ABSTRACT
生成对抗网络(GAN)在各种应用领域(例如计算机视觉,医学和自然语言处理)都非常成功。此外,将物体或人转变为所需形状成为GAN中的一项经过充分研究的研究。GAN是用于学习复杂分布以合成语义上有意义的样本的强大模型。但是, 该领域缺乏全面的审阅, 尤其缺少GAN的损失变体, 评估指标, 保证生成图像多样性和稳定训练。我们总结了合成图像生成方法,并讨论了包括图像到图像翻译,融合图像生成,标签到图像映射以及文本到图像翻译。我们基于它们的基本模型、和结构相关的发展想法、约束、损失函数、评价指标、和训练数据集组织文献。我们介绍了对抗性模型的里程碑,回顾了各种类别的大量先前作品,并提出了从基于模型的方法到数据驱动方法的发展路线的见解。此外,我们重点介绍了一系列潜在的未来研究方向。这篇审阅的独特特征之一是,这些GAN方法和数据集的所有软件实现都已收集并在以下位置:https://github.com/pshams55/GAN-Case-Study.
Introduction
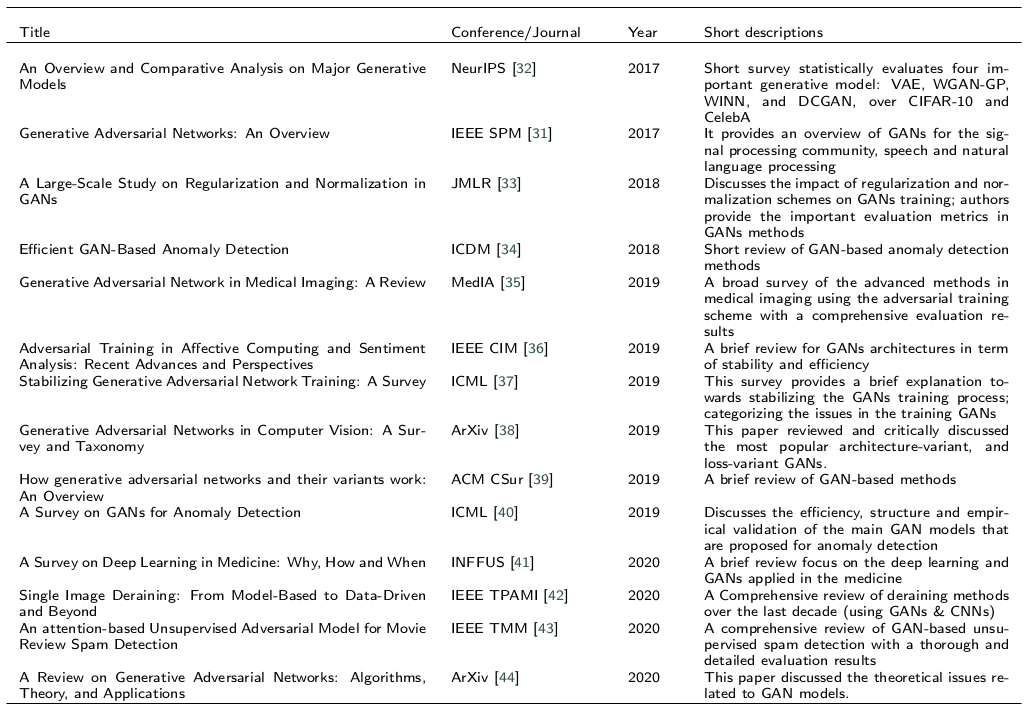
大数据使深度学习算法得以快速发展。特别是,最先进的生成对抗网络(GAN)[1]能够生成各种类别的高保真自然图像。事实证明,经过适当的训练,GAN能够从标准数据分布中合成语义上有意义的数据。GAN由Goodfellow等人[2]于2014年提出,在生成合成图像方面表现优于其他生成模型,后来成为计算机视觉领域的活跃研究领域。图1显示了近年来该主题的重要性。标准GAN包含两个神经网络,一个生成器和一个鉴别器,其中生成器尝试创建欺骗鉴别器的逼真的样本,力图将真实样本与假样本区分开。训练过程将继续进行,直到生成器赢得对抗游戏为止。然后,判别器决定一个随机样本是假的还是真实的。GAN中有两个主要的研究方向。第一个重点是试图提高GAN稳定性并解决GAN的训练问题[3、4、5、6、7]或从信息论[8、9、10]和效率[11,12,13]等不同观点重新定义GAN 。第二部分着重于计算机视觉中GAN的体系结构和应用[3,14,15]。除了图像合成,还有许多成功使用GAN的应用程序,例如图像超分辨率[16],图像标题[17],图像修补[18],文本到图像翻译[19],语义分割 [20],物体检测[21],对抗式攻击[22],神经机器翻译[23],图像融合[24、25、26、27]和图像去噪[28]。Huang等[29]和Goodfellow [30]提供了对GAN的介绍,他们讨论了GAN模型的重要性,并比较了GAN及其变体以生成合成样本。最近,Creswell等[31]提出了对GAN的调研,以评估模型和训练方法。这些通用图像合成调研 在一般情况下讨论了GAN,而没有考虑每个模型的形成细节,优点和缺点。这些研究的局限性在于它们仅涵盖GAN结构和算法方法,包括特征选择和加权方法。表1总结了到目前为止已发布的GAN调查。但是,缺少一份可以通过理论分析来讨论所提出模型的优缺点的调研论文。
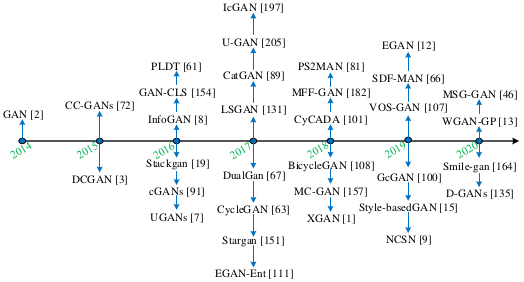
基于这些观察,本文针对以下未解决的问题。当前用于图像合成的最新GAN是什么?当前是否有有效的GAN模型可以达到合成图像生成的最新性能?哪种类型的GAN架构最适合图像到图像的翻译?哪些损失函数最有效?最后:我们总结了广泛用于验证基于GAN的不同方法的数据集。图2列出了用于生成合成图像的GAN的里程碑。
