Using Transformers
Transformer模型通常都很大。 由于有数百万到数百亿的参数,训练和部署这些模型是一项复杂的工作。 此外,由于几乎每天都有新模型发布,而且每个模型都有自己的实现,所以把它们都试出来不是一件容易的事情。
Transformer库用来解决这个问题。 它的目标是提供一个单一的API,通过这个API可以加载、训练和保存任何Transformer模型。它的主要特点是:
- 易于使用:下载、加载和使用最先进的NLP模型进行推理只需两行代码。
- 灵活:它们的核心, 所有的模型都是像 PyTorch
nn.Module或者 Tensorflowtf.keras.Model类, 并且可以以它们机器学习框架的方式处理任意模型。 - 简单: 几乎没有对整个库进行任何抽象。”All in one file” 是一个核心概念:模型的前向传递完全在一个文件中定义,因此代码本身是可以理解和破解的。
最后一个特性使得 Transformers 不同与其他 ML 库。 模型不是建立在跨文件共享的模块上; 相反, 每个模型有它自己的层。 除了使模型更容易接近和理解之外,这还允许您轻松地在一个模型上进行实验,而不影响其他模型。
Behind the pipeline
让我们从一个完整的示例开始,看看在 ` Chapter 1` 中执行以下代码时幕后发生了什么:
1
2
3
4
5
6
7
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier([
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
])
得到:
1
2
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
如我们在 Chapter 1 中所见, 这个 pipeline 将三个 steps 组合在一起:preprocessing, passing inputs through the model, 以及 postprocessing :
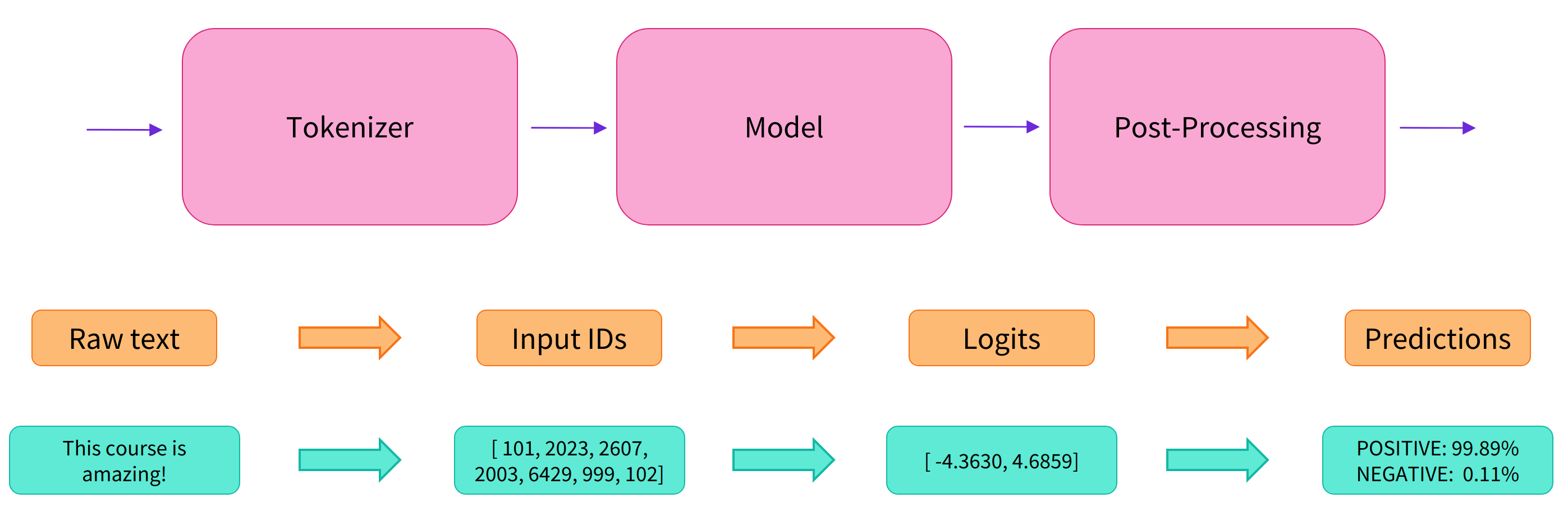
Preprocessing with a tokenizer
与其他神经网络一样,Transformer模型不能直接处理原始文本,因此我们 pipeline 的第一步是将文本输入转换为模型能够理解的数字。为了做到这一点我们使用一个 tokenizer, 它负责:
- 将输入分割成 words 、 subwords 或 symbols (如标点符号),称为 tokens
- 将每个 token 映射到一个整数
- 添加可能对模型有用的额外输入
所有这些预处理都需要以与模型预训练时完全相同的方式进行, 所以我们首先需要从 Model Hub 下载这些信息。为此, 我们使用 AutoTokenizer 类 和 它的 from_pretrained 方法。 使用我们模型的 checkpoint 名字, 它将自动获取与模型 tokenizer 相关的数据并缓存它。
因为 sentiment-analysis pipeline 的默认 checkpoint 是 distilbert-base-uncased-finetuned-sst-2-english, 我们作如下运行:
1
2
3
4
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
一旦我们有了 tokenizer, 我们可以直接将我们的句子传递给它,我们将得到一个字典,它用于好喂给我们的模型。 剩下要做的一件事是将输入id列表转换为 tensor 。
你可以使用 Transformers 而不需要关心它使用的后端 ML 框架。然而,Transformer模型只接受张量作为输入。
要指定我们想要返回的张量类型(PyTorch、TensorFlow或NumPy),我们使用 return_tensors 参数:
1
2
3
4
5
6
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
这里要记住的主要事情是,您可以传递一个句子或一个句子列表,以及指定想要返回的张量的类型(如果没有传递类型,您将得到一个列表的列表)。
下面是PyTorch张量的结果:
1
2
3
4
5
6
7
8
9
10
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
}
输出本身是一个包含两个键的字典, input_ids 和 attention_mask。 input_ids 包含两行整数(每个句子一个),它们是每个句子中 tokens 的唯一标识符。
Going through the model
我们可以下载我们预训练好的模型,就像我们使用 tokenizer 一样。Transformers 提供一个 AutoModel , 它也有一个 from_pretrained 方法:
1
2
3
4
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
在此代码片段中,我们下载了之前在 pipeline 中使用的 checkpoint(实际上应该已经缓存了),并使用它实例化一个模型。
该体系结构只包含基本的Transformer模块:给定一些输入,它输出我们称之为 hidden states 的内容,也称为 features。对于每个模型输入,我们将检索一个高维向量,表征Transformer模型对该输入的上下文理解。
虽然这些 hidden states 本身可能很有用,但它们通常是模型的另一部分,即 head 的输入。在 Chapter 1, 可以使用相同的结构执行不同的任务,但是每个任务都有与之相关联的不同的 head。
A high-dimensional vector?
