引言
Pytorch 文档中这么写到:
1
2
3
torch.gather(input, dim, index, out=None, sparse_grad=False) → Tensor
Gathers values along an axis specified by dim.
因此, 它沿着 axis 来搜集值。 但是它和普通的索引有什么区别呢? 假设我们有一个 $4 \times 6$ 的矩阵(4 表示 batch size, 6 表示 features)。 当我们使用 x[_, :] 或者 x[:, _], 我们将从 batch / feature 中选择相同的索引, 如下图所示:

假设有下面一种情况: 我们想选择第0行第3个特征, 第1行的第7个特征, 第2行的第4个特征以及第3行的第1个特征(索引从0开始)。

我们可能会想要这么做:
1
2
indices = torch.LongTensor([3,7,4,1])
x[:, indices]
但是我们会得到:
1
2
3
4
tensor([[ 3, 7, 4, 1],
[13, 17, 14, 11],
[23, 27, 24, 21],
[33, 37, 34, 31]])
现在, 我们就需要 gather 函数。
gather 函数有三个参数:
- input: 输入的 tensor
- dim: 收集值沿着的维度
- index: 要从
特别地, input 和 index 的维度除了在 dim 维度外的其他维度需要相同。 例如, input 的形状是 $4 \times 10 \times 15$, dim 为 0, 那么 index 必须是 $N \times 10 \times 15$
2D 例子
让我们回到最开始的例子。 我们知道 input, dim = 1, index 的形状应该是 $4 \times 1$。
1
2
3
4
5
6
7
8
9
10
11
indices = torch.LongTensor([3,7,4,1])
indices = indices.unsqueeze(-1)
print(indices.shape)
print(indices)
> torch.Size([4, 1])
> tensor([[3],
[7],
[4],
[1]])
让我们插入它并看看是否有效
1
2
3
4
tensor([[ 3],
[17],
[24],
[31]])
结果是正确的!
3D 例子
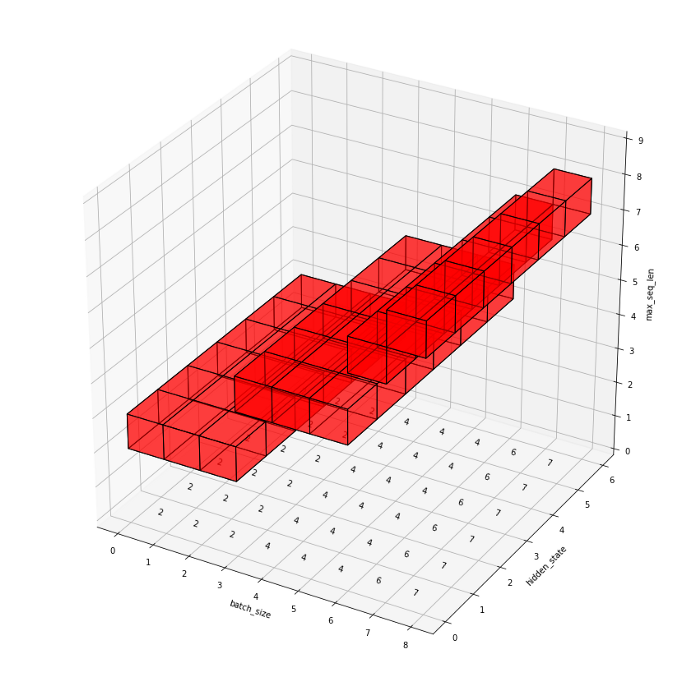
假设我们有一个以下的场景: 将序列填充到最大长度的RNN网络。我们希望收集每个序列的最后一个元素,所有的特征都来自 RNN 的隐藏状态。
输入数据的形状为 $B \times L \times H$。 我们假设 $batch size = 8$, $max_seq_len = 9$, $hidden_size = 6$。
1
2
3
4
5
6
7
8
batch_size = 8
max_seq_len = 9
hidden_size = 6
x = torch.empty(batch_size, max_seq_len, hidden_size)
for i in range(batch_size):
for j in range(max_seq_len):
for k in range(hidden_size):
x[i,j,k] = i + j*10 + k*100
如果我们做以下操作:
1
2
3
4
5
6
7
8
9
10
x[:,4,:]
>tensor([[ 40., 140., 240., 340., 440., 540.],
[ 41., 141., 241., 341., 441., 541.],
[ 42., 142., 242., 342., 442., 542.],
[ 43., 143., 243., 343., 443., 543.],
[ 44., 144., 244., 344., 444., 544.],
[ 45., 145., 245., 345., 445., 545.],
[ 46., 146., 246., 346., 446., 546.],
[ 47., 147., 247., 347., 447., 547.]])