在本文中,我们提供了用于合成图像生成的GAN模型的经验比较研究。我们展示了如何有效地训练GAN来学习隐藏的判别特征。为了公平地比较测试方法,我们使用Python和Tensorflow中的通用框架来训练带有4个NVIDIA GTX Geforce 1080 Ti GPU的模型。我们的概述包括问题的定义,主要GAN方法的总结以及特定解决方案的详细介绍。我们为与GAN相关的所有合成图像生成基准保留了一个部分详细来讲。此外,本调研还通过数学基础和理论分析来讨论当前GAN模型的优缺点。最后, 根据我们的分类, 我们构建了一个网页作为GAN图像合成问题的动态库。该网页将不断更新以提供新的研究和方法 https://github.com/pshams55/GAN-Case-Study。 本文的主要贡献可归纳如下:
- 在各个领域中用于合成图像生成的GAN的最新应用分类, 可分为以下两个类别:单阶段和多阶段模型。
- 审阅GAN的最新模型的体系结构。
- 我们提供了性能指标的详细信息,这些指标通常用于评估GAN模型和数据集。
- 我们为社区提供了一个实时资源库,其中包含本次调查中讨论的源代码,数据集和论文。 它还将每月更新一次。
本文的其余部分安排如下。下一部分将回顾GAN的核心概念。第3节讨论了GAN中使用的不同损失函数。第4节讨论了用于评估GAN模型的最常用数据集。第5节介绍了图像合成中使用的方法。第6节评估了用于图像到图像合成的方法以及可能的未来研究领域。在第7节中,我们将进行总结性讨论,并讨论基于GAN的方法的局限性。
Related Work
在本节中,我们首先列出一些受益于GAN的著名作品,然后我们重点研究各种应用,包括医学成像和图像到图像的翻译。文献综述显示,关于GAN架构和性能的调研论文很少[31,45]。这些工作主要集中在针对不同类型的GAN架构的性能验证上。其他工作是有限的,因为基准数据集不能以适当的方式反映多样性。因此,结果主要集中在图像质量评估上,这可能会降低GAN在生成各种图像中的有效性[46]。在本文中,我们收集了各种各样的GAN模型并进行了详细讨论。为了避免解释流程的中断,我们首先介绍原始的GAN定义,然后在接下来的小节中说明它的变体。一个由 $\theta$ 参数化的生成器 $G$ 接受一个随机噪声 $z$ 作为它的输入, 输出为样本 $G(z, \theta)$。 因此, 输出可以是从分布 $G(z_\theta), p_g$ 生成的一个样本。此外, 有大量的训练数据 $x$ 采样自 $p_{data}$, $G$的目标是使用$p_g$估计$p_{data}$。GAN的基本架构如图3(a)所示。GAN [2]包含两个不同的神经网络:随机噪声向量 $z$ 作为输入生成器 $G$ ,并生成合成数据 $G(z)$,判别器 $D$ 既获取真实数据 $x$ 又获取生成的数据 $G(z)$ 为 输入, 将真实样本和加样本区分开, 如图3(a)所示。通常,$G$ 和 $D$ 都是神经网络架构。GAN [2]的第一个体系结构使用全连接的层FC作为基础网络。 后来,Radford等[3]在GAN中引入了深层全卷积神经网络,从而改善了结果,这是在许多GAN模型中大量使用卷积层的开始。关于卷积算法的其他细节可以在[14]中找到。训练GAN的主要思想是组织一个两人的最小-最大游戏,其中 $G$ 试图产生准确的数据, 而 $D$ 试图识别假数据和真实数据。损失函数如$Eq.(1)$ 所示, 其中 $P_{data}(x)$ 表示真实数据分布 并且 $P_z(z)$ 表示噪声分布。
