ABSTRACT
我们引入一种新的用于视觉-语言任务的预训练表征方法, 叫做Visual-Linguistic BERT(VL-BERT)。
VL-BERT采用了简单但功能强大的Transformer模型作为主干,并对其进行了扩展,以视觉和语言嵌入特性作为输入。
其中,输入的每个元素要么是来自输入句子的一个单词,要么是来自输入图像的感兴趣区域(RoI)。
它被设计用于大多数视觉-语言下游任务。为了更好地利用通用表征,在大规模 Conceptual Captions 数据集和纯文本语料库上对VL-BERT进行预训练。
广泛的实证分析表明,预训练过程能够更好地整合视觉-语言线索,并有利于后续任务,如visual commonsense reasoning、 visual question answering和referring expres-sion comprehension。
值得注意的是,VL-BERT在VCR benchmark排行榜上获得了单模型的第一名。
Model Architecture
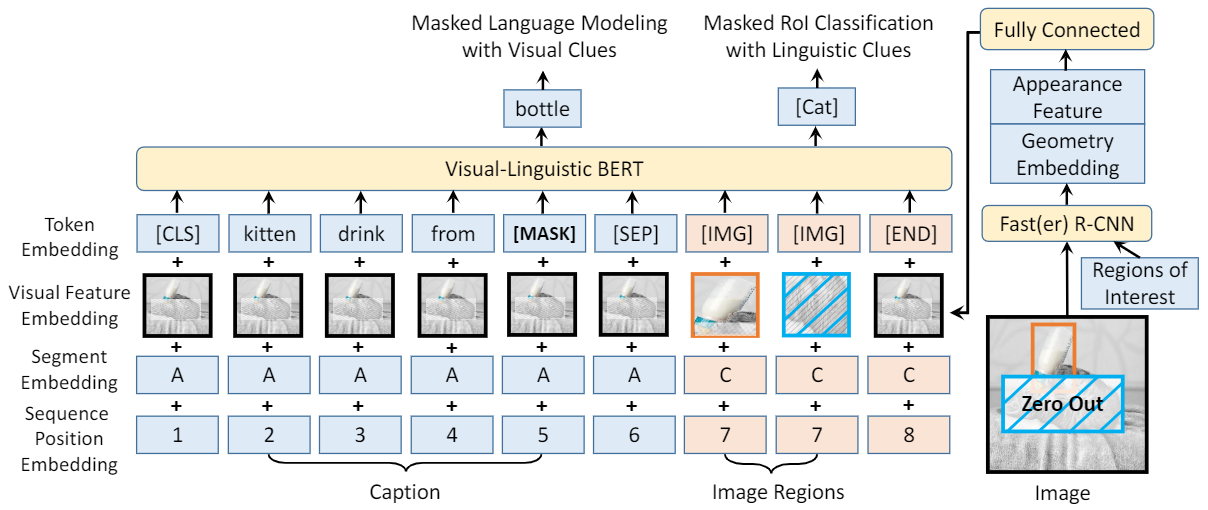
VL-BERT 将视觉和语言元素作为输入,
CONCLUSION
这篇文章开发了一种新的用于视觉-语言任务的预训练表征模型VL-BERT。
VL-BERT没有使用特定于任务的特殊模块,而是采用简单但强大的Transformer模型作为主干。
它在大规模Conceptual Captions数据集和纯文本语料库上预训练。
大量的实验分析表明,预训练过程可以更好地对齐 视觉-语言线索,从而有利于下游任务。
在未来希望寻求更好的预训练任务,这将有利于更多的下游任务。
-
Previous
【深度学习】Spatial As Deep: Spatial CNN for Traffic Scene Understanding -
Next
【深度学习】Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering