Abstract
我们介绍了第一种从场景级手绘草图中自动生成图像的方法。我们的模型允许通过写意草图指定合成目标来生成可控的图像。关键贡献是在EdgeGAN上桥接了一个属性向量, 该网络支持高视觉质量的对象级图像内容生成,而无需使用草图作为训练数据。我们构建了一个名为SketchyCOCO的大规模复合数据集来支持和评估解决方案。在SketchyCOCO上,我们对目标级和场景级的图像生成任务进行了验证。通过定量,定性的结果,人类评估和消融研究,我们证明了该方法具有从各种徒手素描中生成逼真的复杂场景级图像的能力。
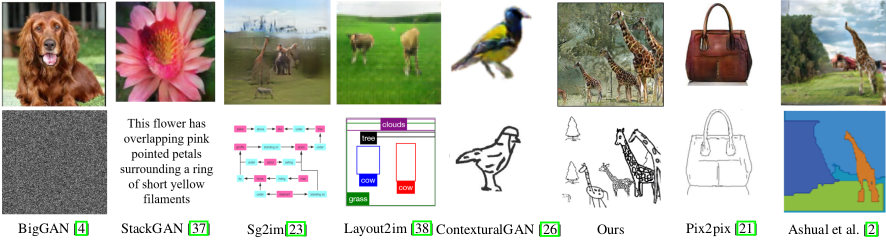
Figure 1: 所提出的方法允许用户可控地从徒手中生成具有许多物体的真实场景级图像,这与无条件GAN和有条件GAN形成鲜明对比的是,我们使用场景草图作为上下文(弱约束),而不是从噪声中生成[4]或更强的约束,例如语义图[2,28]或边缘图[21]。输入的约束从左到右变得更强。
Experiments
Object-level Image Generation
Scene-level Image Generation
Baselines. 没有现有的方法专门用于从场景级手绘草图生成图像。SketchyGAN最初是用于从手绘草图生成对象级图像的。从理论上讲,它也可以用于场景级的手绘草图。pix2pix [21]是一种流行的通用图像到图像模型,应该在所有图像翻译任务中应用。 因此,我们使用SketchyGAN [9]和pix2pix [21]作为基线方法。
由于我们有14081对{场景草图,场景图像}样本,因此直接训练pix2pix和SketchyGAN模型以了解从草图到图像的映射是很直观的。因此,我们对分辨率较低的实体(例如128×128)进行了实验。
我们发现对pix2pix或SketchyGAN的训练都容易出现模式崩溃,通常是在60个epochs(对于SketchyGAN为80个epochs)之后,即便使用了Sketchy-COCO数据集中的所有14081对{场景素描,场景图像}样本。原因可能是数据种类太大而无法建模。即便14K对的大小仍然不足以完成成功的训练。但是,即使有80%的14081对{前景图像和背景草图,场景图像}样本,我们仍然可以使用相同的pix2pix模型进行背景生成,而不会发生任何模式崩溃。这可能是因为在这种情况下,pix2pix模型避免了前景草图和相应前景图像内容之间具有挑战性的映射。更重要的是,由于前景图像为背景生成提供了充分的先验信息和约束条件,训练能够快速收敛。
Comparison with other systems. 我们还将我们的方法与高级方法进行比较,后者使用其他模态的约束来生成图像。
- GauGAN [28]: 原始的GauGAN模型将语义图作为输入。我们发现,GauGAN模型还可以用作从语义草图生成图像的方法,其中草图的边缘具有类别标签,如图7的第7列所示。在我们的实验中,我们测试了在数据集COCO Stuff上预训练的公共模型。另外,我们通过将收集的SketchyCOCO数据集上的语义草图作为输入来训练模型。结果显示在图7的第6列和第8列中。
- Ashual et al. [2]: Ashual等人提出的方法可以使用布局或场景图作为输入。因此,我们将这两种模式与它们的预训练模型进行了比较。为了确保公平,我们仅测试SketchyCOCO数据集中包含的类别,并将最小对象数的参数设置为1。结果显示在图7的第2列和第4列中。

Figure 7: 场景级生成的比较。 细节参见文章5.2节。
-
Previous
【深度学习】Semantically Multi-modal Image Synthesis -
Next
【深度学习】Specifying Object Attributes and Relations in Interactive Scene Generation