PaddlePaddle
安装
cuda 11.0 paddlepaddle 2.0.2 稳定版本
1
python -m pip install paddlepaddle-gpu==2.0.2.post110 -f https://paddlepaddle.org.cn/whl/mkl/stable.html
PaddleHub
PaddleDetection
VisualDL可视化
1
python -u tools/train.py -c configs/yolov3_mobilenet_v1_fruit.yml --use_vdl=True -- vdl_log_dir=vdl_fruit_dir/scalar --eval
- 启动命令添加–use_vdl=True
- 通过 –vdl_log_dir 设置日志保存路径
过visualdl命令实时查看变化曲线:
1
visualdl --logdir vdl_dir/scalar/ --host 127.0.0.1 --port 6006
一键式训练、评估、预测
1
python slim/prune/prune.py -c ./configs/yolov3_mobilenet_v1_voc.yml --pruned_params "yolo_block.0.0.0conv.weights" --pruned_ratios="0.2"
导出模型
1
python slim/prune/export_model.py -c ./configs/yolov3_mobilenet_v1_voc.yml --pruned_params "yolo_block.0.0.0conv.weights" --pruned_ratios="0.2" -o weights=output/yolov3_mobilenet_v1_voc/model_final
模型参数配置
基本设计
利用Python的反射机制,PaddleDection的配置系统从Python类的构造函数抽取多种信息 - 如参数名、初始值、参数注释、数据类型(如果给出type hint)- 来作为配置规则。 这种设计便于设计的模块化,提升可测试性及扩展性。
API
配置系统的大多数功能由 ppdet.core.workspace 模块提供
register: 装饰器,将类注册为可配置模块;能够识别类定义中的一些特殊标注。-
__category__: 为便于组织,模块可以分为不同类别。
-
__inject__: 如果模块由多个子模块组成,可以这些子模块实例作为构造函数的参数注入。对应的默认值及配置项可以是类名字符串,yaml序列化的对象,指向序列化对象的配置键值或者Python dict(构造函数需要对其作出处理,参见下面的例子)。
-
__op__: 配合__append_doc__(抽取目标OP的 注释)使用,可以方便快速的封装PaddlePaddle底层OP。
serializable: 装饰器,利用 pyyaml 的序列化机制,可以直接将一个类实例序列化及反序列化。create: 根据全局配置构造一个模块实例。load_configandmerge_config: 加载yaml文件,合并命令行提供的配置项。
示例
以 RPNHead 模块为例,该模块包含多个PaddlePaddle OP,先将这些OP封装成类,并将其实例在构造 RPNHead 时注入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# excerpt from `ppdet/modeling/ops.py`
from ppdet.core.workspace import register, serializable
# ... more operators
@register
@serializable
class GenerateProposals(object):
# NOTE this class simply wraps a PaddlePaddle operator
__op__ = fluid.layers.generate_proposals
# NOTE docstring for args are extracted from PaddlePaddle OP
__append_doc__ = True
def __init__(self,
pre_nms_top_n=6000,
post_nms_top_n=1000,
nms_thresh=.5,
min_size=.1,
eta=1.):
super(GenerateProposals, self).__init__()
self.pre_nms_top_n = pre_nms_top_n
self.post_nms_top_n = post_nms_top_n
self.nms_thresh = nms_thresh
self.min_size = min_size
self.eta = eta
# ... more operators
# excerpt from `ppdet/modeling/anchor_heads/rpn_head.py`
from ppdet.core.workspace import register
from ppdet.modeling.ops import AnchorGenerator, RPNTargetAssign, GenerateProposals
@register
class RPNHead(object):
"""
RPN Head
Args:
anchor_generator (object): `AnchorGenerator` instance
rpn_target_assign (object): `RPNTargetAssign` instance
train_proposal (object): `GenerateProposals` instance for training
test_proposal (object): `GenerateProposals` instance for testing
"""
__inject__ = [
'anchor_generator', 'rpn_target_assign', 'train_proposal',
