本文介绍了使用Spektral API实现图卷积网络(GCN)的过程,Spektral API 是一个基于Tensorflow 2的图深度学习Python库。我们将使用 CORA 数据集进行半监督节点分类,类似于Thomas Kipf和Max Welling(2017)在原始GCN论文中提出的工作。
Dataset Overview
CORA citation network 数据集由2708个节点组成,每个节点代表一篇文献或一篇技术论文。节点特征是bag-of-words 表示,表示文档中存在一个词。因此,vocabulary 和节点特征包含1433个单词。

我们将数据集视为无向图,其中边表示一个文档是否引用另一个文档,反之亦然。此数据集中没有边特征。该任务的目的是将节点(或文档)划分为7个不同的类,与论文的研究领域相对应。这是一个具有 Single Mode 数据表示设置的 single-label multi-class 分类问题。
这个实现也是 Transductive Learning 的一个例子,其中神经网络在训练期间看到所有数据,包括测试数据集。这与 Inductive Learning 形成对比,Inductive Learning 是一种典型的监督学习,在训练过程中测试数据是分开的。
Text Classification Problem
既然我们要根据文本特征对文档进行分类,那么机器学习处理这个问题的常见方法是将其视为监督文本分类问题。使用这种方法,机器学习模型将只根据文档自身的特征来学习每个文档的隐藏表示。
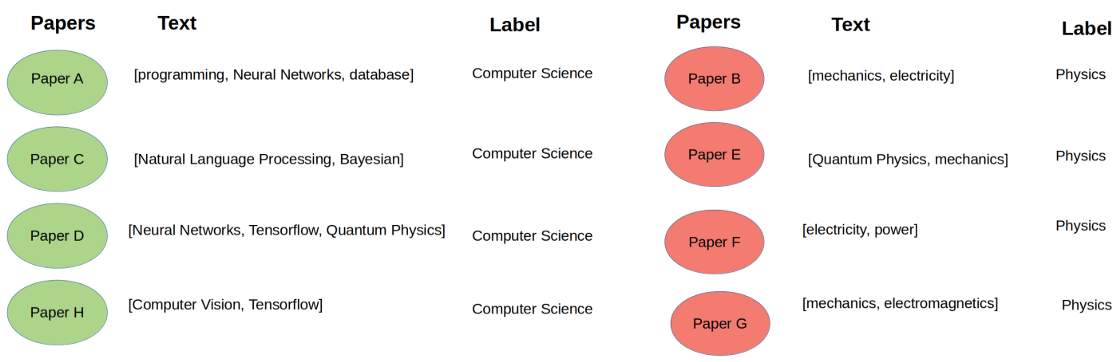 如果每个类都有足够的标记示例,这种方法可能会很好地工作。不幸的是,在现实世界的情况下,标记数据可能是昂贵的。
如果每个类都有足够的标记示例,这种方法可能会很好地工作。不幸的是,在现实世界的情况下,标记数据可能是昂贵的。
那么是否存在解决这个问题的另一种方法?