Transformer 模块的输出向量通常很大。 它通常有三个维度。
- Batch size: 一次处理的序列数(在我们的示例中为2)。
- Sequence length: 序列长度(在我们的例子中是16)。
- Hidden size: 每个模型输入的向量维数。
由于最后一个值,它被称为高维的。Hidden size可以非常大(768对于较小的模型是常见的,在较大的模型中可以达到3072或更多)。
如果我们将预处理过的输入输入到模型中,就可以看到这一点:
1
2
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
1
torch.Size([2, 16, 768])
注意 Transformers 的输出像 namedtuples 或者 dictionaries。 你可以通过 attributes(outputs.last_hidden_state.shape) 或者 key(outputs["last_hidden_state"]) ,如果你知道你要找到东西的位置的话, 甚至通过索引 (outputs[0])。
Model heads: Making sense out of numbers
模型 heads 以 hidden states 的高维向量作为输入, 并且将它们投影到一不同的维度。 它们通常由一些线性层组成:
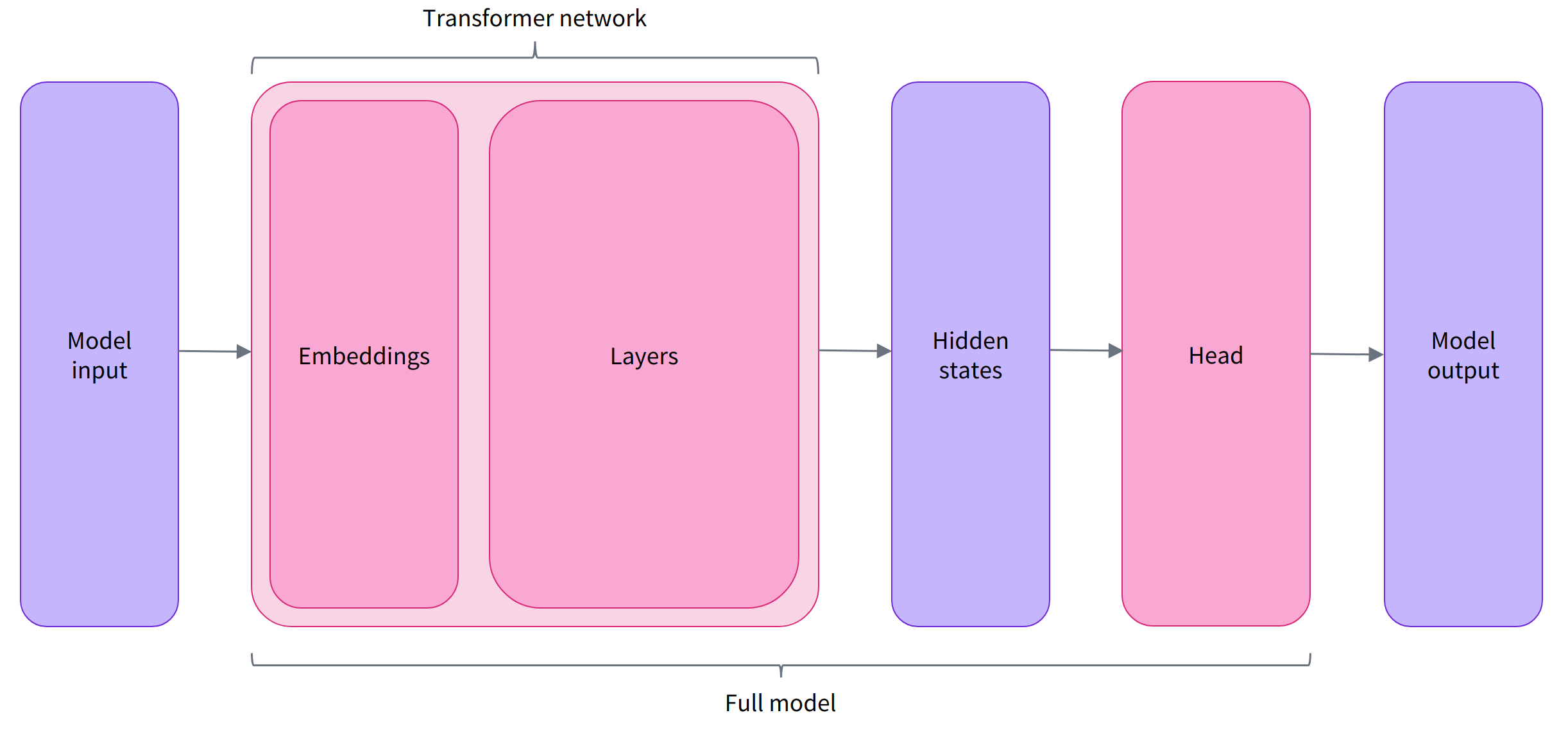
Transformer模型的输出直接发送到模型 head 进行处理。
在这个图中, 模型被表示为 embeddings layer 和 subsequent layers。 embeddings layer 将 输入ID 转换为 tokenized 输入, 再转换成一个与 token 相关的向量。subsequent layers 使用注意力机制控制这些向量产生最终句子的表征。
在 Transformer 中有很多可用的不同的结构, 每一个都是解决特定任务设计的:
*Model (retrieve the hidden states)*ForCausalLM*ForMaskedLM*ForMultipleChoice*ForQuestionAnswering*ForSequenceClassification*ForTokenClassification- and others
对于我们的例子, 我们将需要一个带有 a sequence classification head 的模型(能把句子分为肯定和否定)。因此,我们实际上不使用 AutoModel 类, 而是 AutoModelForSequenceClassification:
1
2
3
4
5
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
现在,如果我们观察我们输入的形状,维度会低得多: model head将我们之前看到的高维向量作为输入,输出的向量包含两个值(每个标签一个):
1
print(outputs.logits.shape)
1
torch.Size([2, 2])
因为我们只有两个句子和两个标签,我们从我们的模型得到的结果是形状为2 x 2。
Postprocessing the output
我们从模型中获得的输出值本身并不一定有意义。让我们来看一看
1
print(outputs.logits)
1
2
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward>)
我们模型对第一个句子的预测 ([-1.5607, 1.6123]) 和 第二个句子的预测 ([ 4.1692, -3.3464])。 这些不是概率,而是 logits,即模型最后一层输出的原始的、未标准化的分数。为了转化成概率, 它们需要通过一个 SoftMax 层。
1
2
3
4
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
1
2
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward>)
现在我们可以看到模型对第一个句子的预测 [0.0402, 0.9598] 和 对第二个句子的预测 [0.9995, 0.0005]。 这些是可识别的概率得分。
为了获得每个位置对应的标签,我们可以检查模型配置的 id2label 属性(下一节将对此进行更多介绍)
1
model.config.id2label
1
{0: 'NEGATIVE', 1: 'POSITIVE'}
Models
在本节中,我们将进一步了解模型的创建和使用。我们将使用 AutoModel 类,当您想从一个 checkpoint 实例化任何模型时,它很方便。
AutoModel 类及其所有相关类实际上是库中各种可用模型的简单封装。它是一个聪明的封装器,因为它可以自动地为您的 checkpoint 猜测适当的模型结构,然后用这个结构实例化一个模型。
但是,如果您知道您想要使用的模型类型,您可以使用直接定义其结构的类。让我们看看BERT模型是如何工作的。
Creating a Transformer
始化BERT模型需要做的第一件事是加载一个 configuration 对象
1
2
3
4
5
6
7
from transformers import BertConfig, BertModel
# Building the config
config = BertConfig()
# Building the model from the config
model = BertModel(config)
configuration 包含许多用于构建模型的属性:
1
print(config)
1
2
3
4
5
6
7
8
9
BertConfig {
[...]
"hidden_size": 768,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
[...]
}
虽然还没有看到所有这些 attributes 的作用,但是应该认识其中一些: hidden_size attribute 定义了 hidden_states 向量的大小, num_hidden_layers 定义了 Transformer 模型有多少层。
Different loading methods
从默认 configuration 创建模型时,将使用随机值对其进行初始化:
1
2
3
4
5
6
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
# Model is randomly initialized!
模型可以在这种状态下使用,但它会输出乱码; 首先需要对它进行训练。我们可以从零开始训练模型,但正如你在 Chapter 1 看到的,这将需要很长时间和大量的数据,它将有不可忽视的环境影响。为了避免不必要和重复的工作,能够共享和重用已经训练过的模型是非常必要的。
加载一个已经训练过的Transformer模型很简单,我们可以使用 from_pretrained 方法来实现这一点:
1
2
3
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
正如您前面看到的,我们可以用等价的 AutoModel 类替换BertModel。我们将从现在开始这样做,因为这会产生 checkpoint-agnostic 的代码;如果您的代码对一个 checkpoint 有效,那么它应该与另一个 checkpoint 无缝地工作。只要 checkpoint 接受过类似任务的训练,即使结构不同,这也适用(for example, a sentiment analysis task)。
在上面的代码示例中,我们没有使用 BertConfig,而是通过 bert-base-cased 的标识符加载预先训练过的模型。这是BERT作者自己训练的一个模型 checkpoint;你可以在它的 model card上找到更多的细节。
这个模型现在使用 checkpoint 的所有权重进行初始化。它可以直接用于对训练的任务进行推理,也可以对新任务进行微调。通过预训练的权重训练,而不是从零开始,我们可以很快达到良好的效果。
权重已经被下载并缓存到缓存文件夹中(因此以后调用 from_pretrained 方法不会重新下载它们), 它的默认路径是 ~/.cache/huggingface/transformers。 你可以通过 HF_HOME 环境变量自定义缓存文件夹。
用于加载模型的标识符可以是 Model Hub上任何模型的标识符,只要它与BERT结构兼容。可用BERT checkpoints 的完整列表可以在这里找到。
Saving methods
保存模型和加载模型一样简单,我们使用 save_pretrained 方法,它类似于 from_pretrained 方法:
1
model.save_pretrained("directory_on_my_computer")
这将在磁盘上保存两个文件:
1
2
3
ls directory_on_my_computer
config.json pytorch_model.bin
如果你看一下 config.json 文件,您将识别构建模型结构所需的属性。这个文件还包含了一些元数据,比如 checkpoint 源自哪里, 你最后一次保存 checkpoint 使用的 Transformers 版本。
pytorch——model.bin 文件被称为 state dictionary; 它包含所有模型的权重。这两个文件是密切相关的; configuration对于了解您的模型体系结构是必要的,而模型权重是您的模型参数。
Using a Transformer model for inference
现在您已经知道了如何加载和保存模型,让我们尝试使用它来进行一些预测。Transformer 模型只能处理数字 —— 数字由 tokenizer 生成。 但是在讨论 tokenizers 之前,让我们先研究一下模型接受哪些输入。
Tokenizers 可以将输入转换成合适框架的 tensors, 而且可以帮助你理解发生了什么, 我们将快速了解在向模型发送输入之前必须做什么。
假设我们有几个序列:
1
2
3
4
5
sequences = [
"Hello!",
"Cool.",
"Nice!"
