神经网络已被用于利用图的结构和性质。我们探索了构建图神经网络所需的组件,并 motivate 了它们背后的设计选择。
本文是两篇关于图神经网络的 Distill 出版物之一。请参 https://distill.pub/2021/understanding-gnns/ ,以理解图像上的卷积如何自然地归纳为图上的卷积。
图无处不在; 现实世界中的对象通常是根据它们与其他事物的 connections 来定义的。一组对象以及它们之间的 connections 自然地表示为图。十多年来,研究人员已经开发出了操作图数据的神经网络(称为图神经网络,或GNNs)。最近的发展提高了他们的能力和表达能力。我们开始看到 antibacterial discovery、physics simulations 、fake news detection、traffic prediction 和 recommendation systems 等领域的实际应用。
本文探索和解释现代图神经网络。我们把这项工作分成四部分。首先,我们看看什么样的数据最自然地表达为图,以及一些常见的例子。其次,我们探讨了图与其他类型数据的不同之处,以及在使用图时我们必须做出的一些特殊选择。第三,我们构建一个现代GNN,通过模型的每个部分,从该领域的 historic 建模创新开始。我们逐渐从一个基本的实现过渡到最先进的GNN模型。第四,也是最后,我们提供了一个GNN PlayGround,您可以在其中使用真实的任务和数据集,以建立一个更强的直觉,了解 GNN 模型的每个组件如何对其做出的预测作出贡献。
首先,让我们确定什么是图。图表示实体集合(节点)之间的关系(边)。
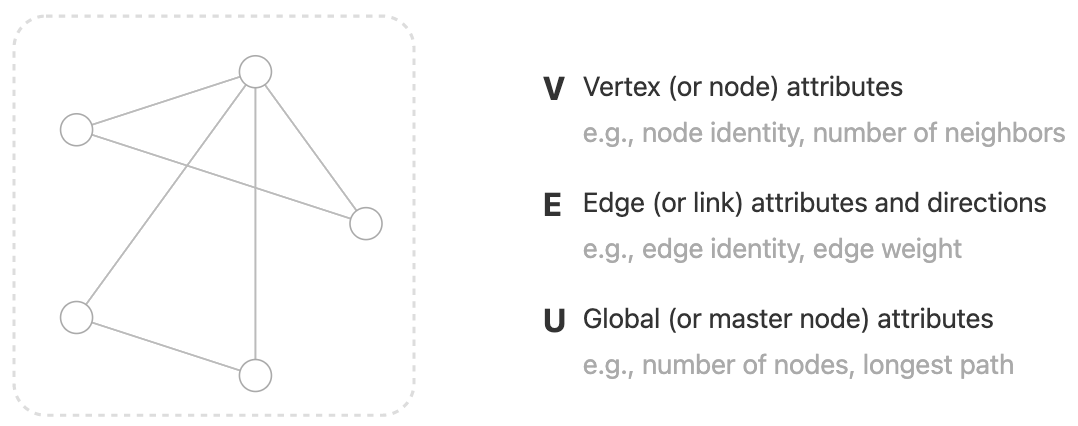 为了进一步描述每个节点、边或整个图,我们可以在图的每个部分中存储信息。
为了进一步描述每个节点、边或整个图,我们可以在图的每个部分中存储信息。
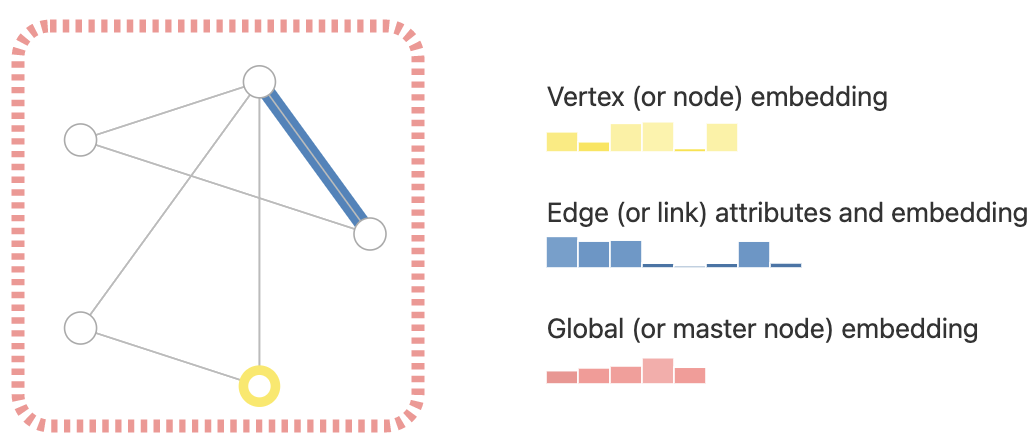 我们还可以通过将方向性与边(有向的、无向的)联系起来来 specialize 图。
我们还可以通过将方向性与边(有向的、无向的)联系起来来 specialize 图。
 图是非常灵活的数据结构,如果现在看起来很抽象,我们将在下一节通过示例使其具体化。
图是非常灵活的数据结构,如果现在看起来很抽象,我们将在下一节通过示例使其具体化。
Graphs and where to find them
您可能已经熟悉了某些类型的图数据,例如社交网络。然而,图是数据的一种非常强大和通用的表示,我们将展示两种您可能认为不能被建模为图的数据: 图像和文本。尽管有违直觉,但我们可以通过将图像和文本视为图来了解它们的对称性和结构,并建立一种直觉,这将有助于理解其他不太像网格的图数据,我们将在后面讨论。
Images as graphs
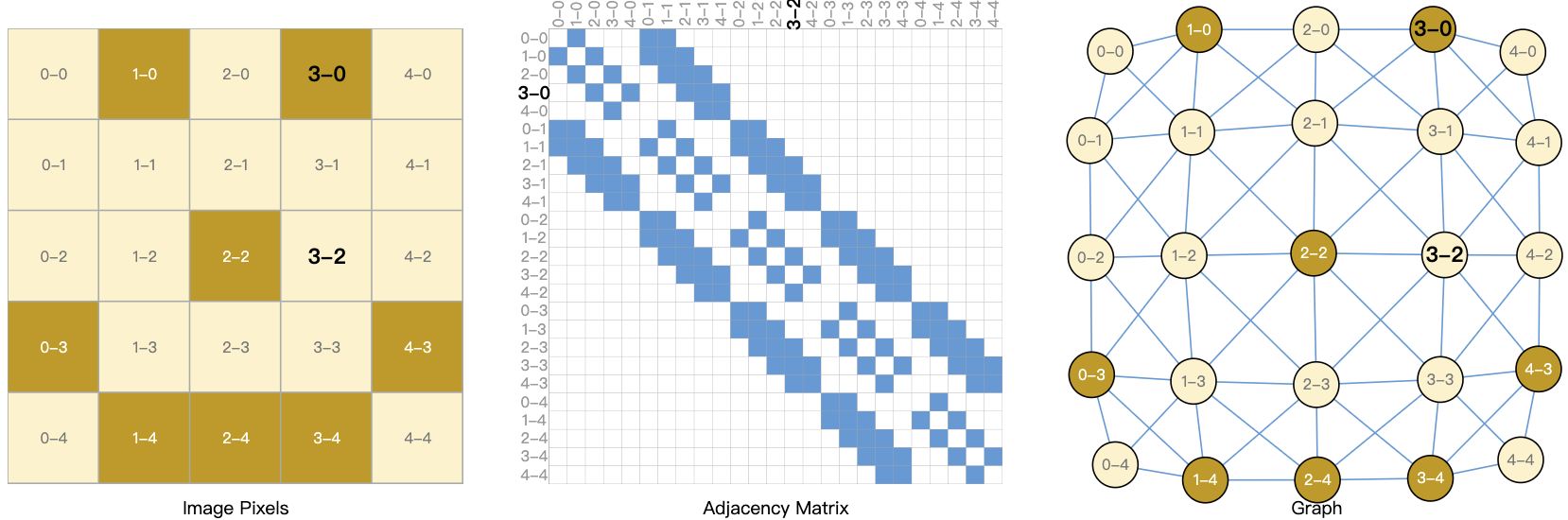
我们通常认为 图像 是带有通道的矩形网格,将它们表示为数组(例如 244x244x3 浮点数)。另一种理解图像的方法是将 图像 看作具有规则结构的图形,其中每个像素代表一个节点,并通过 边 与 相邻像素 连接。每个非边界像素正好有 8 个邻居,存储在每个节点上的信息是一个表示像素的 RGB 值的三维向量。
将图的连通性可视化的一种方法是通过它的邻接矩阵。我们对节点进行排序,在本例中,每个 smiley face 的 5x5 图像中 25 个像素, 用 $n_{nodes} \times n_{nodes}$ 的矩阵填充, 如果两个节点之间共享一条边。 请注意,下面的三种表示形式都是同一数据块的不同视图。
Text as graphs
我们可以将文本数字化,方法是将索引与每个字符、单词或标记联系起来,并将文本表示为这些索引的序列。这创建了一个简单的有向图,其中每个字符或索引都是一个节点,并通过边连接到它后面的节点。
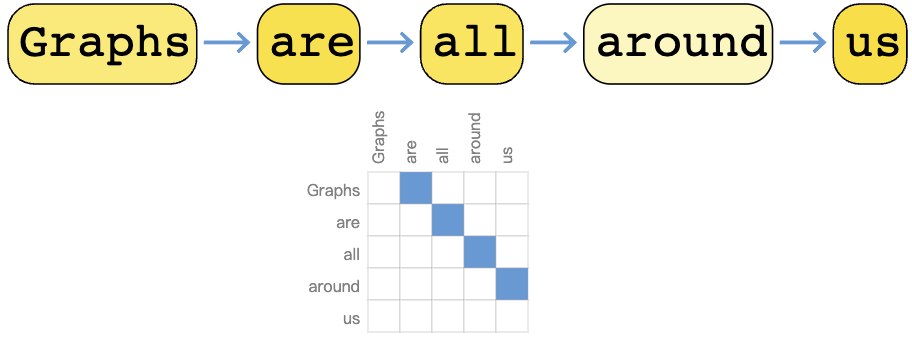
当然,在实践中,这通常不是文本和图像的编码方式:这些 图表示 是冗余的,因为所有的图像和文本都有非常规则的结构。例如,图像在其邻接矩阵中有一个 banded 结构,因为所有节点(像素)都连接在一个网格中。文本的邻接矩阵只是一条对角线,因为每个单词只与前一个单词和下一个单词连接。
Graph-valued data in the wild
图 是描述您可能已经熟悉的数据的有用工具。让我们转向结构更加异构的数据。在这些示例中,每个节点的邻居数量是可变的(与图像和文本的固定邻居大小相反)。除了图之外,这些数据很难用其他方式表达。
Molecules as graphs: 分子是物质的基本组成部分,由三维空间中的原子和电子构成。所有粒子都相互作用, 但是当一对原子彼此保持稳定的距离时,我们就说它们有共价键。不同的原子对和键有不同的距离(如单键、双键)。将3D对象描述为 图 是一种非常方便和常见的抽象,其中节点是原子,边是共价键。这是两个常见的分子,以及它们的相关图。


社交网络作为图。社交网络是研究人们、机构和组织的集体行为模式的工具。我们可以通过将个体建模为节点,将他们的关系建模为边,来构建一个代表一组人的图。

与图像和文本数据不同,社交网络没有相同的邻接矩阵。
Citation networks as graphs. 科学家在发表论文时经常引用其他科学家的研究成果。我们可以将这些引文网络可视化为一个图,其中每篇论文是一个节点,每个有向边是一篇论文与另一篇论文之间的引文。此外,我们还可以在每个节点中添加关于每篇论文的信息,比如在摘要的词嵌入。
Other examples. 在计算机视觉中,我们有时想在视觉场景中标记对象。然后,我们可以通过将这些对象视为节点,将它们的关系视为边来构建图。机器学习模型、编程代码和数学方程也可以用图来表达,其中变量是节点,边是将这些变量作为输入和输出的操作。您可能会在这些上下文中看到 “dataflow graph” 项。
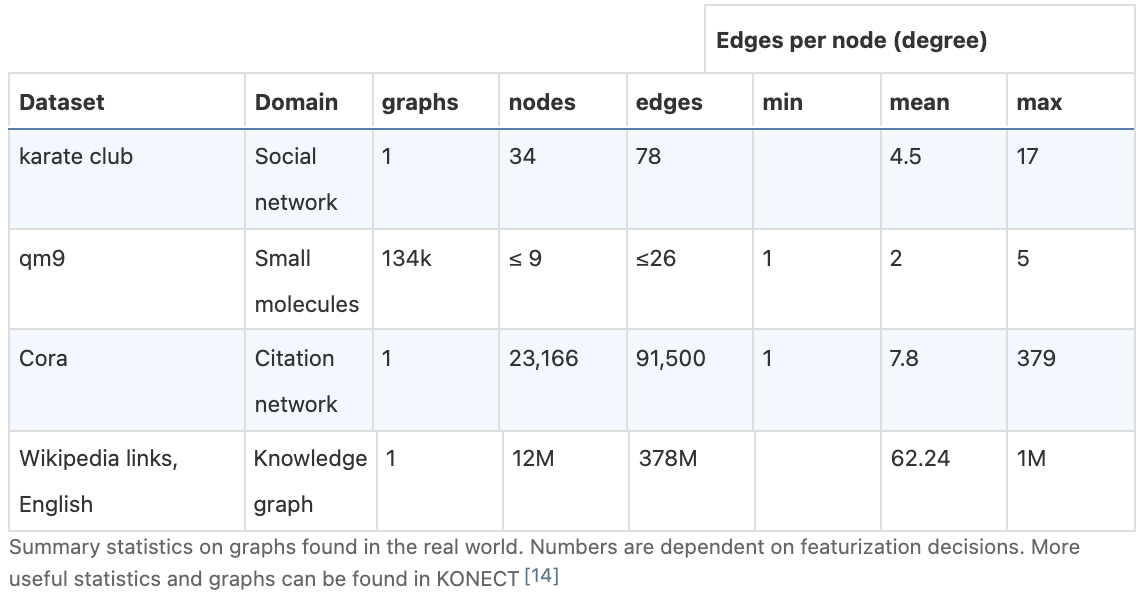
现实世界的图的结构可能在不同类型的数据之间有很大的差异,有些图有很多节点,但它们之间的连接很少,反之亦然。在节点、边的数量和节点的连通性方面,图数据集可以有很大的差异(在给定数据集内和数据集之间)。
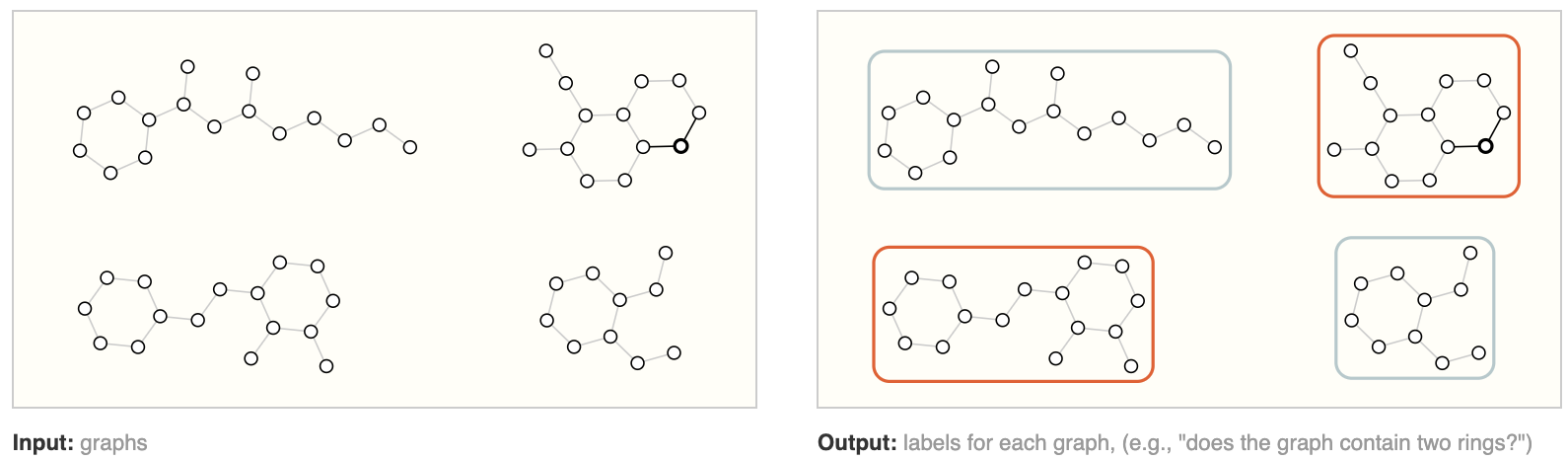
What types of problems have graph structured data?
