相同的评估协议[21,65]。为了量化结果的质量,我们对合成图像执行语义分割,然后比较预测的分割与输入的匹配程度。直觉是,如果我们可以生成与输入标签图相对应的逼真的图像,那么现成的语义分割模型(例如,我们使用的PSPNet [61])应该能够预测真实标签。表1报告了计算出的分割准确率。可以看出,对于像素级交并比(IoU),我们的方法在很大程度上优于其他方法。此外,我们的结果非常接近原始图像的结果,即可以实现的现实主义的理论“上限”。这证明了我们算法的优越性。
![Table 1: 通过Cityscapes数据集上的不同方法对结果进行语义分割评分[7]。我们的结果大大优于其他方法,并且非常接近原始图像的准确性。](https://raw.githubusercontent.com/ShawnDong98/gitimage/main/小书匠/1612515583645.png)
Human Perceptual Study
我们通过人类主观研究进一步评估了我们的算法。我们执行在Cityscapes数据集上的Amazon Mechanical Turk(MTurk)平台上部署的成对A / B测试[7]。我们遵循与Chen和Koltun [5]中所述相同的实验程序。更具体地说,进行两种不同类型的实验:无限时间和有限时间,如下所述。
Unlimited time 为此,workers要同时获得两张图像,对于同一张标签图,每张图像都是通过不同的方法合成的。我们给他们无限的时间来选择看起来更自然的图像。左右顺序和图像顺序是随机的,以确保公平的比较。将所有500张Cityscapes测试图像进行10次比较,每种方法得出5000人的判断。在本实验中,我们仅使用在标签上训练的模型(没有实例图)来确保公平的比较。表2表明,我们方法的两个变体均明显优于其他方法。
。每个单元格都列出了我们的结果优于其他方法的百分比。 机会是50%。](https://raw.githubusercontent.com/ShawnDong98/gitimage/main/小书匠/1612517253840.png)
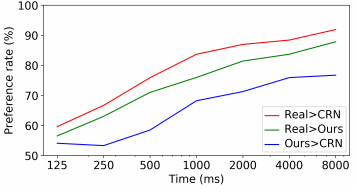
Limited time 接下来,对于有限时间的实验,我们将我们的结果与CRN和原始图像(真实情况)进行比较。在每个比较中,我们显示了两种方法在短时间内的结果。我们根据先前的工作[5]随机选择1/8秒和8秒之间的持续时间。这样可以评估图像之间差异的感知速度。图7示出了在不同时间间隔的比较结果。随着给定时间变得越来越长,这三种类型的图像之间的差异变得更加明显,更易于观察。图9和10显示了一些示例结果。
Analysis of the loss function 我们还使用无限时间实验研究了每项在目标函数中的重要性。具体而言,我们的最终损失包含三个成分:GAN损失,基于判别器的特征匹配损失和VGG感知损失。我们使用(1)仅GAN损失和(2)GAN +特征匹配损失(即无VGG损失)将最终实现与结果进行比较。获得的偏好率分别为68.55%和58.90%。可以看出,增加特征匹配损失会大大改善性能,而增加感知损失会进一步提高结果。但是,请注意,使用感知损失并不重要,即使没有感知损失,我们仍然能够产生视觉上吸引人的结果(例如,图9c,10b)。
Using instance maps 我们将使用实例映射的结果与不使用实例映射的结果进行比较。我们在图像中突出显示汽车区域,并要求参与者选择哪个区域看起来更逼真。我们获得了64.34%的偏好率,这表明使用实例图可以提高结果的真实感,尤其是在对象边界附近。
Analysis of the generator 将所有其他固定组件, 我们将不同生成器的结果进行比较。特别是,我们将生成器与两种最新的生成器架构进行了比较:U-Net [21,43]和CRN [5]。我们评估有关语义分割分数和人类感知研究结果的性能。表3和表4表明,我们的粗到细生成器在很大程度上优于其他网络。
![Table 3: 使用Cityscapes数据集上的不同生成器对结果进行语义分割评分[7]。 我们的生成器获得最高分。](https://raw.githubusercontent.com/ShawnDong98/gitimage/main/小书匠/1612518380568.png)
![Table 4: Cityscapes数据集上的成对比较结果[7]。每个单元格都列出了我们的结果优于其他方法的百分比。 机会是50%。](https://raw.githubusercontent.com/ShawnDong98/gitimage/main/小书匠/1612518849455.png)
Analysis of the discriminator 接下来,我们还将使用多尺度判别器与仅使用一个判别器的结果进行比较,同时保持生成器和损失函数固定不变。Cityscapes上的细分得分[7](表5)表明,使用多尺度判别器有助于产生更高质量的结果并稳定对抗训练。我们还在Amazon Mechanical Turk平台上执行成对A / B测试。69.2%的参与者更喜欢我们使用多尺度判别器的结果,而不是使用单尺度判别器训练的结果(机会为50%)。
![Table 5: 使用Cityscapes数据集上的单个鉴别符(单D)或多尺度鉴别符(多尺度Ds)对结果进行语义分割评分[7]。使用多尺度判别器有助于提高分割分数。](https://raw.githubusercontent.com/ShawnDong98/gitimage/main/小书匠/1612519107230.png)