'test_proposal'
]
def __init__(self,
anchor_generator=AnchorGenerator().__dict__,
rpn_target_assign=RPNTargetAssign().__dict__,
train_proposal=GenerateProposals(12000, 2000).__dict__,
test_proposal=GenerateProposals().__dict__):
super(RPNHead, self).__init__()
self.anchor_generator = anchor_generator
self.rpn_target_assign = rpn_target_assign
self.train_proposal = train_proposal
self.test_proposal = test_proposal
if isinstance(anchor_generator, dict):
self.anchor_generator = AnchorGenerator(**anchor_generator)
if isinstance(rpn_target_assign, dict):
self.rpn_target_assign = RPNTargetAssign(**rpn_target_assign)
if isinstance(train_proposal, dict):
self.train_proposal = GenerateProposals(**train_proposal)
if isinstance(test_proposal, dict):
self.test_proposal = GenerateProposals(**test_proposal)
对应的yaml配置如下,请注意这里给出的是 完整 配置,其中所有默认值配置项都可以省略。上面的例子中的模块所有的构造函数参数都提供了默认值,因此配置文件中可以完全略过其配置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
RPNHead:
test_proposal:
eta: 1.0
min_size: 0.1
nms_thresh: 0.5
post_nms_top_n: 1000
pre_nms_top_n: 6000
train_proposal:
eta: 1.0
min_size: 0.1
nms_thresh: 0.5
post_nms_top_n: 2000
pre_nms_top_n: 12000
anchor_generator:
# ...
rpn_target_assign:
# ...
RPNHead 模块实际使用代码示例。
1
2
3
4
5
6
7
from ppdet.core.workspace import load_config, merge_config, create
load_config('some_config_file.yml')
merge_config(more_config_options_from_command_line)
rpn_head = create('RPNHead')
# ... code that use the created module!
配置文件用可以直接序列化模块实例,用 ! 标示,如
1
2
3
4
5
6
7
8
9
LearningRate:
base_lr: 0.01
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones: [60000, 80000]
- !LinearWarmup
start_factor: 0.3333333333333333
steps: 500
相关工具
为了方便用户配置,PaddleDection提供了一个工具 (tools/configure.py), 共支持四个子命令:
list: 列出当前已注册的模块,如需列出具体类别的模块,可以使用--category指定。help: 显示指定模块的帮助信息,如描述,配置项,配置文件模板及命令行示例。analyze:检查配置文件中的缺少或者多余的配置项以及依赖缺失,如果给出type hint, 还可以检查配置项中错误的数据类型。非默认配置也会高亮显示。generate: 根据给出的模块列表生成配置文件,默认生成完整配置,如果指定--minimal,生成最小配置,即省略所有默认配置项。例如,执行下列命令可以生成Faster R-CNN (ResNetbackbone +FPN) 架构的配置文件:
1
ython tools/configure.py generate FasterRCNN ResNet RPNHead RoIAlign BBoxAssigner BBoxHead LearningRate OptimizerBuilder
如需最小配置,运行:
1
python tools/configure.py generate --minimal FasterRCNN BBoxHead
新增模型算法
PaddleDetection的网络模型模块所有代码逻辑在ppdet/modeling/中,所有网络模型是以组件的形式进行定义与组合,网络模型模块的主要构成如下架构所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
ppdet/modeling/
├── architectures #
│ ├── faster_rcnn.py # Faster Rcnn模型
│ ├── ssd.py # SSD模型
│ ├── yolov3.py # YOLOv3模型
│ │ ...
├── anchor_heads # anchor生成检测头模块
│ ├── xxx_head.py # 定义各类anchor生成检测头
├── backbones # 基干网络模块
│ ├── resnet.py # ResNet网络
│ ├── mobilenet.py # MobileNet网络
│ │ ...
