Training a State-of-the-Art Model
本章介绍了训练图像分类模型和获得最新结果的更高级技术。如果您想了解更多关于深度学习的其他应用,并稍后再讨论,您可以跳过它——稍后的章节不会假设对这种材料有了解。
我们将研究什么是规范化,一种称为 mixup 的强大数据增强技术,progressive resizing 方法和测试时间增强。为了展示所有这些,我们将使用ImageNet中名为Imagenette的子集从头开始训练模型(不使用迁移学习)。它包含一个来自原始ImageNet数据集10个不同的类别组成的子集,以便在我们想实验时更快地进行训练。
这比我们之前的数据集要难得多,因为我们使用的是全尺寸、全彩色图像,这些图像是不同大小、不同方向、不同光线等物体的照片。因此,在本章中,我们将介绍一些充分利用数据集的重要技术,特别是当您从头开始训练时,或使用迁移学习在与使用的预训练模型非常不同的数据集上训练模型时。
Imagenette
fast.ai首次启动时,人们使用三个主要数据集来构建和测试计算机视觉模型:
- ImageNet: 130万张不同尺寸的图像,直径约为500像素,分为1000个类别,其需要几天时间训练
- MNIST: 50,000 个 28×28 手写数字灰度图像
- CIFAR10: 10个类别的60,000张32×32像素彩色图像
问题是,较小的数据集实际上没有有效地推广到大型ImageNet数据集。在ImageNet上行之有效的方法通常必须在ImageNet上开发和训练。这导致许多人认为,只有能够访问巨大计算资源的研究人员才能有效地为开发图像分类算法做出贡献。
我们认为这似乎不太可能是真的。我们从未真正看到过一项研究表明ImageNet恰好正好适合大小,并且无法开发其他数据集来提供有用的见解。因此,我们尝试创建一个新的数据集,研究人员可以快速、廉价地测试他们的算法,这也可能适用于整个ImageNet数据集。
大约三个小时后,我们创建了Imagenette。我们从完整的ImageNet中选择了10个看起来非常不同的类。正如我们所希望的那样,我们能够快速、廉价地创建一个能够识别这些类的分类器。然后,我们尝试了一些算法调整,看看它们如何影响Imagenette。我们发现了一些效果很好的方法,并在ImageNet上进行了测试——我们很高兴发现我们的调整在ImageNet上也运行良好!
这里有一个重要信息:您获得的数据集不一定是您想要的数据集。它特别不可能成为您想要进行开发和原型设计的数据集,这一点尤其不可能。您的目标应该是迭代速度不超过几分钟——也就是说,当您想出一个想尝试的新想法时,您应该能够训练模型,并在几分钟内看到它进展如何。如果做实验需要更长的时间,请考虑如何减少数据集或简化模型,以提高实验速度。你能做的实验越多越好!
1
2
from fastai.vision.all import *
path = untar_data(URLs.IMAGENETTE)
首先,我们将使用 presizing 技巧将数据集放入DataLoaders对象:
1
2
3
4
5
6
dblock = DataBlock(blocks=(ImageBlock(), CategoryBlock()),
get_items=get_image_files,
get_y=parent_label,
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75))
dls = dblock.dataloaders(path, bs=64)
然后进行一次训练作为 baseline
1
2
3
model = xresnet50(n_out=dls.c)
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(), metrics=accuracy)
learn.fit_one_cycle(5, 3e-3)
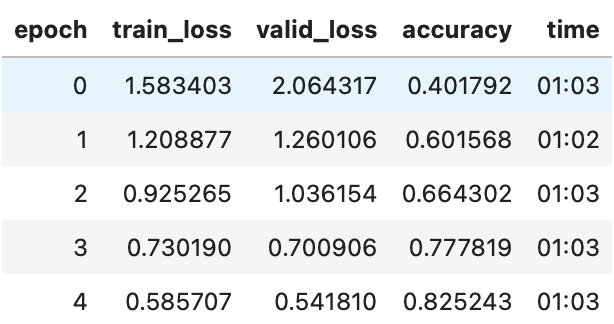
这是一个很好的基线,因为我们没有使用预训练模型,但我们可以做得更好。当处理从头开始训练或微调到与预训练中使用的非常不同的数据集的模型时,有一些其他技术真的很重要。在本章的其余部分,我们将考虑您希望熟悉的一些关键方法。第一个是规范化您的数据。
Normalization
在训练模型时,如果您的输入数据标准化,即平均值为0,标准差为1,这会有所帮助。但大多数图像和计算机视觉库对像素使用0到255之间的值,或0到1之间的值;无论哪种情况,您的数据都不会平均值为0,标准差为1。
让我们抓住一批数据并查看这些值,方法是取除通道轴(轴1)以外的所有轴上的平均值:
1
2
3
4
5
x, y = dls.one_batch()
x.mean(dim=[0, 2, 3]), x.std(dim=[0, 2, 3])
(TensorImage([0.4842, 0.4711, 0.4511], device='cuda:5'),
TensorImage([0.2873, 0.2893, 0.3110], device='cuda:5'))
正如我们所期望的,平均值和标准差不是很接近期望值。幸运的是,通过添加 Normalize 变换,在fastai中可以轻松实现数据规范化。这同时作用于整个 mini-batch,因此您可以将其添加到数据块的 batch_tfms 部分。您需要将您想要使用的平均值和标准差传递给此变换;fastai附带已定义的标准 ImageNet 平均值和标准差。(如果您没有将任何统计数据传递给 Normalize 变换,fastai将自动从您的一批数据中计算它们。)
让我们添加此变换(使用 imagenet_stats , 因为 Imagenette 是 ImageNet 的子集),现在查看一批数据:
1
2
3
4
5
6
7
8
def get_dls(bs, size):
dblock = DataBlock(blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
get_y=parent_label,
item_tfms=Resize(460),
batch_tfms=[*aug_transforms(size=size, min_scale=0.75),
Normalize.from_stats(*imagenet_stats)])
return dblock.dataloaders(path, bs=bs)
1
dls = get_dls(64, 224)
1
2
3
4
5
x,y = dls.one_batch()
x.mean(dim=[0,2,3]),x.std(dim=[0,2,3])
(TensorImage([-0.0787, 0.0525, 0.2136], device='cuda:5'),
TensorImage([1.2330, 1.2112, 1.3031], device='cuda:5'))
让我们看看这对训练我们的模型有什么影响:
1
2
3
model = xresnet50(n_out=dls.c)
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(), metrics=accuracy)
learn.fit_one_cycle(5, 3e-3)
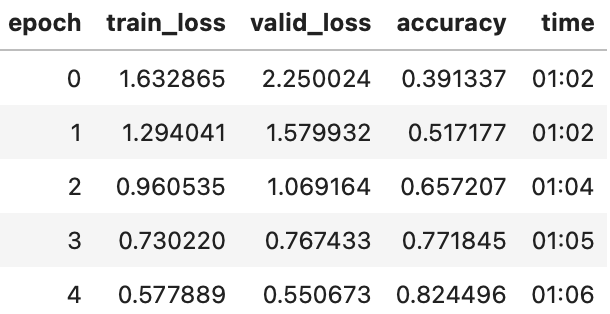
虽然它在这方面只有一点帮助,但在使用预训练模型时,规范化变得尤为重要。预训练模型只知道如何处理它以前见过的类型的数据。如果训练数据中的平均像素值为0,但您的数据以0为像素的最小可能值,那么模型将看到与预期截然不同的东西!