Additional datasets 为了进一步评估我们的方法,我们对NYU数据集进行了无限制的时间比较。针对pix2pix和CRN,我们分别获得了86.7%和63.7%。图8显示了一些示例图像。 最后,我们在ADE20K [63]数据集上显示结果(图11)。
![Figure 8: 在NTU数据集上的比较[40]。 与其他方法相比,我们的方法可生成更加逼真的彩色图像。](https://raw.githubusercontent.com/ShawnDong98/gitimage/main/小书匠/1612519458923.png)
Interactive Object Editing
我们的特征编码器使我们可以对结果图像执行交互式实例编辑。例如,我们可以更改图像中的对象标签以快速创建新颖的场景,例如用建筑物替换树木(图1b)。我们还可以更改单个汽车的颜色或道路的纹理(图1c)。
此外,我们在Helen Face数据集上实现了交互式对象编辑功能,其中提供了不同面部部位的标签[49](图12)。这样可以轻松编辑人像,例如更改脸部颜色以模仿不同的化妆效果或在脸上添加胡须。
Discussion and Conclusion
本文的结果表明,条件GAN可以合成高分辨率的真实感图像,而无需任何人工的损失或预先训练的网络。我们已经观察到,加入感知损失[22]可以稍微改善结果。我们的方法允许许多应用,并且对于需要高分辨率结果但不提供预训练网络的领域可能很有用(例如,医学成像[17]和生物学[8])。
本文还显示了图像到图像合成流程可以扩展以产生各种输出,并在给定适当的训练输入-输出对(例如本例中的实例图)的情况下启用交互式图像处理。在没有被告知什么是“纹理”的情况下,我们的模型学会了对不同对象进行样式化,这些对象也可能会推广到其他数据集(即,使用一个数据集中的纹理来合成另一个数据集中的图像)。我们相信这些扩展可以潜在地应用于其他图像合成问题。
Appendix
A. Training Details
使用Adam解算器[27]从零开始对所有网络进行了训练,学习率为0.0002。我们在前100个时期保持相同的学习率,并在接下来的100个时期将学习率线性衰减为零。权重由均值0和标准差0.02的高斯分布初始化。我们将在配备24GB GPU内存的NVIDIA Quadro M6000 GPU上训练所有模型。
在具有11GB GPU内存的NVIDIA 1080Ti GPU上,推理时间为每2048×1024输入图像20到30毫秒之间。这种实时性能使我们能够开发交互式图像编辑应用程序。
下面我们讨论使用的数据集的细节。
- Cityscapes dataset [7]: 来自Cityscapes训练集中的2975个训练图像,图像尺寸为2048×1024。我们使用Cityscapes验证集进行测试,该验证集包含500张图像。
- NYU Indoor RGBD dataset [40]: 1200张训练图像和249张测试图像,所有图像的分辨率均为561×427。
- ADE20K dataset [63]: 20210个训练图像和2000个测试图像(具有不同的图像大小)。在训练和推理之前,我们将所有图像的宽度缩放到512。
- Helen Face dataset [31, 49]: 2000张训练图像和330张具有不同图像尺寸的测试图像。在训练之前和参考时,我们将所有图像的大小调整为1024×1024。
Generator Architectures
我们的生成器由全局生成器网络和局部增强器网络组成。我们遵循Johnson等[22]和CycleGAN [65]中使用的命名约定。令$c7s1-k$ 表示 7×7 Convolution-InstanceNorm [53] -ReLU层,具有 $k$ 个滤波器且步幅为1。$dk$ 表示 3×3 Convolution-InstanceNorm-ReLU层,具有 $k$ 个滤波器,步幅为2。我们使用反射填充来减少边界伪像。$Rk$表示一个残差块,其中包含两个3×3卷积层,两层卷积数相同。$uk$ 表示3×3的 fractional-strided Convolution-InstanceNorm-ReLU层,具有k个滤波器,步幅为$\frac{1}{2}$。
我们有两个生成器:全局生成器和局部增强器。
Our global network:
$c7s1-64,d128,d256,d512,d1024,R1024,R1024,
R1024,R1024,R1024,R1024,R1024,R1024,R1024,
u512,u256,u128,u64,c7s1-3$
Our local enhancer:
$c7s1-32,d642,R64,R64,R64,u32,c7s1-3$
Discriminator Architectures
对于判别器网络,我们使用70×70 Patch-GAN [21]。令 $C_k$ 表示 4×4 Convolution-InstanceNorm-LeakyReLU层,具有 $k$ 个滤波器且步幅为2。在最后一层之后,我们应用卷积来产生一维输出。我们不在第一个 $C64$ 层使用InstanceNorm。我们使用斜率为0.2的LeakyReLU。 我们所有的三个鉴别器具有相同的架构,如下所示:
$C64-C128-C256-C512$
-
Previous
【深度学习】Pix2Pix:Image-to-Image Translation with Conditional Adversarial Networks -
Next
【深度学习】Skeleton-Aware Networks for Deep Motion Retargeting