当我们从一个 GPU 到多个 GPU,然后到包含多个GPU的多个服务器,它们可能分布在多个机架和网络交换机上,我们的分布式和并行训练算法需要变得更加复杂。细节很重要,因为不同的连接有非常不同的带宽(比如 NVLink 在合理设置下连接6个设备可以提供 100GB/s带宽, PCIe 4.0(16-lane)提供32 GB/s, 同时高速 100GbE 以太网仅能达到 10GB/s )。同时, 要求统计学习者是一个网络和系统的专家也是不合理的。
Data-Parallel Training
让我们回顾一下分布式训练的数据并行训练方法。下图展示 12.5 节中实现的数据并行的变体。 它的关键在于,在更新的参数被重新广播到所有GPU之前,梯度要聚合在GPU 0上。
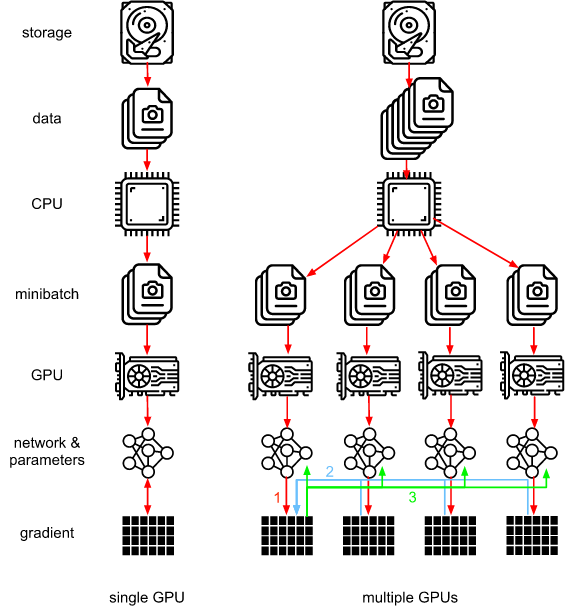
但是,在GPU 0上聚合的决定似乎是特殊的。毕竟,我们也可以在CPU上进行聚合。事实上,我们甚至可以决定在一个GPU上聚合一些参数,同时在另一个GPU上聚合一些参数。只要优化算法支持这一点。例如,如果我们有四个梯度向量 $g_1, …, g_4$, 我们可以将每个 $g_i$ 聚合梯度到一个GPU上。
如12.4节中所讨论的, 我们处理的是真实的物理硬件,不同的总线具有不同的带宽。看一下图12.7.2所示的真实的4路GPU服务器。如果它连接得很好,它可能有 100 GbE 网卡。由于CPU的PCIe通道太少,无法直接连接到所有GPU(例如,消费级英特尔CPU有24个通道),我们需要一个 multiplexer。16x Gens link 的 CPU 的带宽是 16GB/s。这也是每个图形处理器连接到交换机的速度。 这意味着设备之间的通信更有效。
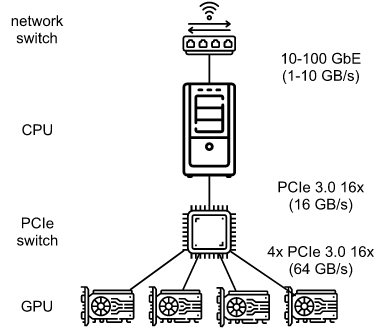