这意味着,当您分发模型时,您还需要分发用于规范化的统计数据,因为任何使用它进行推理或迁移学习的人都需要使用相同的统计数据。同样,如果您使用的是其他人训练过的模型,请确保您了解他们使用的规范化统计信息,并匹配它们。
在前几章中,我们不必处理规范化,因为当通过 cnn_learner 使用预训练模型时,fastai库会自动添加适当的规范化变换;模型使用特定数据 Normalize 进行了预训练(通常来自ImageNet数据集),因此库可以为您填写这些统计信息。请注意,这仅适用于预训练模型,这就是为什么我们需要在从头开始训练时在这里手动添加此信息。
到目前为止,我们的所有训练都以224大小完成。在开始之前,我们可以开始更小的训练。这被称为 progressive resizing。
Progressive Resizing
当fast.ai及其学生团队在2018年赢得DAWNBench比赛时,最重要的创新之一是非常简单的事情:开始使用小图像训练,结束使用大图像的训练。用小图像花大部分时间进行训练,有助于更快地完成训练。使用大图像完成训练可以提高最终的准确性。我们称这种方法为 progressive resizing。
正如我们所看到的,卷积神经网络学到的特征类型与图像的大小没有任何特定——早期层可以找到边缘和梯度等东西,后层可能会找到鼻子和日落等东西。因此,当我们在训练过程中更改图像大小时,并不意味着我们必须为模型找到完全不同的参数。
但很明显,小图像和大图像之间存在一些差异,因此我们不应该期望我们的模型继续完全正常工作,没有任何变化。这让你想起了什么吗?当我们发展这个想法时,它提醒我们迁移学习!我们正在试图让我们的模型学会做一些与之前学到的事情略有不同的事情。因此,在调整图像大小后,我们应该使用 fine_tune 方法。
逐步调整大小还有一个好处:这是另一种形式的数据增强。因此,您应该希望看到经过渐进调整大小训练的模型得到更好的泛化。
要实现渐进调整大小,最方便的是,您首先创建一个 get_dls 函数,该函数像我们之前在部分中所做的那样采用图像大小和批处理大小,并返回您的 DataLoaders:
现在,您可以创建小型 DataLoaders,并以通常的方式使用 fit_one_cycle,训练时间比平时少几个 epoch:
1
2
3
4
dls = get_dls(128, 128)
learn = Learner(dls, xresnet50(n_out=dls.c), loss_func=CrossEntropyLossFlat(),
metrics=accuracy)
learn.fit_one_cycle(4, 3e-3)
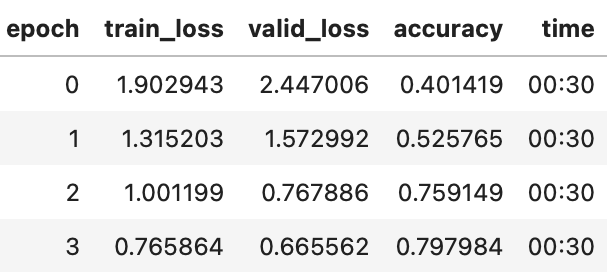
然后,您可以替换 Learner 内部的 DataLoaders,并进行微调:
1
2
learn.dls = get_dls(64, 224)
learn.fine_tune(5, 1e-3)
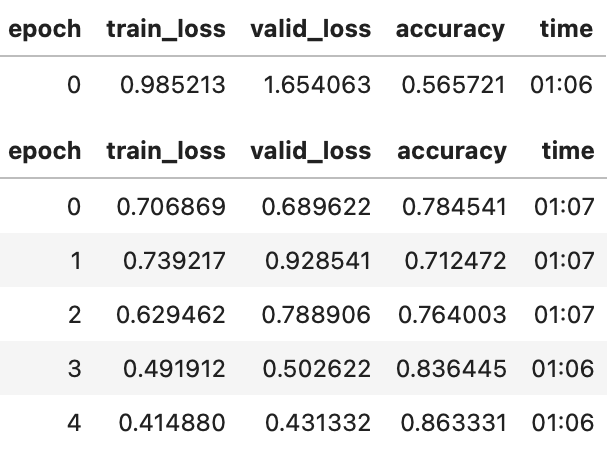
如您所见,我们的性能要好得多,每个 epoch 对小图像的初始训练都要快得多。
您可以随心所欲地重复增加大小和训练更多 epoch 的过程,以获得您想要的图像大小——但当然,使用大于原始图像大小的图像不会有任何好处。
请注意,对于迁移学习,渐进式调整大小实际上可能会损害性能。如果您的预训练模型与迁移学习任务和数据集非常相似,并且是在类似大小的图像上训练的,权重不需要太大变化,则最有可能发生这种情况。在这种情况下,对较小图像的训练可能会损坏预训练的权重。
另一方面,如果迁移学习任务将使用与训练前任务中使用的不同大小、形状或样式的图像,则渐进调整大小可能会有所帮助。和往常一样,“有帮助吗?” 的答案是 “试试看!”
