Abstract
现存的自动评估标准主要对n-gram overlap敏感, 这对于模拟人类评估既没有效率也不必要。
我们假设 semantic propositional content 是人类caption评估重要组成部分, 基于scene graph提出一种新的自动描述评价标准。
Introduction
使用BLEU、ROUGE、CIDEr或者METEOR等评价指标测试captions的问题之一是这些metrics主要是对 n-gram overlap敏感的。
比如:
(a) A young girl standing on top of a tennis court.
(b) A giraffe standing on top of a green field.
两个描述完全不同, 但是得分是相似的。
假设 semantic propositional content 是 人类caption评估的重要组成成分之一。
通过同时将 candidate 和 reference 转换为scene graph的基于图的语义表征 来 评估caption的质量。
为了将image caption分解为scene graph, 我们需要一种两阶段的方式。
在第一阶段, 使用在大数据集上预训练的 dependency parser 建立 caption 词之间的语法依存关系。
在第二阶段, 使用基于规则的系统将依赖树映射为场景图。
给定 candidate 和 reference 的 scene graphs, 我们的准则计算 定义在scene graph表征语义propositions的逻辑 tuples 组合的F-score。
Background and Related Work
Bleu 是一个带有 句子简短惩罚项的 修改过的准确度准则, 在不同长度的 n-grams 计算加权几何平均。
METEROR在计算带有对齐fragmentation penalty的加权 F-score 之前, 使用 exact, stem, syninym 和 paraphrame 匹配 n-grams 之间取对齐句子。
ROUGE是一组measures使用F-measures的文本总结的自动评估。
CIDEr在candidate和reference 句子中应用 term frequency-inverse document frequency(tf-idf)权重到 n-grams 上, 然后比较n-grams之间的余弦相似度。
SPICE Metric
给定一个 candidate caption $c$ 和 一组与图像相关的 reference captions $S = {s_1, …, s_m}$, 我们的目标是计算在 $c$ 和 $S$ 相似度的分数。
首先我们将 candidate caption 和 reference caption 转换为一个编码了语义 propositional content 的中间表征。 我们选择的语义表征是scene graph, 由几个现有的数据集和最近发布的Visual Genome数据集组成的通用结构。
Semantic Parsing——Caption to Scene Graphs
给定一组目标类别 $C$, 一组关系类型 $R$, 一组属性类型 $A$, 以及一个 caption $c$, 我们解码 $c$ 为一个 scene graph:
\[G(c) = <O(c), E(c), K(c)>\]其中 $O(c) \subseteq C$ 是一组在 $c$ 中提到的物体, $E(c) \subseteq O(c) \times R \times O(c)$ 是一组表征物体关系的边, $K(c) \subseteq O(c) \times A$ 是一组物体对应的属性。不把图像中出现的多个物体复制表示, 而是将数量作为物体的属性表示。
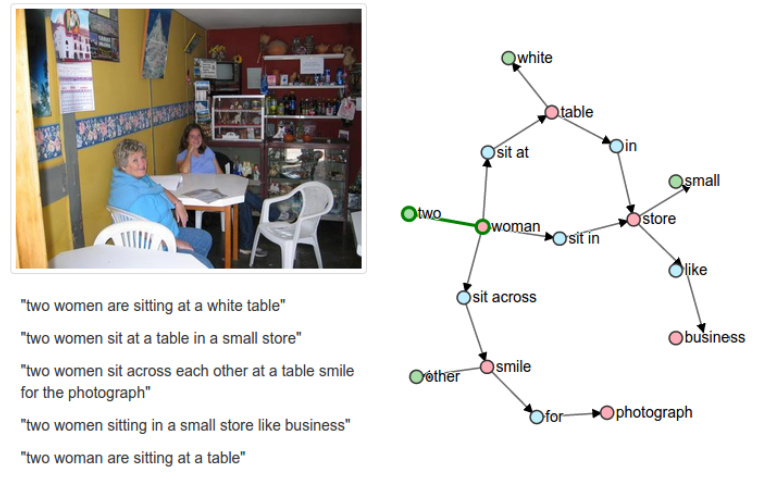
上下文无关的语法依存parser是三个后处理步骤, 它们用来简化量词, 处理代词和处理复数名词。
然后,根据9个简单的语言规则对生成的树结构进行解析,提取出义化的对象、关系和属性,共同组成场景图。
F-score Calculation
为了评估 candidate 和 reference scene graphs 的相似性, 我们将 scene graph 中的 语义关系视为 logical propositions的组合, 或者是一个 tuple。
比如, scene graph 可以被表示以下的 tuples:
\[\{(girl), (court), (girl, young), (girl, standing), (court, tennis), (girl, on-top-of, court)\}\]将scene graph中的semantic propositions视作一组tuples, 我们定义二值匹配操作符 $\otimes$ 作为两个scene graphs 返回匹配tuples的函数。
\[P(c, S) = \frac{\mid T(G(c)) \otimes T(G(S))}{\mid T(G(c))\mid}\] \[R(c, S) = \frac{\mid T(G(c)) \otimes T(G(s))}{\mid T(G(s)) \mid}\] \[SPICE(c, S) = F_1(c, S)=\frac{2 · P(c, S) · R(c, S)}{p(c, S) + R(c, S)}\]c表示候选标题,S表示参考标题集合, G(·) 表示利用某种方法将一段文本 成一个场景图(Scene Graph), T(·)表示将一个场景图转换成一系列元组(tuple)的集合, ⊗运算为非严格匹配。
-
Previous
【深度学习】GPT:Improving Language Understanding by Generative Pre-Training -
Next
【深度学习】Video-to-Video Synthesis