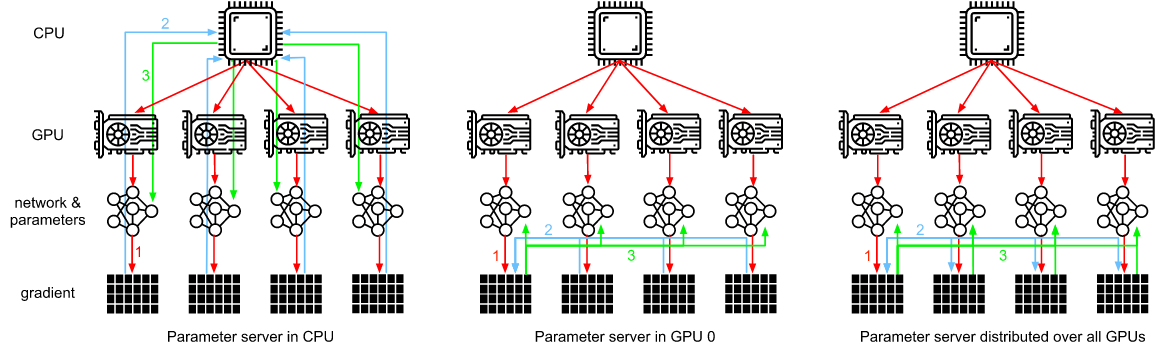
为了便于讨论,让我们假设梯度为160 MB。在这种情况下,将其他3个 GPU 的梯度发送到第4个 GPU 需要30毫秒(每次传输花费 10ms = 160MB / 16GB/s)。 再加上30毫秒来传输权重向量,总共60毫秒。如果我们将所有数据发送到CPU, 这将导致40ms的损耗, 因为四个GPU中的每一个都需要将数据发送到CPU, 总共产生80ms的损耗。最后,假设我们能够将梯度分成4个部分,每个部分40 MB。PCIe switch 提供了所有链路之间的全带宽操作, 现在我们可以在不同的GPU上同时聚合每个部分。这将产生 7.5ms 而不是 30ms 延迟, 由于同步操作总共产生15ms延迟。 根据同步参数的方式,相同的操作可能需要15到80毫秒的时间。下图描述交换参数的不同策略。
注意,当谈到提高性能时,我们还有另一个工具可以使用:在深度网络中,需要花一些时间来计算从顶部到底部的所有梯度。我们可以开始为一组参数同步梯度,同时我们还在为其他组参数计算梯度。
Ring Synchronization
当谈到现代深度学习硬件上的同步时,我们经常遇到定制的网络连接。例如,AWS p3.16xlarge和NVIDIA DGX-2实例共享如图12.7.4所示的连接结构。 每个GPU通过一个PCIe连接连接到主GPU, 它最快有 16GB/s。 此外每个GPU有6个 NVLink 连接, 每个的速度能够达到双向 300 Gbit/s。 这能达到大约每条连接单向 18GB/s。总之,NVLink总带宽明显高于PCIe带宽。问题是如何最有效地利用它。
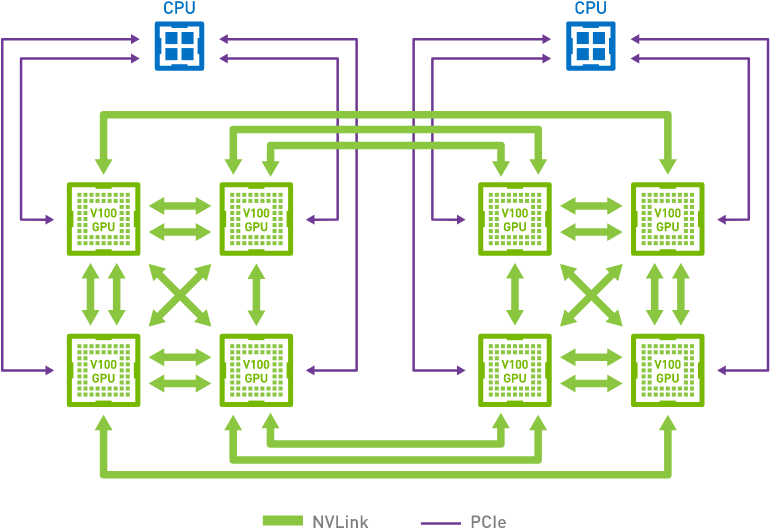
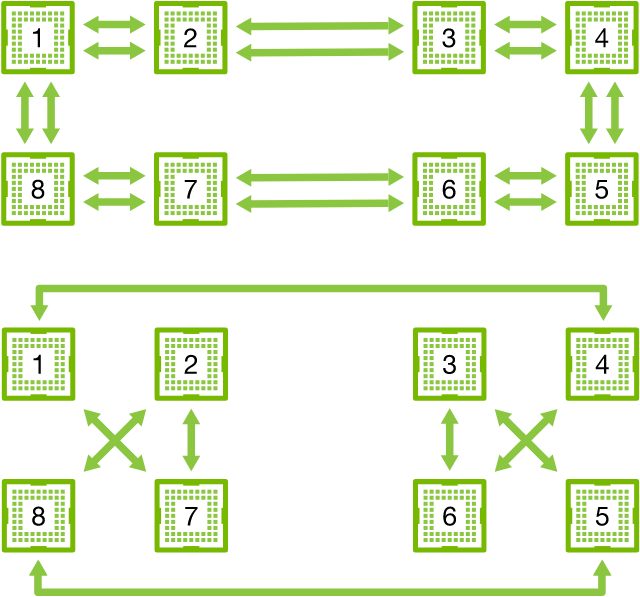
