Abstract
提出一种Scene Graph Auto-Encoder 将语言归纳偏置引入 Image Captioning。
语言归纳偏置指, “person on bike” 这种句子, 我们会将 “on” 推理为 “ride”, 并且推理出 “person riding bike on a road”。
使用 Scene Graph 同时表示 image (I) 和 sentence (S) 的复杂结构。
在文本域, 使用 SGAE 学习一个字典 D, 它以 S -> G -> D -> S 的流程重构 sentence, 其中 D 编码我们所需要的语言先验, 即语言归纳偏置。
在 vision-language 域, 我们使用共享的 D 引导 I -> G -> D -> S 流程。 得益于 Scene Graph 表征 和 共享字典, 归纳偏置可以跨域迁移。
Conclusion
为Image Captioning 模型引入一种语言归纳偏置。
提出一种 Scene Graph Auto-Encoder(SGAE) 无监督学习方法, 其将归纳偏置编码为一个字典。
Network Architecture
在此,我们详细介绍了模型中所有组件的网络结构,包括图卷积网络(GCN)、多模态图卷积网络(MGCN)、字典和解码器。
Graph Convolutional Network
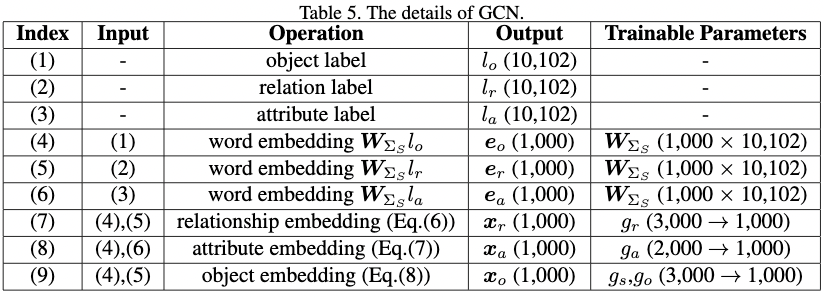
在主文4.2节中, 给定一个sentence scene graph, 我们展示了如何使用GCN计算三个 embeddings, 这个GCN的操作列成了表5。
在表5的 (1) 和 (3) 中, 目标标签 $l_o$, 关系标签 $l_r$, 以及属性标签 $l_a$ 都是 one-hot 向量。词向量矩阵 $W_{\Sigma_S } \in \mathbb{R}^{1000 \times 10102}$ 用于将这些 one-hot 向量映射为在表5(4) 到 (6) 的连续的向量空间。$W_{\Sigma_S}$ 的第二个维度是在所有sentence scene graph中的目标、关系和属性种类的总数。
对于 表5(7) 到 (9) 中的 $g_r$, $g_a$, $g_o$ 和 $g_s$, 他们都是有着相同结构的独立参数: 一个全连接层后接一个 ReLU。 标记 $g_r$($D_{in} \rightarrow D_{out}$) 表示输入维度是 $D_{in}$, 输出维度是 $D_{out}$。
Multi-modal Graph Convolutional Network
在主文 5.1 节中, 我们简短讨论了 MGCN, 表6 列出了它的细节。 除了目标、关系和属性外, MGCN 的输入还包括目标和关系的 RoI Features, 如表6 (1) 到 (5)。RoI Feature 从一个预训练的 Faster RCNN 提取, $v_r$ 是覆盖了 “subject” 和 “object” 区域的池化的特征。
表6(6) 到 (8) 中的词嵌入矩阵是 $W_{\Sigma_I} \in \mathbb{R}^{1000 \times 472}$ , 它和GCN 中用到的不一样。 表6(9)到(11), 使用特征融合操作以融合词嵌入和视觉特征。
与主文中的等式 (6) 和 等式(8) 比较, MGCN对计算关系、属性和目标嵌入有以下更改: 词嵌入 $e$ 替换为 融合嵌入 $u$; $g$ 由 $f$ 替代, 这是一个一层的全连接层接着一个 ReLU。 有了这些修改, 我们将MGCN三个嵌入的计算公式化为:
Relationship Embedding $v’{r{ij}}$:
\[v'_{r_{ij}} = f_r(u_{o_i}, u_{r_{ij}}, u_{o_j})\]Attribute Embedding $v_{a_i}’$:
\[v_{a_i}' = \frac{1}{Na_{i}}\sum_{i=1}^{Na_{i}}f_a(u_{o_i}, u_{a_{i, l}})\]Object Embedding $v_{o_i}’$:
\[v_{o_i}' = \frac{1}{Nr_i}[\sum_{o_j \in sbj(o_i)} f_s (u_{o_i}, u_{o_j}, u_{r_{ij}}) + \sum_{o_k \in obj(o_i)}f_o(u_{o_k}{, u_{o_i}, u_{r_{k_i}}})]\]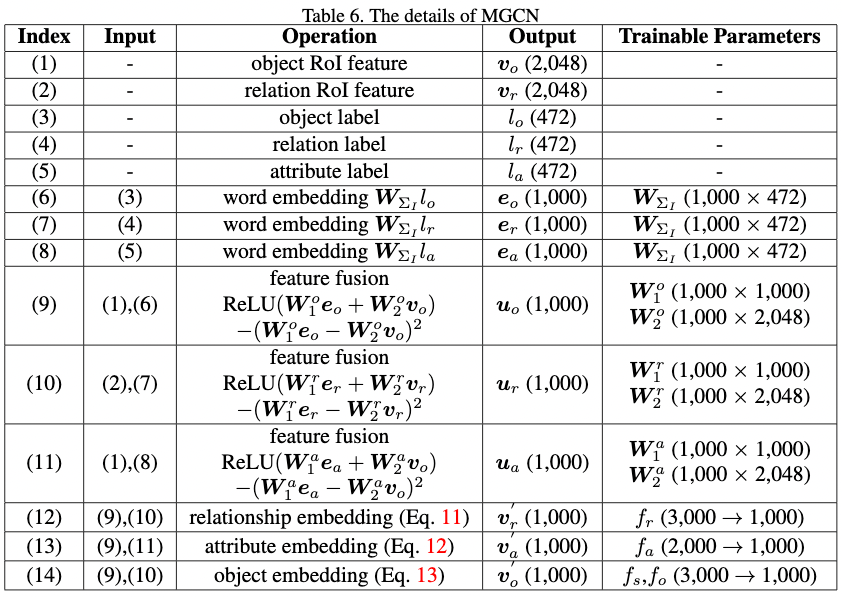
Dictionary