]
tokenizer 转换这些词典的索引, 它们被称之为 input IDs. 每个序列现在都是一组数字!得到的输出是:
1
2
3
4
5
encoded_sequences = [
[ 101, 7592, 999, 102],
[ 101, 4658, 1012, 102],
[ 101, 3835, 999, 102]
]
这是一个编码序列的列表:列表的列表。Tensors 仅接受矩形形状。 这个数组已经是矩形了,所以把它转换成张量很容易。
1
2
3
import torch
model_inputs = torch.tensor(encoded_sequences)
Using the tensors as inputs to the model
利用模型中的张量非常简单我们只需要调用带输入的模型
1
output = model(model_inputs)
虽然模型接受许多不同的参数,但只有输入id是必需的。稍后,我们将解释其他参数的作用以及在什么时候需要它们,但首先,我们需要仔细研究 tokenizers, 它构建Transformer模型可以理解的输入。
Tokenizers
Tokenizers 是NLP pipeline的核心组件之一。它们只有一个目的:将文本转换为模型可以处理的数据。模型只能处理数字,所以 tokenizers 需要将文本输入转换为数字数据。在本节中,我们将探究tokenization pipeline中到底发生了什么。
在NLP任务中,通常处理的数据是原始文本。以下是此类文本的一个例子:
1
Jim Henson was a puppeteer
但是,模型只能处理数字,所以我们需要找到一种将原始文本转换为数字的方法。这就是 tokenizers 的作用,有很多方法可以做到这一点。目标是找到最有意义的表示,也就是对模型最有意义的表示,如果可能的话,是最小的表示。
Word-based
第一种 tokenize r是 word-based 的。 它的设置和使用通常非常简单,只需要一些规则,而且通常会产生不错的结果。例如,在下面的图片中,我们的目标是将原始文本分解成单词,并为每个单词找到数字表示:
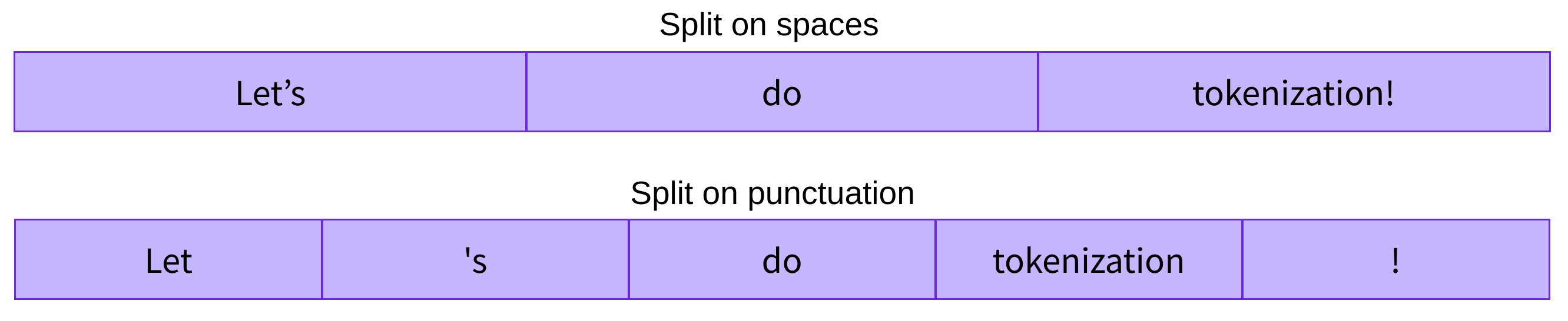
有不同的方法来拆分文本。例如,我们可以通过应用Python的split函数,使用空格将文本标记为单词:
1
2
tokenized_text = "Jim Henson was a puppeteer".split()
print(tokenized_text)
1
['Jim', 'Henson', 'was', 'a', 'puppeteer']
还有一些单词 tokenizers 的变体对标点有额外的规则。有了这种 tokenizer, 我们可以得到一些相当大的词汇表,其中,词汇表由语料库中独立 tokens 的总数来定义。
每个单词都被分配一个ID,从0开始,一直到词汇表的大小。模型使用这些id来标识每个单词。
如果我们希望使用 word-based 的 tokenizer 完全覆盖一种语言,那么我们需要为该语言中的每个单词提供一个标识符,这将生成大量标记。例如,英语中有超过50万个单词,因此要构建从每个单词到输入ID的映射,我们需要跟踪这些ID。此外,像 “dog” 这样的词与像 “dogs” 这样的词的表示方式是不同的,模型最初将无法知道 “dog” 和 “dogs” 是相似的:它将识别出两个词是不相关的。这同样适用于其他类似的词,如 “run” 和 “running”,模型最初不会看到它们是相似的。
最后,我们需要一个自定义 token 来表示不在词汇表中的单词。这被称为 “unknown” token,通常表示为 [UNK] 。如果 tokenizer 生成大量这样的标记,这通常是一个不好的迹象,因为它无法检索单词的合理表示,并且在此过程中会丢失信息。设计词汇表时的目标是让 tokenizer 将尽可能少的单词标记到未知标记中。
一种减少未知 tokens 的方法是更进一步, 使用 character-based tokenizer。
Character-based
Character-based tokenizers 将文本拆分成 characters, 而不是 words。 它主要由两个好处:
- 词汇表(vocabulary)要小得多。
- 词汇表外(未知) tokens 要少得多,因为每个 word 都可以由 characters 构建。
但是这里也出现了一些关于空格和标点符号的问题:

这种方法也不完美。因为现在的表现是基于 characters 而不是 words,所以我们可以从直觉上认为这是没有意义的: 每个 characters 本身的含义并不是很多,而 words 则不是。然而,这又因语言而异;例如,在中文中,每个 characters 所携带的信息比拉丁语中的一个 characters 要多。
需要考虑的另一件事是,我们的模型最终将处理大量的 tokens :虽然一个 word 只有一个 word-based 的 tokenizer,但在转换为 characters 时,它可以很容易地转换为10个或更多的 tokens。
为了获得这两种方法的最佳效果,我们可以使用结合这两种方法的第三种技术: subword tokenization。
Subword tokenization
Subword tokenization 算法的基本原则是不将常用词分解为较小的子词,而将生僻词分解为有意义的子词。
例如, “annoyingly” 可能被认为是一个生僻词,可以被分解为 “annoying” 的和 “ly”。这两个词单独出现的频率更高,同时“annoyingly” 的意思由 “annoying” 和 “ly” 的复合意思保留。
下面是一个例子,展示了 subword tokenization 算法如何标记序列“Let’s do tokenization!”:

这些 subwords 最终提供了很多语义含义:例如,在上面的例子中 “tokenization” 被拆分成 “token” 和 “ization”, 两个具有语义含义且具有空间效率的tokens(只需要两个tokens就可以表示一个长单词)。这允许我们用较小的词汇表获得相对较好的覆盖率,并且几乎没有未知的 tokens。
这种方法在黏着性语言(如土耳其语)中特别有用,在这种语言中,可以通过将子词串在一起形成(几乎)任意长的复杂单词。
And more!