结果表明,最优的同步策略是将网络分解成两个环,直接利用它们进行数据同步。 图12.7.5展示了可以将网络分解为一个具有双NVLink带宽的环(1-2-3-4-5-6-7-8-1)和一个具有常规带宽的环(1-4-6-3-5-8-2-7-1)。在这种情况下,设计一个有效的同步协议并非易事。
给定 $n$ 个计算节点 (或者 GPUs) 我们可以将梯度从第一个节点发送到第二个节点。本地的梯度加上收到的梯度,并将结果发送到第三个节点,以此类推。在 n - 1 步后, 可以在最近访问的节点聚合梯度。 即,聚合梯度的时间随节点数线性增长。但如果我们这样做,算法效率会很低。毕竟,在任何时候,只有一个节点在通信。如果我们将梯度拆分为 n 块 并且 从节点 $i$ 开始同步 块 $i$ 呢? 每一块的大小为 $1/n$, 总共的时间为 $(n-1)/n \approx 1$。 换句话说,花在聚合梯度上的时间不会随着环的增大而增加。这是一个相当惊人的结果。下图说明了在 $n = 4$ 节点, 上面的步骤顺序。
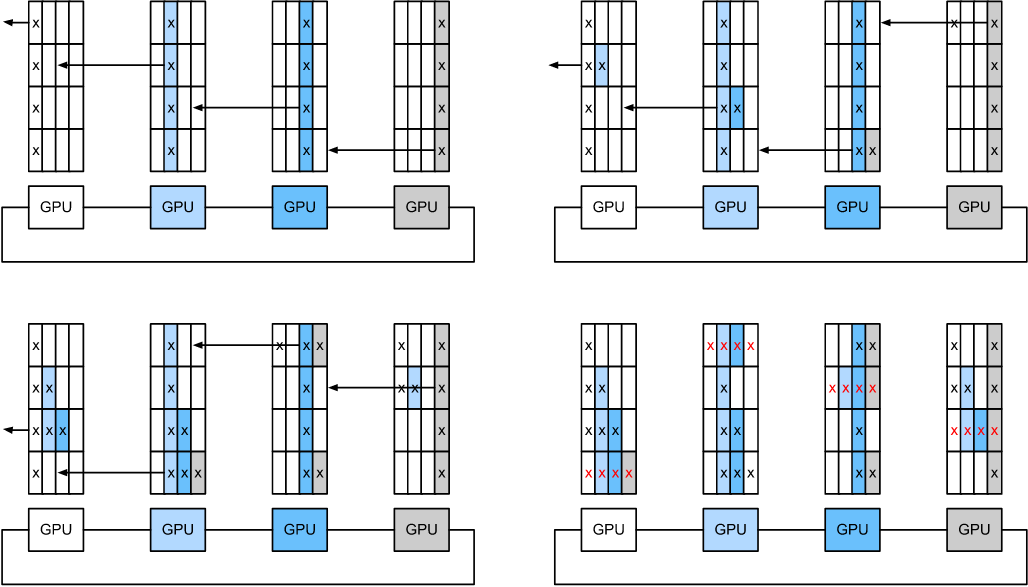
每个节点在将右邻居的梯度加到本地梯度后, 将梯度传给它的左邻居。
如果我们在 8块 V100 GPUs 上同步相同的 160MB, 我们达到大约 $2 · 160MB /(3 · 18GB/s) \approx 6ms$。 尽管我们现在使用8个GPU, 这比使用PCIe总线要好。请注意,在实践中,这些数字会有些糟糕,因为深度学习框架经常不能将通信组合成大规模的突发传输。
请注意,即环同步与其他同步算法没有根本的不同。唯一的区别是,与简单树相比,同步路径稍微复杂一些。
Multi-Machine Training