我们已经描述了一些实际的图例子,但是我们想对这些数据执行什么任务呢?图上有三种一般类型的预测任务: 图级、节点级和边级。
在图级任务中,我们预测整个图的单个属性。对于节点级任务,我们预测图中每个节点的某些属性。对于边级任务,我们想要预测图中边的属性或存在。
对于上面描述的三个级别的预测问题(图级、节点级和边级),我们将展示以下所有问题都可以用一个 GNN 解决。但首先,让我们更详细地浏览一下这三类图预测问题,并提供每个问题的具体例子。
Graph-level task
在图级任务中,我们的目标是预测整个图的属性。例如,对于一个用图表示的分子,我们可能想要预测这个分子闻起来像什么,或者它是否会与与疾病有关的受体结合。
这类似于 MNIST 和 CIFAR 的图像分类问题,我们希望将一个标签与整个图像相关联。对于文本,一个类似的问题是情感分析,我们想要立即识别整个句子的情绪或情感。
Node-level task
节点级任务与预测图中每个节点的身份或角色有关。
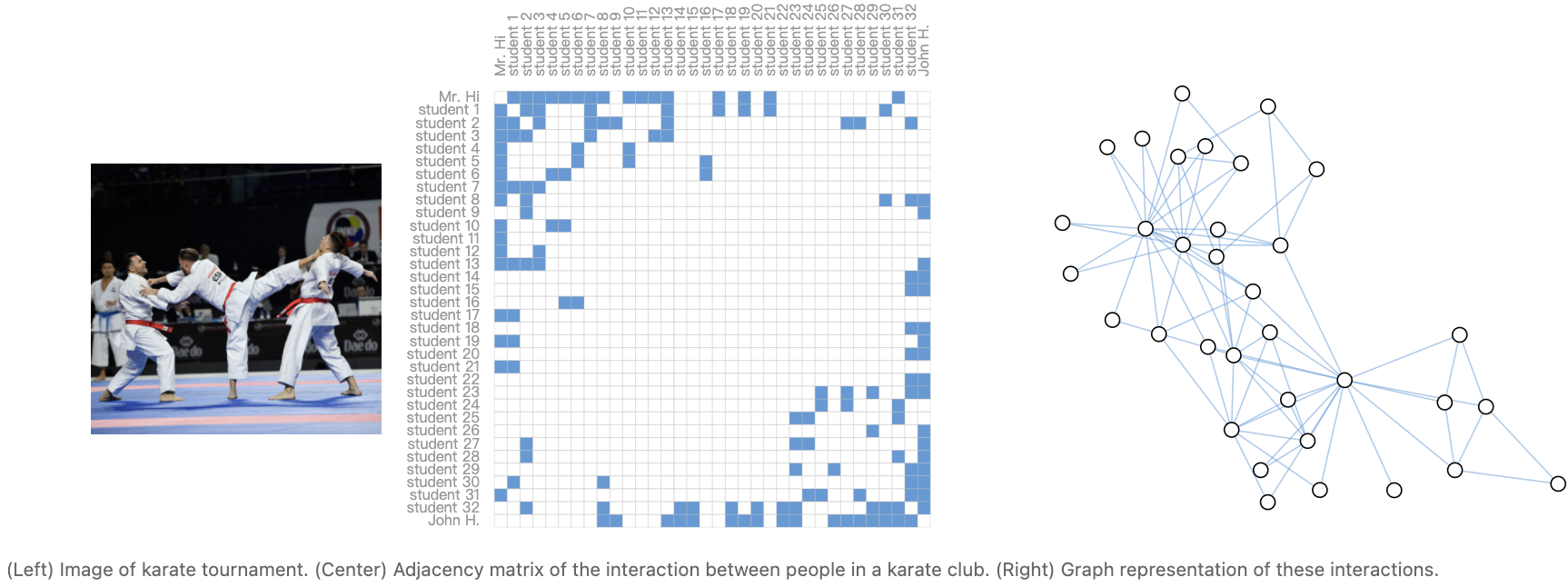
节点级预测问题的典型例子是 Zach’s karate club 。这个数据集是一个单一的社交网络图,由两支空手道俱乐部中的一支在政治分歧后宣誓效忠的个人组成。随着故事的发展,Mr. Hi (Instructor) 和 John H(Administrator)之间的不和造成了空手道俱乐部的分裂。节点代表每个空手道练习者,边代表空手道之外的这些成员之间的互动。预测问题是区分一个给定的成员在不和之后是忠于 Hi 先生还是忠于John H先生。在本例中,节点到 Instructor 或 Administrator 的距离与这个标签高度相关。
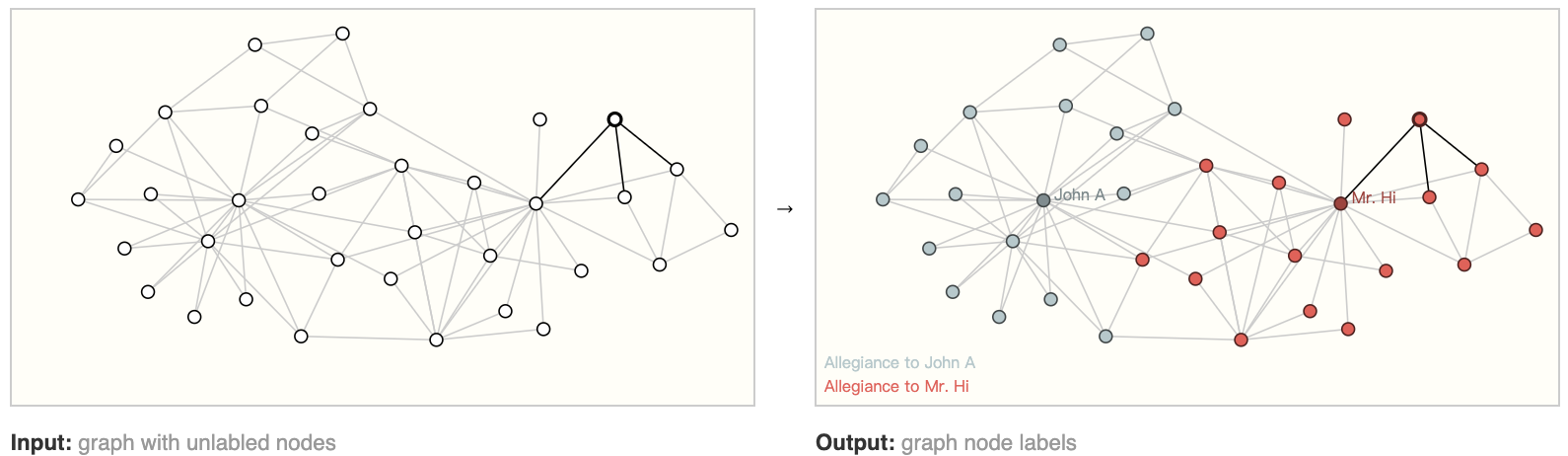
在图像类比之后,节点级预测问题类似于图像分割,我们试图标记图像中每个像素的角色。对于文本,类似的任务是预测句子中每个单词的词性(如名词、动词、副词等)。
Edge-level task
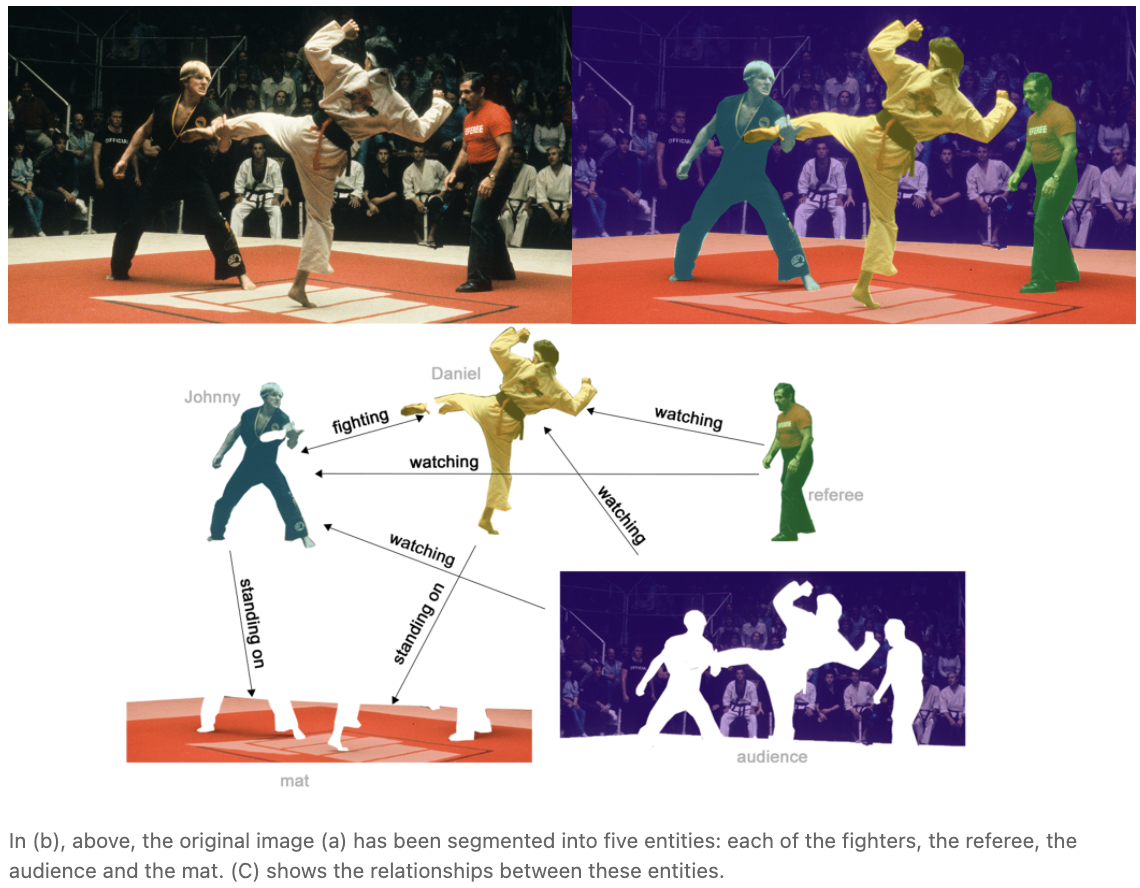
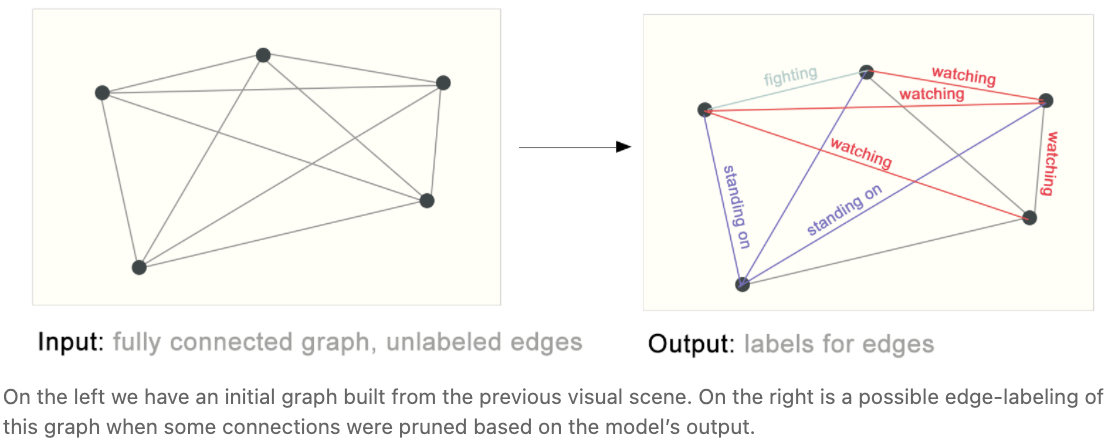
边级推理的一个例子是图像场景理解。除了识别图像中的物体,深度学习模型还可以用来预测它们之间的关系。我们可以将其描述为边级分类: 给定代表图像中物体的节点,我们希望预测这些节点中哪些共享一条边,或者这条边的值是多少。如果我们希望发现实体之间的连接,我们可以考虑图是全连接的,并根据它们的预测值修剪边,得到一个稀疏图。