还有很多其他的技术。举几个例子:
- Byte-level BPE, as used in GPT-2
- WordPiece, as used in BERT
- SentencePiece or Unigram, as used in several multilingual models
您现在应该对 tokenizers 如何工作有了足够的了解,以便开始使用API。
Loading and saving
加载和保存 tokenizers 和模型一样简单。实际上,它是基于相同的两个方法: from_pretrained和 save_pretrained。这些方法将加载或保存 tokenizer 使用的算法(有点像模型的结构)及其词汇表(有点像模型的权重)。
加载 BERT tokenizer 与加载模型的方式相同,只是我们使用了BertTokenizer类:
1
2
3
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
与 AutoModel 类似,AutoTokenizer 类将基于 checkpoint 名称获取库中适当的 tokenizer ,并可以直接用于任何checkpoint:
1
2
3
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
我们现在可以使用tokenizer,如前一节所示
1
tokenizer("Using a Transformer network is simple")
1
2
3
{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
保存 tokenizer 和保存模型一样:
1
tokenizer.save_pretrained("directory_on_my_computer")
我们将在 Chapter 3 中更多地讨论 token_type_ids,稍后我们将解释 attention_mask。首先, 我们看一下 input_ids 如何生成。 为此,我们需要查看 tokenizer 的中间方法。
Encoding
将文本转换成数字称为编码。编码过程分为两个步骤: tokenization,然后转换为输入id。
正如我们所看到的,第一步是将文本拆分为单词(或部分单词、标点符号等),通常称为 tokens。有多个规则可以管理这个过程,这就是为什么我们需要使用模型的名称来实例化 tokenizer,以确保我们使用了与模型预训练时使用的相同的规则。
第二步是将这些 tokens 转换为数字,这样我们就可以用它们构建一个张量,并将它们提供给模型。为此,tokenizer 有一个 vocabulary,当我们使用 from_pretrained 方法实例化它时,就会下载这个词汇表。同样,我们需要使用预训练模型时使用的相同词汇表。
为了更好地理解这两个步骤,我们将分别研究它们。注意,我们将使用一些方法分别执行 tokenization pipeline 的部分内容,以向您显示这些步骤的中间结果,但在实践中,您应该直接在输入上调用 tokenizer (如 section 2 所示)。
Tokenization
tokenization 过程是通过 tokenizer 的 tokenize 方法完成的:
1
2
3
4
5
6
7
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
这个方法的输出是字符串或 tokens 的列表:
1
['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']
这个 tokenizer 是一个 subword tokenizer: 它拆分 words,直到获得可以用词汇表表示的 tokens。以 Transformer 为例, 它被分为两个标记: transform 和 ##er。
From tokens to input IDs
input IDs 的转换由 tokenizer 的 convert_tokens_to_ids 方法处理:
1
2
3
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
1
[7993, 170, 11303, 1200, 2443, 1110, 3014]
这些输出一旦转换为适当的框架张量,就可以用作本章前面所见的模型的输入。
Decoding
解码则是反过来的:我们想从词汇表索引中获得一个字符串。这可以通过如下的解码方法来实现:
1
2
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)
1
'Using a Transformer network is simple'
注意,decode 方法不仅将索引转换回标记,而且还将属于相同单词的标记组合在一起,以生成可读的句子。当我们使用预测新文本的模型时(无论是根据提示生成的文本,还是针对翻译或摘要等序列到序列的问题),这种行为将非常有用。
Handling multiple sequences
在前一节中,我们探索了最简单的用例:对一个较小长度的序列进行推理。然而,已经出现了一些问题:
- 我们如何处理多个序列?
- 我们如何处理多个不同长度的序列?
- 词汇表索引是允许模型良好工作的唯一输入吗?
- 有过长的序列吗?
让我们看看这些问题会带来什么样的问题,并且使用 Transformers API 如何解决它们。
Models expect a batch of inputs
在前面的练习中,您看到了如何将序列转换为数字列表。让我们把这些数转换成一个张量并把它发送给模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor(ids)
# This line will fail.
model(input_ids)
1
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
为什么失败了呢?我们遵循了 section 2 中的步骤。
这个问题是因为我们向模型发送了单个序列, 而 Transformers 模型默认情况下使用多个句子。在这里,当我们将 tokenizer 应用到序列时,我们试图完成 tokenizer 在幕后所做的一切, 但是如果你仔细观察,你会发现它不仅仅是把输入id的列表转换成一个张量,它还在上面加了一个维数。
1
2
tokenized_inputs = tokenizer(sequence, return_tensors="pt")
print(tokenized_inputs["input_ids"])
1
2
tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,
2607, 2026, 2878, 2166, 1012, 102]])
让我们再试一次,添加一个新的维度:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([ids])
print("Input IDs:", input_ids)
output = model(input_ids)
print("Logits:", output.logits)
我们打印 输入id 以及 输出结果 logits —— 这里是输出:
1
2
Input IDs: [[ 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]]
Logits: [[-2.7276, 2.8789]]
批处理是通过模型同时发送多个句子的行为。如果你只有一个句子,你可以用一个序列来构建一个batch:
1
batched_ids = [ids, ids]
这是由两个相同序列组成的一批。
批处理允许模型在输入多个句子时工作。使用多个序列就像用单个序列构建一批一样简单。不过还有第二个问题。当你试图将两个(或更多)句子组合在一起时,它们的长度可能不同。如果你以前用过张量,你就知道它们必须是矩形的,所以你不能把输入id的列表直接转换成张量。为了解决这个问题,我们通常 pad 输入。
Padding the inputs
以下列表的列表不能转换为张量
1
2
3
4
batched_ids = [
[200, 200, 200],
[200, 200]
]
为了解决这个问题,我们将使用 padding 称一个矩形形状制作 tensor。Padding通过向具有较少值的句子添加一个称为Padding标记的特殊单词来确保我们所有的句子具有相同的长度。例如,如果你有10个含有10个单词的句子和1个含有20个单词的句子,填充会确保所有的句子都含有20个单词。在我们的例子中,得到的张量是这样的:
1
2
3
4
5
6
padding_id = 100
batched_ids = [
[200, 200, 200],
[200, 200, padding_id]
]
paddding token ID 可以在 tokenizer.pad_token_id 中找到。 让我们使用它,并将我们的两个句子分别和批量一起发送到模型。
1
2
3
4
5
6
7
8
9
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence1_ids = [[200, 200, 200]]
sequence2_ids = [[200, 200]]
batched_ids = [[200, 200, 200], [200, 200, tokenizer.pad_token_id]]
print(model(torch.tensor(sequence1_ids)).logits)
print(model(torch.tensor(sequence2_ids)).logits)
print(model(torch.tensor(batched_ids)).logits)
1
2
3
4
tensor([[ 1.5694, -1.3895]], grad_fn=<AddmmBackward>)
tensor([[ 0.5803, -0.4125]], grad_fn=<AddmmBackward>)
tensor([[ 1.5694, -1.3895],
[ 1.3373, -1.2163]], grad_fn=<AddmmBackward>)
在我们的批处理预测中,有一些错误的logit: 第二行应该与第二句的logits相同,但是我们得到了完全不同的值。
这是因为Transformer模型的关键特性是 attention 层, 它将每个token contextualize。这些将考虑padding tokens,因为它们涉及序列的所有 tokens。当通过模型传递不同长度的单个句子时,或者当传递应用了相同句子和填充的批处理时,为了获得相同的结果,我们需要告诉那些 attention 层忽略 padding tokens。这可以通过使用 attention mask 来实现。
Attention masks
Attention masks 是有着和输入 IDs tensor 相同形状的 tensor,值为0和1: 1表示应该涉及的tokens, 0表示不应该涉及的tokens(也就是说,它们应该被模型的 attention 层忽略)。
让我们用一个 attention mask 来完成前面的示例:
1
2
3
4
5
6
7
8
9
10
11
12
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id]
]
attention_mask = [
[1, 1, 1],
[1, 1, 0]
]
outputs = model(torch.tensor(batched_ids), attention_mask=torch.tensor(attention_mask))
print(outputs.logits)
1
2
tensor([[ 1.5694, -1.3895],
[ 0.5803, -0.4125]], grad_fn=<AddmmBackward>)
现在我们得到了批处理中第二个句子相同的logit。
请注意第二个序列的最后一个值是一个padding ID,它在 attention mask 中是一个0值。
Longer sequences
对于Transformer模型,可以传递给模型的序列的长度是有限制的。大多数模型处理最多512或1024个 tokens 的序列,当要求处理更长的序列时将崩溃。这个问题有两种解决方案:
- 使用支持较长的序列长度的模型。
- 截断你的序列。
模型支持不同的序列长度,有些模型专门处理非常长的序列。Longformer是一个例子,LED是另一个例子。如果你正在处理一个需要很长序列的任务,我们建议你看看这些模型。
否则,我们建议您通过指定 max_sequence_length 参数:
1
sequence = sequence[:max_sequence_length]
Putting it all together
在最后的几个部分中,我们一直在努力手工完成大部分的工作。我们已经探讨了 tokenizers 的工作原理,并研究了tokenization、conversion to input IDs、padding、truncation和attention masks。
然而, 如我们在 section 2 所见, ,我们在这里会深入Transformers API可以处理所有的这些高级函数。当您直接在句子上调用 tokenizer 时,您将获得可以通过模型传递的输入:
1
2
3
4
5
6
7
8
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
在这里,model_inputs 变量包含模型良好运行所必需的一切。对于DistilBERT,它包括 input IDs 和 attention mask。接受其他输入的其他模型也 有由 tokenizer 对象 提供的输出。
正如我们将在下面的一些示例中看到的,这种方法非常强大。首先,它可以标记单个序列:
1
2
3
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
它还一次处理多个序列,API中没有任何更改:
1
2
3
4
5
6
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"So have I!"