在多台机器上进行分布式训练增加了一个进一步的挑战: 我们需要与相对较低带宽的服务器通信,在某些情况下,这种结构可能会慢一个数量级。跨设备的同步是很棘手。毕竟,不同的机器运行训练代码会有细微的不同速度。因此,如果我们想要使用同步分布式优化,我们需要同步它们。图12.2.7 说明了分布式并行训练是如何发生的。
- 在每台机器上读取(不同的)一批数据,在多个GPU上分割并转移到GPU内存。这些预测和梯度分别在每个GPU批处理上计算。
- 所有本地GPU的梯度聚合在一个GPU上(或者部分聚合在不同的GPU上)。
- 梯度被发送到CPU。
- CPU将梯度发送到一个中央参数服务器,中央参数服务器聚合所有梯度。
- 然后使用聚合梯度更新参数,并将更新后的参数广播回单个CPU。
- 信息发送到一个(或多个)GPU上。
- 将更新后的参数分布在所有GPU上。
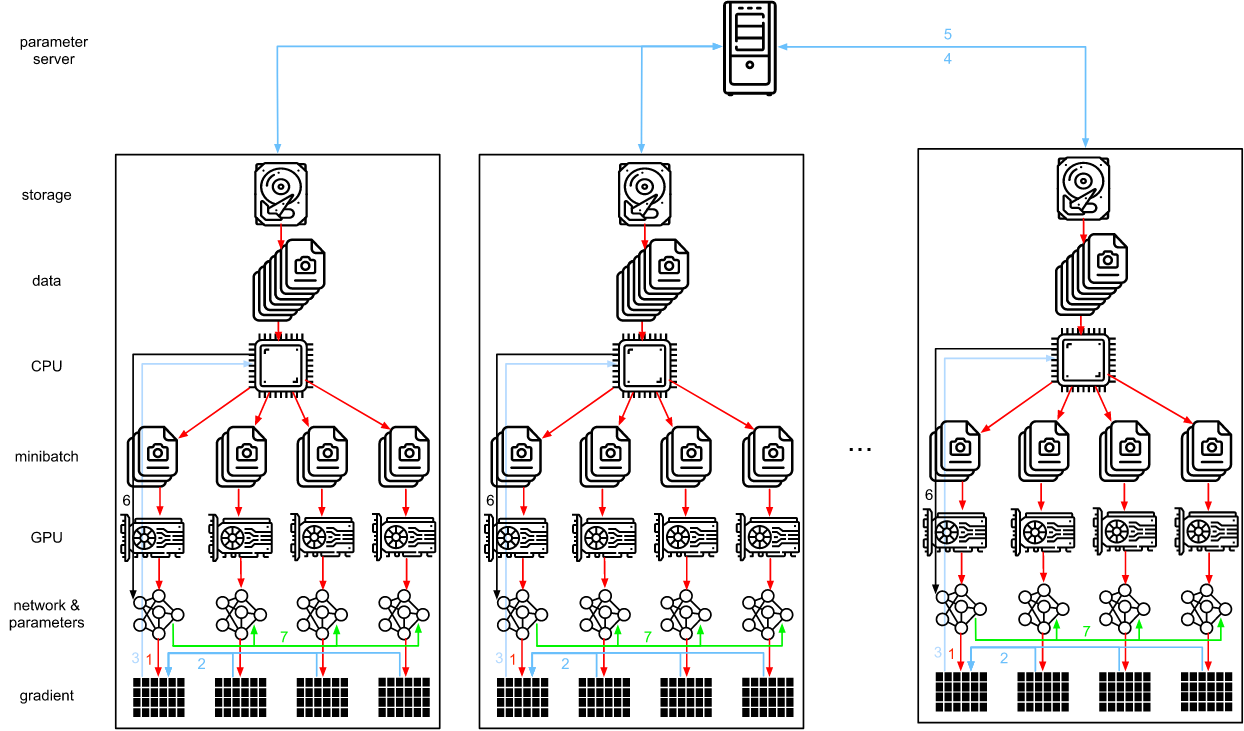
这些操作看起来都很简单。事实上,它们可以在一台机器上高效地执行。但是,我们看到一旦有多台机器,就会发现中央参数服务器成为了瓶颈。毕竟,每台服务器的带宽是有限的, 因此 $m$ 个 worker 发送所有梯度到服务器花费的时间为 $O(m)$。 我们可以通过增加服务器的数量来突破这个瓶颈。此时,每个服务器只需要存储 $O(1/n)$ 的参数, 因此更新和优化的总时间就变成了 $O(m / n)$。 实际上,我们使用同样的机器作为 workers 和服务器。图 12.7.8 展示了这种设计。 特别是,确保多台机器在没有不合理延迟的情况下工作并非易事。我们省略了瓶颈的细节,只简要介绍同步和异步更新。
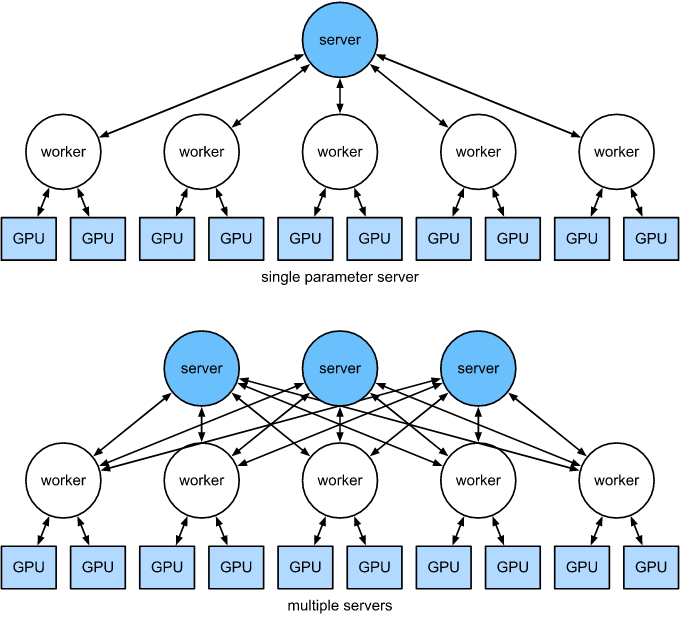
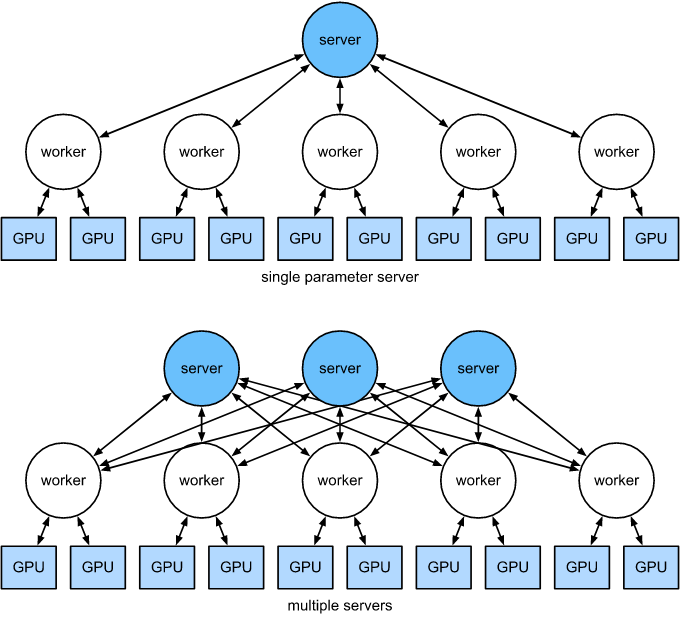
