基于区域的卷积神经网络(Region-based convolutional neural networks, or regions with CNN feature, R-CNNs)是将深度模型应用于目标检测的一种前沿方法[Girshick et al., 2014]。在本节中,我们将讨论R-CNN和对它们的一系列改进:Fast R-CNN [Girshick, 2015], Faster R-CNN [Ren et al., 2015],和Mask R-CNN [He et al., 2017a]。由于篇幅限制,我们将只讨论这些模型的设计。
R-CNNs
R-CNN模型首先从图像中选择几个提出的区域(例如,anchor boxes是一种选择方法),然后标记它们的类别和边界框(例如,offsets)。然后,他们使用CNN进行前向计算,从每个提议的区域提取特征。然后,我们利用每个区域的特征来预测它们的类别和边界框。图13.8.1为一个R-CNN模型。
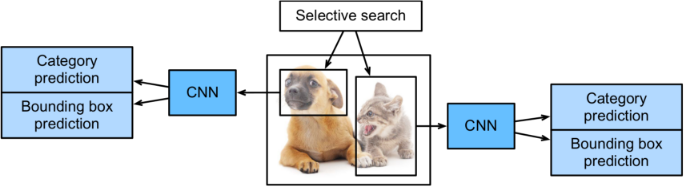
图13.8.1, R-CNN model
具体来说,R-CNN由四个主要部分组成:
- 对输入图像进行选择性搜索,选择多个高质量的提出区域[Uijlings等,2013]。这些被提议的区域通常在多个尺度上被选择,并且有不同的形状和大小。对每个区域的类别和ground-truth边界框进行标注。
- 将一个预先训练好的CNN以截断的形式放置在输出层之前。它将每个提出的区域转换为网络所需的输入维数,并使用前向计算输出从提出的区域中提取的特征。
- 以每个区域的特征和标注类别为样本,训练多个支持向量机进行目标分类。这里使用每个支持向量机来确定一个样本是否属于某个类别。
- 将每个区域的特征和标记的边界框结合为例,训练线性回归模型用于 ground-truth 边界框预测。
虽然R-CNN模型使用预训练CNN有效地提取图像特征,但主要缺点是速度慢。可以想象,我们可以从一幅图像中选择数千个提议的区域,需要CNN进行数千次的前向计算才能进行目标检测。这种巨大的计算负载意味着 R-CNN 在实际应用中并没有得到广泛应用。
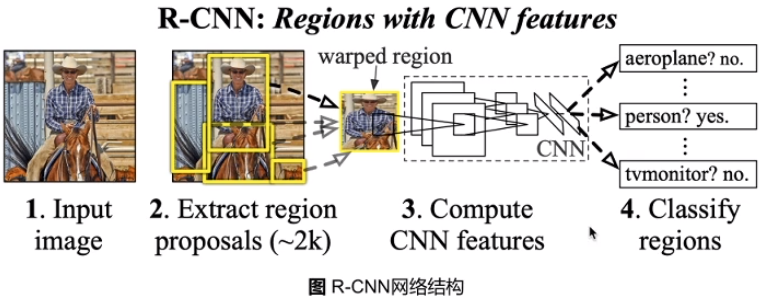
每张图会通过 Selective Search 提取 2000 个候选区域。
每个区域被 warped 到卷积网络要求的输入大小, 然后通过卷积网络得到一个输出, 作为这个区域的特征。
使用这些特征来训练多个svm来识别物体, 每个svm预测一个区域是不是包含某个物体。
使用这些区域特征来训练线性回归器来对区域位置进行调整。
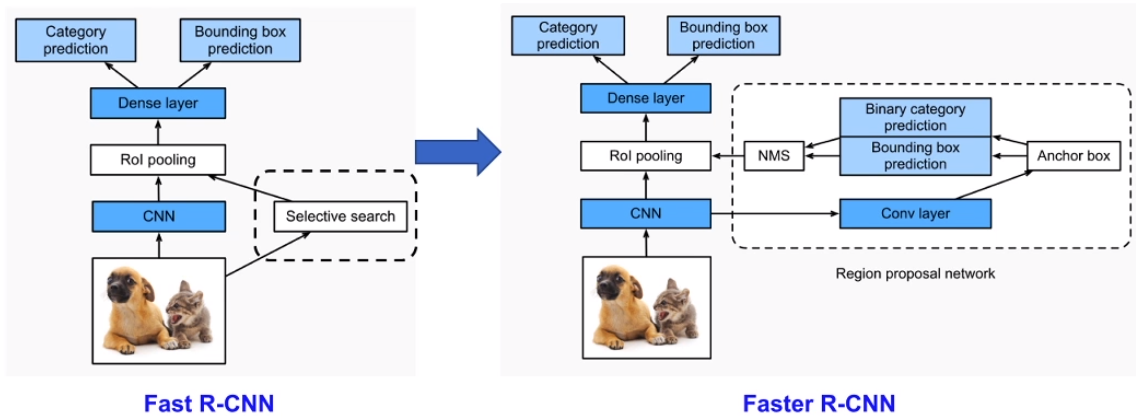
Fast R-CNN
R-CNN模型的主要性能瓶颈是需要为每个提出的区域独立提取特征。由于这些区域有高度的重叠,独立的特征提取会导致大量的重复计算。Fast R-CNN通过只对图像整体进行CNN前向计算来改进R-CNN。
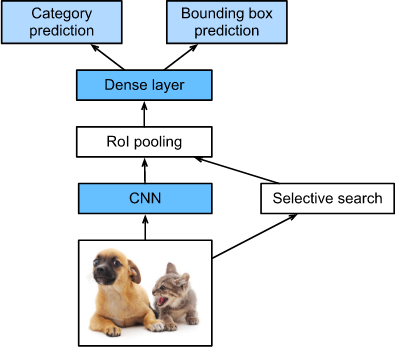
图13.8.2 Fast R-CNN model
图13.8.2 展示了一个Fast R-CNN模型。其主要计算步骤如下:
- 相比于R-CNN模型,Fast R-CNN模型使用整个图像作为CNN的输入进行特征提取,而不是每个提出的区域。此外,该网络通常被训练更新模型参数。由于输入是一幅完整的图像,所以CNN输出的形状为 $1 \times c \times h_1 \times w_1$。
