Abstract
全景驾驶感知系统是自动驾驶的重要组成部分。
高精度和实时感知系统可以帮助车辆在驾驶时做出合理的决策。
作者提出了一个全景驾驶感知网络(you only look once for panoptic YOLOP)),以同时执行交通物体检测、可驾驶区域分割和车道检测。它由一个用于特征提取的编码器和三个用于处理特定任务的解码器组成。
该模型在具有挑战性的BDD100K数据集中表现非常好,在所有三项任务的准确性和速度方面都达到了最先进的水平。
此外,作者通过消融试验验证了联合训练的多任务学习模型的效果。
Method
作者提出了一种简单高效的前向网络,可以完成交通物体检测、可驾驶区域分割和车道检测任务。如图2所示,我们的全景驾驶感知单阶段网络,称为you only look once for panoptic (YOLOP),包含一个共享编码器和三个后续解码器,以解决特定任务。不同的解码器之间没有复杂而多余的共享块,这降低了计算消耗,并使网络易于端到端训练。
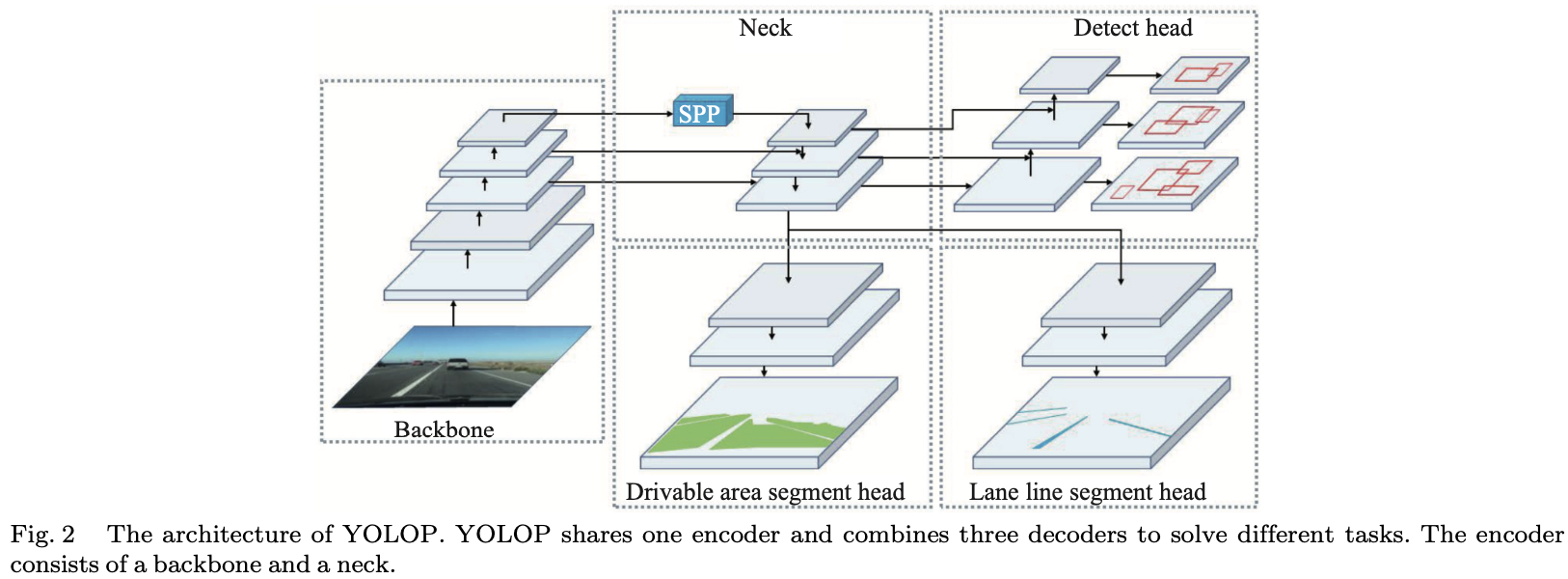
Encoder
该网络共享一个编码器,该编码器由骨干网络和一个颈部网络组成。
Backbone
主干网络用于提取输入图像的特征。通常,一些经典的图像分类网络是骨干。由于YOLOv4在目标检测方面的出色性能,作者选择了CSPDarknet作为主干,解决了优化过程中的梯度重复问题。它支持特征传播和特征重用,从而重新减少参数和计算的数量。因此,它有利于确保网络的实时性能。
Neck
颈部用于融合骨干产生的特征。颈部主要由空间金字塔池(SPP)模块和特征金字塔网络(FPN)模块组成。SPP生成和融合不同尺度的特征,FPN在不同的语义级别融合特征,使生成的特征包含多个尺度和多个语义级别信息。作者在工作中采用串联方法来融合特征。
Decoders
网络中的三个 head 是这三项任务的特定解码器。
Detection head
与YOLOv4类似,采用基于先验框的多尺度检测方案。首先,作者使用一种称为 path aggregation network (PAN)的结构,这是一个自下而上的金字塔网络。FPN自上而下传输语义特征,PAN传输定位特征自下而上。将它们组合起来以获得更好的特征融合效果,然后直接使用PAN中的多尺度融合特征图进行检测。然后,多尺度特征图的每个网格将被分配三个具有不同宽高比的先验框,检测头将预测位置的偏移量和高度和宽度的缩放,以及每个类别的相应概率和预测的置信度。
Drivable area segment head & lane line segment head
可驾驶区域段头和车道线段头采用相同的网络结构。我们将FPN的底层提供给分割分支,大小为$(W /8,H /8,256)$ 。经过三次上采样过程,作者将输出特征图恢复到 $(W,H,2)$ 的大小,这表示可驾驶区域/车道线和背景输入图像中每个像素的概率。由于颈部网络中的共享SPP,我们不会像其他人通常那样在分割分支中添加额外的SPP模块,这不会给我们的网络性能带来任何提升。此外,在上采样层中使用最近的插值方法来降低计算成本,而不是反卷积。因此,分割解码器不仅获得高精度输出,而且在推理过程中速度也非常快。