我们在第9.7节中研究了机器翻译问题,在该节中,我们设计了一个基于两个 RNNs 的 encoder-decoder 体系结构,用于序列到序列学习。具体来说,RNN encoder将一个变长序列转换成一个固定形状的上下文变量,然后RNN encoder根据生成的 tokens 和上下文变量,一个一个地生成输出(目标)序列 tokens。然而,即使 不是所有的输入(源) tokens 都对解码某个 token 有用,在每个解码步骤中仍然使用相同的编码了整个输入序列的上下文变量。
Bahdanau等人提出了一种可微分注意力模型[Bahdanau等人,2014]。在预测一个 token 时,如果不是所有的输入 tokens 都是相关的,那么模型只会对齐(或参加)与当前预测相关的输入序列部分。这是通过将上下文变量作为注意力池化的输出来实现的。
Model
在描述下面关于RNN encoder-decoder 的 badanau attention 时,我们将遵循9.7节中的相同符号。新的基于注意力的模型与第9.7节中相同,只是(9.7.3)中的上下文变量 $c$ 在所有解码时间步 $t’$ 被 $c_{t’}$替换。假设输入序列中有 $T$ tokens,解码时间步 $t$ 处的上下文变量是注意力池化的输出:
\[c_{t'} = \sum_{t=1}^T \alpha(s_{t' - 1}, h_t) h_t \tag{10.4.1}\]其中decoder在时间步 $t’ - 1$ 的隐藏状态 $s_{t’ -1}$ 是 query,encoder隐藏状态 $h_t$ 同时是 key 和 value, 以及(10.3.2)中的注意力权重 $\alpha$ 是 使用 (10.3.3)的additive attention scoring function。
与图9.7.2中的普通 RNN encoder-decoder 结构稍有不同的是,图10.4.1所示的结构具有Bahdanau attention。
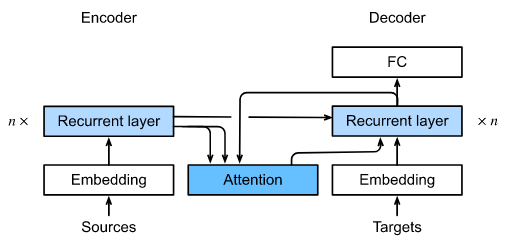
Fig. 10.4.1 带有 Bahdanau attention 的 RNN encoder-decoder 模型的层
1
2
3
import torch
from torch import nn
from d2l import torch as d2l
Defining the Decoder with Attention
为了实现具有badanau注意力的RNN encoder-decoder,我们只需要重新定义 decoder。为了更方便地可视化学习到的注意力权重,下面的AttentionDecoder类定义了具有注意力机制的 decoder 的基本接口。
1
2
3
4
5
6
7
8
class AttentionDecoder(d2l.Decoder):
"""The base attention-based decoder interface."""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError
现在让我们在下面的Seq2SeqAttentionDecoder类中实现带有 badanau注意力 的RNN decoder。 decoder 的状态初始化使用 i) encoder最后一层 所有时间步的隐藏状态(作为注意力的 key 和 value) ii) encoder 在最后一个时间步 的所有层的隐藏状态(初始化decoder的隐藏状态) iii) encoder 的有效长度(在注意力池化中, 用于排除填充标记)。在每一个解码时间步,使用前一个时间步 deocder 的最后一层隐藏状态作为注意力的query。最后,注意力输出和输入embeddings concatenate起来 作为RNN decoder 的输入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
"""
args:
outputs : shape(num_steps, batch_size, num_hiddens), enc 最后一层所有时间步的输出
hidden_state : enc 每层最后一个时间步的输出
return:
outputs : shape(batch_size, num_steps, num_hiddens)
hidden_state : enc 每层最后一个时间步的输出
enc_valid_lens : enc 的有效长度
"""
