Abstract
几个研究指出简单将Scene Gragh 当做黑盒使用会损害 image captioning 的性能, 基于scene graph 的 captioning 模型会过于挖掘图像特征导致难以生成得体的句子。
提出一个框架SG2Caps仅仅使用scene graph 标签生成有竞争力的 image captioning 性能。
基本的思想是拉进两个scene graph 的语义鸿沟, 一个来自图像一个来自句子。
为了达到这个目标, 我们利用了目标的空间位置以及 Human-Object-Interaction(HOI) 标签作为额外的 HOI graph。
直接利用 scene graph 标签避免了在高维CNN特征上卷积的代价, 减少了49%的可训练参数。
Introduction
主流的 image captioning 模型依赖于图像卷积特征 以及对显著区域的注意力 以及 目标 通过循环模型生成 captions。
几乎没有工作报告使用 scene graph 提升生成 caption 的性能, 同时有几个工作强调仅仅使用 scene graph 会产生较差的 captioning 结果 并且会损害 captioning 的性能。
包含节点和边的 Scene Graph 表征可以通过两种方式获得: 1) Visual Scene Graph(VSG) 2) 基于规则的语义解析得从句子中得到 Textual Scene Graph(TSG)。 Scene graph 生成以及用于 image captioning 的文献主要指 VSG 表征
为了利用 scene graph 生成描述, 我们需要 VSG-Caption 标注对。
现在的方法在 Visual Genome 数据集上训练 VSG 生成器, 在 COCO-captions 数据集上训练 TSG 来生成 caption, 最后将在VG上训练的 VSGs 转换为 captions 一边随后使用。
这种方法有两个问题:
- VG 上训练的 VSGs 特定关系特别多(has, on等), 关系的分布是一个长尾分布, 即便是最好性能的 VSG 生成器也不能准确地学习到有意义的关系。 这导致 VSGs 中的噪声, 进而导致损害 captions 的性能。
- 现有的方法存在一种假设, 即 TSGs 和 VSGs 是分庭抗礼的。 然而,当以 VSG 作为输入的时候, 能够生成很好性能的描述。语言偏置并不能从 TSG 迁移到 VSG 上。
为了解决上述问题, 我们提出几种新的方法来提升 VSGs 的captioning 的上下文:
- Human-Object Interaction(HOI) information:人类倾向于通过关注人与物的交互来描述涉及到人类的视觉场景,而忽略其他细节。从一幅图像中提取HOI信息,可以提供一种有效的方法来突出其VSG中的显著部分,从而使其更接近其对应的TSG。因此,我们提出利用预先训练的HOI推断作为部分VSGs,其中场景中所有检测到的对象(不限于人类)构成图节点,HOI信息以适当的关系和属性扩充少数相关节点。
- VSG grounding:VSG的每个节点与图像中的目标边界框具有一对一的关联。这种空间信息可以用来捕捉物体之间的关系。在生成场景图的文献中,边界框极大地提高了对象间关系分类性能[18,17]。
相比于现有的工作, 我们没有使用任何图像或者 目标级的视觉特征; 然而,通过利用HOI信息和VSG grounding,我们实现了具有竞争力的描述生成性能。
研究人员已经表明,由于固有的数据集偏差和无法获得高质量的人工标注,图像描述生成算法的结果不太准确。
SG2Caps模型利用了来自 image captioning 数据集之外的其他来源的额外标注,从而减少了NLP偏差。
我们的贡献总结如下:
- 我们表明,在 coco-caption 数据集上,仅使用VSG就可以实现有竞争力的标题性能,而不需要任何视觉特征。
- 实验结果表明,VSG和TSG在描述生成过程中并不能分庭抗礼,因此提出了改进 VSG 到 captioning 的可学习的转换。
