Abstract
在本文中,我们提出了Uformer,一种有效和高效的基于Transformer的架构,其中我们使用Transformer块构建一个层级编解码器网络来进行图像复原。Uformer有两个核心设计使它适合这个任务。第一个关键元素是 local-enhanced window Transformer 块,我们使用 non-overlapping window-based self-attention 来减少计算需求,并在前馈网络中使用深度卷积来进一步提高其捕获局部上下文的潜力。第二个关键因素是,我们探索了三种 skip-connection 方案,以有效地将信息从编码器传递到解码器。在这两种设计的支持下,Uformer具有很强的用于捕获对图像恢复有用依赖关系的能力。大量的图像恢复实验证明了Uformer在图像去噪、去噪、去模糊和去噪等方面的优越性。
Introduction
Uformer主要两个核心设计使得它适合于图像复原:
第一点是 local-enhanced windows Transformer。使用 non-overlapping window-based self-attention捕获长程依赖。self-attention 捕获局部依赖有局限性。在Transformer块 的 feed-forward 网络的两层 全连接之间使用卷积层更好地捕获局部上下文。
第二点是探索了 Transformer-based encoder-decoder 结构中, 如何取得更好的信息传递。 将encoder到decoder中传递信息的问题视为一个 self-attention 的计算, decoder 中的特征视为 queries, 寻找与encoder的特征之间的关系, encoder 的特征视为 key 和 value。 第一种方法是在decoder的transformer块中加入了一个 self-attention 模块, 使用来自 encoder 的特征作为key和value, decoder的特征作为 query。第二种方法是同时使用 encoder 和 decoder 的特征作为 key 和 value, 使用 decoder 的特征作为 query。
Method
Overall Pipeline
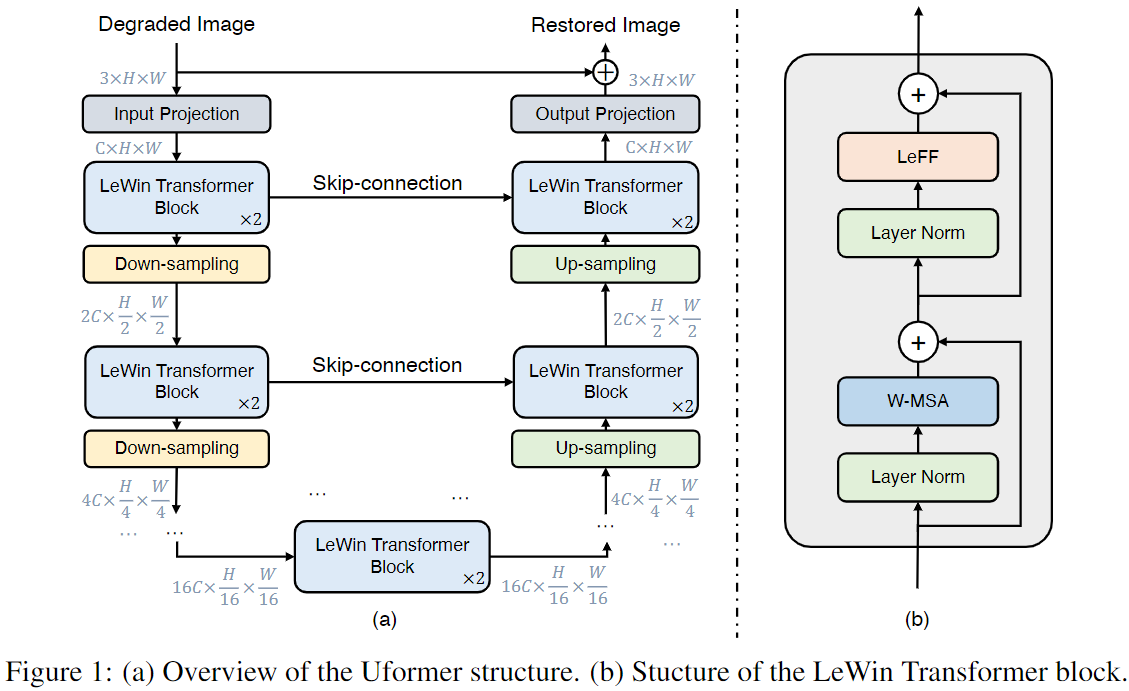
给定退化图像 $I \in \mathbb{R}^{C \times H \times W}$, Uformer首先使用 $3 \times 3$ 的带有LeakyReLU的卷积层提取低层特征 $X_0 \in \mathbb{R}^{C \times H \times W}$。 接下来, 特征 $X_0$ 经过 $K$ 个编码器阶段。 每个阶段包含几个叠在一起的所提出的 LeWin Transformer 块 和 下采样层。LeWin Transformer 块利用 self-attention 机制捕获长程依赖, 并且通过在特征图上使用 non-overlapping windows 的 self-attention 减少计算成本。在下采样层中, 我们首先将拉平的特征转换为 2D 空间特征图, 然后降采样特征图, 并且使用步长为 2 的 $4 \times 4$ 卷积将通道翻倍。例如, 输入特征图为 $X_0 \in \mathbb{R}^{C \times H \times W}$, 第 $l$ 阶段的编码器产生特征图 $X_l \in \mathbb{R}^{2^lC \times \frac{H}{w^l} \times \frac{W}{2^l}}$。
然后, 在encoder的末端添加一个 bottleneck stage, 它由 LeWin Transformer blocks 堆叠在一起组成。在这个阶段,得益于层次结构,Transformer块捕获更长的依赖(甚至是全局的,当窗口大小等于特征图大小时)。
对于图像重构, 提出的解码器包含 K 个阶段。每个阶段包含一个上采样层和堆叠在一起的LeWin Transformer blocks。 使用步长为2的 $2 \times 2$ 卷积上采样。然后将上采样的特征和 encoder 通过skip-connection的相关特征作为 LeWin Transformer blocks 的输入。在 K 个阶段之后, 将拉平的特征变为 2D 特征图 并且用 $3 \times 3$ 卷积层得到残差图像 $R \in \mathbb{R}^{3 \times H \time W}$。最终恢复图像由 $I’ = I + R$ 得到。 在我们的实验中, 设置 $K = 4$ 并且每个阶段包含两个 LeWin Transformer blocks。 使用 Charbonnier loss:
\[\mathcal{l}(I', \hat I) = \sqrt{\| I' - \hat I \|^2 + \epsilon^2}\]其中 $\hat I$ 是 ground-truth 图像, $\epsilon = 10^{-3}$。
LeWin Transformer Block
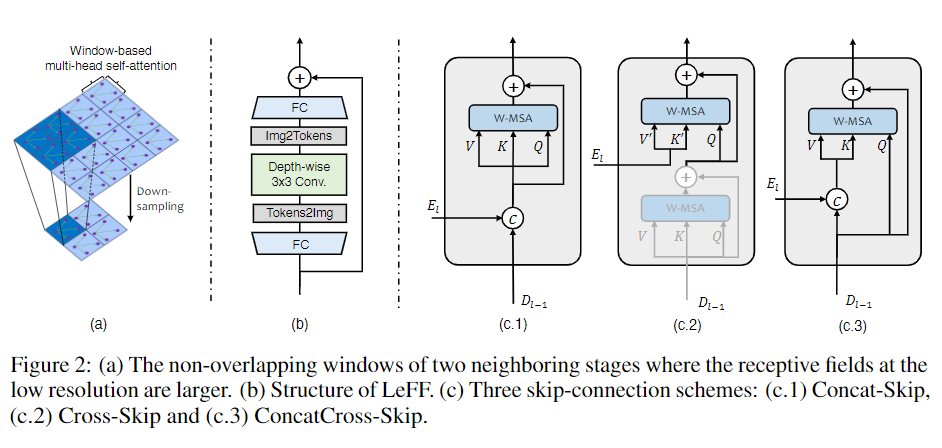
LeWin Transformer 包含两个核心设计:
- non-overlapping Window-based Multi-head Self-Attention (W-MSA)
- Locally-enhanced Feed-Forward Network (LeFF).
Window-based Multi-head Self-Attention (W-MSA): 我们不像普通Transformer 那样使用全局 self-attention,而是在 non-overlapping local windows 中执行 self-attention,这大大降低了计算成本。给定 2D 特征图 $X \in \mathcal{R}^{C \times H \times W}$, 将 $X$ 拆分成窗口大小为 $M \times M$ 的非重叠窗口, 然后从每个窗口 $i$ 得到得到拉平并转置的特征 $X^i \in \mathbb{R}^{M^2 \times C}$, 然后在每个窗口拉平的特征上做 self-attention。 假设 head 的数量为 $k$ 并且 head dimension 为 $d_k = C / k$。 在 non-overlapping windows 中计算第 $k$ 个 head 的 self-attention 可定义为:
\[X= {X^1, X^2, ..., X^N}, N = HW/M^2 \\ Y_k^i = Attention(X^iW_k^Q, X^iW_k^K, X^iW_k^V), i=1, ..., N \\ \hat X_k = {Y_k^1, Y_k^2, ..., Y_k^M}\]此外还在注意力模块中使用相对位置编码, 因此注意力可以被计算为:
\[Attention(Q, K, V) = SoftMax(\frac{QK^T}{\sqrt{d_k}} + B) V\]其中 B 是相对位置偏置,它的值来自可学习参数 $\hat B \in \mathbb{R}^{(2M -1) \times (2M - 1)} $。
Window-based self-attention 相比于全局 self-attention 显著减少了计算成本。 给定特征图 $X \in \mathbb{R}^{C \times H \times W}$, 计算复杂度从 $O(H^2W^2C)$ 减少到 $O(\frac{HW}{M^2}M^4C) = O(M^2HWC)$。 由于我们将Uformer设计成一个层级结构,我们 window-based 的低分辨率特征图的 self-attention 可以在更大的感受野上工作,足以学习长程依赖。
Locally-enhanced Feed-Forward Network (LeFF). 标准Transformer中的Feed-Forward Network(FFN) 无法有效利用局部上下文, 但是临近的像素对于图像复原任务是十分重要的。我们为 Transformer FFN 中增加了一个 depth-wise 卷积块。 首先对每个token使用线性投影层增加它的特征维度。 接下来将 tokens 拉成 2D 特征图 并使用 $3 \times 3$ depth-wise 卷积捕获局部信息。然后我们通过另一个线性层 将特征拉平为 tokens 并减少通道数 以 匹配输出通道的维度。 使用GELU 作为每个线性层和卷积层的激活函数。
Variants of Skip-Connection
Concatenation-based Skip-connection (Concat-Skip): 首先按通道拼接第 $l$ 阶段拉平特征 $E_l$ 和 第 $l-1$ 阶段解码器特征 $D_{l-1}$。 然后在解码阶段 将拼接的特征输入第一个 LeWin Transformer block 的 W-MSA 组件。
Cross-attention as Skip-connection (Cross-Skip):按照 Transformer 中 的解码器机构设计了 Cross-Skip。 首先在每个解码阶段第一个 LeWin Transformer block 中加入一个额外的注意力模块。 第一个 self-attention 模块用来从解码器特征 $D_{l-1}$ 寻找 pixel-wisely 的 self-similarity, 第二个 attention 模块将编码器特征 $E_l$ 作为 keys 和 values, 使用第一个 self-attention 模块输出的特征作为 queries。
Concatenation-based Cross-attention as Skip-connection (ConcatCross-Skip): 拼接编码器特征 $E_l$ 和 解码器特征 $D_{l-1}$ 作为 keys 和 values,使用 decoder 的特征作为 queries。
Conclusions
这篇文章我们通过引入 Transformer 块提出一种用于图像复原的可替换结构。 与现有的基于CNN的结构相比, 我们的 Uformer 主要建立在 LeWin Transformer block 上, 它不仅能够处理局部信息而且可以有效地捕获长程依赖。为了探索如何在编码器-解码器结构中实现更好的信息传递,我们进一步研究了 Uformer 中三种不同的 skip-connection 方案,取得了有竞争力的结果。
Limitation and Broader Impacts.: 得益于提出的结构, Uformer 在大量的图像复原任务(image denoising, deraining, deblurring, and demoireing)上取得了 SOTA 性能。我们还没有测试过 Uformer 用于更多的视觉任务,如 image-to-image trans-lation ,image super-resolution 等等。同时,我们也注意到滥用图像f复原技术带来的一些负面影响。例如,在监控中恢复的图像可能会导致人的隐私问题。同时,该技术可能会破坏摄像机识别和多媒体版权的原始模式,影响图像取证的真实性。
-
Previous
【深度学习】Swin Transformer: Hierarchical Vision Transformer using Shifted Windows -
Next
【深度学习】Masked Autoencoders Are Scalable Vision Learners