- 假设 selective search 生成 n 个提议区域, 它们的不同形状表示CNN输出的不同形状的感兴趣区域(RoIs)。必须从这些RoIs区域中提取相同形状的特征(这里我们假设高为 $h_2$, 宽为 $w_2$)。Fast R-CNN引入了RoI池化,它使用CNN输出和RoI作为输入,输出为从每个提议的区域提取的特征的拼接(形状为 $n \times c \times h_2 \times w_2$)。
- 一个全连接层用于将输出转换成 $n \times d$ 的形状, 其中 $d$ 由模型设计决定。
- 在预测类别期间, 全连接层的形状输出再一次被转换成 $n \times q$ 并且使用 softmax regression($q$ 是种类的数量)。 在预测bbox期间,全连接层的输出形状再次被转换成 $n \times 4$。 这意味着我们为每个提议区域预测种类和bbox。
Fast R-CNN中的RoI池化层与我们之前讨论过的池化层有些不同。在一个普通的池化层中,我们设置了池化窗口、填充和步长来控制输出形状。在RoI池化层中,我们可以直接指定每个区域的输出形状,如指定每个区域输出的高度和宽度为 $h_2$, $w_2$。 假设 RoI窗口的高和宽为 $h$ 和 $w$, 这个窗口被分成 形状为 $h_2 \times w_2$ 的子窗口网格。 每个子窗口的尺寸约为 $(h/h_2) \times (w/w_2)$。 子窗口的高度和宽度必须总是整数,并且最大的元素被用作给定子窗口的输出。这使得RoI池化层能够从不同形状的RoI中提取出相同形状的特征。
在 图13.8.3 中, 我们选择 $3 \times 3$ 区域作为 $4 \times 4$ 输出的RoI。 对于这个 RoI, 我们使用 $2 \times 2$ RoI 池化层获得单个 $2 \times 2$ 的输出。 当我们将区域分成四个子窗口时, 它们分别得到元素 0, 1, 4, 和 5(5是最大的); 2和6(6是最大的); 8和9(9是最大的); 以及10。

图 13.8.3 $2 \times 2$ RoI 池化层
我们使用 torchvision 中的 roi_pool 函数展示 RoI pooling 层的计算。 假设CNN提取的feature X高度和宽度都为4,且只有一个通道。
1
2
3
4
5
import torch
import torchvision
X = torch.arange(16.).reshape(1, 1, 4, 4)
X
输出
1
2
3
4
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
假设图像的高度和宽度都是40像素,并且在图像上 selective search 生成两个提议区域。每个区域表示为5个元素: 区域目标的种类 和 坐上 和 右下 角的 x、y轴坐标。
1
rois = torch.Tensor([[0, 0, 0, 20, 20], [0, 0, 10, 30, 30]])
因为 X 的高和宽是图像的 1/10, 两个提议区域的坐标根据 spatial_scale 乘以 0.1, 并且然后 在X 上 分别标记 RoIs 为 X[:, :, 0:3, 0:3] 和 X[:, :, 1:4, 0:4]。 最后, 我们将两个 RoIs 分为一个 子窗口网格 并且 提取 高和宽为2 的特征 。
1
