Abstract
新的计算机视觉结构独占了聚光灯,但模型结构的影响经常与训练策略和 scaling 策略的同时变化耦合在一起。我们的工作回顾了经典的ResNet (He et al., 2015),并研究了这三个方面,试图解耦它们。令人惊讶的是,我们发现训练和 scaling 策略可能比结构更改更重要,而且,最终的ResNets符合最新的最先进的模型。我们证明了最佳的 scaling 策略依赖于训练模式,并提出了两种新的 scaling 策略: (1)可能发生过拟合的模式下的 scaling 模型深度(否则最好是宽度 scaling ); (2)以更慢的速度提高图像分辨率相比于(Tan & Le, 2019)。使用改进的训练和 scaling 策略,我们设计了一系列的ResNet架构, ResNet-RS, 它在TPU上比 EfficientNets 快1.7 - 2.7倍,而在ImageNet上达到类似的精度。在大规模的半监督学习设置中,ResNet-RS达到了86.2%的top-1 ImageNet准确率,同时比 EfficientNet-NoisyStudent 快4.7倍。训练技术提高了一系列下游任务(可与最先进的自监督算法相媲美)的迁移性能,并扩展到在 Kinetics-400 数据集上进行视频分类。
Introduction
视觉模型的性能是结构、训练方法和 scaling 策略的产物。然而,研究经常强调结构的变化。新的结构是许多进步的基础, 但往往与训练方法和超参数等其他关键细节变化(且不太公开)同时引入。此外,通过现代训练方法增强的新结构有时会与使用过时训练方法的旧结构进行比较(例如,使用ImageNet Top-1准确率为76.5%的ResNet-50 (He et al., 2015))。我们的工作解决了这些问题,并实证研究了训练方法和 scaling 策略对流行的ResNet结构的影响(He et al., 2015)。
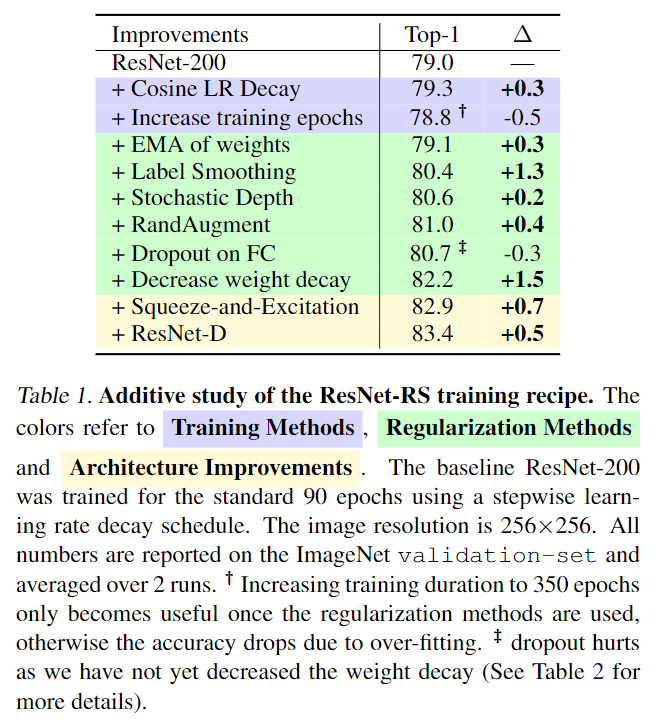
我们调研了了当今广泛使用的现代训练和正则化技术,并将它们应用于ResNets(图1)。在这个过程中,我们遇到了训练方法之间的相互作用,并且在与其他正则化技术结合使用时,显示了减少weight decay 值的好处。 表1中对训练方法的附加研究揭示了这些决策的显著影响: 通过改进的训练方法,top-1 ImageNet准确率为79.0%的标准ResNet提高到了82.2%(+3.2%)。通过两个很小但常用的结构改进(ResNet-D (He et al., 2018) 和 Squeeze-and-Excitation (Hu et al., 2018)),这一比例进一步提高到83.4%。 图1用 speed-accuracy Pareto 曲线跟踪了 ResNet 的改进过程。
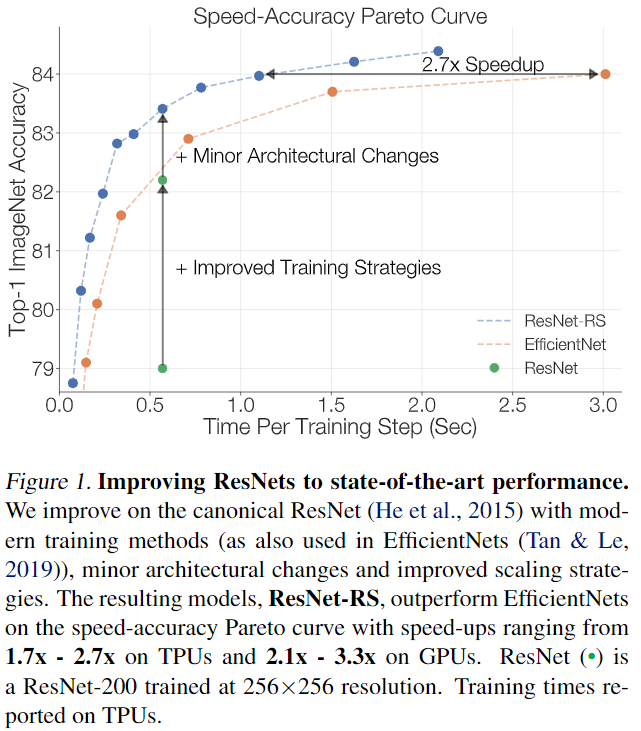
我们提供了 scaling 视觉结构的新视角和实用建议。之前的工作从小模型或从小数量的 epochs 推断 scaling 规则, 我们通过在整个训练期间(例如350个epoch而不是10个epoch)的各种尺度上详尽地训练模型来设计 scaling 策略。在这样做的过程中,我们发现了最佳 scaling 策略和训练策略之间的强依赖性(例如, epochs数量、模型大小、数据集大小)。
Conclusion
通过使用现代训练方法和改进的 scaling 策略来更新vision baseline,我们揭示了ResNet 结构非凡的持久性。简单的结构为最先进的方法设置了强大的基线。这些依赖关系在这些较小的机制中都被忽略了,导致了次优的 scaling 策略。我们的分析引入了新的 scaling 策略,总结为(1)在可能发生过拟合时 scaling 模型深度(否则 scaling 宽度更好) 和 (2)比之前的工作(Tan & Le, 2019)更慢地 scaling 图像分辨率。
-
Previous
【深度学习】Oscar:Object-Semantics Aligned Pre-training for Vision-Language Tasks -
Next
【深度学习】Swin Transformer: Hierarchical Vision Transformer using Shifted Windows