4.3节中的重编码器用于从索引向量 $x$ 和 一个字典 $D$ 中重编码一个新的表征 $\hat x$, 如表7所示的操作。分别如表 7(2) 和 (3)所示, 给定一个索引向量 $x$, 我们首先对x 和 $D$ 之间的每个元作素内积,然后使用 softmax 规范化计算的结果。 最后, 重编码的 $\hat x$ 对 $D$ 中的每个原子加权求和, $\sum_{k=1^K} \alpha_k d_k$, $K$ 的大小为 10000.
Decoders
我们使用语言解码器设置主文中的等式(4) 和 等式 (5)的两个解码器 。 两个解码器都有相同的结构, 如表8所示, 除了输入的embedding不一样。为了方便, 我们引入了编码器的通用结构, 而不区分等式 (4) 和等式(5), 然后在这节的末尾详细的解释他们的不同。
decoder 的实现包括两个 LSTM 层, 以及一个注意力模块。 第一个LSTM的输入包括三项的的拼接: 词嵌入向量 $W_\Sigma w_{t-1}$, 嵌入集合 $\bar z$ 的平均池化, 以及第二个 LSTM 的输出 $h_{t-1}^2$。 因为它们可以提供丰富的上下文信息, 因此我们使用它们作为输入。
然后, 一个由$LSTM_1$ 创建的索引向量 $h_{t-1}^2$如表8(7) 所示, 它会通过注意力模块来指导解码器将注意力放在合适的 $Z$ 的embedding上。给定 $Z$ 和 $h_{t-1}^1$, 表8(8) 和 (9) 的公式可以用来计算 $M$ 维的注意力分布 $\beta$, 然后我们可以通过 (10) 加权求和创建一个 attended embedding $\hat z$。 通过输入 $\hat z$ 和 $h_{t-1}^1$ 到 $LSTM_2$ 并且使用 (11) 到 (13), 可以得到词分布 $P_t$ 用以在时间步 $t$ 采样一个词。
对于等式(4) 和 等式(5) 中的两个解码器, 他们的不同在于使用的输入的 embedding 集合 $Z$ 不同。 在 SGAE 中(等式(5)), $Z$ 被设置为 $\hat X$。 而 SGAE-based encoder-decoder(等式(4)), 我们有一个小的修改, 向量 $z$ 被设置为 $z = [v’, \hat v]$, 其中 $v’ \in \mathcal{V}’$($\mathcal{V}’$ 是 5.1 节中的 scene graph -modulated 特征集合), $\hat v \in \mathcal{\hat V}$($\mathcal{\hat V}$ 是 5.1 节中的重编码特征)。
Details of Scene Graph
Sentence Scene Graph
对于每个句子, 使用 SPICE 解码得到它的scene graph。 我们通过删除在所有解析scene graph 中出现少于10个的目标、关系和属性来过滤它们。过滤之后,还剩下5364个目标、1308个关系和3430个属性。我们将它们合在一起并且使用表5中的词向量矩阵 $W_{\Sigma_S}$ 将节点标签转换为连续的向量表示。
Image Scene Graph
与sentence scene graph 相比,image scene graph的解析更复杂,我们使用Faster-RCNN作为目标检测器对目标进行检测和分类,使用MOTIFS关系检测器对目标之间的关系进行分类,使用一个简单的属性分类器对属性进行预测。细节如下所示。
Object Detector: 对于目标的检测和RoI特征的提取,我们按照[2]训练Faster-RCNN。训练之后 ,我们将提议NMS 的 IoU 阈值设置为 0.7, 将目标 NMS 的阈值设置为 0.3。 每张图像最少选择十个目标, 最多选择100个目标。 使用 RoI pooling 提取目标特征, 它会被用作关系分类器, 属性分类器 以及 MGCN 的输入。
Relationship Classifier: 使用[52] 提出的LSTM结构作为关系分类器。 训练之后, 为 IoU 阈值超过0.2 的两个目标预测关系。
Attribute Classifier: 属性分类器的细节结构如表9所示。 在训练之后, 我们为每个目标预测 Top-3 的属性。
对每个图像, 通过使用预测的目标、关系和属性, 可以构建一个image scene graph。 主文中6.1节有详细的解释, 目标、关系和属性的综述有472个, 因此我们使用 $472 \times 1000$ 的词嵌入矩阵将节点标签转换为表6(6)到(8)的连续向量。
Details
Scene Graph 所对应的含义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
array([[ 0., 9., 408.],
[ 0., 14., 425.],
[ 0., 26., 425.],
[ 1., 14., 408.],
[ 1., 26., 425.],
[ 2., 22., 410.],
[ 3., 13., 429.],
[ 3., 14., 408.],
[ 5., 7., 410.],
[ 5., 26., 408.],
[ 7., 14., 408.],
[ 7., 26., 408.],
[ 13., 14., 463.],
[ 14., 26., 408.],
[ 18., 20., 408.]])
scene graph matrix: [0., 9., 408.] 意思是第 0 个 box 和 第9个 box 之间的关系是 dict[408], 如果 dict[408] 的关系是 on, 那么它们对应的关系就是 on。
attrbute matrix :[0, 1, 2] 意味着 bbox 有三种属性, 分别是 dict[0], dict[1] 和 dict[2]。
如何可视化 Scene Graph
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
from __future__ import print_function
import argparse
import numpy as np
parser = argparse.ArgumentParser()
# Input paths
parser.add_argument('--id', type=str, default='558579',
help='id of image')
parser.add_argument('--mode', type=str, default='sen',
help='image or sen')
opt, _ = parser.parse_known_args()
if opt.mode == 'sen':
sg_dict = np.load('../datasets/Caption/SGAE/spice_sg_dict2.npz', allow_pickle=True)['spice_dict'][()]
sg_dict = sg_dict['ix_to_word']
folder = '../datasets/Caption/SGAE/coco_spice_sg2/'
else:
sg_dict = np.load('../datasets/Caption/SGAE/coco_pred_sg_rela.npy', allow_pickle=True)[()]
sg_dict = sg_dict['i2w']
folder = '../datasets/Caption/SGAE/coco_img_sg/'
sg_path = folder + opt.id + '.npy'
sg_use = np.load(sg_path, allow_pickle=True, encoding="bytes")[()]
if opt.mode == 'sen':
rela = sg_use['rela_info'.encode('utf-8')]
obj_attr = sg_use['obj_info'.encode('utf-8')]
else:
rela = sg_use['rela_matrix'.encode('utf-8')]
obj_attr = sg_use['obj_attr'.encode('utf-8')]
N_rela = len(rela)
N_obj = len(obj_attr)
for i in range(N_obj):
if opt.mode == 'sen':
print('obj #{0}'.format(i), end = ': ')
if len(obj_attr[i]) >= 2:
print ('(', end = '')
for j in range(len(obj_attr[i])-1):
print('{0} '.format(sg_dict[obj_attr[i][j + 1]]), end = '')
print (') ', end = '')
print(sg_dict[obj_attr[i][0]])
else:
print('obj #{0}'.format(i), end = ': ') # maybe it means 'bounding box' but not 'object'
N_attr = 3
