在深度学习中,我们经常使用CNNs或RNNs来编码序列。现在有了注意力机制。 假设我们将一系列 tokens 输入注意力池化中,这样同一组tokens就可以充当queries、keys和values。具体来说,每个query关注所有key-value对,并生成一个注意力输出。由于queries、keys和values来自相同的位置,这将实现 self-attention [[Lin et al., 2017b][Vaswani et al., 2017], 也叫做 intra-attention [Cheng et al., 2016][Parikh et al., 2016][Paulus et al., 2017]。 在本节中,我们将讨论使用self-attention的序列编码,包括为了保留序列顺序关系 使用额外的信息。
1
2
3
4
import math
import torch
from torch import nn
from d2l import torch as d2l
Self-Attention
给定一个输入 tokens 序列 $x_1, …, x_n$, 其中所有的 $x_i \in \mathbb{R}^d(1 \leq i \leq n)$, 它的self-attention输出一个相同长度的序列 $y_1, …, y_n$, 其中:
\[y_i = f(x_i, (x_1, x_1), ..., (x_n, x_n) \in \mathbb{R}^d \tag{10.6.1}\]根据 (10.2.4) 中 注意力池化 $f$ 的定义。 使用 multi-head attention, 下面的代码片段计算一个形状为 (batch size, number of time steps or sequence length in tokens, d) 的张量的self-attention。输出张量具有相同的形状。
1
2
3
4
num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
输出:
1
2
3
4
5
6
7
8
(attention): DotProductAttention(
(dropout): Dropout(p=0.5, inplace=False)
)
(W_q): Linear(in_features=100, out_features=100, bias=False)
(W_k): Linear(in_features=100, out_features=100, bias=False)
(W_v): Linear(in_features=100, out_features=100, bias=False)
(W_o): Linear(in_features=100, out_features=100, bias=False)
)
1
2
3
4
5
batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
# X.shape: (2, 4, 100)
X = torch.ones((batch_size, num_queries, num_hiddens))
# (2, 4, 100) -> (10, 4, 20) -> (10, 4, 4) -> (2, 4, 100)
attention(X, X, X, valid_lens).shape
输出
1
torch.Size([2, 4, 100])
Comparing CNNs, RNNs, and Self-Attention
让我们比较将一个 $n$ token 序列映射到另一个等长序列的结构,其中每个输入或输出 token 都由一个 $d$ 维向量表示。我们将比较 CNNs, RNNs和self-attention。 我们将比较它们的计算复杂度、序列操作和最大路径长度。请注意,序列操作阻止并行计算,而所有序列位置组合之间的更短的路径使学习序列中的长期依赖关系更容易[Hochreiter et al., 2001]。
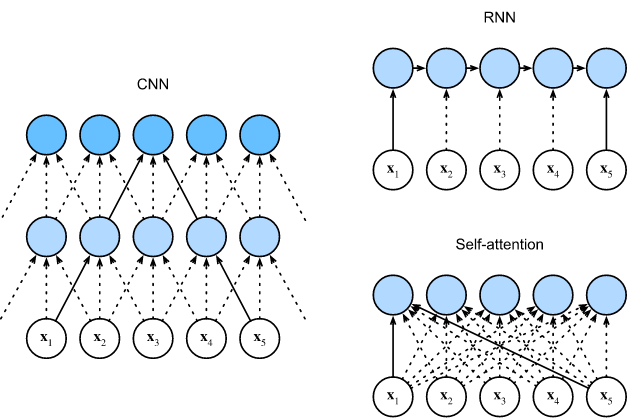
图 10.6.1 比较CNN(忽略paddding的tokens)、RNN和self-attention 结构。考虑一个卷积层,其卷积核大小为 $k$。 我们将在后面的章节中提供更多关于使用CNNs进行序列处理的细节。现在,我们只需要知道,因为序列长度是 $n$, 输入通道和输出通道的数量都是 $d$, 卷积层的计算复杂度为 $O(knd^2)$。如图10.6.1所示, CNNs是层级结构, 因此它的序列操作是 $O(1)$, 最大路径长度是 $O(n / k )$。 例如, 在图10.6.1中, $x_1$ 和 $x_5$在两层卷积核为3的CNN的感受野内。