技术论文除了自身的文本内容外,通常还会引用其他相关论文。从直观上看,被引用的论文很可能属于类似的研究领域。
在这个 citation network 数据集中,除了它自己的文本内容, 我们希望利用每篇论文的引文信息。因此,数据集现在已经变成了一个 paper 的 network。
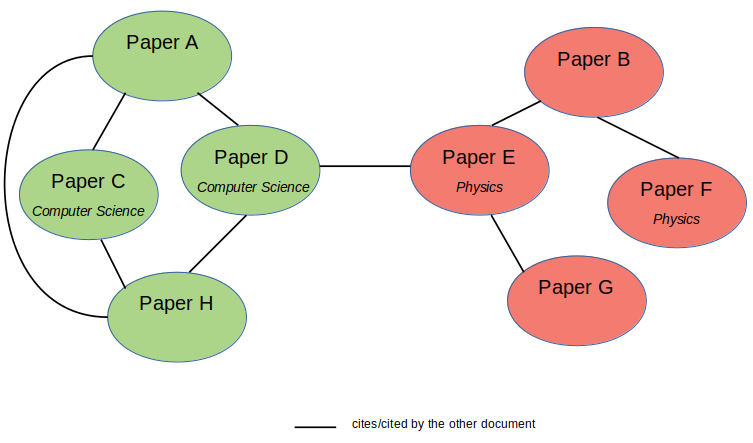
使用这种配置,我们可以利用图神经网络,如图卷积网络(GCNs),来建立一个模型,学习文档之间的互联以及它们自己的文本特征。GCN模型不仅会根据自己的特征,还会根据邻近节点的特征来学习节点(或文档)的隐藏表示。因此,我们可以减少标记样本的数量,并利用 邻接矩阵(A) 或图中的节点连通性实现半监督学习。
图神经网络可能有用的另一种情况是,每个样本本身没有不同的特征,但样本之间的关系可以丰富特征表示。
Implementation of Graph Convolutional Networks
Loading and Parsing the Dataset
在这个实验中,我们将使用构建在Tensorflow 2上的Spektral API来构建和训练一个GCN模型。尽管Spektral 提供内置函数来加载和预处理CORA数据集,但在本文中,我们将从这里下载原始数据集,以便更深入地理解数据预处理和配置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import random
all_data = []
all_edges = []
for root, dirs, files in os.walk("../datasets/GCNs/cora"):
for file in files:
if '.content' in file:
with open(os.path.join(root, file), 'r') as f:
all_data.extend(f.read().splitlines())
elif 'cites' in file:
with open(os.path.join(root, file), 'r') as f:
all_edges.extend(f.read().splitlines())
print(all_data[0])
print(all_edges[0])
random_state = 77
all_data = random.shuffle(all_data)
在 cora.content 文件中,每一行由几个元素组成: 第一个元素表示文档(或节点)ID,直到最后一个元素为止的第二个元素表示节点特征,最后一个元素表示特定节点的标签。
在 cora.cites 文件中,每行包含一个文档(或节点) IDs 的元组。元组的第一个元素表示被引用的论文的ID,第二个元素表示包含引用的论文。虽然这个配置表示一个有向图,但在这种方法中,我们将数据集视为一个无向图。
加载数据之后,我们构建Node Features Matrix (X) 和一个包含相邻节点元组的列表。这个边列表将用于构建一个图,从中我们可以获得 Adjacency Matrix(A)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
labels = []
nodes = []
X = []
for i, data in enumerate(all_data):
elements = data.split('\t')
# 最后一个元素是标签
labels.append(elements[-1])
# 第二个到倒数第二个是 X
X.append(elements[1:-1])
# 第一个是节点
nodes.append(elements[0])
X = np.array(X, dtype=int)
N = X.shape[0] # the number of nodes
F = X.shape[1] # the size of node features
print("X shape: ", X.shape)
edge_list = []
for edge in all_edges:
e = edge.split('\t')
edge_list.append((e[0], e[1]))
print('\nNumber of nodes (N): ', N)
print('\nNumber of features (F) of each node: ', F)
print('\nCategories: ', set(labels))
num_classes = len(set(labels))
print('\nNumber of classes: ', num_classes)

Setting the Train, Validation, and Test Mask
