Abstract
我们介绍了一种从输入场景图生成图像的方法。 该方法将布局嵌入和外观嵌入分开。双重嵌入使得生成的图像与场景图更好地匹配,具有更高的视觉质量并支持更复杂的场景图。此外,该嵌入方案支持每个场景图有多个不同的输出图像,用户可以进一步控制这些图像。我们演示了每个对象控制的两种模式:(i)从其他图像导入元素,以及(ii)通过选择外观原型在对象空间中导航。
code: https://www.github.com/ashual/scene_generation.
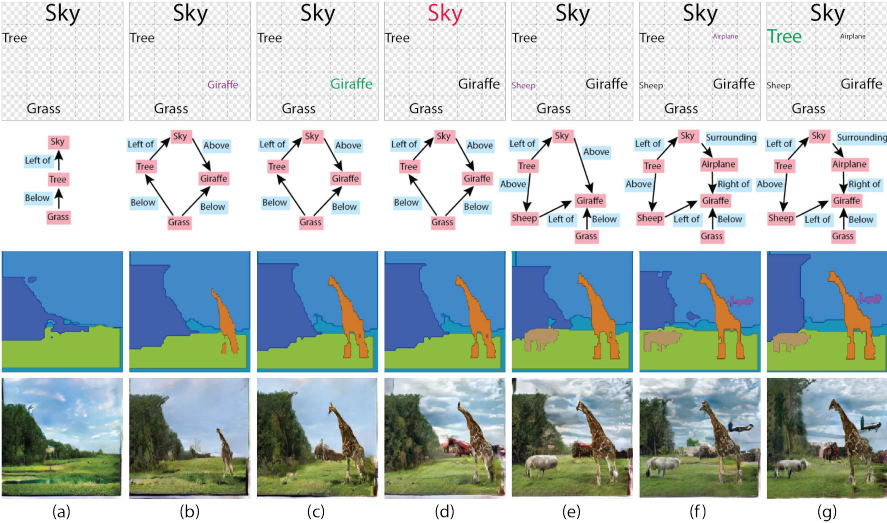
Figure 1. 图像创建过程的示例。(上排)用户界面的示意图面板,用户在其中布置所需的对象。(第二行)基于此布局自动推断的场景图。(第三行)从场景图创建的布局。(下排)生成的图像。图形用户界面颜色的图例在第一行:紫色-添加对象,绿色-调整其大小,红色-替换其外观。(a)具有天空对象,树木和草对象的简单布局。所有对象外观都初始化为随机原型外观。(b)添加了长颈鹿。(c) 长颈鹿被放大。(d)天空的外观更改为其他原型。(e) 加了一只小绵羊。 (f) 增加了飞机。 (g) 树被放大了。

Figure 3. 基于给定场景图的图像生成。 每行是一个不同的示例。(a) 场景图,(b) 提取布局的真实图像, (c)类似于[27]使用图像的真实布局时的结果, (d)我们方法的结果,其中外观属性呈现随机原型,而位置属性粗略地描述了真实边界框,(e) 当我们使用真实图像生成外观属性并将位置属性归零时的结果 $l_i = 0$, (f)我们的结果 $l_i = 0$,并且外观属性是从原型中采样的;以及(g) [9]的结果。

Figure 4. 当将位置属性 $l_i$ 固定为零并采样不同的外观原型时获得的多样性。(a) 场景图,(b) 从中提取布局的真实图像,(c–g)生成图像。

Figure 5. 在保持外观向量固定和从位置分布采样时获得的多样性。(a) 场景图,(b) 从中提取布局的地面真实图像,(c–g) 生成的图像。

Figure 6. 在生成的图像中复制对象的外观。图像是基于场景图创建的,外观是从五个不相关的图像中的一个中获取的。在本例中,天空的外观是从参照图像生成的,而其他所有对象都使用相同的随机外观原型。
-
Previous
【深度学习】SketchyCOCO: Image Generation from Freehand Scene Sketches -
Next
【深度学习】StyleGAN v2论文阅读