Abstract
图像标题是视觉语言理解中的一项基本任务,该模型对给定的输入图像预测一个文本信息标题。
这篇文章提出了一种解决此任务的简单方法。
使用CLIP编码作为标题的前缀,通过使用一个简单的映射网络,然后微调一个语言模型来生成图像标题。
最近提出的CLIP模型包含了丰富的语义特征,这些特征经过了文本语境的训练,使其更适合视觉语言感知。
关键思想是结合一个预训练的语言模型(GPT2),获得对视觉和文本数据的广泛理解。
因此,该方法只需要相当快速的训练就可以生成一个合格的字幕模型。
无需额外的标注或预训练,它可以高效地为大规模和多样化的数据集生成有意义的标题。
令人惊讶的是,即使只训练了映射网络,该方法也能很好地工作,而CLIP和语言模型都保持冻结,从而允许使用较少可训练参数的轻量级架构。
通过定量评估,证明该模型在具有挑战性的 Conceptual Captions 和 nocaps 数据集上取得了与最先进的方法相媲美的结果,同时它更简单、更快、更轻。
Conclusion
总之,基于 CLIP 的图像字幕方法使用简单,不需要任何附加标注,而且训练起来更快。
尽管这篇文章提出了一个更简单的模型,但随着数据集变得更加丰富和多样化,它显示出了更多的优点。
作者认为其方法是一个新的图像字幕范式的一部分,专注于利用现有的模型,而只训练一个最小的映射网络。
这种方法本质上是学习使预先训练的模型的现有语义理解适应目标数据集的风格,而不是学习新的语义实体。
利用这些强大的预训练模型将在不久的将来获得吸引力。
因此,了解如何利用这些组件非常有意义。
Q: 如何提取并利用图像特征的?
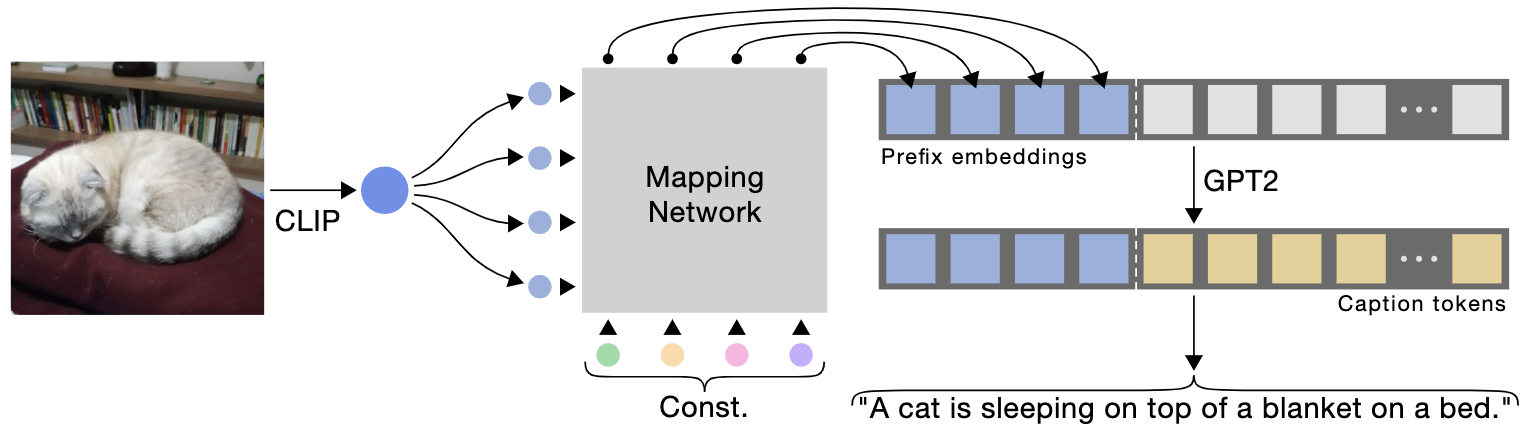
transformer-based 结构的总览, 使得 CLIP 和 语言模型GPT-2 被冻结的情况下,生成有意义的 captions。为了提取固定长度的前缀,我们从CLIP嵌入空间训练一个轻量级的基于 Transformer 的映射网络,并训练一个学习到的常量到GPT-2。在推理时,使用GPT-2生成给定前缀嵌入的标题。还提出了一个使用基于mlp的架构。
-
Previous
【深度学习】Semisupervised Spectral Learning With Generative Adversarial Network for Hyperspectral Anomaly Detection -
Next
【深度学习】Pythia v0.1: the Winning Entry to the VQA Challenge 2018