├── losses # 损失函数模块
│ ├── xxx_loss.py # 定义注册各类loss函数
├── roi_extractors # 检测感兴趣区域提取
│ ├── roi_extractor.py # FPNRoIAlign等实现
├── roi_heads # 两阶段检测器检测头
│ ├── bbox_head.py # Faster-Rcnn系列检测头
│ ├── cascade_head.py # cascade-Rcnn系列检测头
│ ├── mask_head.py # Mask-Rcnn系列检测头
├── tests # 单元测试模块
│ ├── test_architectures.py # 对网络结构进行单元测试
├── ops.py # 封装及注册各类PaddlePaddle物体检测相关公共检测组件/算子
├── target_assigners.py # 封装bbox/mask等最终结果的公共检测组件
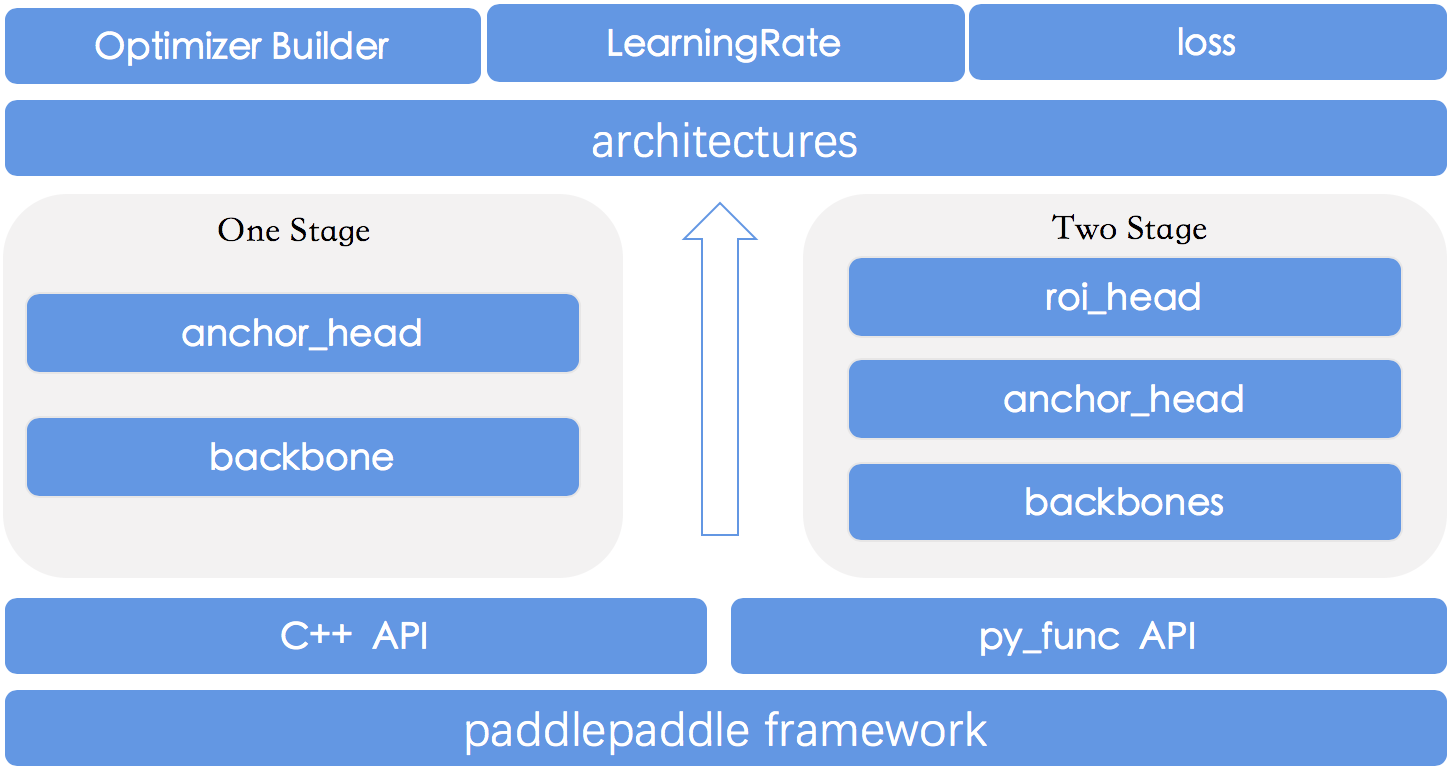
新增模型
搭建新模型的一般步骤是:Backbone编写、检测组件编写与模型组网这三个步骤
Backbone编写
1) 代码编写: PaddleDetection中现有所有Backbone网络代码都放置在ppdet/modeling/backbones目录下,所以我们在其中新建darknet.py如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from ppdet.core.workspace import register
@register
class DarkNet(object):
__shared__ = ['norm_type', 'weight_prefix_name']
def __init__(self,
depth=53,
norm_type='bn',
norm_decay=0.,
weight_prefix_name=''):
# 省略内容
pass
def __call__(self, input):
# 省略处理逻辑
pass
然后在backbones/__init__.py中加入引用:
1
2
from . import darknet
from .darknet import *
几点说明:
- 为了在yaml配置文件中灵活配置网络,所有Backbone、模型组件与architecture类需要利用
ppdet.core.workspace里的register进行注册,形式请参考如上示例; - 在Backbone中都需定义
__init__函数与__call__函数,__init__函数负责初始化参数,在调用此Backbone时会执行__call__函数; __shared__为了实现一些参数的配置全局共享,具体细节请参考配置文件说明文档。
2) 配置编写: 在yaml文件中以注册好了的 DarkNet 类名为标题,可选择性的对 __init__ 函数中的参数进行更新,不在配置文件中配置的参数会保持__init__函数中的初始化值:
1
2
3
4
DarkNet:
norm_type: sync_bn
norm_decay: 0.
depth: 53
检测组件编写
1) 代码编写:编写好Backbone后,我们开始编写生成anchor的检测头部分,anchor的检测头代码都在 ppdet/modeling/anchor_heads 目录下,所以我们在其中新建yolo_head.py 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from ppdet.core.workspace import register
@register
class YOLOv3Head(object):
__inject__ = ['yolo_loss', 'nms']
__shared__ = ['num_classes', 'weight_prefix_name']
def __init__(self,
num_classes=80,
anchors=[[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]],
yolo_loss="YOLOv3Loss",
nms=MultiClassNMS(
score_threshold=0.01,
nms_top_k=1000,
