Distributed Attention for Grounded Image Captioning
研究了弱监督 grounded image caption 的问题。给定一副图像, 目标是自动生成一个句子来描述图像的上下文, 每个名词对应于图像中相应的区域。 由于缺乏明确的细粒度 region word对齐作为监督,这个任务是具有挑战性的。以往的弱监督方法主要是探索各种正则化方案来提高 attention accuracy。但是它们的表现远远不及全监督。一个被忽视的主要问题是, 生成 visually groundable words 的注意力可能只集中在最 discriminate 的部分, 而不能覆盖整个目标, 这个问题叫做partial grounding 问题。为此,在论文中提出了一种简单而有效的方法来缓解这一问题 。具体来说,设计了一个分布式注意力机制,当生成单词时, 强制网络聚合来自多个空间不同区域且语义一致的信息。因此, focused region proposals 的交集应该形成一个完全包含感兴趣目标的视觉区域。
研究了在没有 grounding annotations 的情况下生成具有准确 grounding regions 的 image captions 的问题。揭示了缓解 partial grounding 问题对 grounding performance 至关重要。提出了分布式注意力机制,强制网络在生成单词时将语义一致的不同区域聚合在一起。
Dual Graph Convolutional Networks with Transformer and Curriculum Learning for Image Captioning
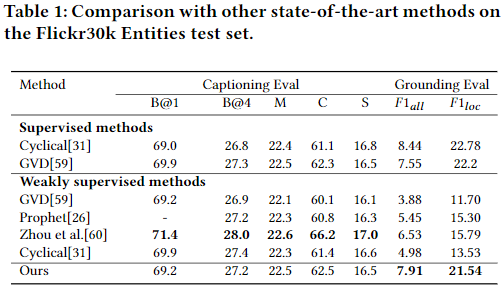
现有的 image captioning 方法只关注于理解单个图像中对象或实例之间的关系,而没有探索上下文图像之间存在的上下文关联。在这片文章中为 Image Caption 提出了带有transformer和 curriculum learning 的双向图卷积神经网路(Dual-GCN)。具体来说,不使用object-level GCN来捕获单一图像中目标对目标的空间关系,而是采用 image-level GCN来捕获相似图像提供的特征信息。设计良好的双向 GCN 可以使 Transformer 更好地理解图像中不同目标之间的关系,并充分利用相似图像作为辅助信息对图像进行合理的描述。同时,通过引入 cross-review 策略来决定 difficulty levels,采用 curricu-lum learning 作为训练策略,以提高模型的鲁棒性和泛化性。
提出一种使用 Curriculum Learning 作为学习策略 结合了 Dual-GCN 和 Transformer 的 image caption 模型。 由 object-level GCN 和 image-level GCN 编码的视觉特征被设计用来融合局部和全局视觉编码。Transformer 解码器能够理解提取的视觉特征生成合理的描述结果。 通过 cross-review 机制决定数据集的难度, 使用 curriculum learning 作为训练策略确保提出的模型以一种从易到难的方式训练。
Question-controlled Text-aware Image Captioning
