Blog
自动文本图像合成是一项具有挑战性的任务,最近受到了极大的关注。该研究为机器学习(ML)模型如何捕获视觉属性并将其与文本关联提供了丰富的见解。相对于其他引导图像创作的输入,如sketches、 object masks或 mouse traces (我们在之前的工作中已经强调过),描述性句子是一种更加直观和灵活的表达视觉概念的方式。因此,一个强大的自动文本图像生成系统也可以是快速内容创建的有用工具,可以应用于许多其他创造性应用程序,类似于其他努力将机器学习集成到艺术创作中(例如,Magenta)。
最先进的图像合成结果通常使用生成对抗网络(GANs)来实现,它训练两个模型,一个是生成器,试图创建真实的图像,另一个是判别器,试图确定图像是真实的还是伪造的。许多文本到图像生成模型都是GANs,它们习惯于使用文本输入来生成语义相关的图像。这是非常具有挑战性的,特别是当提供了长而模糊的描述时。此外,GAN训练容易出现模式崩溃,这是训练过程中常见的情况,即生成器学习只产生有限的输出集,从而导致判别器无法学习鲁棒策略来识别伪造图像。为了减少模式崩溃,一些方法使用了multi-stage refinement networks 来迭代地refine 图像。然而,这种系统需要多阶段的训练,这比简单的单阶段端到端模型效率低。其他的努力则依赖于分层的方法,即在最终合成一个真实的图像之前,首先建立目标布局模型。这就需要使用标记的分割数据,而这很难获得。
在文本到图像生成的跨模态对比学习中,我们提出了Cross-Modal Contrastive Generative Adversarial Network(XMC-GAN),它通过 学习使用模态间(图像-文本)和模态内(图像-图像)的对比损失 最大化图像和文本之间的互信息 来解决文本-图像生成问题。这种方法有助于判别器学习更鲁棒和更具有判别性的特征,因此XMC-GAN即使在单阶段训练中也不容易出现模式崩溃。重要的是,与以前的 multi-stage 或 hierarchical 方法相比,XMC-GAN通过简单的 one-stage 生成实现了最先进的性能。它是端到端可训练的,并且只需要图像-文本对(相对于标记分割或边界框数据)。
Contrastive Losses for Text-to-Image Synthesis
文本-图像合成系统的目标是生成清晰、逼真的场景,并对其条件文本描述具有较高的语义保真度。为了实现这一点,我们提出了最大化对应对之间的互信息:
- 带有描述场景的句子的图像(真实的或生成的)
- 一个生成的图像和一个具有相同描述的真实图像
- 图像的区域(真实的或生成的)以及与之相关的单词或短语。
在XMC-GAN中,这是使用对比损失实现的。与其他GAN类似,XMC-GAN包含一个用于合成图像的生成器,以及一个判别真实图像和生成图像的判别器。真实图像,描述这些图像的文本,以及由文本描述产生的图像三组数据对该系统的对比损失作出贡献。生成器和判别器的单个损失函数是由带有全文描述的完整图像计算出的损失,结合单词或短语相关的分块图像计算出的损失。然后,对于每批训练数据,我们计算每个文本描述与真实图像之间的余弦相似度得分,以及每个文本描述与生成的这批图像之间的余弦相似度得分。目标是使匹配的对(文本到图像和真实的图像到生成的图像)具有较高的相似性得分,而非匹配的对具有较低的相似性得分。这样的对比损失允许判别器学习更鲁棒和更具有判别性的特征。
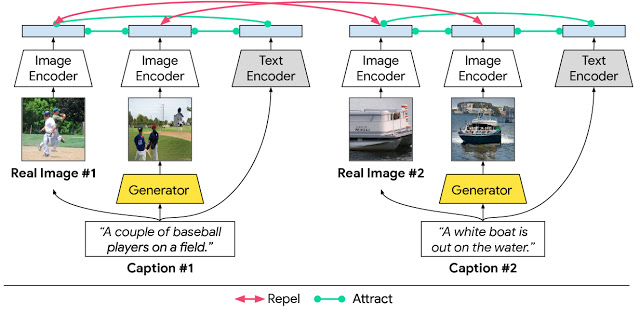
在我们提出的XMC-GAN文本-图像合成模型中,模态间和模态内对比学习。
Results
我们将XMC-GAN应用于三个具有挑战性的数据集,第一个是MS-COCO图像的MS-COCO描述的集合,另外两个是 Localized Narratives 的数据集,其中一个包含MS-COCO图像(我们称之为LN-COCO),另一个描述Open images数据(LN-OpenImages)。我们发现XMC-GAN在每一个方面都达到了新的技术水平。XMC-GAN生成的图像描绘了比使用其他技术生成的场景质量更高的场景。在MS-COCO上,XMC-GAN将最先进的Fréchet初始距离(FID)分数从24.7提高到9.3,并且明显受到人类评估者的青睐。
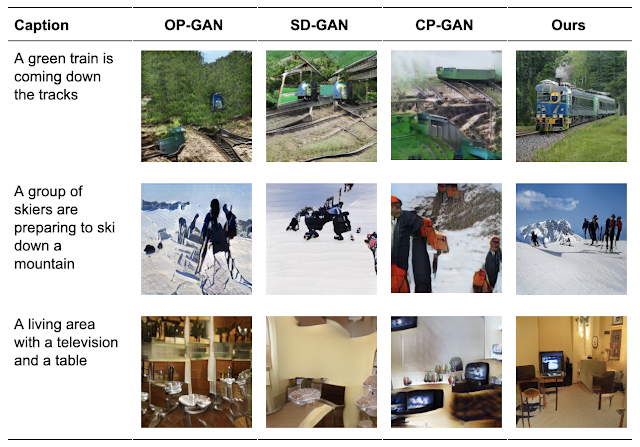
XMC-GAN还可以很好地概括具有挑战性的localization narratives数据集,它包含更长的、更详细的描述。我们之前的工作TReCS使用 mouse trace 输入处理 Localized Narratives 的文本到图像生成,以提高图像生成质量。尽管没有 mouse trace annotations,XMC-GAN在LN-COCO上的图像生成方面仍然能够显著优于TReCS,将最先进的FID从48.7提高到14.1。
Paper
Reference
-
Previous
【d2l】Model Selection, Underfitting, and Overfitting -
Next
【d2l】Numerical Stability and Initialization