我们可以尝试的另一件事是将数据增强应用于验证集。到目前为止,我们只将其应用于训练集;验证集总是获得相同的图像。但也许我们可以尝试对验证集的几个增强版本进行预测并对其进行平均。我们接下来会考虑这种方法。
Test Time Augmentation
我们一直在使用随机裁剪来获得一些有用的数据增强,这导致了更好的泛化能力,并导致对更少的训练数据的需求。当我们使用随机裁剪时,fastai将自动为验证集使用中心裁剪——也就是说,它将在图像中心选择最大的正方形区域,而不会越过图像的边缘。
这经常会有问题。例如,在多标签数据集中,有时有面向图像边缘的小目标;这些小目标可以通过中心裁剪完全被裁掉。即使对于我们的 pet breed 分类问题,也可能裁剪出识别正确品种所需的关键特征,如鼻子颜色。
解决这个问题的一个方法是避免完全随机裁剪。相反,我们可以简单地挤压或拉伸矩形图像,以适应正方形空间。但是我们错过了一个非常有用的数据增强,我们也使模型的图像识别更加困难,因为它必须学习如何识别挤压和挤压的图像,而不仅仅是正确比例的图像。
另一个解决方案是不要以中心裁剪进行验证,而是从原始矩形图像中选择多个区域进行裁剪,将每个区域传递给我们的模型,并获取预测的最大值或平均值。事实上,我们不仅可以针对不同的裁剪这样做,还可以针对我们所有测试时增强参数的不同值。这被称为测试时增强(TTA)。
根据数据集,测试时增强可以显著提高准确性。它根本不改变训练所需的时间,但会根据请求的测试时间增强图像的数量增加验证或推理所需的时间。默认情况下,fastai将使用未增强的中心裁剪图像加上四个随机增强的图像。
您可以将任何 DataLoader 传递给 fastai 的 tta 方法;默认情况下,它将使用您的验证集:
1
2
3
4
preds,targs = learn.tta()
accuracy(preds, targs).item()
0.8737863898277283
正如我们所看到的,使用 TTA 可以很好地提高我们的性能,不需要额外的训练。然而,这确实会使推理速度变慢——如果您平均为TTA提供五张图像,推理速度会慢五倍。
我们看到了一些数据增强如何帮助训练更好的模型的例子。现在让我们专注于一种名为Mixup的新数据增强技术。
Mixup
张鸿毅等人在2017年的论文《mixup: Beyond Empirical Risk Minimization》中介绍的 mixup 是一种强大的数据增强技术,可以提供显著更高的准确性,特别是当您没有太多数据,也没有在类似于数据集的数据上训练的预训练模型时。文章解释说:“虽然数据增强会改进泛化,但该方法依赖于数据集,因此需要使用专家知识。” 例如,作为数据增强的一部分,翻转图像是常见的,但您应该只水平翻转还是垂直翻转?答案是,这取决于您的数据集。此外,如果翻转不能为您提供足够的数据增强,则无法“flip more”。
对于每张图像,Mixup 如下:
- 从数据集中随机选择另一张图像。
- 随机挑选一个权重。
- 在图像中取加权平均值(使用所选图像第2步的权重);这将是您的自变量。
- 用图像的标签取此图像标签的加权平均值(相同权重);这将是您的因变量。
在伪代码中,我们正在这样做(其中t是我们加权平均值的权重):
1
2
3
4
image2,target2 = dataset[randint(0,len(dataset)]
t = random_float(0.5,1.0)
new_image = t * image1 + (1-t) * image2
new_target = t * target1 + (1-t) * target2
为了做到这一点,我们的目标需要独热编码。本文使用图7-1中的方程(其中λ与我们伪代码中的t相同)来描述这一点。

第三张图像是通过添加第一个图像的0.3倍和第二个图像的0.7倍来构建的。在这个示例中,模型应该预测 “church” 还是 “gas station” ?正确的答案是30%的教堂和70%的加油站,因为如果我们对独热编码目标进行线性组合,我们将得到这些。例如,假设我们有10个类,而“教堂”由索引2表示,“加油站”由索引7表示。独热编码表示如下所示:
1
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0] and [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
因此,这是我们的最终目标:
1
[0, 0, 0.3, 0, 0, 0, 0, 0.7, 0, 0]
通过向 Learner 添加 callback,这一切都在fastai内部为我们完成了。回调是fastai内部用于在训练循环中注入自定义行为(如 learning rate schedule 或 mixed precision 的训练)。在第16章中,您将学习所有关于 callback的信息,包括如何制作自己的 callback。
以下是我们使用Mixup训练模型的方法:
1
2
3
4
model = xresnet50()
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(),
metrics=accuracy, cbs=Mixup)
learn.fit_one_cycle(5, 3e-3)
当我们用以这种方式 “mixed up” 的数据训练模型时会发生什么?显然,训练会更难,因为很难看到每张图像中的内容。该模型必须预测每张图像有两个标签,而不仅仅是一个标签,并计算每个标签的加权量。然而,过拟合似乎不太可能成为一个问题,因为我们没有在每个 epoch 显示相同的图像,而是显示两种图像的随机组合。