]
model_inputs = tokenizer(sequences)
它可以根据几个目标进行填充
1
2
3
4
5
6
7
8
9
# Will pad the sequences up to the maximum sequence length
model_inputs = tokenizer(sequences, padding="longest")
# Will pad the sequences up to the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, padding="max_length")
# Will pad the sequences up to the specified max length
model_inputs = tokenizer(sequences, padding="max_length", max_length=8)
它还可以截断序列
1
2
3
4
5
6
7
8
9
10
11
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"So have I!"
]
# Will truncate the sequences that are longer than the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, truncation=True)
# Will truncate the sequences that are longer than the specified max length
model_inputs = tokenizer(sequences, max_length=8, truncation=True)
tokenizer 对象可以处理到特定框架张量的转换,然后可以直接将其发送给模型。例如,在下面的代码示例中,我们将使 tokenizer 返回来自不同框架的张量 —— “pt” 返回 PyTorch tensors, “tf” 返回 TensorFlow tensors, 以及 “np” 返回 NumPy arrays:
1
2
3
4
5
6
7
8
9
10
11
12
13
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"So have I!"
]
# Returns PyTorch tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
# Returns TensorFlow tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="tf")
# Returns NumPy arrays
model_inputs = tokenizer(sequences, padding=True, return_tensors="np")
Special tokens
如果我们看一下由 tokenizer 返回的输入id,就会发现它们与之前的略有不同:
1
2
3
4
5
6
7
8
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
print(model_inputs["input_ids"])
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
1
2
[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102]
[1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]
在开头添加一个token ID,在末尾添加一个token ID。让我们解码上面的两个id序列,看看这是关于什么:
1
2
print(tokenizer.decode(model_inputs["input_ids"]))
print(tokenizer.decode(ids))
1
2
"[CLS] i've been waiting for a huggingface course my whole life. [SEP]"
"i've been waiting for a huggingface course my whole life."
tokenizer 在开头添加了特殊词 [CLS],在结尾添加了特殊词 [SEP]。这是因为模型是用这些进行预训练的,所以为了得到相同的推理结果,我们也需要添加它们。注意,有些模型不添加特殊的单词,或者添加不同的单词;模型也可以只在开头或结尾添加这些特殊的词。在任何情况下,tokenizer 都知道哪些是预期的,并将为您处理这个问题。
Wrapping up: From tokenizer to model
现在我们已经看到了 tokenizer 对象在应用于文本时使用的所有单独步骤,让我们最后一次看看它是如何用它的主API处理多个序列(padding!)、非常长的序列(truncation!)和多种类型的张量的:
1
2
3
4
5
6
7
8
9
10
11
12
13
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"So have I!"
]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)
Fine-tuning a pretrained model
在 Chapter 2 中,我们探讨了如何使用 tokenizers 和预训练模型来进行预测。但是,如果您想为自己的数据集调整预先训练过的模型,该怎么办呢?这就是这一章的主题!您将学习:
- 如何从Hub准备大型数据集
- 如何使用 high-level Trainer API 来优化模型
- 如何使用自定义训练循环
- 如何利用 Accelerate 轻松地在任何分布式运行自定义训练循环设置
Processing the data
这里是我们如何在PyTorch中训练一个批次的 sequence classifier
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import torch
from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
# Same as before
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"This course is amazing!",
]
batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
# This is new
batch["labels"] = torch.tensor([1, 1])
optimizer = AdamW(model.parameters())
loss = model(**batch).loss
loss.backward()
optimizer.step()
当然,仅仅用两个句子来训练模型不会产生很好的结果。为了获得更好的结果,您需要准备一个更大的数据集。
在本节中,我们将使用MRPC(Microsoft Research Paraphrase Corpus)数据集作为示例。 该数据集由5801对句子组成,用一个标签表示它们是否被 paraphrases(即,如果两个句子的意思相同)。我们在本章中选择它是因为它是一个小的数据集,所以很容易实验训练它。
Loading a dataset from the Hub
Hub不只是包含模型;它也有多种不同语言的数据集。您可以在这里浏览数据集,我们建议您在读完这一节之后尝试加载和处理一个新的数据集(参见这里的通用文档)。但是现在,让我们把重点放在MRPC数据集上!这是组成GLUE benchmark的10个数据集之一,GLUE benchmark是一个学术基准,用于衡量跨10个不同文本分类任务的ML模型的性能。
Datasets 库提供了一个非常简单的命令来下载和缓存数据集。我们可以像这样下载MRPC数据集:
1
2
3
4
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
raw_datasets
1
2
3
4
5
6
7
8
9
10
11
12
13
14
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
如您所见,我们得到一个 DatasetDict 对象,它包含训练集、验证集和测试集。每一个都包含几个列(sentence1、sentence2、label和idx)和一个行变量,这是每个集合中的元素数量(因此,训练集中有3668对句子,验证集中有408对句子,测试集中有1725对句子)。
这个命令下载和缓存数据集, 默认为 ~/.cache/huggingface/dataset。
我们可以通过索引来访问 raw_datasets 对象中的每一对句子,就像使用字典一样:
1
2
raw_train_dataset = raw_datasets["train"]
raw_train_dataset[0]
1
2
3
4
{'idx': 0,
'label': 1,
'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'}
我们可以看到 labels 已经是整数了,所以我们不需要在那里做任何预处理。为了知道哪个整数对应于哪个标签,我们可以检查 raw_train_dataset 的 features。
1
raw_train_dataset.features
1
2
3
4
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
label 是 ClassLabel 类型, 从整数到标签名字的映射是按文件夹名字排序的。0 对应 not_equivalent, 1 对应 equivalent。
Preprocessing a dataset
为了预处理数据集,我们需要将文本转换为模型能够理解的数字。
正如您在前一章所看到的,这是通过 tokenizer 完成的。我们可以给 tokenizer 提供一个句子或一个句子列表,这样我们就可以像这样直接标记每对句子的第一个句子和第二个句子:
1
2
3
4
5
6
from transformers import AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
然而,我们不能仅仅传递两个序列给模型,就能预测这两个句子是否被paraphrases。我们需要成对处理这两个序列,并应用适当的预处理。幸运的是,tokenizer还可以采用一对序列,并按照BERT模型所期望的方式对其进行处理:
1
2
inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs
1
2
3
4
5
{
'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
我们在 Chapter 2 讨论了 input_ids 和 attention_mask 键值, 但是我们推迟讨论了 token_type_ids。 在这个例子中,它告诉模型输入的哪一部分是第一个句子,哪一部分是第二个句子。
如果我们解码 IDs 的 input_ids 返回 words:
1
tokenizer.convert_ids_to_tokens(inputs["input_ids"])
我们将会得到:
1
['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
所以当有两个句子时, 我们看到模型期望输入是这种形式 [CLS] sentence1 [SEP] sentence2 [SEP]。 使用 token_type_ids 对齐我们得到:
1
2
['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
如您所见,与 [CLS] sentence1 [SEP] 对应的输入部分的 token type ID都为0,而与 sentence2 [SEP] 对应的其他部分的token type ID都为1。
请注意,如果您选择一个不同的checkpoint,您不一定在您的 tokenized inputs 中有 token_type_ids (例如,如果您使用一个 DistilBERT 模型,它们就不会返回)。只有当模型知道如何处理它们时,它们才会被返回,因为它在训练前已经看到它们了。
在这里,BERT是用 token type IDs进行预训练的,并且在我们在 Chapter 1 中讨论的 masked language modeling objective 之上,它还有一个额外的目标,称为 next sentence prediction。这个任务的目标是建立句子对之间的关系模型。
对于下一个句子预测,该模型被提供成对的句子(with randomly masked tokens),并被要求预测第二个句子是否在第一个句子之后。为了让这个任务不那么non-trivial,一半的时间里,句子从原始文档中提取出来,另一半时间里,这两个句子来自两个不同的文档。
通常,您不需要担心在您的标记化输入中是否有 token_type_ids :只要您为 tokenizer 和 model 使用相同的checkpoint,一切都会很好,因为 tokenizer 知道为它的模型提供什么。
现在我们已经看到了我们的 tokenizer 如何处理一对句子,我们可以使用它来标记整个数据集: 我们可以给标记器提供一个句子对列表,先给它第一个句子的列表,然后给它第二个句子的列表。这也与我们在 Chapter 2 中看到的 padding 和 truncation 选项兼容。所以,预处理训练数据集的一种方法是:
1
2
3
4
5
6
tokenized_dataset = tokenizer(
raw_datasets["train"]["sentence1"],
raw_datasets["train"]["sentence2"],
padding=True,
truncation=True,
)
这可以很好地工作,但是它有返回字典的缺点(我们的 key 为 input_ids, attention_mask 和 token_type_ids, values为列表的列表)。只有当你有足够的RAM在 tokenization 期间存储你的整个数据集时,它才会工作(Datasets 库是Apache Arrow文件存储在磁盘上,所以你只保留你所需要的样本加载在内存中)。
要将数据保存为数据集,我们将使用 Dataset.map 的方法。如果我们需要做更多的预处理,而不仅仅是 tokenization ,这也允许我们有一些额外的灵活性。map方法的工作原理是在数据集的每个元素上应用一个函数,所以让我们定义一个函数来 tokenizes 我们的输入:
1
2
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
这个函数接受一个字典(like the items of our dataset),并返回一个新的字典,其中包含 key 为 input_ids、attention_mask 和 token_type_ids。请注意,如果 example 字典包含几个样本(each key as a list of sentences),它也可以工作,因为正如前面所见,标记器对句子对列表起作用。这将允许我们在 map 调用中使用batched=True 选项,这将大大加快tokenization。 tokenizer 由一个用Rust语言写的 Tokenizers 库支撑。这个tokenizer 可以非常快,但只有在我们一次给它大量输入的情况下。
注意,我们现在在 tokenization 函数中省略了padding参数。这是因为填充所有的样本到最大长度是没有效率的:当我们构建一个批次时 padding 样本更好,因为这样我们只需要填充到该批次的最大长度,而不是整个数据集的最大长度。
下面是我们如何在所有数据集上一次性应用 tokenization 函数。我们在 map 调用中使用了 batch =True,因此函数一次应用于数据集的多个元素,而不是单独应用于每个元素。
1
2
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
Datasets 库应用这种处理的方式是通过增加数据集新的字段, 每个键对应由预处理函数返回的字典中的每个键:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
DatasetDict({
train: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 3668
})
validation: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
test: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 1725
})
})
在对 Dataset.map 应用 preprocessing 函数时,甚至可以通过传递 num_proc 参数进行映射使用multiprocessing。我们这里没有这样做,因为 Tokenizers 库已经使用多个线程标记样本更快,但是如果你不使用 fast tokenizer 这个库的支持,这可能会加快你的预处理。
我们的 tokenize_function 返回键值为 input_ids、attention_mask和 token_type_ids 的字典,因此这三个字段被添加到我们的数据集的所有分割中。注意,如果预处理函数为我们应用映射的数据集中的现有键返回一个新值,那么我们也可以更改现有字段。
我们需要做的最后一件事是,当我们对元素进行批处理时,将所有的例子填充到最长元素的长度,我们称之为动态填充。
Dynamic padding
在PyTorch中,负责在批处理中组合样本的函数称为 collate 函数。它是构建 DataLoader 时可以传递的参数,默认值是将样本转换为PyTorch张量并拼接它们(如果元素是列表、元组或字典,则是递归地拼接)的函数。这在我们的情况下是不可能的,因为我们的输入不会都是相同的大小。我们已经故意推迟了填充,以便只在每个批处理上应用它,避免有太多填充导致过长的输入。这将加快相当多的训练,但请注意,如果你在一个TPU上训练,它会导致问题,TPU喜欢固定的形状,即使这需要额外的填充。
要在实践中做到这一点,我们必须定义一个collate函数,它将对我们想要一起批处理的数据集的项应用正确数量的填充。幸运的是,Transformers 库通过 DataCollatorWithPadding 为我们提供了这样的函数。当您实例化它时,它接受一个tokenizer(以知道使用哪个padding token,以及模型期望填充在输入的左边还是右边),并将完成您需要的一切:
1
2
3
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
为了测试这个新玩具,让我们从我们的训练集中抓取一些样本,我们想一起批量训练。这里,我们删除了列 idx、sentence1 和 sentence2,因为它们不需要并且包含字符串(我们不能用字符串创建张量),并查看批处理中每个条目的长度。
1
2
3
4
5
samples = tokenized_datasets["train"][:8]
samples = {
k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]
}
[len(x) for x in samples["input_ids"]]
我们得到的样本长度从32到67不等Dynamic padding 是指这批样本全部填充到长度为67,即这批样本的最大长度。如果没有动态填充,所有的样本都必须填充到整个数据集的最大长度,或者模型可以接受的最大长度。让我们再次检查我们的 data_collator 是否正确地动态填充了这批数据:
1
2
batch = data_collator(samples)
{k: v.shape for k, v in batch.items()}
1
2
3
4
{'attention_mask': torch.Size([8, 67]),
'input_ids': torch.Size([8, 67]),
'token_type_ids': torch.Size([8, 67]),
'labels': torch.Size([8])}
看上去不错!现在我们已经从原始文本转向模型可以处理的批量文本,我们准备对其进行微调。
Fine-tuning a model with the Trainer API
Transformers 提供了一个Trainer类来帮助您调整它在您的数据集上提供的任何预训练模型。完成了上一节中所有的数据预处理工作之后,就只剩下几个步骤来定义Trainer了。最困难的部分可能是为运行Trainer.train准备环境,因为它在CPU上运行得很慢。
下面的代码示例假设您已经执行了上一节中的示例。下面是一个简短的总结,概述你所需要的:
1
2
3
4
5
6
7
8
9
10
11
12
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
Training
在定义 Trainer 之前的第一步是定义一个 TrainingArguments 类,这个类将包含 Trainer 用于训练和评估的所有超参数。您必须提供的唯一参数是保存训练过的模型的目录,以及checkpoints。对于剩下的部分,您可以保留默认值,对于基本的微调应该可以很好地工作。
1
2
3
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
第二步是定义我们的模型。和前一章一样,我们将使用带有两个标签的 AutoModelForSequenceClassification 类:
1
2
3
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
您将注意到,与第2章不同的是,在实例化这个预训练模型后,您会得到一个警告。这是因为BERT没有进行过句子对分类的预训练,所以我们放弃了预训练模型的head,而添加了一个新的适合序列分类的head。这些警告表明,一些权重没有被使用(预训练的head的权重被丢弃),而另一些则被随机初始化(用于新head的权重)。
一旦我们有了我们的模型,我们就可以通过传递到目前为止构建的所有目标来定义 Trainer —— model、training_args、training 和validation datasets、data_collator 和 tokenizer。
1
2
3
4
5
6
7
8
9
10
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
请注意,当您像我们在这里所做的那样传递 tokenizer 时,Trainer 使用的默认 data_collator 将是前面定义的DataCollatorWithPadding,因此您可以跳过这个调用中的 data collator=data collator 这一行。
要微调数据集上的模型,我们只需要调用 Trainer 的 train 方法:
1
trainer.train()
这将开始微调(在GPU上应该需要几分钟),并每500步报告训练损失。然而,它不会告诉您您的模型运行得有多好(或多差)。这是因为:
- 我们没有告诉 Trainer 在训练期间进行评估, 通过将 evaluation_strategy 设置为 “steps”(每个eval步骤评估)或 “epoch” (在每个epoch的末尾评估)来进行评估。
- 我们没有为 Trainer 提供一个 compute_metrics 函数来在评估期间计算度量(否则评估就会打印出损失,这不是一个非常直观的数字)。
Tokenizer Doc
Quicktour
Training the tokenizer
我们使用 Byte-Pair Encoding (BPE) tokenizer。
- 从训练语料库中出现的所有 characters 作为 tokens 开始。
- 识别最常见的tokens pair,并将其合并为一个token。
- 重复, 直到 vocabulary 达到我们想要的大小
主要的API是类 Tokenizer, 下面是如何实例化一个BPE模型:
1
2
3
4
from tokenizers import Tokenizer
from tokenizers.models import BPE
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
为了训练tokenizer, 我们需要实例化一个 trainer, 在这里使用 BpeTrainer:
1
2
3
from tokenizers.trainers import BpeTrainer
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
我们可以设置训练参数 vocab_size 或 min_frequency(这里它们的默认值是30000和0)。 最重要的部分是我们之后会用到的 special_tokens。
Note: special token的顺序非常重要, 这里 [UNK] 将会得到ID 0, [CLS] 将会得到ID 1, 以此类推
我们可以现在训练我们的tokenizer, 但这不会是最优的。 如果不是用 pre-tokenizer 将会将我们的输入拆分成词, 我们可能得到几个重叠的词: 比如我们可能得到 it is token 因为这两个词通常会相邻出现。使用 pre-tokenizer 将确保没有 token 会比 pre-tokenizer 返回的词更大。这里我们想要训练一个 subword BPE tokenizer, 以及我们将要通过空格分割使用一个尽可能最简单的 pre-tokenizer。
1
2
3
from tokenizers.pre_tokenizers import Whitespace
tokenizer.pre_tokenizer = Whitespace()
现在, 我们可以使用任意我们想要使用的文件列表调用 train() 方法:
1
2
files = [f"data/wikitext-103-raw/wiki.{split}.raw" for split in ["test", "train", "valid"]]
tokenizer.train(files, trainer)
保存所有的配置和词典到一个文件, 可以使用 save() 方法:
1
tokenizer.save("data/tokenizer-wiki.json")
也可以使用 from_file() 方法从文件加载 tokenizer:
1
tokenizer = Tokenizer.from_file("data/tokenizer-wiki.json")
Using the tokenizer
现在我们已经训练了一个 tokenizer, 我们可以在使用它的 ` encode()` 方法 处理任意文本。
1
output = tokenizer.encode("Hello, y'all! How are you 😁 ?")