对于带有多个 scene texts 的图像,不同的人可能对不同的文本信息感兴趣。现有的 text-aware image captioning 模型无法根据不同的信息需求生成不同的 captions。为了探索如何生成个性化的text-aware captions,定义了一个新的具有挑战性任务,即 Question-controlled 的 Text-aware Image captioning (Qc-TextCap)。该任务以问题为控制信号,需要模型来理解问题,找到相关的 scene texts,并用人类语言流利地将其与物体结合起来进行描述。基于两个现有的 text-aware captioning 数据集,自动构造了两个数据集 ControlTextCaps和 Con-trolVizWiz 来支持该任务。提出了一种新的 Geometry 与 Question Aware 模型(GQAM)。GQAM首先采用 Geometry-informed Visual Encoder 考虑空间关系来融合 region-leve object features 和 region-level scene text features。然后,设计了一个 Question-guided 编码器,为每个问题选择最相关的视觉特征。最后,GQAM使用Multimodal Decoder生成个性化的 text-aware caption。
帮助视障人士生成个性化的 text-aware captions, 提出了一个新的有挑战性的任务, 叫做 Question-controlled Text-aware Image Captioning(Qc-TextCap)。 因为它在交互上很方便, 使用关于 scene texts 中的问题来控制 text-aware caption 生成。Qc-TextCap任务需要模型来理解问题,找到相关的 scene texts 区域,并将答案与初始标题合并,以生成最终的 text-aware caption。为了支持这个任务,基于现有的 text-aware 标题数据集自动构造了 ControlTextCaps 和 ControlVizWiz 数据集。进一步提出了一个 Geometry 和 Question Aware 模型(GQAM),以逐步编码相关的视觉特征和文本特征。最后, 进一步证明了以问题作为控制信号的模型可以产生更丰富、更多样化的标题。
Similar Scenes arouse Similar Emotions: Parallel Data Augmentation for Stylized Image Captioning
Stylized image captioning 系统旨在生成一个不仅在语义上与给定的图像相关,而且还与给定的风格描述一致的描述。这个任务的最大挑战之一是缺乏足够的成对的 stylized 数据。许多研究关注的是无监督的方法,而没有从数据增强的角度考虑。这篇文章指出, 人们在类似的场景中可能会回忆起类似的情绪,并且经常用类似的风格短语表达类似的情绪,因此产生了数据增强想法。这篇文章提出了一个新的 Extract-Retrieve-Generate 数据增强框架,从小规模的 stylized 句子中提取风格短语,并将其 graft 到大规模的 factual captions 中。首先,设计了 emotional signal extractor 从小规模 stylized 句子中提取 style 短语。其次,构造了 plugable 的 multi-modal scene retriever,以检索由一对图像和它的stylized caption表征的场景, 它们和大规模 factual data 中的 query image 或 caption 相似。最后,基于相似场景的 style phrases 和当前场景的 factual description,构建 emotion-aware 的 caption 生成器,为当前场景生成流畅多样的 stylized captions 。大量的实验结果表明,该框架能够有效地缓解数据短缺问题。它还显著提高了几个现有的 image captioning 模型在监督和非监督设置下的性能,在句子相关性和风格方面都比最先进的 stylized image captioning 方法表现得更好。