torchvision.ops.roi_pool(X, rois, output_size=(2, 2), spatial_scale=0.1)
输出:
1
2
3
4
5
6
tensor([[[[ 5., 6.],
[ 9., 10.]]],
[[[ 9., 11.],
[13., 15.]]]])
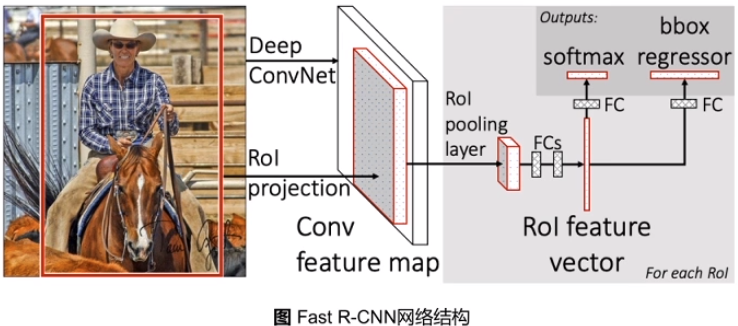
1)warp -> RoI Pooling
每个区域内均匀分成若干小块, 每个小块得到该区域内的最大值。
2) svm + regressor -> softmax + regressor
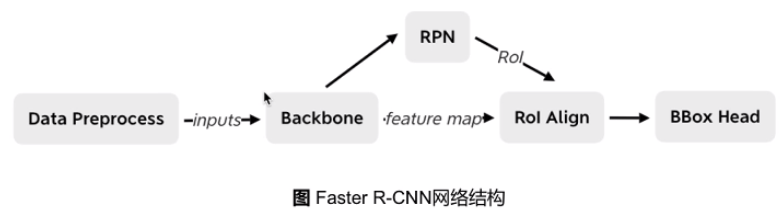
Faster R-CNN
为了获得精确的目标检测结果,Fast R-CNN通常要求在 selective search 中生成许多提议区域。Faster R-CNN用区域提议网络(RPN)取代 selective search。
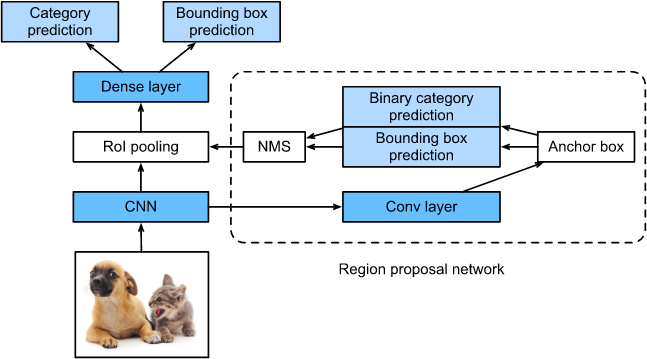
图 13.8.4 Faster R-CNN 模型
图 13.8.4 展示了一个 Faster R-CNN 模型。 相较于 Fast R-CNN, Faster R-CNN 仅将生成提议区域的方法从selective search 改为区域提议网络(RPN)。模型的其他部分保持不变。详细的区域提议网络计算过程如下所示:
- 我们使用一个 padding 为1 的 $3 \times 3$ 卷积层 变换 CNN的输出, 并且将输出通道的数量设置为 $c$。 这样,CNN从图像中提取的feature map中的每个元素都是一个长度为 $c$ 的新feature。
- 我们使用 feature map 中的每一个元素 作为 生成多个 不同尺寸 和 长宽比的 anchor boxes 的中心,然后标记它们。
- 我们使用在 anchor boxes的中心 的 长度 $c$ 的元素的特征 预测 二分类(物体或背景)并且 对预测每个 anchor boxes 的边界框。
- 然后,我们使用非极大值抑制去除对应预测目标类别的相似的边界框。最后,我们将预测的边界框作为RoI池化层所要求的区域输出。
值得注意的是,作为Faster R-CNN模型的一部分,区域提议网络是与模型的其余部分一起训练的。此外,Faster R-CNN的目标函数包括了目标检测中的类别和bbox预测,以及区域提议网络中anchor boxes的二值类别和bbox预测。最后,区域提议网络可以学习如何生成高质量的提议区域,从而在保持目标检测精度的同时减少提议区域的数量。
第一阶段: 产生候选区域
- 使用 Anchor 替代 Selective Search, 选取候选区域
- 选出包含物体的Anchor进入RoI Pooling提取特征
第二阶段: 对候选区域进行分类并预测目标物体位置

Anchor: 特征图上的每个点作为中心点, 生成多个大小比例不同的边界框, 这些框称为 Anchor。
图中红色、蓝色和绿色代表三种Anchor, 它们的大小不同。 每种 Anchor又分成了长宽比为1:2, 1:1, 2:1的三个Anchor, 因此特征图每个位置生成9个Anchor。
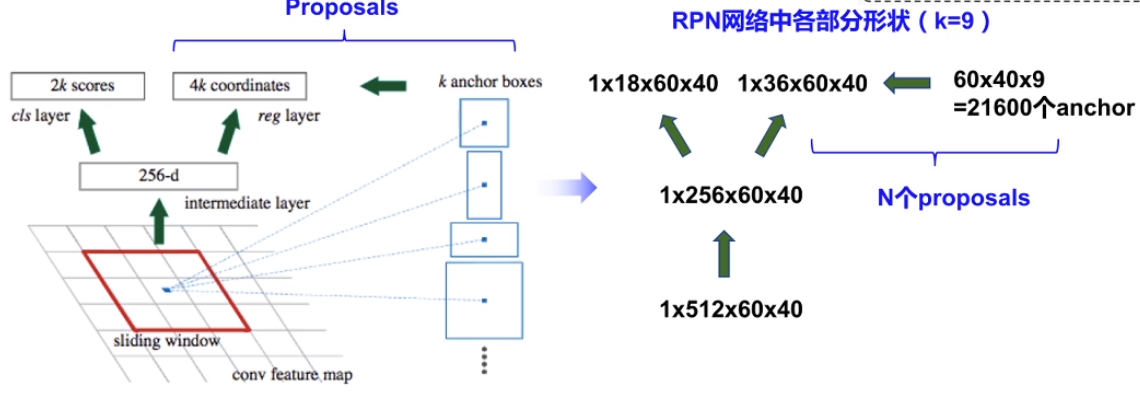
分类分支中 $18$ 是 $2 * 9$, 回归分支中 $36$ 是 $4 \times 9$ 。
RPN网络的训练策略