Tokenization pipeline
当调用 encode() 或者 encode_batch(), 输入的文本将执行以下pipeline:
- Normalization
- Pre-Tokenization
- The Model
- Post-Processing
Normalization
Normalization 是你应用在原始字符串上的一系列操作, 使得它更少的随机性或者更干净。通常的操作包括 stripping whitespace, removing accented characters 或者 lowercasing all text。 如果你熟悉 Unicode normalization, 它也是应用在大多数tokenizers中的非常常见的规范化操作。
在 Tokenizer 库中每个规范化操作被表示为一个 Normalizer, 并且你可以使用一个 Sequence 组合它们。 下面是一个使用 NFD Unicode normalization 和 removing accents 的例子:
1
2
3
4
from tokenizers import normalizers
from tokenizers.normalizers import NFD, StripAccents
normalizer = normalizers.Sequence([NFD(), StripAccents()])
你可以在任意字符串上测试 normalizer。
当建立一个 Tokenizer, 你可以通过改变相应的 attribute 定制化 normalizer。
1
tokenizer.normalizer = normalizer
当然, 如果你更换了一个 tokenizer 的 normalization, 你应该从头训练 tokenizer。
- NFD: NFD unicode normalization
- NFKD: NFKD unicode normalization
- NFC: NFC unicode normalization
- NFKC: NFKC unicode normalization
- Lowercase: 将所有大写替换为小写
- Strip: 移除掉输出指定侧(left, right, 或者两边)的空格字符
- StripAccents: 移除掉unicode中的所有重音符号(用在NFD中为了一致性)
- Replace:用定制化的字符串替换掉指定内容
- BertNormalizer: 提供一系列原始BERT中的 Normalizer
-
- clean_text
-
- handle_chinese_chars
-
- strip_accents
-
- lowercase
- Sequence:组合多个Normalizers
Pre-Tokenization
Pre-tokenization 是将文本拆分成更小的 objects 的方式, 它给出了你的 tokens 在训练时的上界。 一个很好的方式是将你的文本拆分成 “words”, 然后你最终的 tokens 将会是这些 words 中的一部分。
使用 空格 和 标点 将输入拆分是一种简单的 pre-tokenize 的方式, 它由 Whitespace pre-tokenizer实现:
1
2
3
4
5
6
7
from tokenizers.pre_tokenizers import Whitespace
pre_tokenizer = Whitespace()
pre_tokenizer.pre_tokenize_str("Hello! How are you? I'm fine, thank you.")
# [("Hello", (0, 5)), ("!", (5, 6)), ("How", (7, 10)), ("are", (11, 14)), ("you", (15, 18)),
# ("?", (18, 19)), ("I", (20, 21)), ("'", (21, 22)), ('m', (22, 23)), ("fine", (24, 28)),
# (",", (28, 29)), ("thank", (30, 35)), ("you", (36, 39)), (".", (39, 40))]
你可以组合任意的 PreTokenizer 到一起。 例如, 这里有一个 pre-tokenizer, 它将按空格、标点符号和数字进行分割。
1
2
3
4
5
6
from tokenizers import pre_tokenizers
from tokenizers.pre_tokenizers import Digits
pre_tokenizer = pre_tokenizers.Sequence([Whitespace(), Digits(individual_digits=True)])
pre_tokenizer.pre_tokenize_str("Call 911!")
# [("Call", (0, 4)), ("9", (5, 6)), ("1", (6, 7)), ("1", (7, 8)), ("!", (8, 9))]
就像我们在 Quicktour 看到的, 你可以通过改变对应的 attribute 定制化一个 Tokenizer 的 pre-tokenizer。
1
tokenizer.pre_tokenizer = pre_tokenizer
当然, 如果你更换了一个 tokenizer 的 pre-tokenizer, 你应该从头训练 tokenizer。
ByteLevel
在将所有字节重新映射到一组可见字符,按空格分割。由OpenAI GPT-2引入, 它有以下优势:
- 因为它是在字节上映射的,所以使用它的 tokenizer 只需要256个字符作为初始字母(一个字节可以拥有的值的数量),而不是13万多个Unicode字符。
- 没有必要使用
UNKtoken, 因为我们可以用 256 个 tokens 表达任何东西。 - 对于完全不可读的非 ascii 字符, 它依然可以工作。
Input: "Hello my friend, how are you?"
Ouput: "Hello", "Ġmy", Ġfriend", ",", "Ġhow", "Ġare", "Ġyou", "?"