这样的话我们会得到所有的 batches, 第4个序列元素, 以及所有的隐藏状态。
接下来,我们知道每个序列最后一个元素的索引(这可以是NLP任务句子中最后一个 token 的索引)。
1
lens = torch.LongTensor([5,6,1,8,3,7,3,4])
现在,只想从每个样本中提取第 lens 个 token 的隐藏状态值。
input 的形状是 $batch_size \times max_seq_len \times hidden_state(8 \times 9 \times 6)$。 我们想沿着 $seq_len$ 维度 (1), 因此, index 的形状为 $8 \times 1 \times 6$。
因此, 我们只有 8 个值(lens), 但是我们需要填入 48 个值(8 * 6)。 解决方法是很简单的, 我们仅需要将 lens 重复 6 次:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
lens = torch.LongTensor([5,6,1,8,3,7,3,4])
# add one trailing dimension
lens = lens.unsqueeze(-1)
print(lens.shape)
> torch.Size([8, 1])
# repeat 6 times
indices = lens.repeat(1,6)
print(indices.shape)
> torch.Size([8, 6])
print(indices)
> tensor([[5, 5, 5, 5, 5, 5],
[6, 6, 6, 6, 6, 6],
[1, 1, 1, 1, 1, 1],
[8, 8, 8, 8, 8, 8],
[3, 3, 3, 3, 3, 3],
[7, 7, 7, 7, 7, 7],
[3, 3, 3, 3, 3, 3],
[4, 4, 4, 4, 4, 4]])
进一步, 我们在中间插入一个空维度, 使得它变成 $8 \times 1 \times 6$
1
2
3
4
indices = indices.unsqueeze(1)
print(indices.shape)
> torch.Size([8, 1, 6])
然后应用它:
1
2
3
4
results = torch.gather(x, 1, indices)
print(results.shape)
> torch.Size([8, 1, 6])
形状是正确的, 那么值呢?
1
2
3
4
5
6
7
8
tensor([[[ 50., 150., 250., 350., 450., 550.]],
[[ 61., 161., 261., 361., 461., 561.]],
[[ 12., 112., 212., 312., 412., 512.]],
[[ 83., 183., 283., 383., 483., 583.]],
[[ 34., 134., 234., 334., 434., 534.]],
[[ 75., 175., 275., 375., 475., 575.]],
[[ 36., 136., 236., 336., 436., 536.]],
[[ 47., 147., 247., 347., 447., 547.]]])
我们看到它包含了来自batch的所有样本,在每个样本中都有所有的特征,我们看到序列元素对应的是5 6 1 8 3 7 3 4。
发生了什么?
为了理解它的意思,让我们仅分片批量中的一个样本:
1
2
indices[0,:]
> tensor([5, 5, 5, 5, 5, 5])
它包含6个元素,匹配隐藏状态的数量——这意味着对于第0个样本中的每个隐藏状态,选择dim 轴的第5个元素。同样的事情发生在批量中的第2个样本上: tensor 包含 [1,1,1,1,1,1] 意味着对于对于6个隐藏状态,我们想要从句子的第一个位置获取值。
为了让它更清晰,我创建了简单的可视化。其它设置相同,除了 lens = [2, 2, 2, 4, 4, 4, 6, 7]。你可以清楚地看到 indices 的值是如何与 input 张量的值相对应的。
Reference
-
Previous
【深度学习】Unified Visual-Semantic Embeddings:Bridging Vision and Language with Structured Meaning Representations -
Next
【深度学习】Auto-Parsing Network for Image Captioning and Visual Question Answering