keep_top_k=100,
nms_threshold=0.45,
background_label=-1).__dict__):
# 省略部分内容
pass
然后在 anchor_heads/__init__.py 中加入引用:
1
2
from . import yolo_head
from .yolo_head import *
几点说明:
__inject__表示引入封装好了的检测组件/算子列表,此处yolo_loss与nms变量指向外部定义好的检测组件/算子;- anchor 的检测头实现中类函数需有输出loss接口
get_loss与预测框或建议框输出接口get_prediction; - 两阶段检测器在anchor的检测头里定义的是候选框输出接口
get_proposals,之后还会在roi_extractors与roi_heads中进行后续计算,定义方法与如下一致。 - YOLOv3算法的loss函数比较复杂,所以我们将loss函数进行拆分,具体实现在
losses/yolo_loss.py中,也需要注册; - nms算法是封装paddlepaddle中现有检测组件/算子,如何定义与注册详见定义公共检测组件/算子部分。
模型组网
1)代码编写: 本步骤中,我们需要将编写好的Backbone、各个检测组件进行整合拼接,搭建一个完整的物体检测网络能够提供给训练、评估和测试程序去运行。 1.组建 architecture: 所有architecture网络代码都放置在 ppdet/modeling/architectures 目录下,所以我们在其中新建 yolov3.py 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
from ppdet.core.workspace import register
@register
class YOLOv3(object):
__category__ = 'architecture'
__inject__ = ['backbone', 'yolo_head']
__shared__ = ['use_fine_grained_loss']
def __init__(self,
backbone,
yolo_head='YOLOv3Head',
use_fine_grained_loss=False):
super(YOLOv3, self).__init__()
# 省略内容
def build(self, feed_vars, mode='train'):
# 省略内容
pass
def build_inputs(self, ):
# 详解见【模型输入设置】章节
pass
def train(self, feed_vars):
return self.build(feed_vars, mode='train')
def eval(self, feed_vars):
return self.build(feed_vars, mode='test')
def test(self, feed_vars):
return self.build(feed_vars, mode='test')
几点说明:
- 在组建一个完整的网络时必须要设定
__category__ = 'architecture'来表示一个完整的物体检测模型; - 在
__init__函数中传入我们上面定义好的backbone与yolo_head的名称即可,根据yaml配置文件里这些组件的参数初始化,ppdet.core.workspace会自动解析加载; - 在architecture类里必须定义
build_inputs函数,为了适配检测网络的输入与Reader模块,具体见模型输入设置模块; - 在architecture类里必须定义
train、eval和test函数,在训练、评估和测试程序中会分别调用这三个函数来在不同场景中加载网络模型。
2) 配置编写:
首先定义网络模型名称:
1
architecture: YOLOv3
接下来根据网络模型名称 YOLOv3 来初始化网络组件名称:
1
2
3
YOLOv3:
backbone: DarkNet
yolo_head: YOLOv3Head
之后 backbone 、yolo_head 的配置步骤在上面已经介绍,完成如上配置就完成了物体检测模型组网的工作。
模型输入设置
在architecture定义的类里必须含有 build_inputs 函数,这个函数的作用是生成feed_vars 和 loader。