上面单个参数服务器是一个瓶颈,因为它的带宽是有限的。下面多个参数服务器聚合存储部分参数。
Key–Value Stores
在实践中实现分布式多GPU训练所需的步骤是非常重要的。这就是为什么使用通用抽象(即重定义更新语义的键值存储)是值得的。
在许多 workers 和 gpu 的计算梯度 $i$ 可以被定义为:
\[g_i = \sum_{k \in workers} \sum_{j \in GPUs} g_{ijk}\]其中 $g_{ijk}$ 是 woker $k$ 在GPU $j$ 上的梯度 $i$。 在这个操作的关键方面是它是 commutative reduction, 也就是说,它将许多向量转化为常量,而操作的顺序并不重要。这对于我们的目的是很好的,因为我们不需要(需要)细粒度控制何时接收梯度。此外, 注意这个操作独立于不同的 $i$。
这允许我们定义以下两个操作: push(累积梯度) 和 pull(检索聚合梯度)。 因为我们有许多不同的梯度集合(毕竟,我们有许多层),我们需要用一个键 $i$ 来索引这些梯度。 这非常像 key-value 存储。它们也满足许多类似的特性,特别是在跨多个服务器分布参数时。
键值存储的 push 和 pull 操作如下所述:
- push(key, value): 将一个特定的梯度(值)从 worker 发送到通用存储。在那里,值被聚合起来。
- pull(key, value): 从通用存储中检索聚合值。
通过隐藏所有关于同步的复杂性背后的一个简单的推拉操作我们可以解决统计建模者的担忧。而系统工程师需要处理这些分布式同步的复杂细节。
-
Previous
【深度学习】SCST:Self-critical Sequence Training for Image Captioning -
Next
【机器学习】Log Derivative Trick