The challenges of using graphs in machine learning
那么,我们如何用神经网络来解决这些不同的图任务呢?第一步是考虑我们将如何表示与神经网络兼容的图。
机器学习模型通常以矩形或网格状阵列作为输入。因此,如何以一种与深度学习兼容的格式表示它们并不是一种直观的方法。图有多达四种类型的信息,我们可能会使用它们来进行预测:节点、边、全局上下文和连接性。前三个相对比较直观: 例如, 节点可以形成节点特征矩阵 $N$, 通过在 N 中分配每条边一个索引 $i$ 并 存储 $node_i$的特征。虽然这些矩阵的样本数量可变,但它们可以在不使用任何特殊技术的情况下进行处理。
然而,表示图的连通性要复杂得多。也许最明显的选择是使用邻接矩阵,因为它很容易 tensorisable。然而,这种表示方式有一些缺点。从示例数据集表中,我们可以看到一个图中的节点数可以达到数百万,每个节点的边数可以有很大的变化。通常,这会导致非常稀疏的邻接矩阵,这是空间低效的。
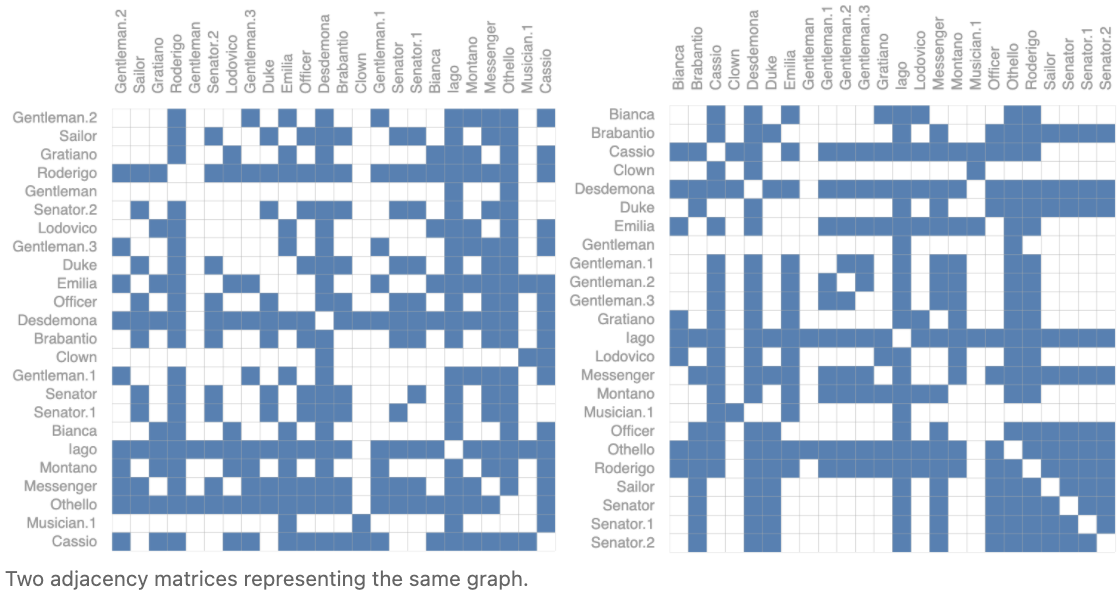
另一个问题是,有许多邻接矩阵可以编码相同的连通性,并不能保证这些不同的矩阵在深度神经网络中会产生相同的结果(也就是说,它们不是 permutation invariant 的)。
例如,前面的 Othello graph 可以用这两个邻接矩阵等价地描述。它也可以用节点的其他可能排列来描述。
下面的例子显示了每个邻接矩阵,可以描述这个4个节点的小图。这已经是大量的邻接矩阵了对于更大的例子比如 Othello,这个数字是 untenable 的。
 表示稀疏矩阵的一种优雅且节省内存的方法是用邻接表。在第 k 个邻接表的 entry 中 将 在节点 $n_i$ 和 $n_j$ 之间的边 $e_k$ 的连通性表示为 tuple(i, j)。因为我们期望边的数量远小于邻接矩阵($n^2_{nodes}$) entries 的数量, 我们避免在图不连通的部分的计算和存储。
表示稀疏矩阵的一种优雅且节省内存的方法是用邻接表。在第 k 个邻接表的 entry 中 将 在节点 $n_i$ 和 $n_j$ 之间的边 $e_k$ 的连通性表示为 tuple(i, j)。因为我们期望边的数量远小于邻接矩阵($n^2_{nodes}$) entries 的数量, 我们避免在图不连通的部分的计算和存储。
为了使这个概念具体化,我们可以看看在这个规范下如何表示不同图中的信息:
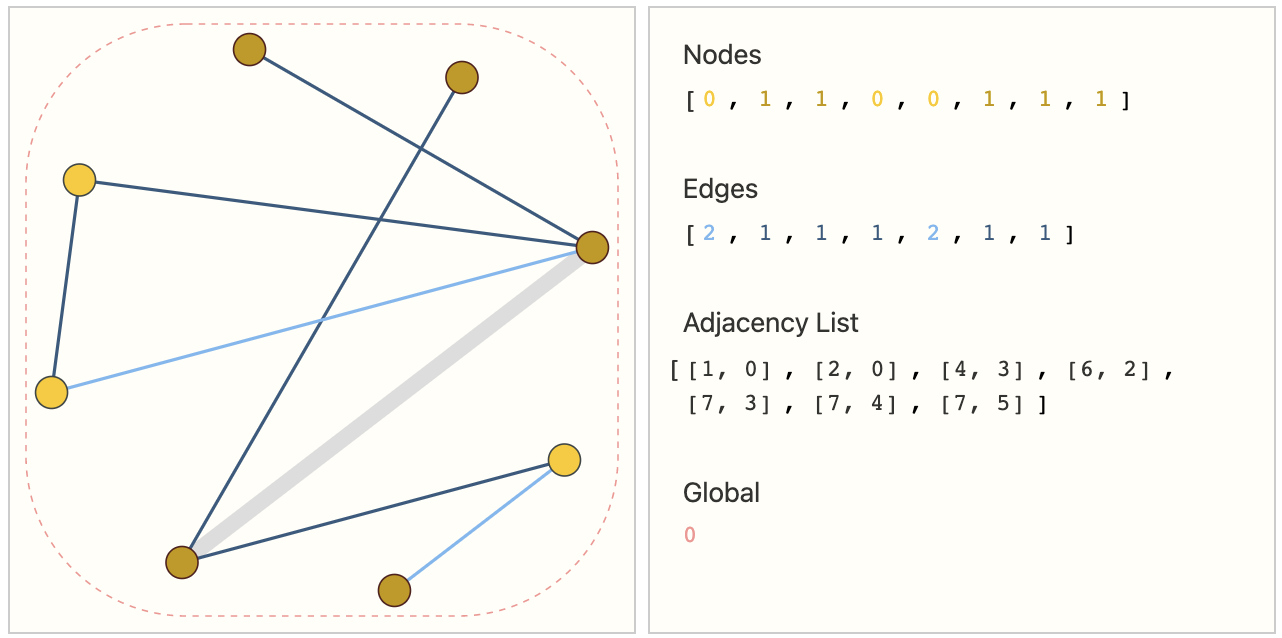
图中每个 node/edge/global 使用标量值, 但是实际中它们大都是向量或张量。相比于将节点张量的大小为 $n_{nodes}$, 我们将把节点张量的大小表示为 $(n_{nodes}, node_{dim})$。 对其他图属性一样如此。
Graph Neural Networks
既然图的描述是 permutation invariant 的矩阵形式,我们将使用图神经网络(GNN)来描述图的预测任务。GNN是对保持图对称性(permutation invariances)的图的所有属性(节点、边、全局上下文)的 optimizable transformation。我们将使用 Gilmer 等人提出的 “message passing neural network” 来构建 GNN,使用Battaglia 等人引入的 Graph Nets architecture schematics。GNNs 采用“graph-in, graph-out”的架构,这意味着这些模型类型接受一个图作为输入,将信息加载到其节点、边和全局上下文中,并逐步转换这些嵌入,而不改变输入图的连通性。
The simplest GNN
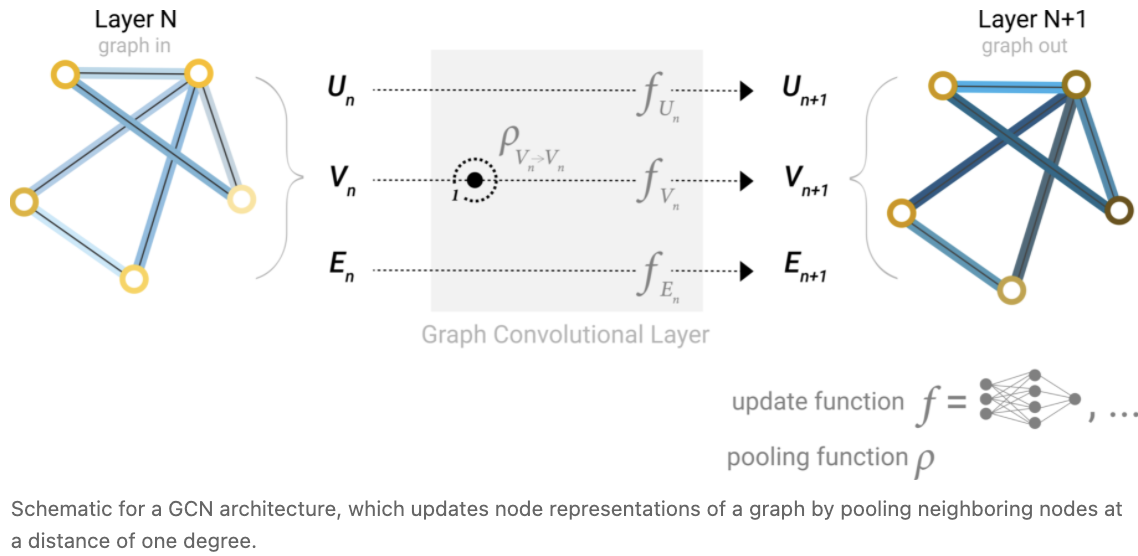
有了上面所构造的图的数值表示(使用向量而不是标量),我们现在准备构建一个GNN。我们将从最简单的GNN架构开始,在这个架构中,我们学习所有图属性(节点、边、全局)的新嵌入,但我们还没有使用图的连通性。
这个 GNN 在图的每个组件上使用单独的多层感知器(MLP)(或您喜欢的可微模型); 我们称之为GNN层。对于每个节点向量,我们应用 MLP 并得到一个学习到的节点向量。我们对每条边都这样做,学习每条边的嵌入,对全局上下文向量也这样做,学习整个图的单个嵌入。
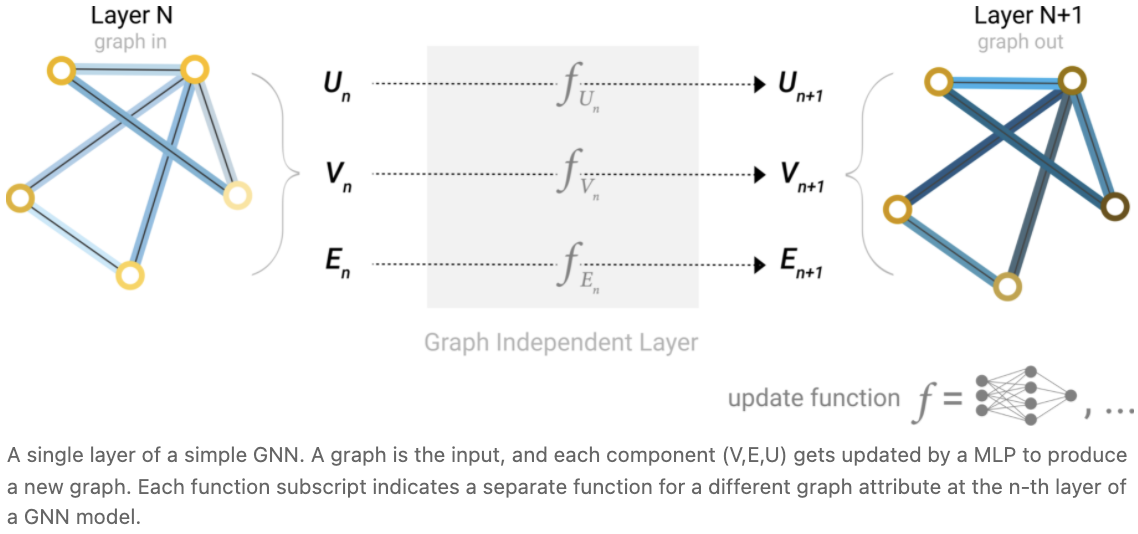
与神经网络模块或层一样,我们可以将这些GNN层堆叠在一起。
由于GNN不更新输入图的连通性,因此我们可以用与输入图相同的邻接表和相同数量的特征向量来描述GNN的输出图。但是,输出图已经更新了嵌入,因为GNN已经更新了每个节点、边和全局上下文表示。
GNN Predictions by Pooling Information
我们已经构建了一个简单的GNN,但是如何在上面描述的任何任务中进行预测呢?
