Abstract
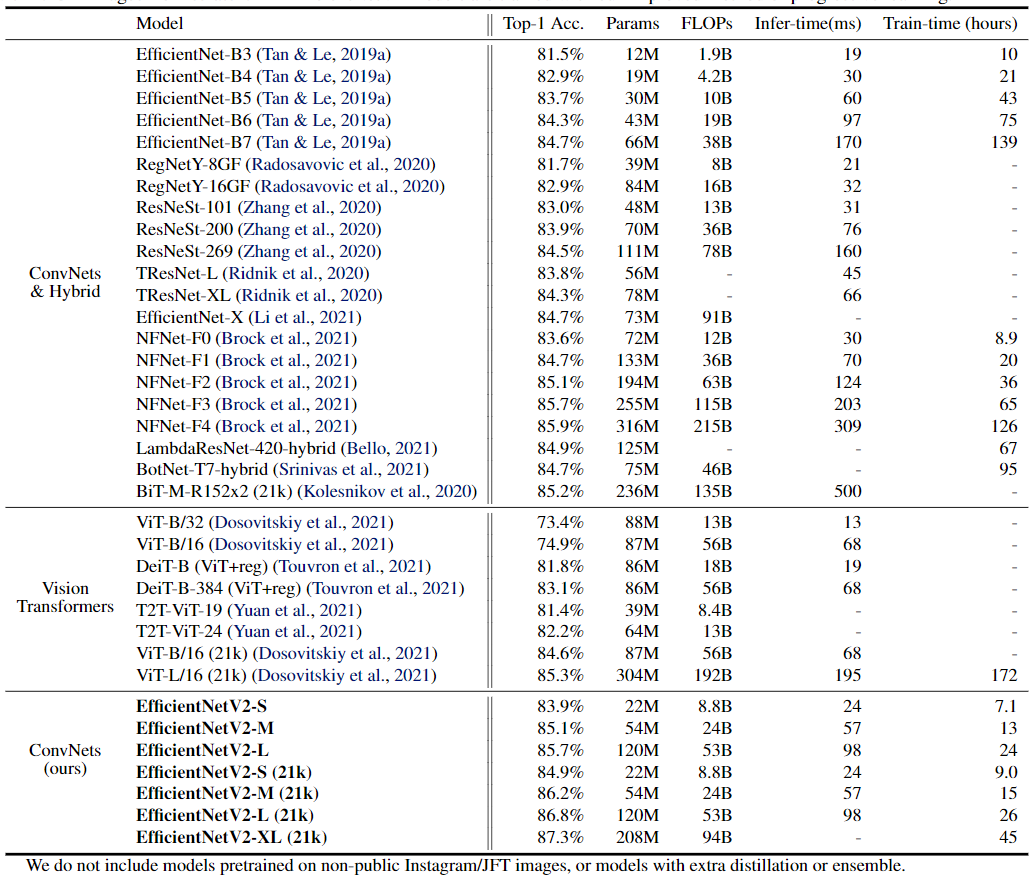
本文介绍了一种新的卷积网络——EfficientNetV2,它比以往的模型具有更快的训练速度和更好的参数效率。为了开发这些模型,我们使用了 training-aware NAS(neural architecture search) 和 scaling 的组合,以联合优化训练速度和参数效率。在新的搜索空间中加入了诸如 Fused-MBConv 这样的新操作,对模型进行了搜索。我们的实验表明,EfficientNetV2模型训练速度比最先进的模型快得多,同时体积小了6.8倍。
我们的训练可以通过在训练过程中逐步增大图像大小来进一步加快,但这往往会导致准确率下降。为了补偿这种精度下降,我们提出了一种改进的渐进学习方法,它可以随着图像大小自适应调整正则化(如数据增强)。
通过渐进式学习,我们的 EfficientNetV2 在 ImageNet 和 CIFAR/Cars/Flowers 数据集上明显优于以前的模型。通过在同样的ImageNet21k上进行预训练,我们的 EfficientNetV2 在 ImageNet ILSVRC2012 上达到 87.3% 的 top-1 准确率,比最近的ViT高出 2.0% 的准确率,同时使用相同的计算资源进行5 -11x倍的训练。
Main Results
Conclusion
本文介绍了 EfficientNetV2,这是一个用于图像识别的更小、更快的新神经网络系列。经过 training-aware NAS 和 model scaling 的优化,我们的 Efficient - NetV2 显著优于以前的模型,同时在参数方面更快、更有效。为了进一步提高训练速度,我们提出了一种改进的渐进学习方法,即在训练过程中联合增加图像大小和正则化。大量实验表明我们的 EfficientNetV2 在 ImageNet 和 CIFAR/Flowers/Cars 上取得了很好的结果。与 EfficientNet 和最近的作品相比,我们的 EfficientNetV2 训练速度提高了 11 倍,同时体积缩小了 6.8 倍
-
Previous
【机器学习】XGBoost: A Scalable Tree Boosting System -
Next
【深度学习】Enhance Multimodal Transformer With External Label And In-Domain Pretrain: Hateful Meme Challenge Winning Solution