\[\min_G \max_D V(G, D) = E_{x \thicksim P_{data}(x)}[log D(x)] + E_{z \thicksim P_z(z)}[ log (1 - D(G(z))) ] \tag{1}\]![Fig3:GAN体系结构及其变体。(a) 展示了GAN的基本体系结构[2]; (b) 显示[47]中引入的执行类条件图像合成的条件GAN; (c) 显示了InfoGAN [8]和ACGAN [48]的体系结构; (d) 显示了BAGAN架构[49]。](https://raw.githubusercontent.com/ShawnDong98/gitimage/main/小书匠/1615036234137.png)
$G, D$ 是生成器和判别器, $G$ 将 $z$ 映射为 元素 $X$, $D$ 同时 $x$ 和 $G(z)$ 区分它们是真实的样本还是假的样本。 如果一个样本采样自真实输入 $x$, $D$ 将会最大化它的输出, 而如果一个样本采样自 $G$, $D$会最小化它的输出, 因此, $Eq.(1) log(1 - D(G(z)))$的第二项将会出现。 这种调整导致两个方面
- 由 $D$ 产生的决策边界 给创建的样本 惩罚巨大的误差, 这些样本远离决策边界, 因此帮助 “不好的” 产生样本移向决策边界。 这种方法有助于生成高质量的图像。
- 产生的离决策边界不近的样本更新 $G$ 的时候传递更多的梯度, 这解决了 GAN 训练的梯度消失问题。
图4展示了标准GAN在MNIST数据及上训练的步数。值得注意的是, GANs有三个关键的挑战:
- 模式崩溃: GANs最常见的故障之一是模式崩溃,当G将不同的输入映射到相同的输出时会发生这种情况。
- 梯度消失: 对于GAN的最优训练,G和D都需要产生有价值的反馈。一个训练好的D将损失函数压缩为0,因此,梯度近似为零,这将向G传递少量反馈,从而导致速度减慢或完全停止学习。同样的,不准确的D产生错误的反馈,误导G。
- 收敛: 虽然全局纳什均衡的存在已被证明,达到这个均衡不是很简单。GANs经常发生振荡或循环行为,容易收敛到局部纳什均衡,而局部纳什均衡在主观上可能远离全局均衡。
以下各节概述了用于解决上述问题的GAN体系结构。在本文中,我们调研了合成图像的产生并确定了不同的网络,其中最早的论文是在2014年提出的[2]。这些技术基于五个主要标准进行分组:网络设计; 学习策略; 有监督的方法; 无监督的方法; 域适应和其他方法(请参见表2)。如图1所示,合成图像的生成是近年来研究的活跃领域之一。在这篇综述中,我们仅关注于最先进的图像合成技术,其中包括200多个研究成果。此外,我们使用Github上作者发布的代码重现了本文显示的一些结果。我们通过确定未来工作的方向来完成本调查。为了设计GAN的第一个体系结构,全连接(FC)神经网络用于 $G$ 和 $D$ [2],以基于Toronto Face Dataset 1,MNIST [50]和CIFAR-10 [51]生成伪造图像。Chen和Jiang [52]提出了一种基于FC层的GAN框架,该模型仅在少数数据分布集上表现出较高的性能。后来,提出了其他类型的GAN,我们将在以下各节中进行讨论。