我们将 Node Features Matrix(X) 和 Adjacency Matrix(A) 输入到神经网络。我们还将为每个训练、验证和测试数据集设置长度为 N 的 Boolean masks。当它们属于相应的训练、验证或测试数据集时,这些mask 的元素为True。例如,对于训练数据,train mask的元素为True。
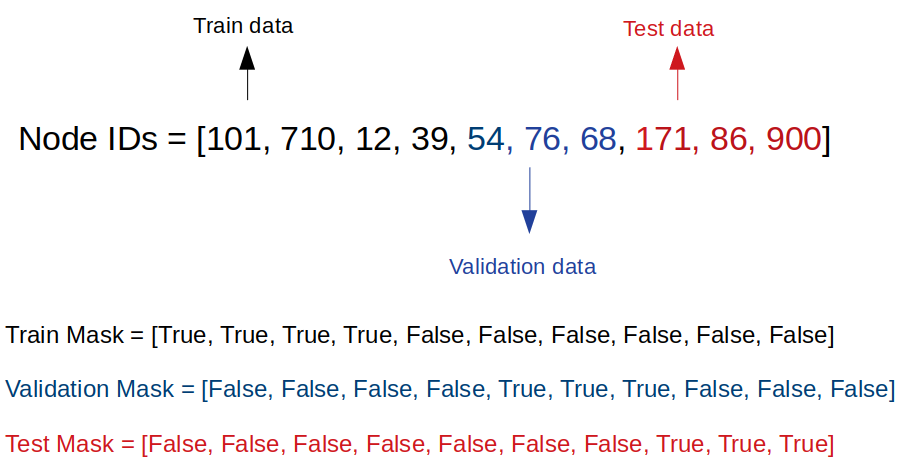
在论文中,他们为每个类挑选了20个标记好的样本。因此,有7个类,我们总共有140个带标签的训练样本。我们还将使用500个标记验证样本和1000个标记测试样本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
def limit_data(labels, limit=20, val_num=500, test_num=1000):
label_counter = dict((l, 0) for l in labels)
train_idx = []
for i in range(len(labels)):
label = labels[i]
if label_counter[label] < limit:
train_idx.append(i)
label_counter[label] += 1
if all(count == limit for count in label_counter.values()):
break
rest_idx = [x for x in range(len(labels)) if x not in train_idx]
val_idx = rest_idx[:val_num]
test_idx = rest_idx[val_num:(val_num+test_num)]
return train_idx, val_idx, test_idx
train_idx, val_idx, test_idx = limit_data(labels)
train_mask = np.zeros((N, ), dtype=bool)
train_mask[train_idx] = True
val_mask = np.zeros((N, ), dtype=bool)
val_mask[val_idx] = True
test_mask = np.zeros((N, ), dtype=bool)
test_mask[test_idx] = True
Obtaining the Adjacency Matrix
下一步是获取图的 Adjacency Matrix(A)。我们使用 NetworkX 来帮助我们做到这一点。我们将初始化一个图,然后将节点和边列表添加到图中。
1
2
3
4
5
6
G = nx.Graph()
G.add_nodes_from(nodes)
G.add_edges_from(edge_list)
A = nx.adjacency_matrix(G)
print('Graph info: ', nx.info(G))

Converting the label to one-hot encoding
与其他机器学习模型一样,构建GCN之前的最后一步是对标签进行编码,然后将它们转换为独热编码。
1
2
3
4
5
6
7
8
9
def encode_label(labels):
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)
labels = to_categorical(labels)
return labels, label_encoder.classes_
labels_encoded, classes = encode_label(labels)
print("labels_encoded: ", labels_encoded)
print("classes: ", classes)
现在,我们完成了数据预处理,并准备构建GCN
Build the Graph Convolutional Networks
GCN模型结构和超参数遵循GCN原始论文的设计。GCN模型将接受2个输入,节点Node Features Matrix (X) 和 Adjacency Matrix (A)。我们将使用 Dropout 层 和 L2正则化实现 2层GCN。我们还将设置最大训练 epochs 为 200,并实施 Early Stopping,patience 为 10。这意味着,一旦验证损失连续10个epoch没有减少,训练将停止。为了监控训练和验证的准确性和损失,我们还将在回调中调用TensorBoard。
在将 Adjacency Matrix(A) 输入到 GCN 之前,我们需要根据原文进行额外的预处理,执行 renormalization trick 技巧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# Parameters
channels = 16 # Number of channels in the first layer
dropout = 0.5 # Dropout rate for the features