1) 向RPN网络中输入一个监督信息, 判断 Anchor 是否包含物体
- Anchor包含物体——正样本
- Anchor不包含物体——负样本
2) 根据Anchor和真实框IoU取值, 判断正 or 负样本。
- 正样本: 与某一真实框 IoU 最大的 Anchor, 与任意真实框 IoU > 0.7 的Anchor
- 负样本: 与所有真实框 IoU < 0.3 的Anchor
3) 采样规则:
- 共采样256个样本
- 从正样本中随机采样, 采样个数不超过128个
- 从负样本中随机采样, 补齐256个样本
RPN网络监督信息
分类分支: Anchor是否包含物体
- 正样本 - 1
- 负样本 - 0
回归分支: Anchor到真实框的偏移量
\[t^*_x = (x^* - x_a) / w_a \qquad_y^* = (y^* - y_a) / h_a \\ t_w^* = \log(w^* / w_a) \qquad _h^* = \log(h^* / h_a)\]- $x_a, y_a, w_a, h_a$ - anchor
- $x^{*}, y^{*}, w^{*}, h^{*}$ - 真实框
RPN网络Loss
RPN网络 Loss 计算公式:
\[\begin{aligned} L(\{p_i\}, \{t_i\}) &= \frac{1}{N_{cls}} \sum_i L_{cls}(p_i, p_i^*) \\ &+ \lambda \frac{1}{N_{reg}} \sum_i p_i^* L_{reg}(t_i, t_i^*) \end{aligned}\]RPN 网络的Loss是 分类 和 回归 两个Loss 相加得到的。
- $p$:分类分支的预测值
- $t$:回归分支的预测值
- $p^{*}$: 表示分类监督信息, 取值为0 或 1
-
- 1:表示Anchor为正样本
-
- 0: 表示Anchor为负样本
- $t^{*}$:表示回归分支的监督信息
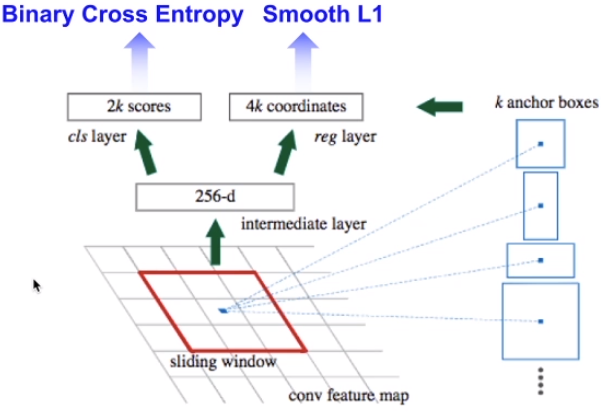
回归分支 Loss 计算公式
\[\frac{1}{N_{reg}} \sum_i p_i^* L_{reg}(t_i, t_i^*)\] \[L_{\log}(t^u, v) = \sum_{i \in \{x, y, w, h\}} \text{smooth}_{L_1}(t_i^u - v_i)\]其中:
\[\text{smooth}_{L_1}(x) = \begin{cases} 0.5 x^2 & \text{if} \quad \mid x \mid < 1 \\ \mid x \mid - 0.5 & \text{otherwise} \end{cases}\] \[\frac{d \text{ smooth}_{L_1}}{dx} = \begin{cases} x & \mid x \mid < 1 \\ \pm 1 & \mid x \mid > 1 \end{cases}\]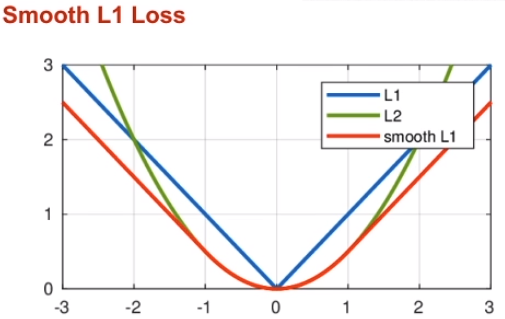
- 当预测框与监督信息差别过大时,梯度值不至于过大;
- 当预测框与监督信息差别很小时, 梯度值足够小。
RoI Pooling 和 RoI Align
RoI Pooling
从feature map上经过RPN得到一系列的proposals,大概2k个,这些bbox大小不等,如何将这些bbox的特征进行统一表示就变成了一个问题。即需要找一个办法从大小不等的框中提取特征使输出结果是等长的。
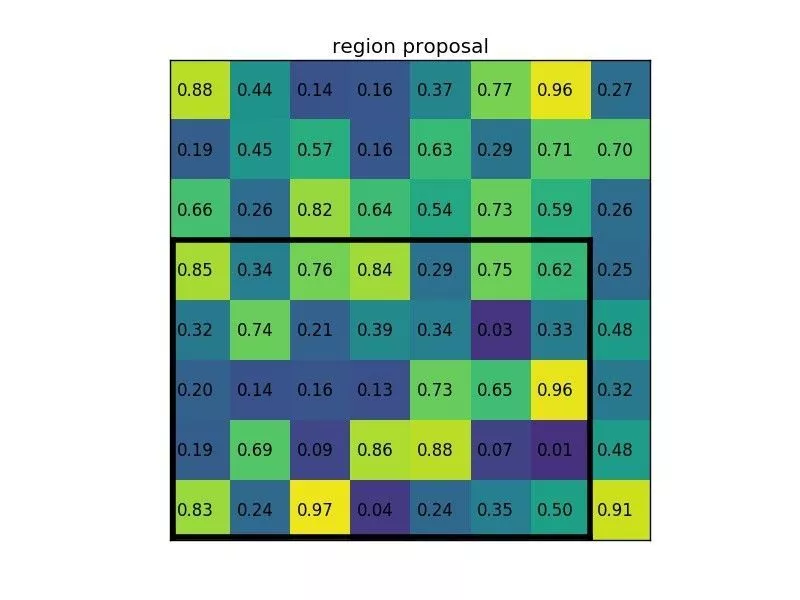
假如现在有一个8x8的feature map,现在希望得到2x2的输出,有一个bbox坐标为[0,3,7,8]。
这个bbox的w=7,h=5,如果要等分成四块是做不到的,因此在ROI Pooling中会进行取整。就有了上图看到的h被分割为2,3,w被分割成3,4。这样之后在每一块(称为bin)中做max pooling,可以得到下图的结果。
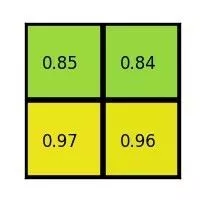
这样就可以将任意大小bbox转成2x2表示的feature。
ROI Pooling需要取整,这样的取整操作进行了两次, 会导致监测信息和提取出的特征不匹配。
- 候选框的位置取整。 当RoI位置不是整数时, RoI的位置需要取整。
- 提取特征时取整。 划分4个子区域做max pooling, 框的长度需要做近似取整。

ROI Align

因此有人提出不需要进行取整操作,如果计算得到小数,也就是没有落到真实的pixel上,那么就用最近的pixel对这一点虚拟pixel进行双线性插值,得到这个“pixel”的值。
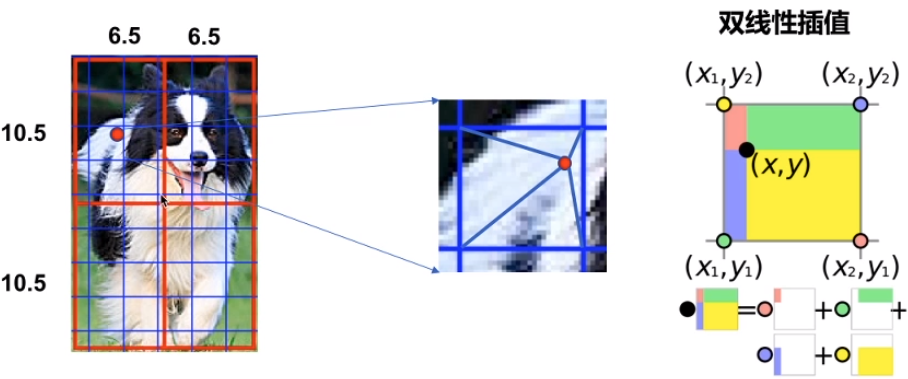
在区域内均匀地取 N 个点, 找到特征图上离每个点最近的四个点; 再通过双线性插值的方式, 得到点的输出。 最后对N个点取平均得到区域的输出。
BBox Head
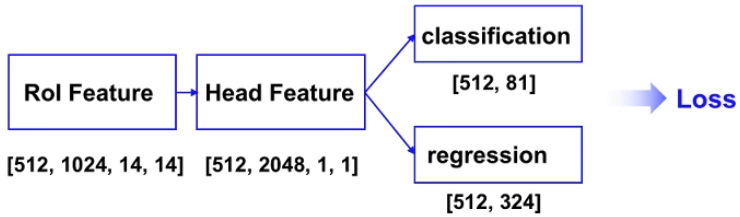
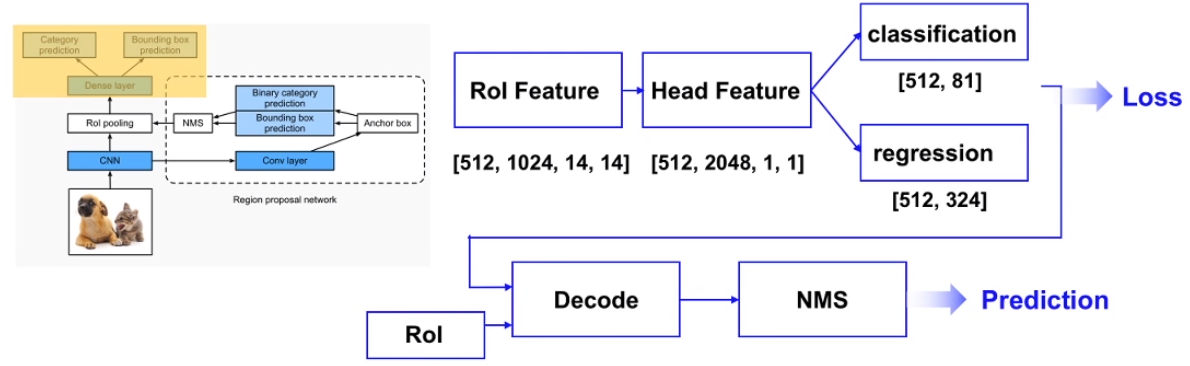
RoI Feature 经过 Pooling 将特征图从 14 x 14 压缩到 1 x 1; 然后这个特征经过两个 FC 作为分类分支和回归分支的预测, 最后再去计算loss。
预测阶段和RPN阶段生成proposals的过程类似, 先将head部分的输出和RPN输出的RoI解码得到预测框, 再进行NMS得到最终预测结果。
BBox Head 训练阶段
1) 判断RPN网络产生的候选框是否包含物体
2) 根据 RoI 和 真实框的 IoU, 判断正 or 负样本
- 正样本: IoU > 0.5
- 负样本: IoU < 0.5
3) 采样规则
- 共采样512个样本
- 从正样本中随机采样, 采样个数不超过128个
- 从负样本中随机采样, 补齐512个样本
BBox Head 中的监督信息
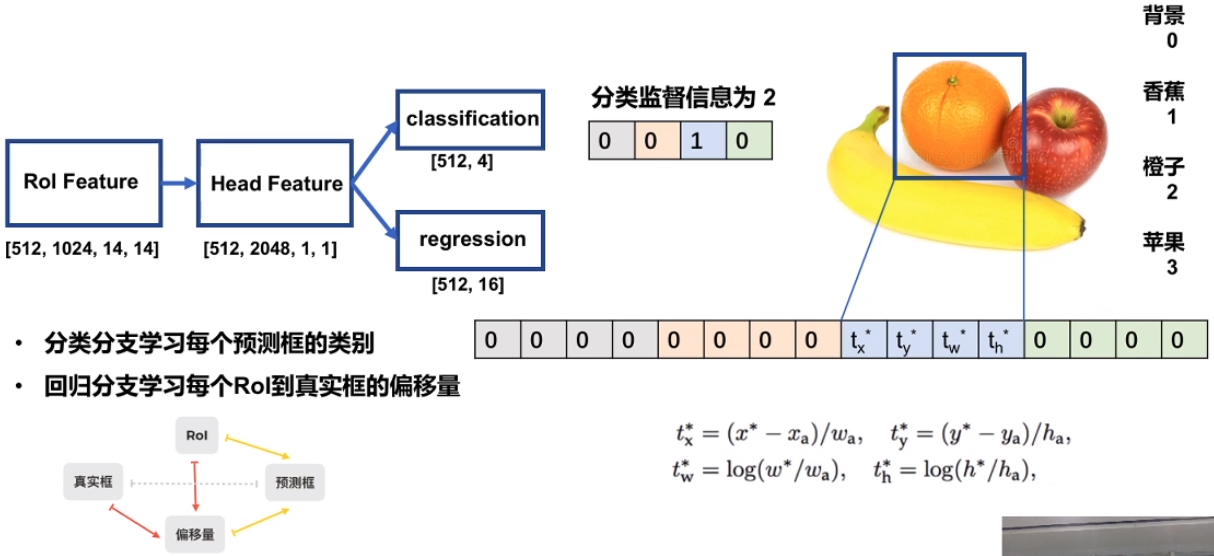
上面是分类监督信息,向量长度为4, 表示4类。
下面是回归监督信息, 向量长度为16, 表示4类的4个回归信息。
BBox Head Loss
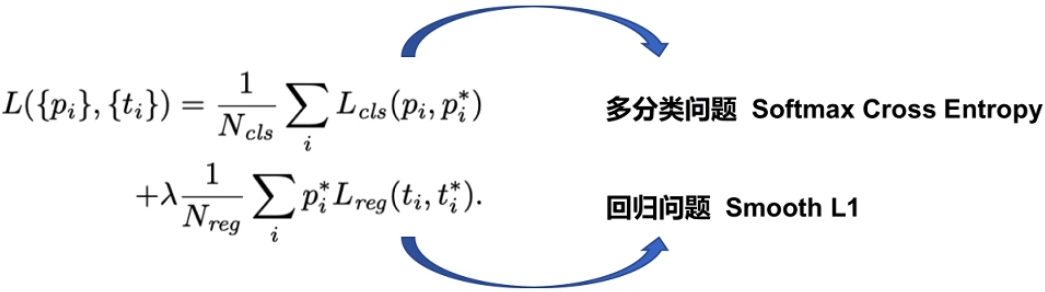
- $p$: 分类分支的预测值
- $t$:回归分支的预测值
- $p^*$: 表示真实框的分数, 取值为0或1
-
- 1:表示RoI为正样本
-
- 0: 表示RoI为负样本
- $t^*$: 表示回归分支的监督信息
Mask R-CNN
如果用图像中每个目标的像素级位置来标记训练数据,Mask R-CNN模型可以有效地利用这些详细的标签来进一步提高目标检测的精度。
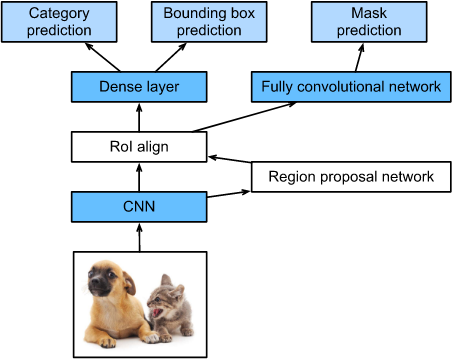
图13.8.5 Mask R-CNN model.