我们将考虑二分类的情况,但这个框架可以很容易地扩展到多类或回归的情况。如果任务是对节点进行二分类预测,并且图中已经包含了节点信息,那么这种方法对于每个节点嵌入很简单,应用一个线性分类器。
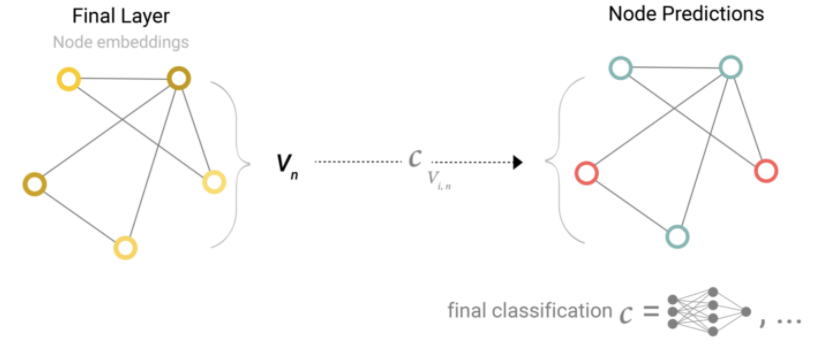
然而,事情并不总是那么简单。例如,图中的信息可能存储在边中,但节点中没有信息,但仍然需要对节点进行预测。我们需要一种方法从边收集信息,并将其传递给节点进行预测。我们可以通过 pooling 来实现。分两步 Pooling proceeds:
- 对于要 pooled 的每个项,收集它们的每个嵌入项并将它们连接到一个矩阵中。
- 然后,通常通过求和操作对收集到的嵌入进行 aggregated。
我们使用符号 $\rho$ 表示 pooling 操作,将从边收集信息到节点表示为 $\rho_{E_n \rightarrow V_n}$。
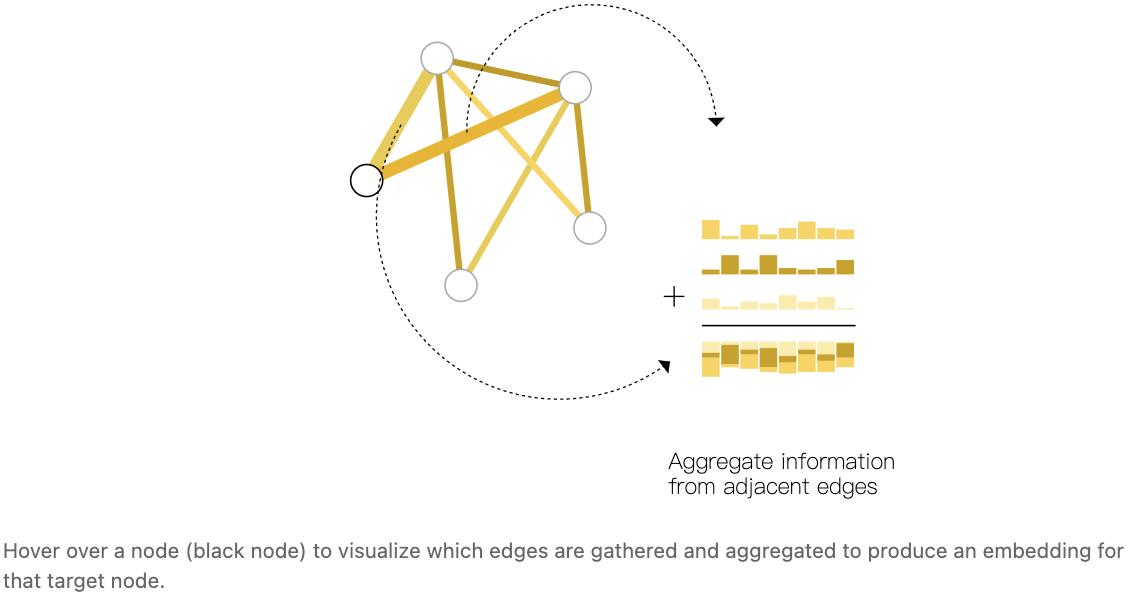
因此,如果我们只有边级的特征,并试图预测二分类节点信息,我们可以使用 pooling 将信息 route (或pass) 到它需要去的地方。
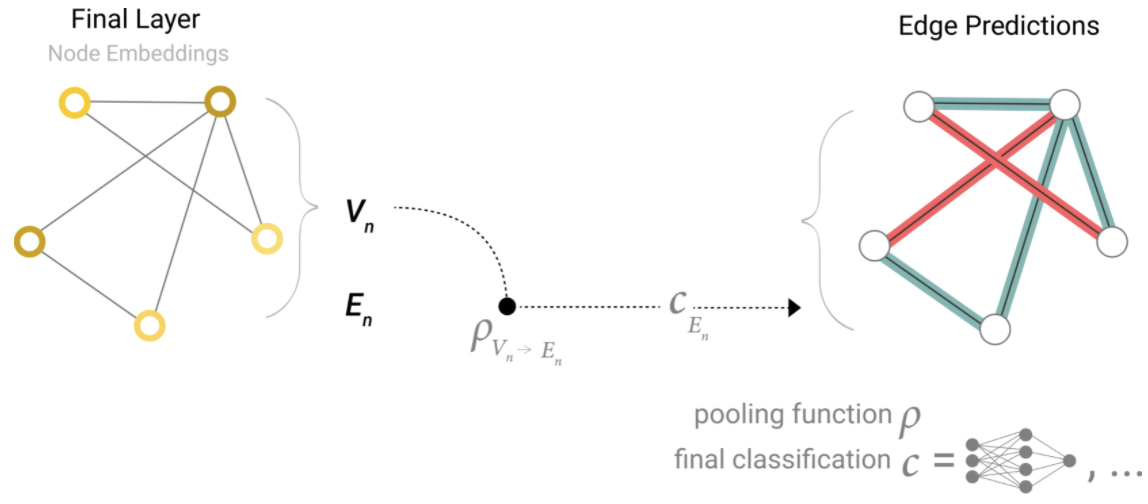
如果我们只有节点级的特征,并试图预测二分类的边级信息。
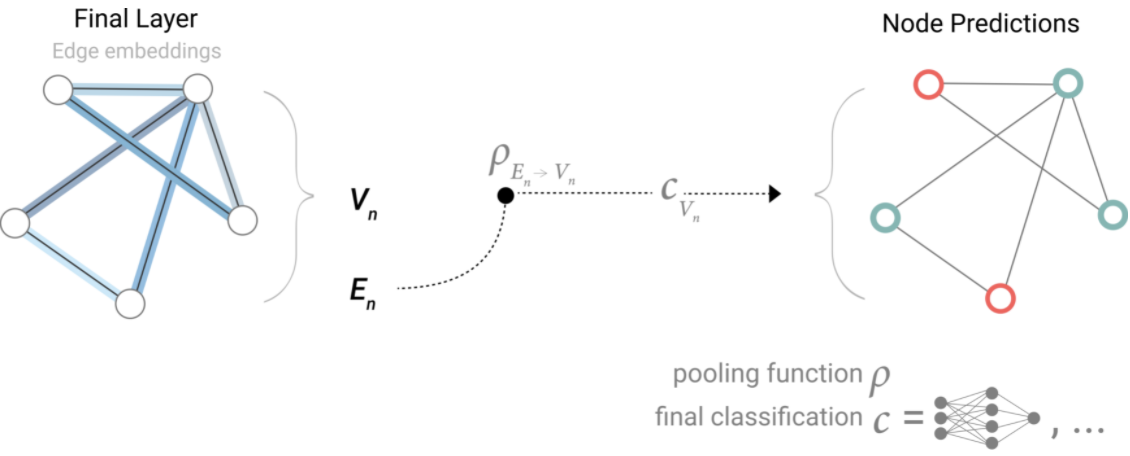
如果我们只有节点级别的特性,并且需要预测二分类的全局属性,那么我们需要收集所有可用的节点信息并将它们聚合在一起。这类似于 CNN 的全局平均池层。对于边也可以这样做。
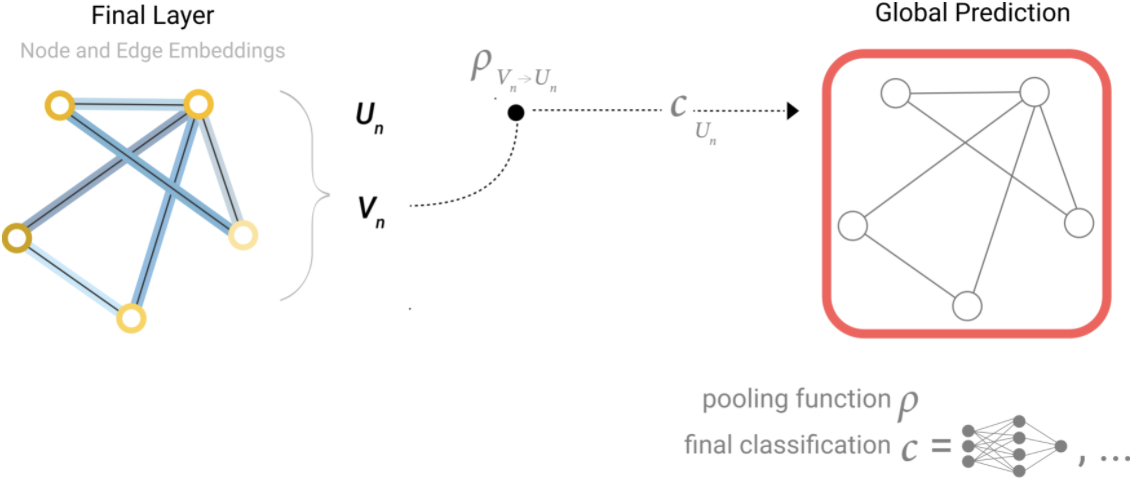 在我们的例子中, 分类模型 $c$ 可以被任意可微的模型替换, 或者使用泛化的线性模型实现 multi-class 分类。
在我们的例子中, 分类模型 $c$ 可以被任意可微的模型替换, 或者使用泛化的线性模型实现 multi-class 分类。
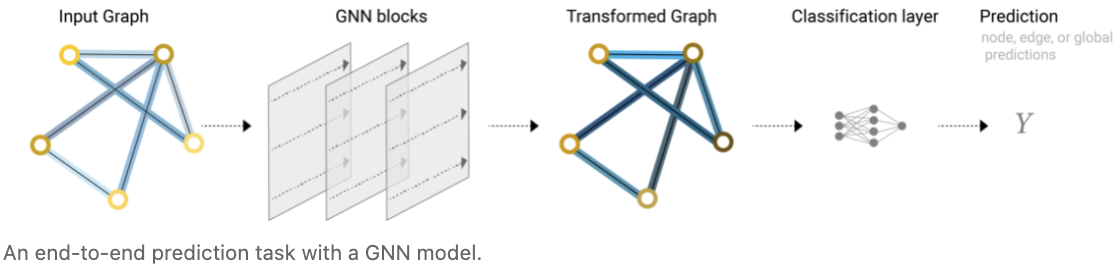