# Shape of `outputs`: (`num_steps`, `batch_size`, `num_hiddens`).
# Shape of `hidden_state[0]`: (`num_layers`, `batch_size`, `num_hiddens`)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
"""
args:
X: shape(batch, steps)
state: (outputs, hidden_state, enc_valid_lens)
return:
outputs : shape(batch_size, num_steps, vocab_size)
enc_outputs : enc的输出
hidden_state : dec 每层最后一个时间步的输出
enc_valid_lens : enc 有效长度
"""
# Shape of `enc_outputs`: (`batch_size`, `num_steps`, `num_hiddens`).
# Shape of `hidden_state[0]`: (`num_layers`, `batch_size`, `num_hiddens`)
enc_outputs, hidden_state, enc_valid_lens = state
# Shape of the output `X`: (`num_steps`, `batch_size`, `embed_size`)
# X.shape: (steps, batch, embedding)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
# 每个时间步
for x in X:
# Shape of `query`: (`batch_size`, 1, `num_hiddens`)
# 最后一层最后一个时间步的输出作为query
query = torch.unsqueeze(hidden_state[-1], dim=1)
# Shape of `context`: (`batch_size`, 1, `num_hiddens`)
context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)
# Concatenate on the feature dimension
# 每个时间步的输入 和 Attention 池化后的 enc 输出拼接
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# Reshape `x` as (1, `batch_size`, `embed_size` + `num_hiddens`)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# After fully-connected layer transformation, shape of `outputs`: (`num_steps`, `batch_size`, `vocab_size`)
# 在 时间步维 拼接起来outputs
# 全连接层输出每个词的概率
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state, enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
接下来,我们使用一个包含 4个序列输入, 7个时间步长的 minibatch 测试 实现的具有badanau注意力的decoder。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (`batch_size`, `num_steps`)
# state: (outputs, hidden_state, valid_len)
# outputs.shape: (4, 7, 16)
# hidden_state.shape: (2, 4, 16)
state = decoder.init_state(encoder(X), None)
# output.shape: (4, 7, 10)
# enc_outputs
# hidden_state(dec): (2, 4, 16)
# valid_len
output, state = decoder(X, state)
print(output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape)
输出:
1
(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([4, 16]))
Training
与9.7.4节类似,这里我们指定了超参数,实例化一个encoder和一个decoder,并训练这个模型进行机器翻译。由于新增加了注意力机制,这次的训练比9.7.4章节中没有注意力机制的训练要慢得多。
1
2
3
4
5
6
7
8
9
10
11
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens,
num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(len(tgt_vocab), embed_size, num_hiddens,
num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
输出
1
loss 0.019, 4516.7 tokens/sec on cuda:0
训练完模型后,我们用它将几个英语句子翻译成法语,并计算它们的BLEU分数。
1
2
3
4
5
6
7
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
输出:
1
2
3
4
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est riche ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
1
2
3
attention_weights = torch.cat(
[step[0][0][0] for step in dec_attention_weight_seq], 0).reshape(
(1, 1, -1, num_steps))
通过可视化翻译最后一个英语句子时的注意力权重,我们可以看到每个 query 在 key-value 对上分配了非均匀的权重。结果表明,在每个解码步骤中,输入序列的不同部分被选择性地聚集在注意力池化中。
1
2
3
4
# Plus one to include the end-of-sequence token
d2l.show_heatmaps(
attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),
xlabel='Key positions', ylabel='Query positions')

Summary
- 当预测一个 token 时,如果不是所有的输入 token 都是相关的,具有badanau注意力的RNN encoder-decoder会选择性地聚合输入序列的不同部分。这是通过将加性注意力池化的输出作为上下文变量来实现的。
- 在RNN encoder-decoder中,badanau attention将上一个时间步的decoder隐藏状态作为query,将所有时间步的encoder隐藏状态同时作为 key 和 value。
Exercises
- 将实验中的GRU替换成LSTM。
- 修改实验,以 scaled dot-product 代替 additive attention 评分函数。它如何影响训练效率?