for j in range(N_attr - 1):
print('{0} {1}, '.format(sg_dict[obj_attr[i][j + 4]],\
sg_dict[obj_attr[i][j+1]]), end = '')
j = N_attr - 1
print('{0} {1}'.format(sg_dict[obj_attr[i][j + 4]],\
sg_dict[obj_attr[i][j+1]]))
for i in range(N_rela):
obj_idx = 0 if opt.mode == 'sen' else 1
sbj = sg_dict[ int(obj_attr[int(rela[i][0])][obj_idx]) ]
obj = sg_dict[ int(obj_attr[int(rela[i][1])][obj_idx]) ]
rela_name = sg_dict[rela[i][2]]
print('rel #{3}: {0}-{1}-{2}'.format(sbj,rela_name,obj,i))
如何处理 sentence scene graph
以下内容是如何处理sentence scene graph的: 1).create_coco_sg.py 通过spice中的parser方法来生成coco dataset中每个图片的scene graph 运行的时候要先进代码将coco_use设置为coco_train,然后把self-critical.pytorch/coco-caption/pycocoevalcap/spice/中的sg.json保存为spice_sg_train.json,然后把这个文件放到/data中去,同理把coco_use设置为coco_val,然后把生成的sg.json保存为spice_sg_val.json。
2).process_spice_sg.py 将spice_sg_val.json和spice_sg_train.json处理为按照image_id.npy形式保存在coco_spice_sg中。具体格式为: ssg[‘obj_info’]:list,每一个list都代表着一个object以及其对应的attribute, 第一个元素是object name在dict中的index,后面的元素都是 attribute对应dict中的index。 ssg[‘rela_info’]:numpy数组,每一行3个元素,分别为[sbj_id,obj_id,relation_id] 其中的sbj_id和obj_id对应于ssg[‘obj_info’]中的obj list的index, relation_id为其在dict中的index。 还有处理完的dict可以保存为spice_sg_dict.npz. 我先生成了一个spice的字典,其中把很多词语正则化了一下,前9487个词和原始的词典一致,后面的为增补的词典。
3).process_sg_extend.py 生成适合attention extend model的数据,直接从之前的生成的数据中来改。 先生成一个字典,其中前9487个词和原始词典一致,然后加入sentence scene graph的字典,以及image scene graph的字典。 然后把image scene graph的数据改了就好了。也就是只改变cocobu_rela中的数据,然后把改变完的数据保存到cocobu_sg_img中去。 而对于sentence scene graph,其还是保存在coco_spice_sg中。 新的字典保存在sg_dict_extend.npz中。
对于coco_spice_sg2,其实就是字典更大了,比如coco_spice_sg中对应的字典是caption生成的字典时把小于等于5个词的词给删除了,然而coco_spice_sg2中对应的字典是caption生成的字典时把小于等于4个词的词给删除了.不同的字典对最后影响不是那么大。
生成 sentence scene graph
需要把 coco_caption/pycocoevalcap/spice 文件夹下的 spice-1.0.jar 替换为主文件夹下的 spice-1.0.jar。
Reference
-
Previous
【深度学习】Neural Motifs:Scene Graph Parsing with Global Context -
Next
【深度学习】Unified Visual-Semantic Embeddings:Bridging Vision and Language with Structured Meaning Representations