无参注意力
n_train = 50 n_test = 50
x_train, _ = torch.sort(torch.rand(n_train) * 5)

x_test = torch.arange(0, 5, 0.1)

y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,))
y_truth = f(x_test)
x_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
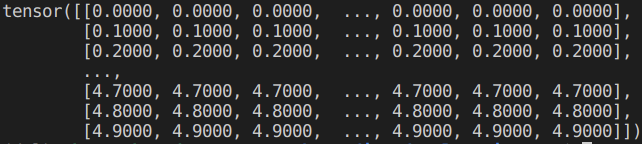
每一个x_test样本按行广播为x_train的形状,作为query。
Q:x_repeat: (n_test, n_train)
K:x_train: (n_train)
V: y_train: (n_train)
Attention Weight: (n_train, n_train)
有参注意力
Nadaraya-Watson Kernel Regression
n_train = 50 n_test = 50
x_train, _ = torch.sort(torch.rand(n_train) * 5)
x_test = torch.arange(0, 5, 0.1)
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,))
y_truth = f(x_test)
x_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
# Shape of the output `queries` and `attention_weights`:
# (no. of queries, no. of key-value pairs)
#--- dim_0是batch, dim_1是n_train ---
queries = queries.repeat_interleave(keys.shape[1]).reshape(
(-1, keys.shape[1]))
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# Shape of `values`: (no. of queries, no. of key-value pairs)
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)
X_tile = x_train.repeat((n_train, 1))
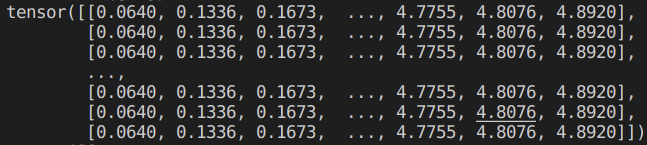
Y_tile = y_train.repeat((n_train, 1))
按列广播。
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
训练:
Q:x_train -> queries : (n_train) -> (n_train, n_train - 1)
K:keys: (n_train, n_train - 1)
V:values: (n_train, n_train - 1)
Attention Weight: (n_train, n_train - 1)
测试:
keys = x_train.repeat((n_test, 1))
values = y_train.repeat((n_test, 1))
Q:x_test -> queries : (n_test) -> (n_test, n_train)
K:keys: (n_test, n_train)
V:values: (n_test, n_train)
Attention Weight: (n_test, n_train)
Additive Attention
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
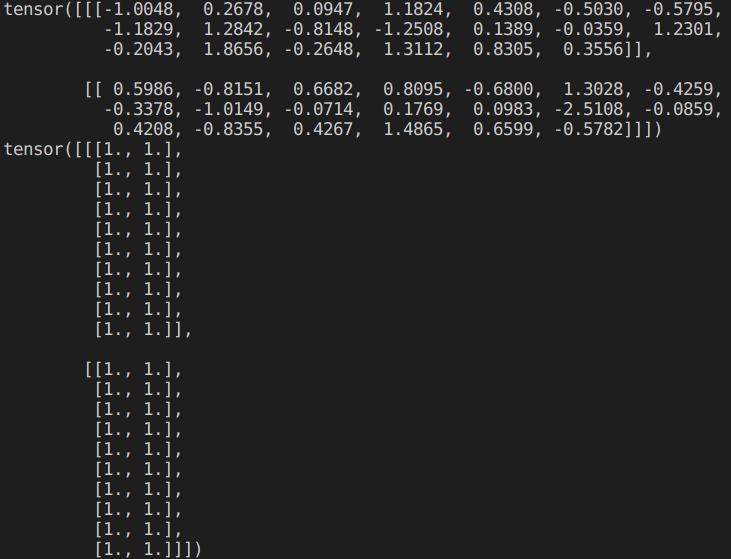
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
Q: queries: (2, 1, 20) -> (2, 1, num_hidden) -> (2, 1, 1, num_hidden)
K: keys: (2, 10, 2) -> (2, 10, num_hidden) -> (2, 1, 10, num_hidden)
V: values: (2, 10, 4)
Attention Weight: (2, 1,10, 8)-> (2, 1, 10, 1) -> (2, 1, 10)
Scaled Dot-Product Attention
queries = torch.normal(0, 1, (2, 1, 2))
keys = torch.ones((2, 10, 2))
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
Q: queries: (2, 1, 2)
K: keys: (2, 10, 2) -> (2, 2, 10)
V: values: (2, 10, 4)
Attention Weight: (2, 1,10)
Multi-Head Attention
multi-head attention 的每个 head 选择 scaled dot-product attention。令 $p_q = p_k = p_v = p_o/h$。
num_hiddens, num_heads = 100, 5
batch_size, num_queries, num_kvpairs, valid_lens = 2, 4, 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
Q:X:(2, 4, 100) -> (2, 4, 100) -> (2*5, 4, 20)
K:Y:(2, 6, 100) -> (2, 6, 100) -> (2*5, 6, 20)
V:Y:(2, 6, 100) -> (2, 6, 100) -> (2*5, 6, 20)
Attention Weight: (2*5, 4, 6)
Self-Attention
num_hiddens, num_heads = 100, 5
batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))