1) feed_vars 是由 key:fluid.data 构成的字典,key是由如下yaml文件中 fields 字段构成,在不同数据集、训练、评估和测试中字段不尽相同, 在使用中需要合理组合。
1
2
3
4
5
6
7
8
TrainReader:
inputs_def:
fields: ['image', 'gt_bbox', 'gt_class', 'gt_score']
EvalReader:
inputs_def:
fields: ['image', 'im_size', 'im_id']
...
在数据源解析中已经提到,数据源roidbs会解析为字典的形式,Reader会根据feed_vars所含字段进行解析适配。
2) loader 是调用 fluid.io.DataLoader 根据 feed_vars 来完成DataLoader的组建。
配置及运行
PaddleDetection在 ppdet/optimizer.py 中注册实现了学习率配置接口类LearningRate、优化器接口类 OptimizerBuilder。
- 学习率配置 在yaml文件中可便捷配置学习率各个参数:
1
2
3
4
5
6
7
8
9
10
11
LearningRate:
base_lr: 0.001
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones:
- 400000
- 450000
- !LinearWarmup
start_factor: 0.
steps: 4000
几点说明:
PiecewiseDecay与LinearWarmup策略在ppdet/optimizer.py中都已注册。- 除了这两个优化器之外,您还可以使用paddlepaddle中所有的优化器paddlepaddle官网文档。
- Optimizer优化器配置:
1
2
3
4
5
6
7
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.0005
type: L2
- 其他配置:在训练、评估与测试阶段,定义了一些所需参数如下:
1
2
3
4
5
6
7
8
9
use_gpu: true # 是否使用GPU运行程序
max_iters: 500200 # 最大迭代轮数
log_iter: 20 # 日志打印队列长度, 训练时日志每迭代x轮打印一次
save_dir: output # 模型保存路径
snapshot_iter: 2000 # 训练时第x轮保存/评估
metric: COCO # 数据集名称
pretrain_weights: xxx # 预训练模型地址(网址/路径)
weights: xxx/model_final # 评估或测试时模型权重的路径
num_classes: 80 # 类别数
PaddleX
安装
1
pip install paddlex -i https://mirror.baidu.com/pypi/simple
数据标注、转换、划分
格式转换
LabelMe标注后的数据还需要进行转换为PascalVOC或MSCOCO格式,才可以用于目标检测任务的训练,创建D:\dataset_voc目录,在python环境中安装paddlex后,使用如下命令即可
1
2
3
4
paddlex --data_conversion --source labelme --to PascalVOC \
--pics D:\MyDataset\JPEGImages \
--annotations D:\MyDataset\Annotations \
--save_dir D:\dataset_voc
数据集划分
转换完数据后,为了进行训练,还需要将数据划分为训练集、验证集和测试集,同样在安装paddlex后,使用如下命令即可将数据划分为70%训练集,20%验证集和10%的测试集
1
paddlex --split_dataset --format VOC --dataset_dir D:\MyDataset --val_value 0.2 --test_value 0.1
执行上面命令行,会在D:\MyDataset下生成labels.txt, train_list.txt, val_list.txt和test_list.txt,分别存储类别信息,训练样本列表,验证样本列表,测试样本列表