Abstract
大规模的预训练通常可以产生更好的泛化性能,例如,在大量的图像-文本对上进行训练的CLIP (contrast Language-Image pre-training),在各种视觉任务中表现出了很强的 zero-shot 能力。
为了进一步研究CLIP带来的优势,我们提出在两种典型的场景下的各种V&L模型中使用CLIP作为视觉编码器:
- 将 CLIP 插入特定任务的微调
- 将 CLIP 与 V&L 预训练任务结合并迁移的下游任务。
结果表明 CLIP 比广泛使用的视觉编码器 BottomUp-TopDown 表现更好。
Introduction
近期工作(Anderson et al., 2018a;Jiang等,2020;Zhang等人,2021)观察到视觉表示已经成为V&L模型的性能瓶颈,并强调了学习一种强大的视觉编码器的重要性。
这些高性能视觉编码器使用类别标签(例如,Im-ageNet) (Russakovsky等人,2015年)或边界框(例如,Visual Genome)(Krishna等人,2017年)的人工标注的数据进行训练。
然而,此类检测或图像分类数据的采集成本较高,且视觉表现受到预定义类标签的限制。
因此,需要一种视觉编码器,它可以在更多样化和大规模的数据源上训练,不受一组固定标签的限制,并具有对未见过的目标和概念具有泛化能力。
CLIP在ImageNet分类等基准测试中显示了强大的 zero-shot 能力。我们假设它对于V&L任务也具有很大的潜力。然而,将CLIP作为 zero-shot 模型直接应用于 V * L 任务被证明是困难的(第5节和Kim等人(2021年)),因为许多V&L任务需要复杂的多模态推理。因此,我们建议将CLIP与现有的V&L模型结合起来,用CLIP的视觉编码器取代它们的视觉编码器。
我们考虑两种典型场景:
- 将 CLIP 直接插入任务特定的 fine-tuning 中
- 将 CLIP 与 V&L 预训练在图像文本对上预训练, 并且迁移到下游任务上。
在任务特定的 fine-tuning 上, 我们考虑了三个热门任务: VQA, image cationing 和 V&L Navigation。
在所有三个任务中,CLIP-ViL带来了较强基线的显著改善,在VQA v2.0上的准确率为1.4%,在COCO字幕上的准确率为6.5,在 Room-to-Room navigation 上的成功率为4.0%
在VL 预训练中, 将传统的基于区域的表征替换为 CLIP 特征。CLIP-VIL_p 在 VQAv2, SNLI-VE和GQA 上取得了好的表现, 在 VQA 上取得了新 SOTA (76.7% on test-std), 在 SNLI-VE 上取得了新SOTA(80.20% on test)。CLIP-Res50 的 CLIP-ViL_p 比广泛基于区域的编码器 (BUTD) ResNet101 的表现更好。 CLIP-Res50x4 的 CLIP-ViL_p 比 VinVL-ResNeXt152 的表现更好, 其实当前的 SOTA, 并且极致 Scale-up 基于区域的编码器。
Background and Motivation
Motivation
尽管CLIP在视觉任务中具有较强的zero-shot能力,但在某些V&L下游任务中,CLIP没有表现出相同的表现水平。
例如,如果我们将VQA 2.0 (Goyal et al., 2017)转换为 zero-shot 的图像到文本检索任务,我们只观察 chance 性能(第5节)。
因此,我们建议将CLIP的视觉编码器与之前的V&L模型集成(图1)。
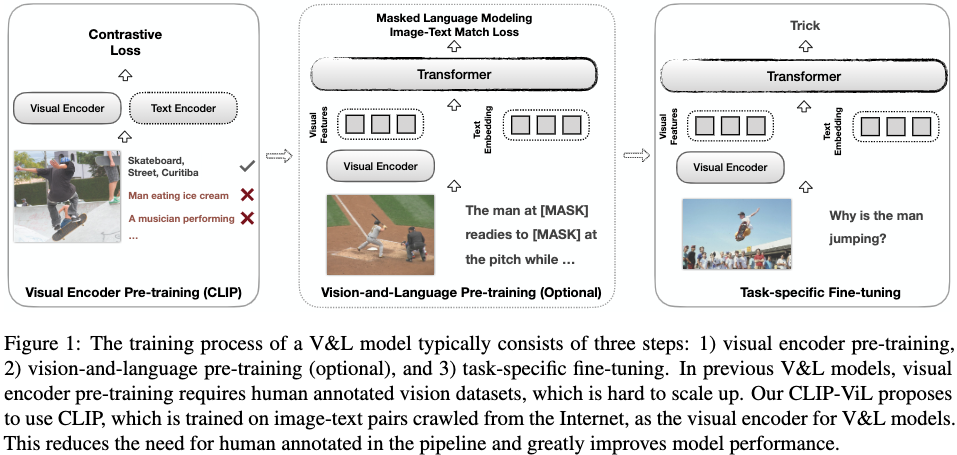
我们考虑使用CLIP的不同视觉主干。 (CLIP-ResNet denoted as CLIP-Res): CLIP-Res50, CLIP-Res101, CLIP-Res50x4, 和 CLIP-ViT-B。
接下来,我们将在两个场景中描述我们的方法:
- 直接特定于任务的微调(第3节)
- V&L预训练(第4节)。
CLIP-ViL
Visual Question Answering
Experimental Setup: 参考 (Jiang 等人 2020) 提取 grid feature。
Experimental Results:与传统的在 ImageNet 分类任务上预训练的视觉特征提取器相比, CLIP 视觉模块表现出明显的提升。
我们进一步展示了在 VG 上预训练的检测的结果。相比于 ImageNet-Res50 编码器, 它提升了 Pythia_VG 2.82% 的表现, 在 MCAN_VG 上提升了 2.90% 的表现。然而,使用Pythia_VG时CLIP-Res50的性能下降了5.54%,使用MCAN_VG时下降了4.08%。可能原因是,与ImageNet相比,CLIP-Res50是在不同的数据和不同的方法上进行训练的,所以为ImageNet模型设计的Visual-Genome微调实际可能会损害性能。