与我们见过的其他增强方法相比,mixup 需要更多的 epoch 来训练以获得更好的准确性。您可以使用fastai repo中的示例/train_imagenette.py脚本来尝试使用或不使用Mixup来训练Imagenette。在撰写本报告时,Imagenette repo中的排行榜显示,所有领先结果使用Mixup 大于80个 epoch 的训练,而不使用 Mixup 较少的epoch。这也符合我们使用Mixup的经验。
Mixup如此令人兴奋的原因之一是它可以应用于照片以外的数据类型。事实上,有些人甚至通过在模型内的激活上使用Mixup,而不仅仅是在输入上,表现出了良好的效果——这也允许Mixup用于NLP和其他数据类型。
Mixup为我们处理了另一个微妙的问题,那就是实际上,对于我们之前见过的模型来说,我们的损失不可能完美。问题在于,我们的标签是 1 和0,但softmax和sigmoid的输出永远不能等于1或0。这意味着训练我们的模型会使我们的激活更接近这些值, 因此,我们所做的 epoch 越多,我们的激活就越极端。
使用Mixup,我们不再有这个问题,因为只有当我们碰巧与同一类的另一个图像“mixup”时,我们的标签才会正好是1或0。剩下的时候,我们的标签将是一个线性组合,例如我们早些时候在教堂和加油站的例子中获得的0.7和0.3。
然而,这方面的一个问题是,Mixup“意外”使标签大于0或小于1。也就是说,我们没有明确告诉我们的模型,我们希望以这种方式更改标签。因此,如果我们想进行更改,使标签更接近或远离0和1,我们必须更改Mixup的数量——这也改变了数据增强的数量,这可能不是我们想要的。然而,有一种方法可以更直接地处理这个问题,那就是使用标签平滑。
Label Smoothing
在损失的理论表达式中,在分类问题中,我们的目标是独热编码的(在实践中,我们倾向于避免这样做来节省内存,但我们计算的损失与我们使用独热编码是一样的)。这意味着该模型被训练为除一个类别外的所有类别返回0,并训练返回1。即使0.999也“不够好”;该模型将获得梯度,并学会以更高的信心预测激活。这鼓励了过拟合,并在推理时为您提供了一个不会给出有意义概率的模型:即使不太确定,它总是会对预测类别说1,只是因为它是以这种方式训练的。
如果您的数据没有完美的标签,这可能会变得非常有害。在我们在第2章研究的熊类中,我们看到一些图像被错误地标记或包含两种不同类型的熊。一般来说,您的数据永远不会完美。即使标签是由人类手工制作的,他们也可能犯错误,或对更难标记的图像存在意见分歧。
进而,我们可以将所有 1 替换为略小于 1 的数字,将 0 替换为略高于 0 的数字,然后进行训练。这叫做标签平滑。通过鼓励您的模型不那么自信,标签平滑将使您的训练更加健壮,即使有错误的标签数据。结果将是一个在推理方面更好地推广的模型。
这是 label smoothing 在实践中如何工作的: 我们从一个独热编码标签开始, 使用 $\frac{\epsilon}{N}$ 替换掉所有的 0, 其中 $N$ 是类别的数量, $\epsilon$ 是参数。 因为我们想要标签加起来等于1, 因此我们将 1 替换为 $1 - \epsilon + \frac{\epsilon}{N}$。 这样,我们就不会鼓励模型过度自信地预测一些事情。在我们有10个类的Imagenette示例中,目标变成了一些像这样的东西(这里是与索引3对应的目标):
1
[0.01, 0.01, 0.01, 0.91, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01]
在实践中,我们不想对标签进行独热编码,幸运的是,我们不需要(独热编码只是可以解释标签平滑和可视化)。
要在实践中使用此功能,我们只需在给 Learner 的 callback 中更改损失函数:
1
2
3
4
model = xresnet50()
learn = Learner(dls, model, loss_func=LabelSmoothingCrossEntropy(),
metrics=accuracy)
learn.fit_one_cycle(5, 3e-3)
与Mixup一样,在训练更多 epoch 之前,您通常不会看到标签平滑的重大改进。你自己试试看:在标签平滑显示改善之前,你必须训练多少个 epoch?
Conclusion
您现在已经看到了在计算机视觉中训练最先进的模型所需的一切,无论是从头开始还是使用迁移学习。现在你所要做的就是对自己的问题进行实验!查看使用Mixup和标签平滑进行更长时间的训练是否避免了过拟合,并为您提供更好的结果。尝试progressive resizing并测试时增强。
最重要的是,请记住,如果您的数据集很大,整个事情的原型是没有意义的。找到一个代表整体的小子集,就像我们对 Imagenette 所做的那样,并在上面进行实验。
-
Previous
【深度学习】Hierarchical Cross-Modality Semantic Correlation Learning Model for Multimodal Summarization -
Next
【深度学习】SGEITL:Scene Graph Enhanced Image-Text Learning for Visual Commonsense Reasoning