On the Role of Scene Graphs in Image Captioning
Abstract
Scene graphs 表示图像中的语义信息, 他可以帮助 image cationing 系统产生更多描述性的输出, 而不仅仅使用图像作为上下文。最近的 captioning 方法依赖于 ad-hoc 方法获取图像的 graph。然而,这些 graph 引入了噪声, parser 的错误对 captioning 准确性的影响尚不清楚。 在这项工作中, 调研了 Scene Graph 在多大程度上可以帮助 image captioning。 结果表明, 最先进的 scene graph parser 几乎可以像 ground-true graph 一样帮助captioning提高性能, 这表明目前的瓶颈更多地存在于 captioning 模型, 而不是 scene graph parser 的性能上。
Conclusion
这篇文章提出了一种新的 image captioning 框架, 该框架融合了SOTA scene graph parser Factorizable-Net 的 scene graph 特征。 特别地, 研究了将图卷积编码的 relation-aware 的 scene graph 特征 与 区域级的特征集成的问题, 以提高 image captioning 性能。
Auto-Encoding Scene Graphs for Image Captioning
Abstract
我们提出了 Scene Graph Auto-Encoder (SGAE),将 language inductive bias 整合到encoder-decoder image captioning 框架中,以获得更 human-like 的 captions。直觉上, 我们人类在固定搭配和上下文推理之中使用 inductive bias。 例如, 当我们看到 “person on bike” 的关系, 我们很自然地会想到替换 “on” 为 “ride”, 并且推理出 infer “per-son riding bike on a road”, 即便 “road” 并不明显出现。因此,利用这种 bias 作为一种语言先验,有望帮助传统的编码器-解码器模型不会过拟合数据集的 bias,并专注于推理。特别地, 我们使用 scene graph —— 一个有向图 ($\mathcal{G}$) ,其中一个目标节点由形容词节点和关系节点相连——来同时表示图像($\mathcal{T}$)和句子($\mathcal{S}$)复杂的结构化布局。在文本域, 我们使用SGAE学习一个字典 $(\mathcal{D})$, 它帮助以 $\mathcal{S} \rightarrow \mathcal{G} \rightarrow \mathcal{D} \rightarrow \mathcal{S}$ 流程重构句子, 其中 $\mathcal{D}$ 编码了所需的语言先验; 在 vison-language 域,使用共享的 $\mathcal{D}$ 以 $\mathcal{I} \rightarrow G \rightarrow D \rightarrow S$ 指导 encoder-decoder。借助 scene graph 表征和共享字典, inductive bias 是跨域的。
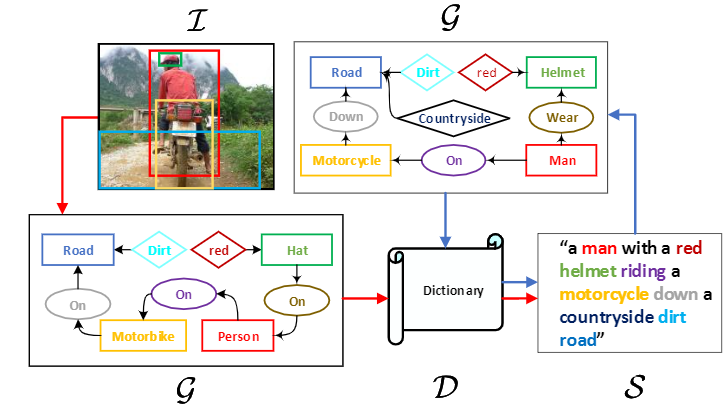
解释 auto-encoding scene graphs (蓝色箭头) 到 传统 encoder-decoder 框架的 image captioning(红色箭头) , 其中 language inductive bias 被编码为可训练的共享字典。 单词颜色对应图像和句子 scene graphs 中的节点。
Conclusions
这篇文章提出加入 language inductive bias —— 更human-like language generation的先验 —— 到之前的 encoder-decoder image captioning 框架。特别地, 我们提出一种新的无监督学习方法: Scene Graph Auto-Encoder (SGAE), 编码 inductive bias 为一个字典, 这个字典可以共享为语言生成的 re-encoder,并且可以显著提高encoder-decoder 的性能。