现在我们已经演示了我们可以构建一个简单的 GNN 模型,并通过在图的不同部分之间 routing 信息来进行二分类预测。这种 pooling 技术将用作构建更复杂的GNN模型的构建块。如果我们有新的图属性,我们只需定义如何将信息从一个属性传递到另一个属性。
请注意,在这个最简单的GNN公式中,我们根本没有在GNN层中使用图的连通性。每个节点、每条边以及全局上下文都是独立处理的。我们只在共享信息进行预测时使用连接性。
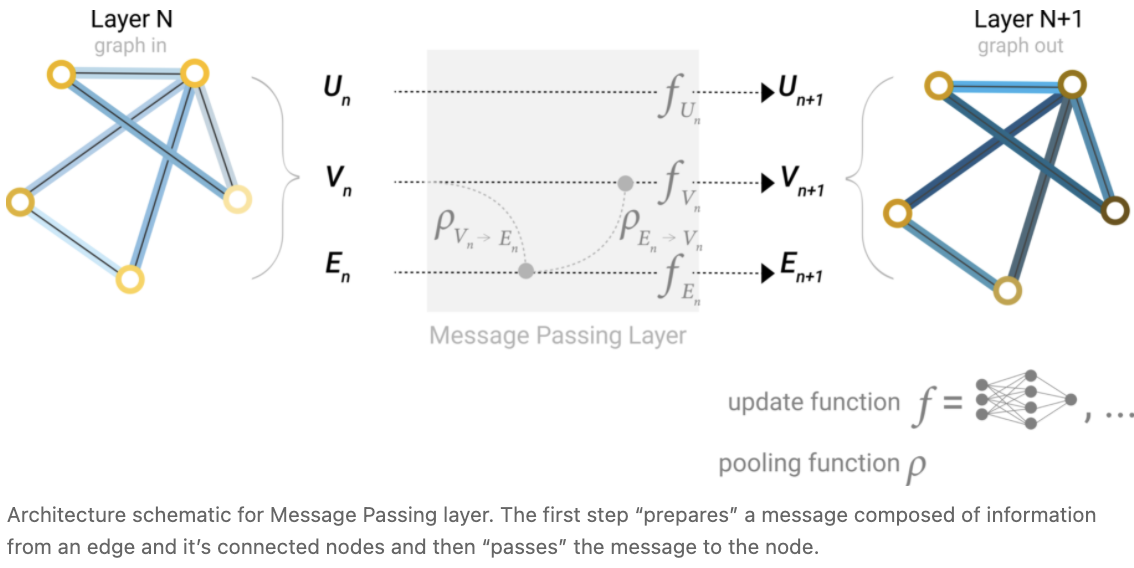
Passing messages between parts of the graph
我们可以通过在 GNN 层中使用 pooling 来进行更复杂的预测,以便使我们所学的嵌入能够感知图的连通性。我们可以使用消息传递来实现这一点,在消息传递中,相邻节点或边交换信息并影响彼此更新的嵌入。
消息传递分为三个步骤:
- 图中的每个节点,收集所有相邻节点嵌入(或消息), 其实上述中的 $g$ 函数
- 通过聚合函数(如sum)聚合所有消息。
- 所有 pooled 的消息都通过一个更新函数传递,通常是一个学习过的神经网络。
正如 pooling 可以应用于节点或边一样,消息传递也可以发生在节点或边之间。
这些步骤是利用图的连接性的关键。我们将在GNN层中构建更复杂的消息传递变体,这些变体将产生更具 expressiveness 和 power 的GNN模型。
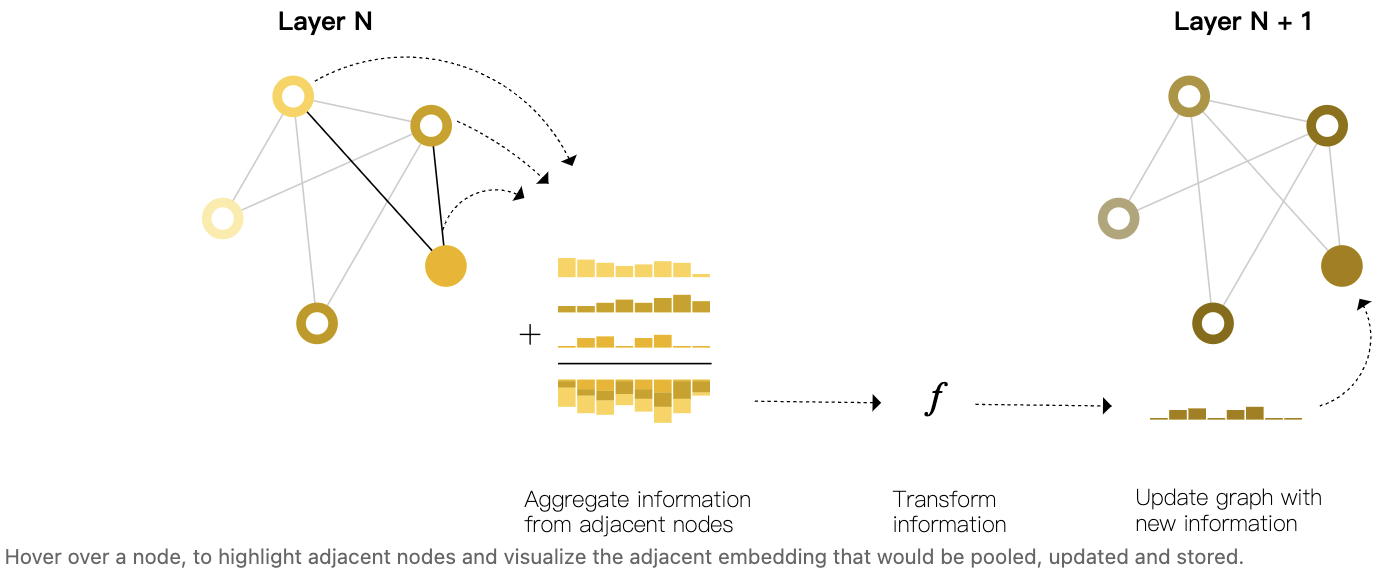
当应用一次时,这个操作序列是最简单的 message-passing GNN层类型。这让人想起了标准的卷积: 本质上, message passing 和 卷积 是聚合和处理元素邻居信息的操作,以便更新元素的值。在图中,元素是一个节点,而在图像中,元素是一个像素。然而,图中相邻节点的数量可以是可变的,不像图像中每个像素都有一组相邻元素。
通过将传递 GNN 层的消息堆叠在一起,节点最终可以合并来自整个图的信息: 在三层之后,节点拥有关于离它三步远的节点的信息。