如图13.8.5所示, Mask R-CNN是对Faster R-CNN模型的修改。mask R-CNN模型将RoI池化层替换为RoI Align层。这允许使用双线性插值来保留feature map上的空间信息,使得Mask R-CNN更适合像素级的预测。RoI alignment层对所有 RoI 输出相同形状的特征图。它不仅预测了RoIs 的类别和边界框,而且允许我们使用一个额外的全卷积网络来预测目标的像素级位置。
Summary
- 一个R-CNN模型选择几个提议区域,使用一个CNN执行前向计算,并提取每个提议的区域的特征。然后利用这些特征来预测所提议区域的类别和边界框。
- Fast R-CNN通过只对图像整体进行CNN前向计算来改进R-CNN。引入RoI池化层,从不同形状的RoI中提取相同形状的特征。
- Faster R-CNN用区域建议网络代替了Fast R-CNN中使用的选择性搜索。这减少了生成的提议区域的数量,同时确保了精确的目标检测。
- Mask R-CNN使用了与Faster R-CNN相同的基本结构,但是增加了一个全卷积层,帮助在像素级定位目标,进一步提高了目标检测的精度。
FPN
构造多尺度金字塔, 期望模型能够具备检测不同大小尺度物体的能力
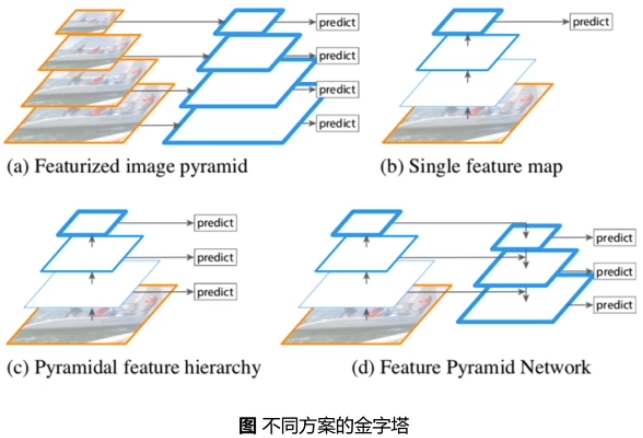
(a) Featurized image pyramid: 将输入图像缩放到不同尺度, 使用多个模型进行预测
(b) Single feature map: 仅使用最后一层的特征作为检测模型后续部分的输入
(c) Pyramidal feature hierarchy: 每个层级分别预测
(d) Feature Pyramid Network(FPN): 将不同层的特征进行融合再分级预测
FPN 网络结构
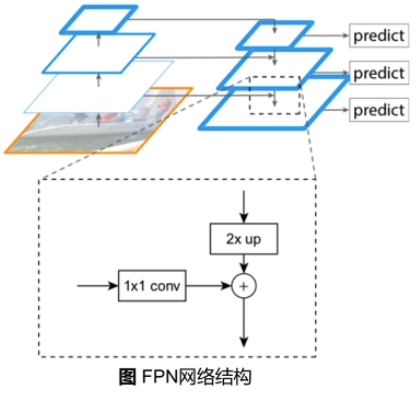
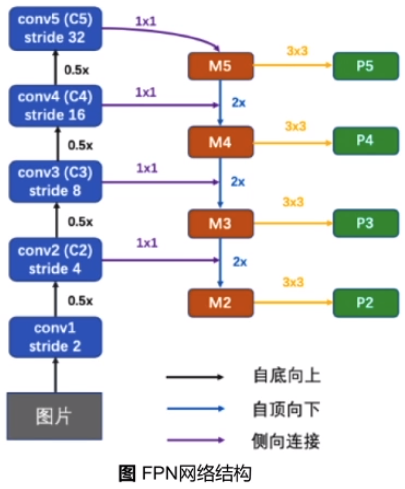
输入为骨干网络每一层的输出; 将特征进行上采样, 再与上一层特征相加得到FPN结构每一层的输出, FPN结构和骨干网络是相互独立的。
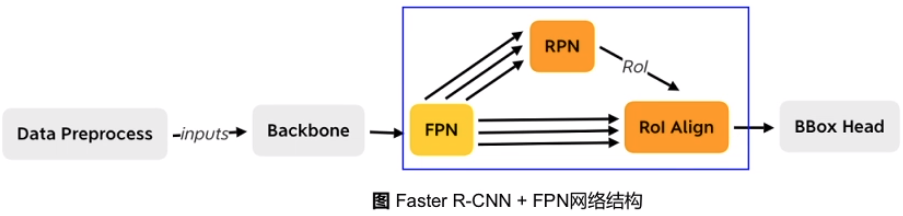
在骨干网络之后增加FPN网络 ,此时输出的是多个特征图, RPN模块和RoI Align模块会受到影响, 第二阶段 BBox head 不变。
FPN结构下的RPN网络
(1) Anchor: ${32^2, 64^2, 128^2, 256^2, 512^2} \rightarrow {P_2, P_3, P_4, P_5, P_6}$
(2) RPN网络分为多个head预测不同尺度上的候选框
(3) RPN网络的预测结果和anchor解码得到的RoI会进行合并
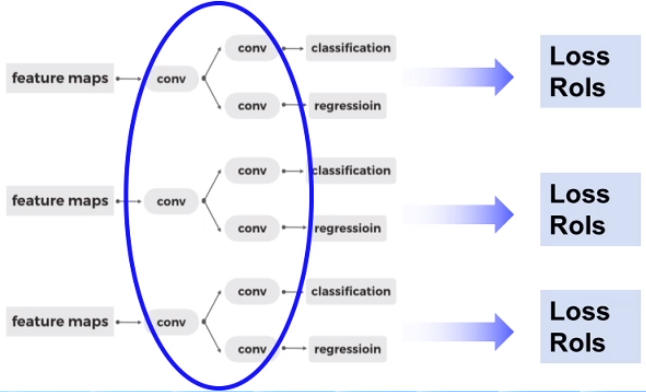
圈中卷积的权重是共享的。
FPN下的RoI Align
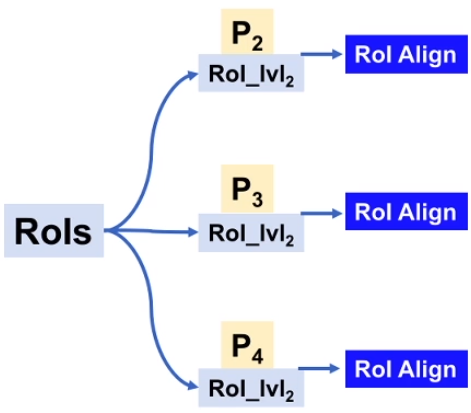
如何将 RoI 分配到不同层级?