l2_reg = 5e-4 # L2 regularization rate
learning_rate = 1e-2 # Learning rate
epochs = 200 # Number of training epochs
es_patience = 10 # Patience for early stopping
# Preprocessing operations
A = GraphConv.preprocess(A).astype('f4')
# Model definition
X_in = Input(shape=(F, ))
fltr_in = Input((N, ), sparse=True)
dropout_1 = Dropout(dropout)(X_in)
graph_conv_1 = GraphConv(channels,
activation='relu',
kernel_regularizer=l2(l2_reg),
use_bias=False)([dropout_1, fltr_in])
dropout_2 = Dropout(dropout)(graph_conv_1)
graph_conv_2 = GraphConv(num_classes,
activation='softmax',
use_bias=False)([dropout_2, fltr_in])
# Build model
model = Model(inputs=[X_in, fltr_in], outputs=graph_conv_2)
optimizer = Adam(lr=learning_rate)
model.compile(optimizer=optimizer,
loss='categorical_crossentropy',
weighted_metrics=['acc'])
model.summary()
tbCallBack_GCN = tf.keras.callbacks.TensorBoard(
log_dir='./Tensorboard_GCN_cora',
)
callback_GCN = [tbCallBack_GCN]
Note: 需要 tensorflow == 2.2.2, spektral == 0.6.0
Train the Graph Convolutional Networks
我们正在实施 Transductive Learning,这意味着我们将把整个 graph 提供给训练和测试。我们使用之前构造的 Boolean masks 分离训练、验证和测试数据。这些 masks 将被传递给 sample_weight 参数。我们将 batch_size 设置为整个图的大小,否则图将被打乱。
为了更好地评估每个类的模型性能,我们使用 F1-score 来代替准确性和损失指标。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# Train model
validation_data = ([X, A], labels_encoded, val_mask)
model.fit([X, A],
labels_encoded,
sample_weight=train_mask,
epochs=epochs,
batch_size=N,
validation_data=validation_data,
shuffle=False,
callbacks=[
EarlyStopping(patience=es_patience, restore_best_weights=True),
tbCallBack_GCN
])
# Evaluate model
X_te = X[test_mask]
A_te = A[test_mask,:][:,test_mask]
y_te = labels_encoded[test_mask]
y_pred = model.predict([X_te, A_te], batch_size=N)
report = classification_report(np.argmax(y_te,axis=1), np.argmax(y_pred,axis=1), target_names=classes)
print('GCN Classification Report: \n {}'.format(report))
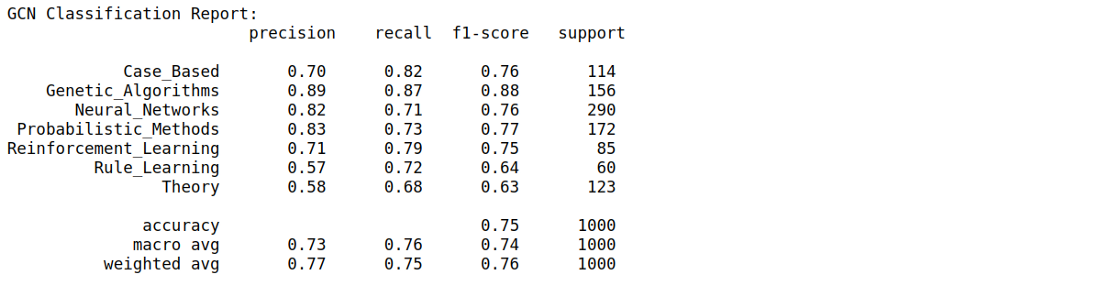
训练完成!
从分类报告中,我们得到 macro average F1-score 为 74%。
##
Reference
-
Previous
【深度学习】SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS -
Next
【深度学习】Understanding Graph Convolutional Networks for Node Classification