这篇文章提出了一种新的 extract-retrieve-generate 数据增强框架,用于 stylized image captioning。该框架首先从已有的风格化句子中提取风格短语。然后,该框架通过 plugable 的 multi-modal scene retriever 进一步检索一组类似场景。该框架利用相似场景的 stylized captions 中的 style phrases,为大规模 factual corpus 中的图像 生成相应的 stylized captions。大量的实验结果表明,该框架能够有效地缓解数据匮乏问题。 它还显著提高了几种现有 image captioning 模型在有监督和无监督设置下的性能,大大优于最先进的 stylized image captioning 方法。
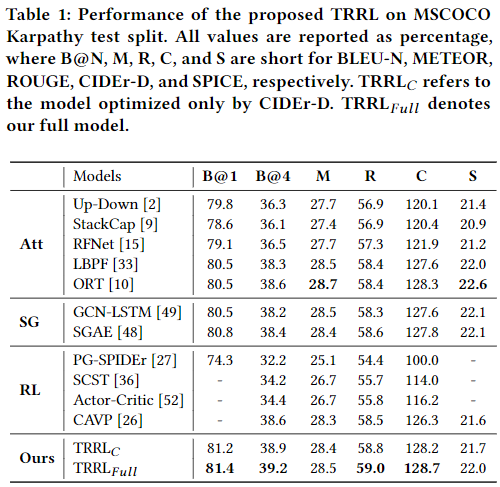
Triangle-Reward Reinforcement Learning: Visual-Linguistic Semantic Alignment for Image Captioning
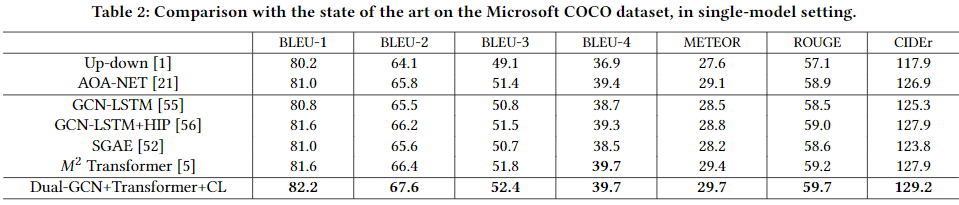
Image Captioning 是指在给定的图像中,生成一个由 sequential linguistic words 组成的句子,用来描述visual units(如物体、关系和属性)。大多数现有的方法依赖于流行的交叉熵(XE)函数的监督学习,将 visual units 转换为sequence of linguistic words。然而, XE 目标对 visual-linguistic 对齐不敏感, 不能判别惩罚 semantic inconsistency,缩小 context gap。为了解决这些问题,提出了 Triangle-Reward Reinforcement Learning(TRRL) 方法。TRRL以 scene graph ($\mathcal{G}$) 对象为节点,关系为边,分别表示图像、生成的句子和真实句子,并在训练过程中相互对齐。具体来说,TRRL 将 image captioning 表示为operative agents,其中第一个 agent 旨在从图像(I)中提取visual scene graph ($\mathcal{G}_{img}$),第二个 agent 将此 graph 翻译为句子(S)。为了判别惩罚 visual-linguistic inconsistency, TRRL 提出新的 triangle-reward function: 1)生成的句子及其所对应的真实句子分别被分解成linguistic scene graph ($\mathcal{G}_{sen}$) 和 真实 scene graph ($\mathcal{G}_{gt}$)。2) $\mathcal{G}_{img}$, $\mathcal{G}_{sen}$ 和 $\mathcal{G}_{gt}$ 配对计算语义相似度分数,通过这个语义相似度给各个 agent 分配 reward。同时,为了使训练目标对上下文变化敏感,提出了 node-level 和 triplet-level 评分方法来联合测量 visual-linguistic graph 的相关性。
这篇文章提出了 Triangle-Reward Reinforcement Learning(TRRL) 方法用于 image captioning,该方法由 multi-agent 网络和 triangle-reward 函数组成。与之前的方法相比,TRRL可以判别惩罚 visual-linguistic inconsistencyt 的不一致,从而实现 visual units 和 linguistic words 之间的显式语义对齐。特别地,TRRL 使用 scene graph 来分别表示图像、生成的句子和真实句子,这些句子相互对齐,按比例分配reward给agent。同时,为了使训练目标对上下文变化敏感,提出了 node-level 和 triplet-levels 评分方法,这两种方法联合测量了 visual-linguistic graph 的相关性,并有效地缩小了 context gap。
Direction Relation Transformer for Image Captioning
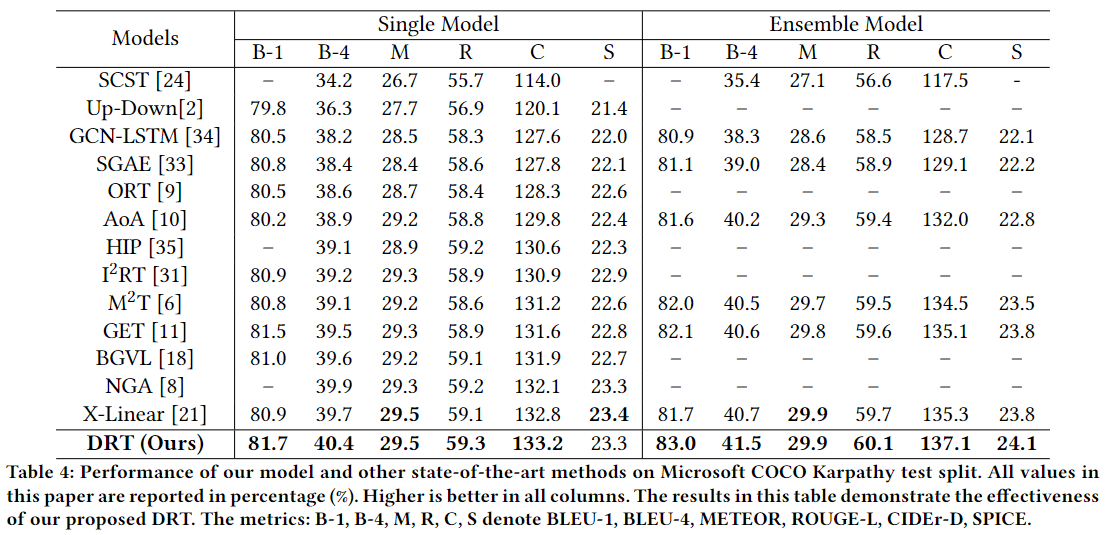
Image Captioning 是一项具有挑战性的任务,它结合了计算机视觉和自然语言处理来生成图像内容的文本描述。近年来,基于 Transformer 的编解码器结构在 image captioning 处理中取得了巨大的成功,该体系利用 multi-head attention mechanism 来捕获目标区域之间的上下文关系。但这类方法将区域特征视为 a bag of tokens ,而不考虑它们之间的方向关系,难以理解图像中物体之间的相对位置,难以有效生成正确的标题。这篇文章提出了一种新的 Direction Relation Transformer,将 relative direction embedding 加入到 multi-head 中,称为DRT,以改善视觉特征之间的方向感知。首先根据目标区域的位置信息生成 relative direction matrix,然后探索三种 direction-aware 的 multi-head attention形式,将 direction embedding 加入到 Transformer 架构中。
这篇文章提出了一种新的Direction Relation Transformer,可以有效地利用目标区域之间的相对方向关系,从而改进 image captioning。通过预先定义方向类别,从 bounding boxes 中提取高层次的方向语义,以全面理解复杂的视觉场景。此外,还探索了三种 Direction-Aware 的 Multi-Head Attention,将 relative direction embedding 加入到注意力模块中。
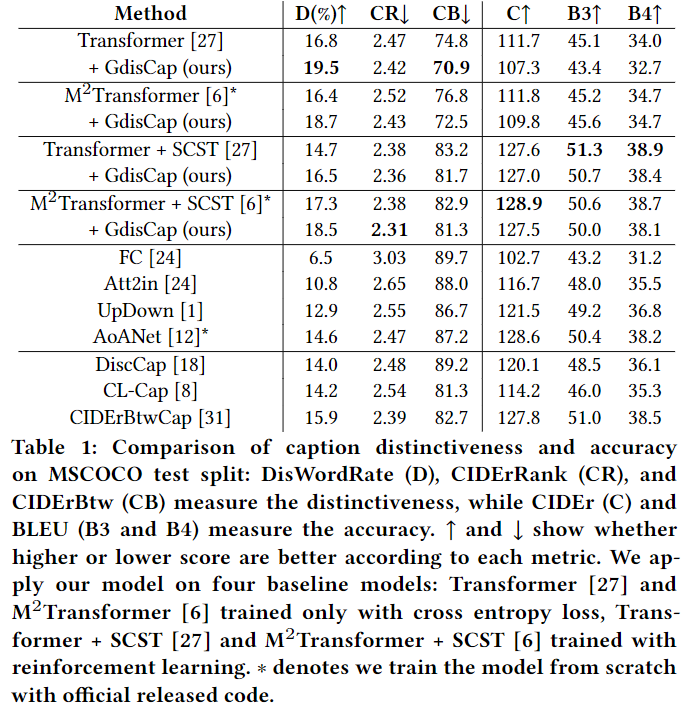
Group-based Distinctive Image Captioning with Memory Attention
利用自然语言描述图像被称为 image captioning,随着计算机视觉和自然语言生成技术的发展, image captioning 技术得到了不断的发展。虽然传统的 captioning 模型基于流行指标实现了高的准确性,即BLEU,CIDEr和SPICE,captions 区分目标图像和其它相似图像的能力还有待探索。为了生成独特的标题,一些先辈使用对比学习 或 重新加权真实的 captions。但是,一个相似图像组中的对象之间的关系(例如,同一相册或细粒度事件中的 items 或 properties)将被忽略。这篇文章使用一种 Group-based Distinctive Captioning Model (GdisCap)来提高 image captions 的 distinctiveness ,该模型将每幅图像与一个相似组中的其它图像进行比较,突出了每幅图像的唯一性。 特别地,提出了一种 group-based memory attention (GMA) 模块,该模块存储图像组中 unique 的物体特征(即与其他图像中的物体相似度低)。这些 unique 的物体特征在生成描述时被强调,从而产生更独特的captions。此外,在 ground-truth captions 中选择 distinctive 的词来监督语言解码器和GMA。最后,提出了一个新的评价指标 —— distinctive word rate(DisWordRate)来衡量 captions 的distinctiveness。
这篇文章研究了 image captions 的一个重要特性 – distinctiveness,它模仿了人类描述图像独特细节的能力,从而使 image captions 能够从其他语义相似的图像中区分出来。提出了一种 Group-based Distinctive Captioning 模型(GdisCap),该模型将目标图像中的物体与语义相似的图像中的物体进行比较,并突出了图像中独特的区域。此外,提出两个损失函数来训练所提出的模型: distinctive word loss 鼓励模型产生 distinguishing 的信息; memory classification loss 帮助 weighted memory attention 包含 distinct concepts。
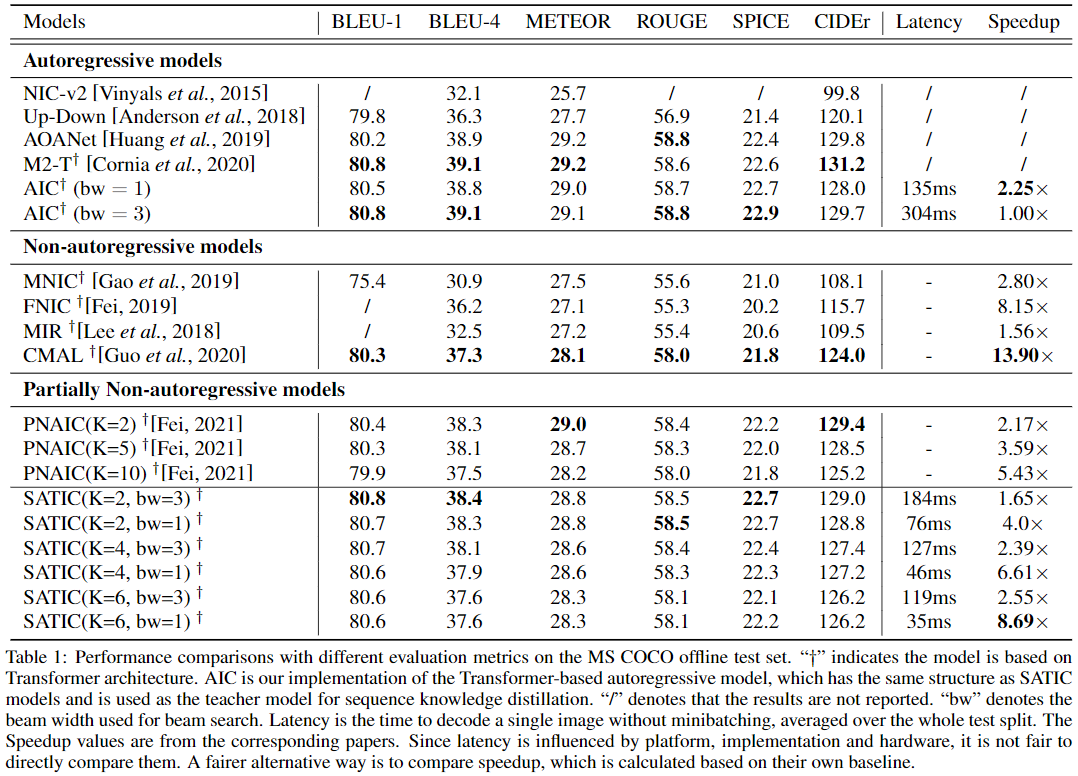
Semi-Autoregressive Transformer for Image Captioning
目前最先进的 image captioning 模型采用自回归解码器,即它们以之前生成的单词为条件来生成每个单词,这导致了推断过程中的严重 latency。为了解决这个问题,非自回归 image captioning 模型最近被提出,通过并行生成所有单词,显著加快了推理的速度。然而,这些非自回归模型由于过度消除了单词依赖,不可避免地会出现生成质量的下降。 为了在速度和质量之间做出更好的权衡,引入了一种 image captioning 的半自回归模型(SATIC),该模型在全局中保持了自回归特性,但在局部中并行生成单词。在 Transformer 的基础上,只需要进行少量的修改就可以实现SATIC。
这篇文章引入了一种半自回归的 image captioning 模型(简称SATIC),该模型在全局中保持了自回归特性,在局部中保持了非自回归特性。
Unifying Multimodal Transformer for Bi-directional Image and Text Generation
这篇文章研究的联合学习的 image-to-text 和 text-to-image 的生成,这是自然的双向任务。典型的现有工作为每个任务设计独立的 task-specific 的模型。这篇文章基于单个多模态模型来联合研究双向任务, 提出了一个统一的图像和文本生成框架。具体来说,将这两个任务描述为序列生成任务,其中将图像和文本表示为统一的 tokens 序列,Transformer学习 multimodal interactions 来生成序列。进一步提出 two-level granularity 特征表示和 sequence-level 训练来改进基于 transformer 的统一框架。
这篇文章提出了一个统一的 multimodal Transformer 用于双向 image-and-text 生成任务。与针对双向任务的两个单独模型的设计相比,所提出的方法降低了 task-specific 模型的昂贵设计成本,并优化了存储利用率。为了解决基于 Transformer 的图像和文本生成模型的挑战,设计了 two-level granularity 特征表示和 sequence-level 训练策略。two-level granularity 特征表示解决了特征离散过程中信息丢失的问题。sequence-level 训练策略解决了交叉熵训练引起的测试时误差累积问题。
-
Previous
【深度学习】Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering -
Next
【深度学习】CVPR2021:MultiModal 相关论文