当RNNs更新hidden state时, 多个 $d \times d$ 权重矩阵 和 $d$ 维 hidden state 的计算复杂度维 $O(d^2)$。 因为序列长度是 $n$, 循环层计算复杂度为 $O(nd^2)$。 根据图 10.6.1, $O(n)$的序列操作不能并行化, 并且最大路径长度也是 $O(n)$。
在 self-attention 中, queries,keys 和 values 都是 $n \times d$ 的矩阵。 考虑 10.3.5 中的 scaled dot-product attention, $n \times d$ 的矩阵 乘以 一个 $d \times n$ 的矩阵, 然后 输出 $n \times n$ 的矩阵, 它再乘以 一个 $n \times d$ 的矩阵。 因此, self-attention的计算复杂度为 $O(n^2d)$。如图 10.6.1, 每个token通过self-attention直接连接到其他的token。 因此计算可以 以$O(1)$序列操作并行化 并且 最大路径长度也是 $O(1)$。
总而言之,CNNs和self-attention都可以并行计算,且self-attention的最大路径长度最短。然而,关于序列长度的平方计算 的复杂度 使得self-attention对于非常长的序列非常慢。
Positional Encoding
与RNNs循环一个一个地处理序列 tokens 不同的是, self-attention避开了序列操作,而支持并行计算。为了使用序列顺序信息,我们可以通过向输入表示添加位置编码插入绝对位置或相对位置信息。位置编码可以是学习的,也可以是固定的。下面,我们描述了一种基于正弦和余弦函数的固定的位置编码[Vaswani等人,2017]。
假设输入表征 $R \in \mathbb{R}^{n \times d}$ 对于一个序列的$n$个tokens 包含 $d$ 维的 embeddings。 位置编码输出 $X + P$ 使用一个相同形状的 positional embedding 矩阵 $P \in \mathbb{R}^{n \times d}$, 它在第 $i^{th}$ 行 和 第 $(2j)^{th}$ 或 第 $(2j + 1)^th$ 列的元素为:
\[P_{i, 2j} = \sin(\frac{i}{10000^{2j / d}}) \\ P_{i, 2j + 1} = \cos(\frac{i}{10000^{2j / d}}) \tag{10.6.2}\]乍一看,这个三角函数的设计看起来很奇怪。在解释这个设计之前,让我们先在下面的 PositionalEncoding 类中实现它。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class PositionalEncoding(nn.Module):
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# Create a long enough `P`
self.P = torch.zeros((1, max_len, num_hiddens))
# 对 时间步 进行编码, 也就是位置编码。
# (max_len, ) -> (max_len, 1)
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(
10000,
torch.arange(0, num_hiddens, 2, dtype=torch.float32) /
num_hiddens)
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
"""
args:
X : (batch_size, num_steps, encoding_dim)
return:
X + P
"""
# 从 位置编码 中截取 X 的时间步的部分, 将位置信息加入embedding
X = X + self.P[:, :X.shape[1], :].to(X.device)
return self.dropout(X)
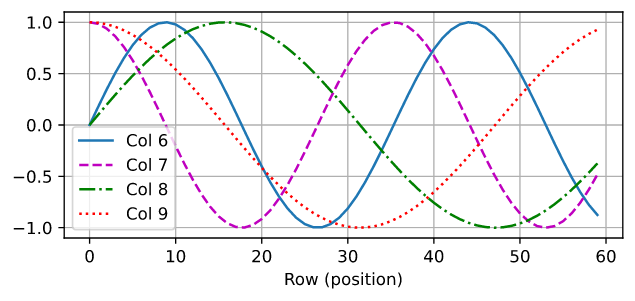
在 positional embedding 矩阵 $P$ 中, 行对应序列中的位置,列代表不同的位置编码维度。在下面的例子中, 我们可以看到 positional embedding 矩阵 的 第6 和 第7 列 比 第8 和 第9 列有更高的频率。 第6和第7列(第8和第9列也相同)的 偏差 是由于 sin 和 cos 函数的变化导致的。
1
2
3
4
5
6
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)', figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])
Absolute Positional Information
为了看出频率随着编码维度单调递增 和 绝对位置信息相关, 让我们打印出0, 1, …, 7的二进制表示。 正如我们所看到的,最低位,第二最低位,第三最低位分别在每一个数字,每两个数字,每四个数字上交替出现。
1
2
for i in range(8):
print(f'{i} in binary is {i:>03b}')
1
2
3
4
5
6
7
8
0 in binary is 000
1 in binary is 001
2 in binary is 010
3 in binary is 011
4 in binary is 100
5 in binary is 101
6 in binary is 110
7 in binary is 111
在二进制表示中,高位的频率比低位的频率低。类似地,如下面的热力图所示,位置编码通过使用三角函数沿编码维度降低频率。由于输出是浮点数,因此这种连续表示比二进制表示更节省空间。
1
2
3
P = P[0, :, :].unsqueeze(0).unsqueeze(0)
d2l.show_heatmaps(P, xlabel='Column (encoding dimension)',
ylabel='Row (position)', figsize=(3.5, 4), cmap='Blues')

Relative Positional Information
除了捕获绝对位置信息外,上述位置编码还允许模型容易地学习通过相对按相对位置参与。这是因为对于固定的位置偏差 $\delta$, 位置编码在位置 $i + \delta$ 可以用在位置 $i$ 的线性投影表示。
这个投影可以用数学来解释。表示 $\omega_j = 1/10000^{2j/d}$, 对于固定的偏差 $\delta$, (10.6.2)中的任意对$(p_{i, 2j}, p_{i, 2j+1})$ 可以被线性地投影到 $(p_{i + \delta, 2j}, p_{i+\delta, 2j+1})$:
\[\begin{aligned} & \begin{matrix} \left[\begin{array}{rr} \cos(\delta \omega_j) & \sin(\delta \omega_j) \\ -\sin(\delta \omega_j) & \cos(\delta \omega_j) \end{array}\right] \end{matrix} \begin{matrix} \left[\begin{array}{rr} p_{i+, 2j} \\ p_{i, 2j+1} \end{array}\right] \end{matrix} \\ &= \begin{matrix} \left[\begin{array}{rr} \cos(\delta \omega_j) \sin(i \omega_j) + \sin(\delta \omega_j) \cos(i \omega_j) \\ -\sin(\delta \omega_j) \sin(i \omega_j) + \cos(\delta \omega_j)\cos(i \omega_j)) \\ \end{array}\right] \end{matrix} \\ &= \begin{matrix} \left[\begin{array}{rr} \sin((i + \delta) \omega_j) \\ \cos((i + \delta)\omega_j) \end{array}\right] \end{matrix} \\ &= \begin{matrix} \left[\begin{array}{rr} p_{i+\delta, 2j} \\ p_{i+\delta, 2j+1} \end{array}\right] \end{matrix} \\ \end{aligned}\]其中 $2 \times 2$ 的投影矩阵不依赖于任意的位置索引 $i$。
Summary
- 在self-attention中, queries, keys, 和 values 都来自于同一个位置。
- CNNs 和 self-attention 都可以并行计算, 并且 self-attention 有更短的最大路径长度。 然而,序列长度的平方的计算复杂度使self-attention对于非常长的序列计算很慢。
- 为了使用序列顺序信息,我们可以通过向输入表示添加位置编码注入绝对位置或相对位置信息。
Exercises
- 假设我们设计了一个深度结构,通过将self-attention层与位置编码叠加来表示序列。会有什么问题?
- 你能设计一个可学习的位置编码方法吗?