Conclusion
这篇文章提出利用CLIP作为视觉特征编码器在不同任务上用于不同的 V&L 模型。
用两种方法进行实验:
1) 直接将 CLIP 插入特定任务的微调 2) 将CLIP 与 VL 预训练结合, 然后在下游任务上微调。
大量的实验表明, CLIP-ViL 和 CLIP-ViL_p 能够取得有竞争力或更好的成绩。
Bug
RuntimeError: NCCL Error 1: unhandled cuda error
使用 pytorch 1.7.1 无此问题
MMF
提取特征 no kernel image is available for execution on the device
将 maskrcnn/layers/nms.py 中的:
1
nms = _C.nms
改为
1
2
3
4
5
try:
import torchvision
from torchvision.ops import nms
except:
nms = _C.nms
将 maskrcnn/layers/roi_align.py 中的:
1
roi_align = _ROIAlign.apply
改为
1
2
3
4
5
try:
import torchvision
from torchvision.ops import roi_align
except:
roi_align = _ROIAlign.apply
安装 MMF
1
2
conda create -n mmf python=3.7
conda activate mmf
1
2
3
git clone https://github.com/facebookresearch/mmf.git
cd mmf
pip install --editable .
配置提取特征环境
1
2
conda create -n maskrcnn_benchmark
conda activate maskrcnn_benchmark
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# first, make sure that your conda is setup properly with the right environment
# for that, check that `which conda`, `which pip` and `which python` points to the
# right path. From a clean conda env, this is what you need to do
# this installs the right pip and dependencies for the fresh python
conda install ipython
# maskrcnn_benchmark and coco api dependencies
pip install ninja yacs cython matplotlib
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 -c pytorch
git clone https://gitlab.com/vedanuj/vqa-maskrcnn-benchmark.git
cd vqa-maskrcnn-benchmark
将 maskrcnn/layers/nms.py 中的:
1
nms = _C.nms
改为
1
2
3
4
5
try:
import torchvision
from torchvision.ops import nms
except:
nms = _C.nms
将 maskrcnn/layers/roi_align.py 中的:
1
roi_align = _ROIAlign.apply
改为
1
2
3
4
5
try:
import torchvision
from torchvision.ops import roi_align
except:
roi_align = _ROIAlign.apply
1
python setup.py build develop
Bug
pytorch/vision 安装失败
pytorch 1.7.1 安装分支 -b v0.8.2。
opencv 依赖
1
apt install libgl1-mesa-glx
1
apt-get install libglib2.0-dev
-
Previous
【深度学习】Florence: A New Foundation Model for Computer Vision -
Next
【深度学习】In Defense of Grid Features for Visual Question Answering