- Whitespace: 按词的边界做分割
- WhitespaceSplit: 在所有空格字符上分割
- Punctuation: 分离所有的标点符号
- Metaspace: 按空格分割, 并将空格替换为特殊字符 “
_” (U+2581) - Digits: 将数字从其他字符中分割出来
- Split:通用的 pre-tokenizer
- Sequence: 对
PreTokenizer做组合
The Model
一旦输入文本完成了 normalize 和 pre-tokenize, Tokenizer 在 pre-tokens 上使用 mdoel。 这是你的语料库中需要训练的部分。
model 的作用是使用它学到的规则,将你的单词分解成 tokens。它还负责将这些 tokens 映射到模型词汇表对应的IDs。
model 在初始化 Tokenizer 时被传递,因此您应该已经知道如何自定义这个部分。
- BPE
- Unigram
- WordLevel
- WordPiece
WordLevel
这是经典的tokenization算法。 它允许您简单地将单词映射到id,而不需要任何花哨的东西。这种方法的优点是使用和理解非常简单,但是它需要非常大的词汇表来实现良好的覆盖。使用这个 Model 需要使用 PreTokenizer。
BPE
最受欢迎的 subword tokenization 算法之一。 Byte-Pair-Encoding 由 characters 开始, 将最频繁一起出现的 characters 拼在一起, 创建出新的 tokens。 它然后迭代地创建新的tokens。BPE能够通过使用多个 subword tokens 来构建它从未见过的单词,因此需要更小的词汇表,拥有unk(unknown) tokens 的机会更小。
WordPiece
这是一个和 BPE 非常相似的 subword tokenization 算法, 通常由 Google 使用, 比如 BERT。 它使用一种贪婪算法, 尝试先构建一个长的 words, 当整个 words 不存在词汇表时, 将它拆分为多个 tokens。 它不同于 BPE 从 characers 开始, 尽可能地创建大的 tokens。 它使用著名的 ## 前缀, 确定 tokens 是一个 word 的一部分。
Unigram
Unigram 也是一个 subword tokenization 算法, 通过尝试识别最佳 subword tokens 集来最大化给定句子的可能性。这与BPE的不同之处在于,它不是基于一组顺序应用的规则而确定的。相反,Unigram将能够计算多种tokenizing 方式,同时选择最可能的一种。
Post-Processing
Post-processing 是 Tokenization pipeline 的最后一步, 在 Encoding 返回之前执行一个额外的变换, 比如增加特殊的 tokens。
如我们在 quik tour 所见, 我们可以通过设定相关的 attribute 定制化一个 Tokenizer 的 post processor。
1
2
3
4
5
6
7
from tokenizers.processors import TemplateProcessing
tokenizer.post_processor = TemplateProcessing(
single="[CLS] $A [SEP]",
pair="[CLS] $A [SEP] $B:1 [SEP]:1",
special_tokens=[("[CLS]", 1), ("[SEP]", 2)],
)
与 pre-tokenizer 和 normalizer 不同的是, 你在修改 post-processor 后, 不需要重新训练一个 tokenizer。
在整个 pipeline 之后, 我们有时在一个 tokenized string 送入模型之前 想要插入 一些特殊的 tokens, 比如 [CLS] My horse is amazing [SEP]。 PostProcessor 负责完成这件事。
TemplateProcessing 让你很容易地模板化post processing, 增加 special tokens, 和为每个 sequence/special token 指定 type_id。 模板提供了两个字符串,分别代表单个序列和序列对,以及一组要使用的特殊 tokens。
- single:
"[CLS] $A [SEP]" - pair:
"[CLS] $A [SEP] $B [SEP]" - special tokens:
-
"[CLS]"
-
"[SEP]"
Input: ("I like this", "but not this")
Output: "[CLS] I like this [SEP] but not this [SEP]"
All together: a BERT tokenizer from scratch
让我们将它们放在一起构造一个 BERT tokenizer。 首先, BERT 依赖于 WordPiece, 因此我们使用这个 model 实例化一个新的 Tokenizer:
1
2
3
4
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
bert_tokenizer = Tokenizer(WordPiece(unk_token="[UNK]"))
然后BERT 通过 removing accents 和 lowercasing 预处理文本。 我们使用一个 unicode normalizer:
1
2
3
4
from tokenizers import normalizers
from tokenizers.normalizers import Lowercase, NFD, StripAccents
bert_tokenizer.normalizer = normalizers.Sequence([NFD(), Lowercase(), StripAccents()])
pre-tokenizer 通过 whitespace 和 punctuation 拆分:
1
2
3
from tokenizers.pre_tokenizers import Whitespace
bert_tokenizer.pre_tokenizer = Whitespace()
使用我们之前见到的模板 post-processing:
1
2
3
4
5
6
7
8
9
10
from tokenizers.processors import TemplateProcessing
bert_tokenizer.post_processor = TemplateProcessing(
single="[CLS] $A [SEP]",
pair="[CLS] $A [SEP] $B:1 [SEP]:1",
special_tokens=[
("[CLS]", 1),
("[SEP]", 2),
],
)
如我们在 Quicktour 所见训练 tokenizer:
1
2
3
4
5
6
7
8
9
from tokenizers.trainers import WordPieceTrainer
trainer = WordPieceTrainer(
vocab_size=30522, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"]
)
files = [f"data/wikitext-103-raw/wiki.{split}.raw" for split in ["test", "train", "valid"]]
bert_tokenizer.train(files, trainer)
bert_tokenizer.save("data/bert-wiki.json")
Decoding
上面是编码输入文本, Tokenizer 也需要一个API解码, 它将 IDs 转换会 文本。 这由方法 decode() 和 decode_batch() 实现。
decoder 将会首先将 IDs 映射回 tokens 并且 移除掉所有的 special tokens, 然后使用空格拼接这些tokens:
1
2
3
4
5
6
output = tokenizer.encode("Hello, y'all! How are you 😁 ?")
print(output.ids)
# [1, 27253, 16, 93, 11, 5097, 5, 7961, 5112, 6218, 0, 35, 2]
tokenizer.decode([1, 27253, 16, 93, 11, 5097, 5, 7961, 5112, 6218, 0, 35, 2])
# "Hello , y ' all ! How are you ?"
如果你使用增加特殊 characters 来表示 给定 word 的 subtokens 的 model(想 WordPiece 中的 ##), 你需要定制化 decoder 合理地处理它们。 如果我们使用我们之前的 bert_tokenizer , 默认解码如下:
1
2
3
4
5
6
output = bert_tokenizer.encode("Welcome to the 🤗 Tokenizers library.")
print(output.tokens)
# ["[CLS]", "welcome", "to", "the", "[UNK]", "tok", "##eni", "##zer", "##s", "library", ".", "[SEP]"]
bert_tokenizer.decode(output.ids)
# "welcome to the tok ##eni ##zer ##s library ."
通过改变它为一个合适的decoder, 我们得到:
1
2
3
4
5
from tokenizers import decoders
bert_tokenizer.decoder = decoders.WordPiece()
bert_tokenizer.decode(output.ids)
# "welcome to the tokenizers library."
Using Tokenizers
在 Quicktour 中, 我们看到了使用文本文件如何构造和训练一个 tokenizer, 实际上我们可以使用任意的 python 迭代器。
下面的例子,我们将使用相同的 Tokenizer 和 Trainer, 构造如下:
1
2
3
4
5
6
7
8
9
10
11
12
from tokenizers import Tokenizer, models, normalizers, pre_tokenizers, decoders, trainers
tokenizer = Tokenizer(models.Unigram())
tokenizer.normalizer = normalizers.NFKC()
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel()
tokenizer.decoders = decoders.ByteLevel()
trainer = trainers.UnigramTrainer(
vocab_size=20000,
initial_alphabet=pre_tokenizers.ByteLevel.alphabet(),
special_tokens=["<PAD>", "<BOS>", "<EOS>"],
)
这个 tokenizer 基于 Unigram 模型。 它使用 NFKC Unicode normalization 方法规范化输入, 并且使用 ByteLevel pre-tokenizer 作为相应的解码器。
The most basic way
最简单的方法是使用一个 List:
1
2
3
4
5
6
7
8
9
10
11
# First few lines of the "Zen of Python" https://www.python.org/dev/peps/pep-0020/
data = [
"Beautiful is better than ugly."
"Explicit is better than implicit."
"Simple is better than complex."
"Complex is better than complicated."
"Flat is better than nested."
"Sparse is better than dense."
"Readability counts."
]
tokenizer.train_from_iterator(data, trainer=trainer)
也可以使用 List、Tuple 或者 np.,array。
Using the Datasets library
使用 huggingface 的 datasets 库
1
2
3
4
5
import datasets
dataset = datasets.load_dataset(
"wikitext", "wikitext-103-raw-v1", split="train+test+validation"
)
下一步是在此数据集上构造迭代器:
1
2
3
def batch_iterator(batch_size=1000):
for i in range(0, len(dataset), batch_size):
yield dataset[i : i + batch_size]["text"]
为了提高效率,我们实际上可以提供一批用于训练的样本,而不是逐个迭代它们。通过这样做,我们可以期望得到与直接从文件中训练时非常相似的性能。
迭代器好了之后, 我们需要的近视开始训练。 为了使进度条更好看, 我们可以指定数据集的长度:
1
tokenizer.train_from_iterator(batch_iterator(), trainer=trainer, length=len(dataset))
Using gzip files
因为Python中的gzip文件可以用作迭代器,所以训练这些文件非常简单:
1
2
3
4
import gzip
with gzip.open("data/my-file.0.gz", "rt") as f:
tokenizer.train_from_iterator(f, trainer=trainer)
如果我们想要训练 gzip 文件, 会稍微复杂一点:
1
2
3
4
5
6
7
8
9
files = ["data/my-file.0.gz", "data/my-file.1.gz", "data/my-file.2.gz"]
def gzip_iterator():
for path in files:
with gzip.open(path, "rt") as f:
for line in f:
yield line
tokenizer.train_from_iterator(gzip_iterator(), trainer=trainer)
GET STARTED
安装
1
pip install transformers