- 将FPN的特征金字塔类比为图像金字塔
- 根据面积来对候选框进行分配
- $k$: 分配的层级
- $k_0$: 基准层
- $wh$: RoI的尺寸
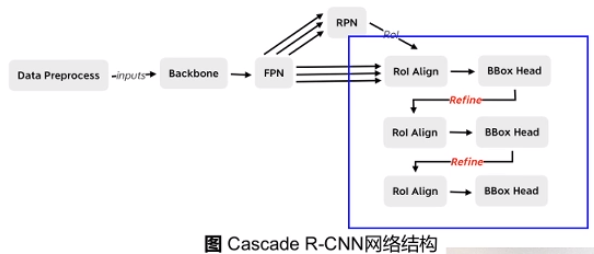
Cascade R-CNN
Cascade-RCNN 首先对Faster R-CNN的 IoU 进行了分析。
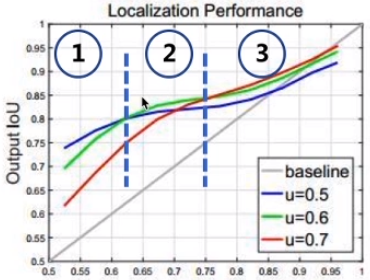
- 横轴: RPN生成的RoI和真实框的IoU;
- 纵轴: 经过第二阶段BBox head得到的新的bbox和真实框的IoU;
- 线条:使用不同IoU阈值筛选出候选框训练出来的模型
RoI 自身的 IoU 和 训练器训练用的 IoU 阈值较为接近时, 训练器的性能最优。
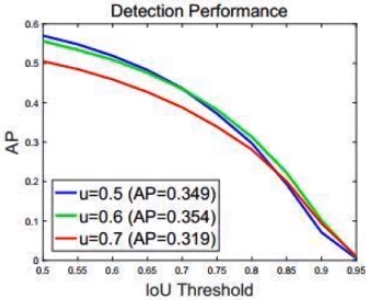
单一阈值训练出来的检测器效果有限
引入多个head对RoI进行调整。
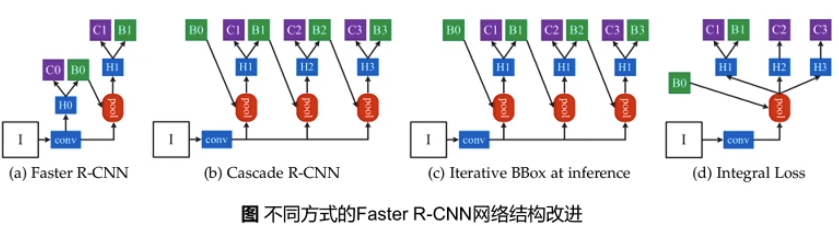
不同的改进方式:
Cascade R-CNN:对box三次微调, 每次 BBox head 的偏移量 和 RoI解码作为下个阶段的 RoI 输入Iterative BBox: 三次微调时的权重共享Integral Loss: 三次微调并联完成, 公用同样的RoI
Libra R-CNN
检测中的不平衡问题:
Feature Level$\rightarrow$ 提取出的不同level的特征怎么才能真正地充分利用? $\rightarrow$ FPN特征融合Sample Level$\rightarrow$ 采样的区域是否具有代表性? $\rightarrow$ 采样策略Objective Level$\rightarrow$ 目前设计的损失函数能不能引导目标检测器更好地收敛? $\rightarrow$ Loss
Libra R-CNN 的特征融合
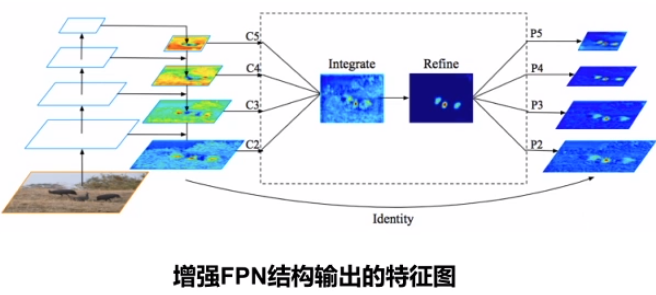
增强 FPN 结构输出的特征图
Rescale: 将不同层级的特征图通过插值或下采样的方法同一到C4层Integrate: 将汇集的特征进行融合 $C = \frac{1}{L} \sum_{l=l_{min}}^{l_{max}}C_l$Refine: 使用non-local结构对融合特征进一步加强Strengthen: 将优化后的特征与不同层级上的原始特征加和
Libra R-CNN 的采样策略

- 计算每个类别需要的采样个数
- 每个类别分别进行采样
- 例如: 正样本共20个, 包含2类, 期望采样4个正样本; 那么, 每一类随机采样2个正样本。

- 将负样本根据IoU分为两部分, 例如阈值取0.1
- 大于阈值的样本, 根据IoU进行分桶, 计算应该落在每个桶中的样本数量, 最后得到IoU均匀分布的负样本
- 低于阈值的样本随机采样
Libra R-CNN 的回归损失函数
Smooth L1 Loss
\[\text{smooth}_{L_1}(x) = \begin{cases} 0.5 x^2 & \text{if $\mid x \mid$ < 1} \\ \mid x \mid - 0.5 & \text{otherwise} \end{cases}\]Loss 较大的样本认为是困难样本
Loss 较小的样本是容易样本
Smooth L1 中困难样本对应的梯度相对与容易样本的梯度更大, 导致不同样本学习能力的不平衡
Balanced L1 loss
\[L_b(x) = \begin{cases} \frac{a}{b}(b \mid x \mid + 1) \ln(b\mid x \mid + 1) - \alpha \mid x \mid & \text{$\mid x \mid < 1$} \\ \gamma \mid x \mid + C & \text{otherwise} \end{cases}\]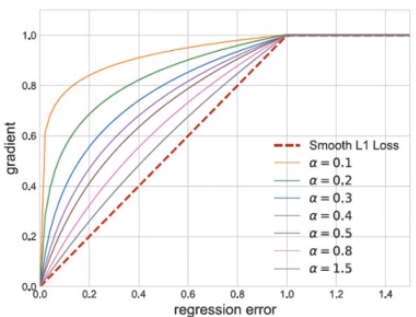
IoU loss
优点:
IoU就是我们所说的交并比,是目标检测中最常用的指标,在 anchor-based 的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和ground-truth的距离
- 可以说它可以反映预测检测框与真实检测框的检测效果。
- 还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。(满足非负性;同一性;对称性;三角不等性)
缺点:
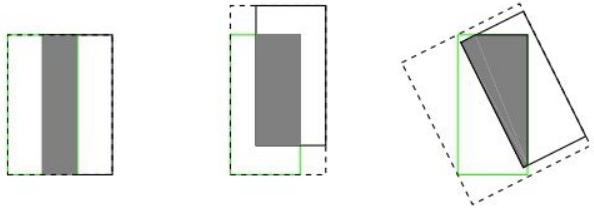
- 如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重合度)。同时因为loss=0,没有梯度回传,无法进行学习训练。
- IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。
GIoU(Generalized Intersection over Union)
由于IoU是比值的概念,对目标物体的scale是不敏感的。然而检测任务中的BBox的回归损失(MSE loss, l1-smooth loss等)优化和IoU优化不是完全等价的,而且 Ln 范数对物体的scale也比较敏感,IoU无法直接优化没有重叠的部分。
这篇论文提出可以直接把IoU设为以下回归的loss:
\[GIoU = IoU - \frac{\mid A_c - U \mid}{\mid A_c \mid}\]上面公式的意思是:先计算两个框的最小闭包区域面积 $A_c$(通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
- 与IoU相似,GIoU也是一种距离度量,作为损失函数的话,$G_{\text{GIoU}} = 1 - \text{GIoU}$,满足损失函数的基本要求
- GIoU对scale不敏感
- GIoU是IoU的下界,在两个框无限重合的情况下,IoU=GIoU=1
- IoU取值
[0,1],但GIoU有对称区间,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标。 - 与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
DIoU loss
DIoU要比GIou更加符合目标框回归的机制,将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。
\[\text{DIoU} = \text{IoU} - \frac{\rho^2 (b, b^{gt})}{c^2}\]基于IoU和GIoU存在的问题,作者提出了两个问题:
- 直接最小化anchor框与目标框之间的归一化距离是否可行,以达到更快的收敛速度?
- 如何使回归在与目标框有重叠甚至包含时更准确、更快?
其中,$b, b^{gt}$别代表了预测框和真实框的中心点,且 $\rho$ 代表的是计算两个中心点间的欧式距离。$c$ 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
优点
- 与GIoU loss类似,DIoU loss($L_{D_{IoU}} = 1 - DIoU$)在与目标框不重叠时,仍然可以为边界框提供移动方向。
- DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
- 对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快,而GIoU损失几乎退化为IoU损失。
- DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
CIoU loss(Complete-IoU)
论文考虑到bbox回归三要素中的长宽比还没被考虑到计算中,因此,进一步在DIoU的基础上提出了CIoU。其惩罚项如下面公式:
\[R_{CIoU} = \frac{\rho^2(b, b^{gt})}{c^2} + \alpha v\]其中 $\alpha$ 是权重函数
而 $v$ 用来度量长宽比的相似性, 定义为 $v = \frac{4}{\pi^2}(arctan \frac{w^{gt}}{h^{gt}} - arctan \frac{w}{h})^2$
完整的 CIoU 损失函数定义:
\[L_{CIoU} = 1 - IoU + \frac{\rho^2(b, b^{gt})}{c^2} + \alpha v\]最后, CIoU loss 的梯度类似于 DIoU loss, 但还要考虑 $v$ 的梯度。 在长宽 [0, 1] 的情况下, $w^2 + h^2$ 的值通常很小, 会导致梯度爆炸, 因此在 $\frac{1}{w^2 + h^2}$ 实现时将替换成1。
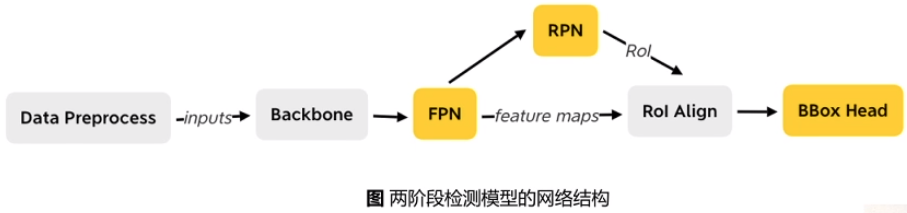
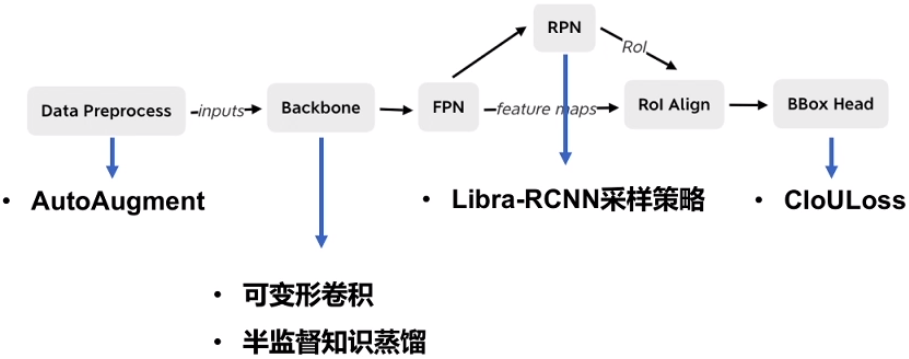
两阶段检测模型优化策略
服务器短模型优化策略
Baseline: ResNet50-vd + FPN + Cascade RCNN
Reference
- ROI Pooling和ROI Align
- Region of interest pooling explained
- https://aistudio.baidu.com/aistudio/education/group/info/16617
- Region-based CNNs (R-CNNs)
- Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression