W&B 是什么?
Weights & Biases (W&B) 是一套帮助我们更快建立更好的模型的机器学习工具。
它有以下两个特点:
- Dashboard: 用于追踪实验
- Artifacts 记录数据集和模型的版本
Dashboard
Databoard 有以下的优势:
- 记录指标:实时跟踪模型性能,并立即找到存在问题地方。
- 可视化结果: 可视化 graphs, images, videos, audio, 3D objects 等等
- 随时随地训练:W&B 以 dashboard 为核心, 无论在哪里训练, 所有的结果都会记录在同一个地方
- 便于组织:W&B 可以搜索、过滤、排序、分组实验数据, 可以为不同的任务比较不同的模型并且找到表现最好的模型。
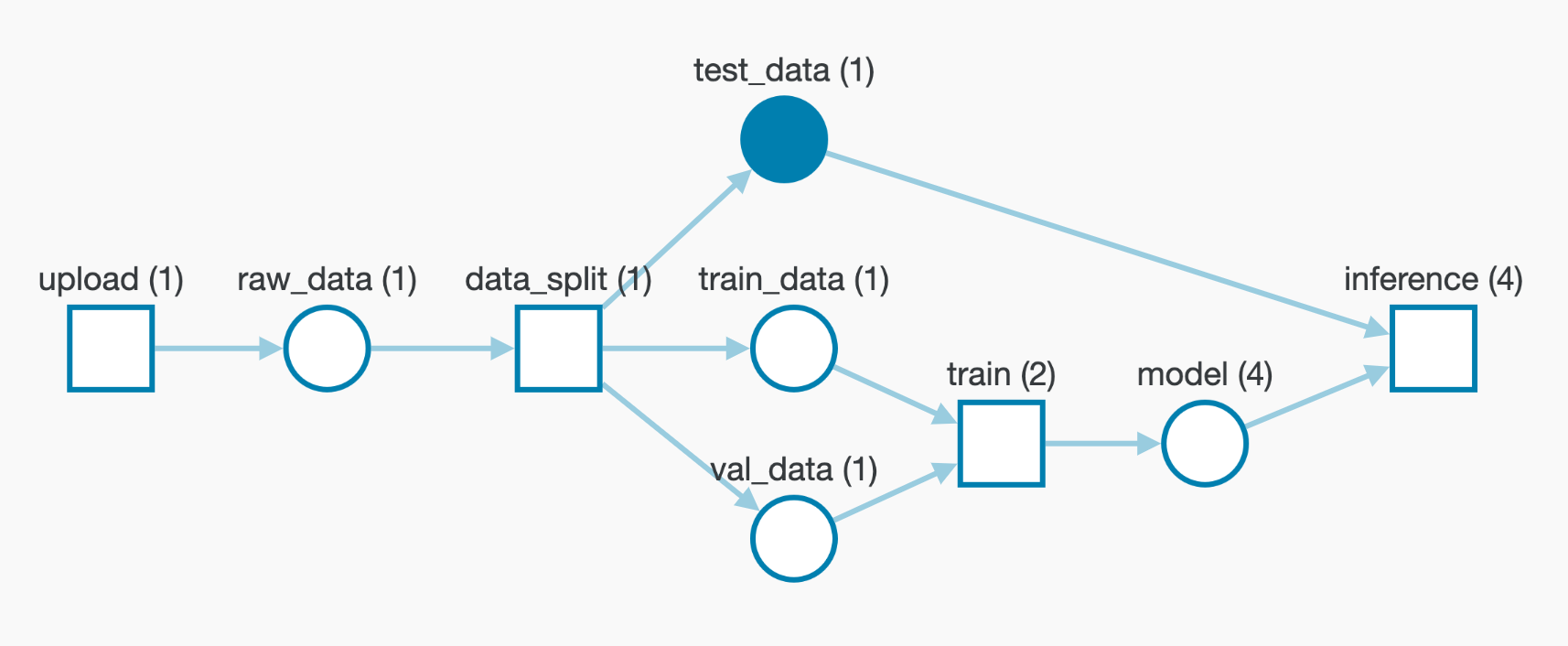
Artifacts (dataset versioning)
使用 W&B Artifacts 可以记录pipline中的数据集、模型、依赖和结果的各种版本。
可以将 Artifact 想象一个带有版本控制的数据文件夹。 一旦在 Artifact 保存, 所有的修改都会自动被记录, 给你一个完成的改动历史。
设置 W&B
安装wandb
1
pip install --upgrade -q wandb
import wandb 并 log in
你需要一个唯一的 API key 登陆 Weights & Biases。
- 在 https://wandb.ai/site 注册免费的账户
- 在 https://wandb.ai/authorize 得到 API key
在kaggle kernel 中有两种方式登陆:
wandb.login(), 它会要求输入 API key, 复制粘贴即可- 使用 kaggle secrets 存储 API key 并且使用以下代码段登陆。
1
2
3
4
5
6
7
8
9
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
# I have saved my API token with "wandb_api" as Label.
# If you use some other Label make sure to change the same below.
wandb_api = user_secrets.get_secret("wandb_api")
wandb.login(key=wandb_api)
1
2
3
4
import wandb
from wandb.keras import WandbCallback
wandb.login()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 1. Import other dependencies
import tensorflow as tf
print(tf.__version__)
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_addons as tfa
import os
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
1
2
3
4
5
6
7
8
# 2. Set the random seeds
def seed_everything():
os.environ['TF_CUDNN_DETERMINISTIC'] = '1'
np.random.seed(hash("improves reproducibility") % 2**32 - 1)
tf.random.set_seed(hash("by removing stochasticity") % 2**32 - 1)
seed_everything()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 3. Set hyperparameters
TRAIN_PATH = '../input/resized-plant2021/img_sz_256/'
AUTOTUNE = tf.data.experimental.AUTOTUNE
CONFIG = dict (
num_labels = 6,
train_val_split = 0.2,
img_width = 224,
img_height = 224,
batch_size = 64,
epochs = 10,
learning_rate = 0.001,
architecture = "CNN",
infra = "Kaggle",
competition = 'plant-pathology',
_wandb_kernel = 'ayut'
)