Convolution GANs
从 FC 到卷积神经网络 (CNN) 的迁移适用于图像数据。先前的实验表明,使用CNN训练G和D非常困难,主要是由于以下五个原因:不收敛,梯度减小,生成器和鉴别器之间的不平衡,模型崩溃,超参数选择。一种解决方案是使用对抗网络的拉普拉斯金字塔[53]。在此模型中,将真实图像转换为多尺度金字塔图像,并对卷积GAN进行训练以生成多尺度和多层次特征图,通过组合所有特征图可以得出最终特征图。拉普拉斯金字塔是包含带通图像和低频残差的线性可逆图像演示。
\[h_k = l_k(I) = G_k(I) - u(G_{k+1}(I)) = I_k - u(I_{k+1}) \tag{2}\]其中 $k$ 是金字塔的层数, $I$ 表示图像, $u(.)$ 表示光滑的升采样操作并且将 $I$ 提升到两倍的尺寸。 因此 $u(I)$ 是 一个新的图像尺寸。 拉普拉斯金字塔 $l_k(I)$ 不同的 $k$ 层 的 系数 $h_k$ 通过 两个邻近的高斯金字塔层的方差计算得到, $h_k = I_k$。 从拉普拉斯金字塔系数 $[h_1, h_2, …, h_K]$ 来重构一张图像, 这些系数从 $I_k = h_k$ 开始回归递归, 如下:
\[I_k = u(I_{k + 1}) + h_k \tag{3}\]经过训练后,该模型具有一组生成凸模型 ${G_0, G_1, …, G_k}$, 它们中的每个都捕获对图像在网络的不同尺度系数$h_k$的分布。
\[\bar I_k = u(\bar I_{k + 1}) + \bar h_k = u(\bar I_{k+1}) + G_k(z_k, u(I_{k + 1}))\]blablabla…. 这块我看不懂
与其他GAN结构相比, 条件GAN与[63、108、11]相比, 在多模态数据上具有更好的性能。另一方面,InfoGAN [8]是另一个发展方向,它使用一小部分隐变量之间的互信息来获取语义信息。该架构如图3(c)所示。这样的模型可以以无监督的方式应用于确定不同的对象,并且InfoGAN产生的所有样本在语义上都有意义。
Zhou等人[109]介绍了一种使用条件GAN的归一化技术,该技术限制了低维流形中权重的搜索空间。在[110,111]中,作者提出了一个用于能源管理系统的条件对抗网络。 事实证明,他们的方法收敛速度更快,但作者并未强调模型的复杂性。Odena等人[48]提出了一种新颖的GAN分类器(ACGAN),其架构类似于InfoGAN。在此模型中,条件变量将不会添加到判别器,并且将使用外部分类器来预测类别标签上的概率。损失函数被优化以改善类别预测。在[49]中,作者提出了一种使用平衡GAN(BAGAN)结构的数据增强方法,如图3(d)所示。将类条件应用于隐空间, 使生成程序产生目标类别。BAGAN的结构类似于InfoGAN 和 ACGAN。 然而, BA只产生一个输出, 而InfoGAN和ACGAN有两个输出。
在[112]中,作者提出了一个深层的条件GAN模型,该模型从作为条件变量的语义布局和场景属性中汲取了力量。这种方法能够在不同情况下生成清晰的物体边缘的逼真的图像。图5比较了由InfoGAN和ACGAN在CIFAR-10上生成的图像。