- SG2Caps 利用 VSG 的空间位置 和 HOI 信息从 VSGs 生成更好的描述。节点位置有助于识别对象之间有意义的关系(结果在CIDEr得分中增加5分)。HOI抓住了自然语言交流的本质(在CIDEr得分中获得7分)。因此,它们有助于缩小TSG和VSG之间的语义差距,从而实现image captioning。
- 为 SG2Caps 添加一种轻量化的如何视觉特征的策略。低维的全局视觉特征可以作为VSG 的一个节点, 进一步提升仅用 scene graph 模型的性能。
Related Work
Image Captioning:主流的 image captioning 模型直接将卷积图像特征送到一个循环网络生成自然语言。此类图像描述模型中的自顶向下方法依赖于基于注意力的深度模型[13,15,31,24]。基于上下文的注意力, 将其应用于一层或多层 CNN 的输出。使用目标检测计算目标级的自底向上的注意力。这种自底向上的注意力机制是很多视觉-语言任务的SOTA。
VSG in image captioning: 许多研究[27,7,18,23,28,11,33]设计了一些方法,力求在基准VG数据集[8]上实现VSG生成任务。最近的一些研究[32,30,6,21,25,10]介绍了VSG(除了视觉特征)的使用,希望对对象属性和关系进行编码可以改善image captioning。一些工作用了隐式场景图表示[32,5],而另一些作品则探索了关系和属性的显式表示[30,21,14,9]。显式场景图方法是将视觉神经网络特征与图像或物体的CNN特征相结合。这种显式的场景图方法将场景图生成器作为黑箱使用。例如,Wang等人[21]利用了 FactorizableNet[11],有人[30,6,35]利用了Motif Net[33],有人[10,14]利用 Iterative Mes-sage Passing[23]作为黑盒场景图生成器。
研究人员发现,单靠VSG的字幕效果很差。最近,一项深入的研究认为,正是VSG中的噪声(往往是关系)损害了图像描述性能[14]。
之前有一个工作使用 VSG 标签作为 captioning 模型唯一的输入, 并且观察到单独使用 VSG 标签导致不令人满意的结果。我们的模型和他们的不同点在于:
- 我们的模型使用新的方法使得 VSGs 更适合用于 captioning
- 我们利用了 HOI 信息进一步提升 captioning 性能
- 我们的模型可以处理可变节点数量的VSGs
性能也超过了其仅用 scene graph 模型的性能, 此外,它用了更丰富的类别词典以及外部词嵌入 (1600 vs 150)。
Proposed model
我们的模型SG2caps由 VSG 生成器, VSG 编码器和语言解码器组成。
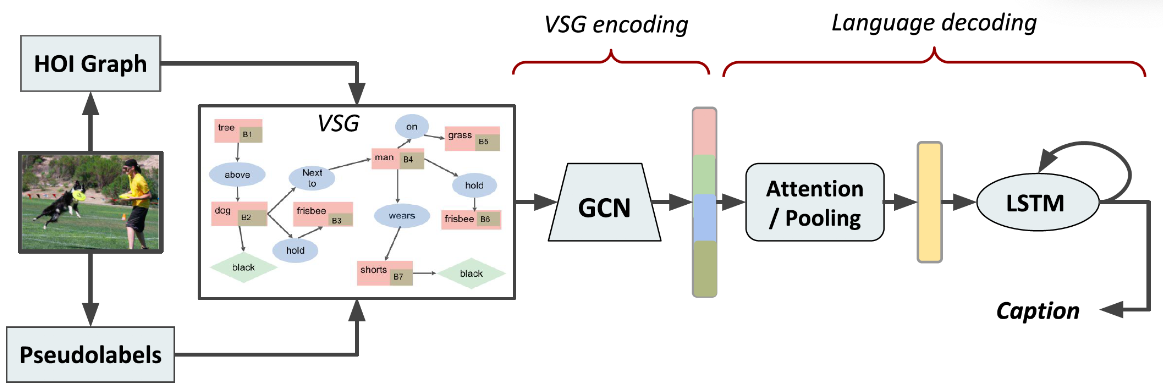
VSG 包括目标, 它们的属性, 空间位置 和 物体内部关系。
VSG encoder 生成上下文相关的embeddings, 其作为语言解码器的输入。
语言解码器由基于注意力的 LSTM 网络组成。
VSG generator
VSG Generator 包括两个部分。
VG150 Pseudolabel: 现成的VSG生成器提供目标类别作为节点标签和成对的关系。我们学习自己的属性分类器,并使用MotifNet[33]在VG150上训练VSG生成器。将预先训练好的VSG生成器应用于COCO图像上,生成scene graph pesudolabel,从而生成具有节点、节点属性、节点位置和成对关系的 visual scene graph。目标、属性和关系对应 VG150 的此表, 包括150个目标类别, 50个关系和203个属性。
Partial COCO scene graph: 同时,我们使用一个在COCO图像上预训练的目标检测器来创建一个COCO目标列表,这些目标作为另一个图(称为HOI图)的节点。然后,我们使用HOI推理填充仅和人这个类别相关的几个属性和关系边。我们称它为局部场景图,因为它的关系信息有限,节点大多是不连通的,但都是在COCO词汇表中。没有检测到人类别目标的图像,部分VSGs不包含任何HOI增强,它只包含检测到的目标创建的节点列表。
