Abstract
这篇文章提出一个新任务, 无监督视觉语言语法归纳。
给定一个 image-caption 对,目标是同时提取图像和语言的共享层次结构。
这种基于两种模态的结构化输出,是朝着对多模态信息的高层次理解迈出的明确一步。
除了传统的可视化语法归纳任务中存在的挑战外,VL语法归纳还需要一个模型来捕获上下文语义并执行细粒度对齐。
为了解决这些问题,这篇文章提出了一种新的方法CLIORA,该方法为树的不同层次的所有成分构建了一个共享的视觉-语言区域树结构,该结构具有上下文相关的语义。
它通过对比学习训练计算每个组成部分和图像区域之间的匹配分数。
它集成了两个层级的融合,即score-level 和 feature-level,从而允许细粒度的对齐。
最后引入了一个新的评估指标: Critical Concept Recall Rate, (CCRR)来显式评估VL语法归纳,在Flickr30k实体上显示出了2.6%的改进。
通过两个派生任务来评估模型,即语言语法归纳和 phrase grounding,并在这两个方面都进行了改进。
LIMITATION AND FUTURE WORK
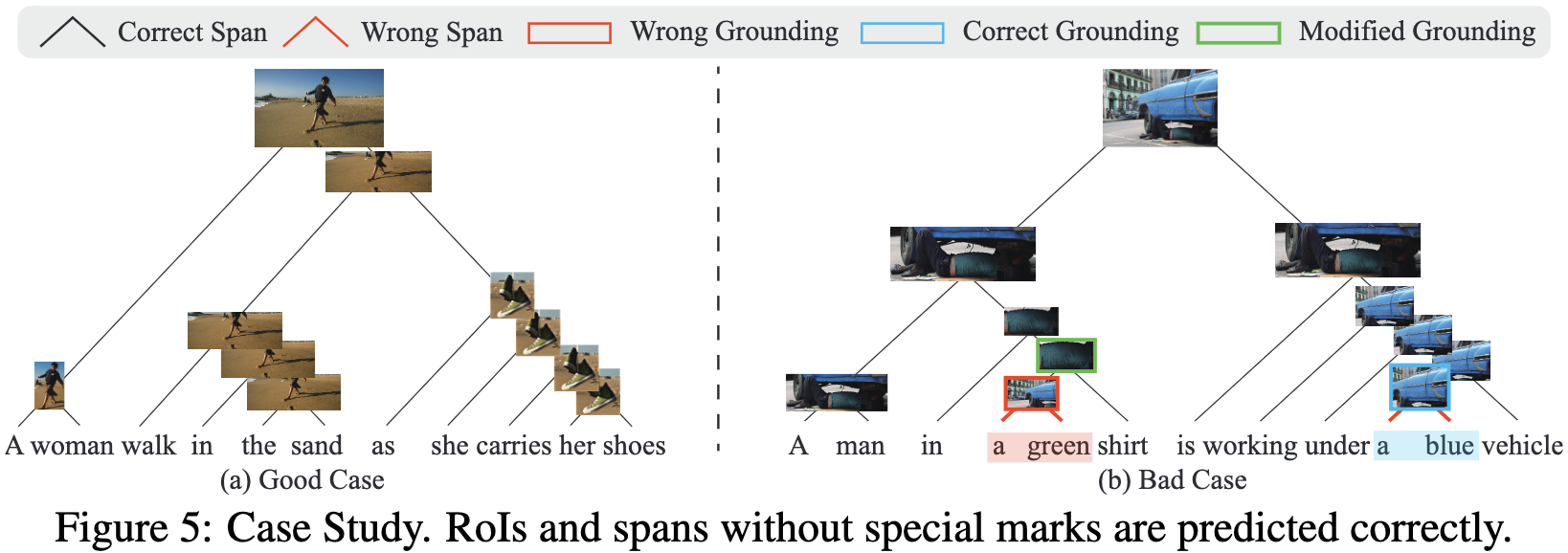
虽然CLIORA已经取得了令人鼓舞的结果(成功的例子见图5(a)和附录H),但无监督VL语法归纳远远不能令人满意。图5(b)演示了一个典型的失败案例,错误地预测了一个绿色区域,该区域在 ground-truth tree 中应该是绿色t恤。这个错误的 span 被错误地 grounded 到一个包含绿色建筑的大区域。有趣的是,在结合更多的上下文和组成一个更大 span 的绿色衬衫后,grounding 结果被修改为一个正确的区域(绿色矩形)。这一失败案例揭示了恰当建模上下文语义的重要性,这突出了我们提出的任务的主要挑战,并呼吁未来对更好的上下文模型的研究。
接下来,为VL语法归纳建模这种共享结构的最佳方法是什么? 一个有前景的扩展可能是探索视觉结构,以正则化共享VL语法。值得注意的是,视觉图像还包含丰富的空间和语义结构(Si & Zhu,2011;赵等人,2017),可以与 contituency trees 对齐。利用这种结构也可能有助于产生更有意义的共享结构。
回到工作的动机,人类如何用这样的共享空间建模和处理多模态信息? 这项工作提供了一个关于语法归纳和 phrase grounding 的潜在答案。然而,在人类认知计算模型中使用密集向量和符号结构之间的争论从未停止过(Tang等人,2019年)。这个谜题也给我们留下了广阔的空间,让我们去探索人类多模态共享世界的其他潜在解释。
-
Previous
【深度学习】VOLO: Vision Outlooker for Visual Recognition -
Next
【深度学习】VLGrammar: Grounded Grammar Induction of Vision and Language