到目前为止,本书主要关注命令式编程,它使用print, +等语句,以及 if 改变程序状态。
1
2
3
4
5
6
7
8
9
10
def add(a, b):
return a + b
def fancy_func(a, b, c, d):
e = add(a, b)
f = add(c, d)
g = add(e, f)
return g
print(fancy_func(1, 2, 3, 4))
1
10
Python 是一门解释性语言。 我们评估上面 fancy_func 函数, 它按顺序执行函数体的操作。 评估 $e = add(a, b)$ 并且存储结果为变量 $e$, 从而改变程序的状态。 接下来的两个状态 $f = add(c, d)$ 和 $g = add(e, f)$ 也相似地实现加法并且存储结果为变量。
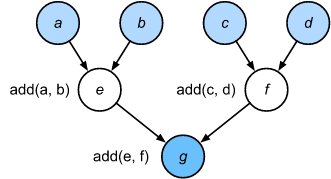
尽管命令式的编程是方便的, 但是是不足够的。 一方面,即便 add 函数反复地调用 fancy_fuc 函数, Python 将会分别执行调用三次函数。 如果它们在GPU上执行, 由Python解释器引起的开销可能会变得难以承受。 此外, 它需要保存 $e$ 和 $f$ 的变量值, 直到所有 fancy_func 的状态被执行。 这是因为我们不知道变量 $e$ 和 $f$ 是否将会用于程序的其他部分。
Symbolic Programming
考虑另一种方法,symbolic programming,在这种方法中,只有在完全定义了进程之后,才会执行计算。这个策略被多个深度学习框架使用,包括 Theano 和 TensorFlow。它通常包括以下步骤:
- 定义要执行的操作
- 将操作编译成可执行程序
- 提供所需的输入并调用编译后的程序以供执行
这允许进行大量的优化。首先,在许多情况下,我们可以跳过Python解释器,从而消除在多个GPU上与CPU上的单个Python线程配对时的性能瓶颈。其次, 一个编译器能优化和重写上述代码为 print((1 + 2) + (3 + 4)) 甚至 print(10)。 例如,当不再需要某个变量时,它可以释放内存(或从不分配内存)。或者它可以将代码完全转换成等价的部分。为了更好地理解,考虑下面对命令式编程的模拟。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def add_():
return '''
def add(a, b):
return a + b
'''
def fancy_func_():
return '''
def fancy_func(a, b, c, d):
e = add(a, b)
f = add(c, d)
g = add(e, f)
return g
'''
def evoke_():
return add_() + fancy_func_() + 'print(fancy_func(1, 2, 3, 4))'
prog = evoke_()
print(prog)
y = compile(prog, '', 'exec')
exec(y)
1
2
3
4
5
6
7
8
9
10
def add(a, b):
return a + b
def fancy_func(a, b, c, d):
e = add(a, b)
f = add(c, d)
g = add(e, f)
return g
print(fancy_func(1, 2, 3, 4))
10
命令式(解释式)编程和符号编程之间的区别如下:
- 命令式编程更容易。在Python中使用命令式编程时,大多数代码都是简单易懂的。 调试命令式编程代码也更容易。这是因为获取和打印所有相关中间变量值或使用Python的内置调试工具更容易。
- 符号编程更有效,也更容易移植。符号编程使得在编译期间更容易优化代码,同时还能够将程序移植到独立于Python的格式中。这允许程序在非Python环境中运行,从而避免了与Python解释器相关的任何潜在性能问题。
Hybrid Programming
从历史上看,大多数深度学习框架都是在命令式方式和符号式方式之间进行选择的。例如,Theano, TensorFlow,Keras, CNTK都是用符号式构建模型。相反,Chainer和PyTorch采用命令式方法。 在后来的版本中,TensorFlow 2.0和Keras添加了命令模式。
如上所述,PyTorch基于命令式编程并使用动态计算图。为了利用符号编程的可移植性和效率,开发人员考虑是否有可能将两种编程模型的优点结合起来。这就产生了torchscript,允许用户使用纯命令式编程进行开发和调试,同时能够将大多数程序转换为符号程序,以便在需要产品级计算性能和部署时运行。
Hybridizing the Sequential Class
要了解 hybridization 是如何工作的,最简单的方法是考虑多层的深层网络。按照惯例,Python解释器需要执行所有层的代码,以生成一条指令,然后转发给CPU或GPU。对于单个计算设备,这不会导致任何重大问题。然而, 如果我们使用 8-GPU的服务器, Python将忙于保持所有GPU工作。 单线程Python解释器成了这里的瓶颈。让我们看看如何通过将Sequential替换为HybridSequential来解决代码的重要部分。我们首先定义一个简单的MLP。
1
2
3
4
5
6
7
8
9
10
11
12
13
import torch
from torch import nn
from d2l import torch as d2l
# Factory for networks
def get_net():
net = nn.Sequential(nn.Linear(512, 256), nn.ReLU(), nn.Linear(256, 128),
nn.ReLU(), nn.Linear(128, 2))
return net
x = torch.randn(size=(1, 512))
net = get_net()
net(x)
1
tensor([[0.1009, 0.1146]], grad_fn=<AddmmBackward>)
使用 torch.jit.script 函数转换模型, 们能够在MLP中编译和优化计算。模型的计算结果保持不变。
1
2
net = torch.jit.script(net)
net(x)
1
tensor([[0.1009, 0.1146]], grad_fn=<AddmmBackward>)
这似乎好得让人难以置信: 编写与之前相同的代码,然后使用 torch.jit.script 简单地转换模型。 一旦发生这种情况,网络就被优化了(我们将在下面对性能进行基准测试)。
Acceleration by Hybridization
为了演示编译所获得的性能改进,我们比较了 Hybridization 前后评估 net(x) 所需的时间。让我们先定义一个类来度量这个时间。当我们开始度量(和改进)性能时,它将在整个章节中非常有用。
1
2
3
4
5
6
7
8
9
10
11
12
#@save
class Benchmark:
"""For measuring running time."""
def __init__(self, description='Done'):
self.description = description
def __enter__(self):
self.timer = d2l.Timer()
return self
def __exit__(self, *args):
print(f'{self.description}: {self.timer.stop():.4f} sec')
现在我们可以调用网络两次,一次使用torchscript,一次不使用torchscript。
1
2
3
4
5
6
7
8
9
net = get_net()
with Benchmark('Without torchscript'):
for i in range(1000):
net(x)
net = torch.jit.script(net)
with Benchmark('With torchscript'):
for i in range(1000):
net(x)
1
2
Without torchscript: 0.7222 sec
With torchscript: 0.5762 sec
如上面观察到的结果, 在 nn.Sequential 使用 torch.jit.script 函数之后,通过符号式编程提高了计算性能。
Serialization
编译模型的好处之一是我们可以将模型及其参数序列化(保存)到磁盘上。这允许我们以一种独立于所选择的前端语言的方式存储模型。这使我们能够将训练过的模型部署到其他设备上,并轻松地使用其他前端编程语言。同时,代码通常比命令式编程更快。让我们看看 save 函数的作用。
1
2
net.save('my_mlp')
!ls -lh my_mlp*
1
-rw-r--r-- 1 jenkins jenkins 651K Jul 24 08:45 my_mlp
-
Previous
【深度学习】CycleGAN:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks -
Next
【d2l】Asynchronous Computation