Auto-Parsing Network for Image Captioning and Visual Question Answering
Abstract
这篇文章提出一种 Auto-Parsing Network (APN) 来发现和挖掘输入图像的 hidden tree structures 以提高 Transformer-based vision-language 系统的有效性。具体地说, 在每个 self-attention 层上增加一个由 attention operations 参数化的 Probabilis-tic Graphical Model (PGM) 以加入稀疏性假设。使用这个 PGM 将输入序列分成几个 clusters。 每个cluster 可以被视为内部 entities 的 parent。 通过将这些受PGM约束的 self-attention 层叠加,低层的 cluster 组成一个新的序列, 而上层的PGM将进一步分割该序列。通过迭代方法可以隐式解析出一个 sparse tree, 这个树的层次化知识可以融合进 transformed embeddings, 它可以用来解决 vision-language 任务。具体来说,我们展示了我们的APN可以在两个主要的视觉语言任务中增强基于Transformer的网络: Captioning 和 VQA。 此外, 这篇文章还提出了一种基于概率的 PGM 解析算法, 通过它我们可以在推理时发现输入的隐含结构。
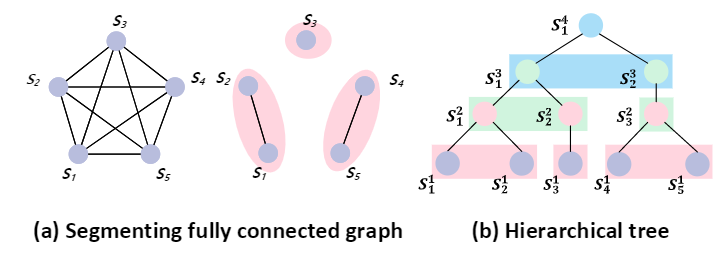
(a) 经典的的 self-attention 和 Probabilistic Graphical Model (PGM) 约束的 self-attention 有不同的 graph 先验。左边的经典的self-attention对一个 graph 中的两个节点之间都建立连接, 是一种全连接 graph。 右边是带有 PGM 约束的graph, 五个节点被分割成三个 clusters。 (b) 通过堆叠 PGM 约束的 self-attention 层, 层次化的树可以自动构建。 因此我们叫做我们的网络 Auto-Parsing Network (APN)。
Auto-Encoding Scene Graphs
Dictionary
我们引入如何学习字典 $\mathcal{D}$ 并且使用它重编码 $\hat \mathcal{X} \leftarrow R(\mathcal{X}; D)$。 主要的灵感来自被广泛用于QA、VQA,以及 one-shot classification 的使用一个 working memory 提供基于动态知识的 run-time inference。 $\mathcal{D}$ 的目标是将 language inductive bias 嵌入语言组合中。因此, 我们提出将字典学习放在句子自重构的框架中。将 $\mathcal{D}$ 表示为一个 $d \times K$ 的矩阵 $D = {d_1, d_2, …, d_k}$。 $K$ 在实现时设为 10000。 给定一个词向量 $x$, 重构函数 $R_\mathcal{D}$ 可以公式化为:
\[\hat x = R(x; \mathcal{D}) = D \alpha = \sum_{k=1}^K \alpha_k d_k\]Conclusion
这篇文章在 Transformer self-attention 层上增加了一个 Probabilistic Graphical Model (PGM), 它将稀疏假设增加入了原始的全连接注意力。 这样可以避免琐碎的全局依赖关系, 并且可以发现和利用局部上下文。此外,我们将受约束的 self-attention 层堆叠起来, 并在其上增加层次约束, 这样可以通过隐式解析得到一颗树。这样,模型就可以在端到端训练期间无监督地解析树。文中还提出一种树解析算法, 利用计算得到的 PGM 概率来提取hidden trees。 因此, 我们可以求出每个样本的 hidden structure。 在 Captioning 和 VQA 上提出两种不同的 APNs。