VSG encoder
我们使用伪标签和HOI graph的并集作为图像的VSG。一个VSG 是一个元组: $\mathcal{G} = (\mathcal{N}, \varepsilon)$, 其中 $\mathcal{N}$ 和 $\varepsilon$ 是节点和边的集合。 $\mathcal{N}$ 中有四种节点: 目标节点 $o$, 属性节点 $a$, 边界框节点 $b$ 以及 关系节点 $r$。 $N$ 中的每个节点被表示为一个 d 维向量。 $\varepsilon$ 的边定义如下:
- 如果目标 $o_i$ 有一个属性 $a_{i, l}$, 那么有一条有向边 $o_i$ 到 $a_{i, l}$
- 从 $o_i$ 到 边界框 $b_i$ 有一条有向边
- 如果存在三元关系 $<o_i - r_{ij} - o_j>$, 构造从 $o_i$ 到 $r_{ij}$ 和 从 $r_{ij}$ 到 $o_j$ 的两条有向边。
接下来, 我们将原始的节点 embedding $e_o$, $e_a$, $e_b$, $e_r$ 转换为一个新的上下文无关的 embeddings 集合 $\mathcal{X} = {x_{r_{ij}}, x_{o_i}, x_{a_i}, x_{b_i}}$。
我们使用五个空间图卷积函数 $g_r$, $g_a$, $g_b$, $g_s$, 和 $g_o$来生成上述embeddings。 它们是有独立参数的相同结构: 全连接层接着一个 ReLU激活函数。
Relationship embedding $x_{r_{ij}}$: 给定 $\mathcal{G}$ 的三元组关系 $<o_i - r_{ij} - o_j>$, $x_{r_{ij}}$ 一起定义为 subject $o_i$, object $o_j$ 和 predicate ($r_{ij}$) 如下:
\[x_{r_{ij}} = g_r(e_{i_i}, e_{r_{ij}}, e_{o_j})\]Attribute embedding $x_{a_i}$: 对于 $\mathcal{G}$ 中的一个目标节点 $o_i$ 和 它的属性 $a_{i, 1:N_{a_i}}$, embedding $x_{a_i}$ 由:
\[x_{a_i} = \frac{1}{N_{a_{i}}} \sum_{l=1}^{N_{a_i}}g_a(e_{o_i}, e_{a_{i, j}})\]其中 $N_{a_i}$ 是对 $o_i$ 的属性数量。
Bounding box embedding $x_{b_i}$: 给定 $o_i$ 和 它的边界框 $b_i$, $x_{b_i}$ 被定义为:
\[x_{b_i} = g_b(e_{o_i, e_{b_i}})\]Object embedding $x_{o_i}$: 一个节点 $o_i$ 基于边的方向扮演不同的角色, 例如 $o_i$ 在三元组中可以作为 subject 或者 object。 object embeddings 将整个三元组考虑在内:
\[x_{o_i} = \frac{1}{N_{r_i}[\sum_{o_j \in sbj(o_j)}(e_{o_i}, e_{o_j}, e_{r_{ij}}) + \sum_{o_k \in obj(o_i)} g_o(e_{o_k}, e_{o_i}, e_{r_{ki}})]\]其中 $N_{r_{i}} = \mid sbj(i) \mid + \mid obj(i) \mid$ 是所有包含 $o_i$ 的三元组关系的数量。
注意模型和 SGAE 不同的地方在于 我们为 $x_{b_i}$ 学习参数 并且 融合不同输出 embeddings。 我们在节点级用求和操作组合 $x_{o_i}$, $x_{b_i}$, $x_{a_i}$ 来形成 $\mathcal{X}$, 再将其送入注意力 LSTM, 而SGAE是简单地拼接。
Fusing visual features 我们用视觉特征以一种简单的策略增强 scene graph 特征。在输出 graph embedding 添加一个 summary projection。求和节点使用 图像级 P6 特征的全局池化, 后面跟着一个投影层将 256 维summary 节点投影为 128 维向量, 后面接一个 ReLU 非线性激活。投影 summary 节点维度和 GCN embedding 大小相匹配。 因此它与上述的 $\mathcal{X}$ 向量相拼接。上述融合策略与其他论文不同, 其他论文将融合特征在单独节点层级融合。
Languge Model
给定一幅图像 $I$ 的 VSG $\mathcal{G}$, 我们想要生成一个句子 $w_{1:T} = w_1, w_2, .., w_T$ 描述图像。对于 SG2Caps, 使用两层的 encoder-decoder LSTM 结构用于此部分。 LSTM 采用 VSG 编码的 $\mathcal{X}$ 作为输入。
LSTM 的操作可以表示为: $h_t = LSTM(x_t, h_{t-1})$, 其中 $x_t$ 是 LSTM 输入向量 并且 $h_t$ 是LSTM 输出向量。 令 LSTM 的注意力层和解码器层的状态为 $h_t^1$ 和 $h_t^2$。 在每个时间步 $t$, 注意力LSTM捕获上下文信息 $x_t^1$ 通过拼接之前的解码器 LSTM 的隐藏状态, 平均池化 VSG 特征 ($\bar f = \frac{1}{k} \sum_i f_i$) 和 之前生成的词表征:
\[x_t^1 = concat(h_{(t-1)}^2, \bar f_t, W_e u_t)\]其中 $W_e$ 是词典 $\sum$ 的词嵌入矩阵 并且 $u_t$ 是它在时间步 $t$ 的独热编码。
对于 VSG 特征在时间步 $t$ 生成规范化权重 $\alpha_t$:
\[a_{i, t} = w_a^T \tanh (W_{fa}f_i + W_{ha}h_t^1) \\ \alpha_{i, t} = \text{softmax}(a_{i, t})\]其中 $w_a^T \in \mathbb{R}^H$, $W_{fa} \in \mathbb{R}^{H \times D_f}$, $W_{ha} \in \mathbb{R}^{H \times H}$ 是可学习的权重。 attended VSG 特征 $\hat f_t$ 输入 解码器 LSTM 是一个输入特征 $f_i$ 的一个凸组合:
\[\hat f_t = \sum_{i=1}^{N_f} \alpha_{i, t} f_i\]$\mathcal{X}$ 使得对 scene graph 的每个目标级别的节点学习注意力系数。
解码器 LSTM 的输入由从注意力 LSTM 层的之前的隐藏状态、注意力加权的 VSG 特征: $x_t^2 = [h_t^1, \hat f_t]$ 自称。 对于一个词序列 $w_1, w_2, …, w_T$, 表示为 $w_{1:T}$, 在时间步 $t$ 对可能的输出的条件概率分布为 $p(w_t \mid w_{1:t-1}) = \text{softmax}(W_ph_t^2 + b_p)$。 完整输出序列的分布计算为条件概率的乘积。
Conclusion
发掘目标、属性和关系的编码对 image captioning 来说是有用的信息。 然而, 盲目地使用 visual scene graph 生成 句子难以生成合理的句子描述。
所提出的 SG2Caps pipeline 使得预训练网络用于:
- SGDet 在其它 scene graph 数据集上
- 大幅减小 HOI 数据集 和 COCO caption 数据集的 语义角色 的鸿沟——表明强大的 captioning 模型可以仅通过低维的目标和关系标签空间得到。