我们可以更新架构图,以包含这个新的节点信息源:
Learning edge representations
我们的数据集并不总是包含所有类型的信息(节点、边和全局上下文)。当我们想要对节点进行预测,但我们的数据集只有边信息时,我们在上面展示了如何使用 pooling 将信息从边路由到节点,但只在模型的最后一个预测步骤。我们可以通过消息传递在 GNN 层的节点和边之间共享信息。
我们可以像之前使用相邻节点信息一样,合并来自相邻边的信息,首先 pooling 边信息,用更新函数进行转换,然后存储。
然而,存储在图中的节点和边信息不一定是相同的大小或形状,因此,如何将它们组合起来还不是很清楚。一种方法是学习从边空间到节点空间的线性映射,反之亦然。或者,可以在更新函数之前将它们连接在一起。
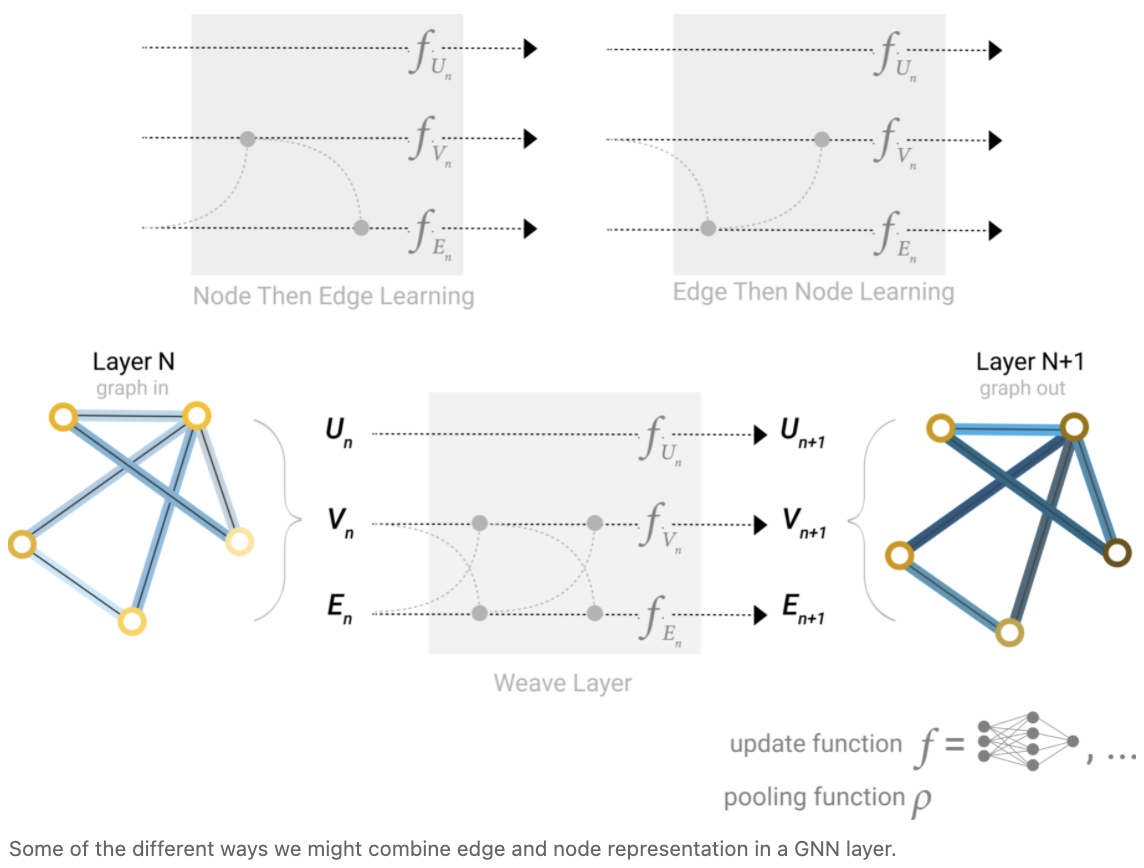
在构造 GNN 时,更新哪些图属性以及以何种顺序更新它们是一个设计决策。我们可以选择是否在边嵌入之前更新节点嵌入,或者反过来。这是一个开放的研究领域有各种各样的解决方案, 例如我们可以更新 “weave” 的方式, 我们有四个更新表示, 组合成新节点和边表示:节点到节点(线性), 边对边(线性), 节点-边(边层),边-节点(节点层)。
Adding global representations
我们到目前为止描述的网络有一个缺陷: 即使我们多次应用消息传递,图中彼此相距遥远的节点可能永远无法有效地相互传递信息。对于一个节点,如果我们有k层,信息最多传播k步。在预测任务依赖于相距很远的节点或节点组的情况下,这可能是一个问题。一种解决方案是让所有节点都能够相互传递信息。不幸的是,对于大的图,这种方法很快就会变得计算昂贵(尽管这种称为 ‘virtual edges’ 的方法已经用于小的图,如分子)。
这个问题的一个解决方案是使用图(U)的全局表示,它有时被称为 master node 或 context vector。这个全局上下文向量连接到网络中的所有其他节点和边,可以作为它们之间传递信息的桥梁,构建一个图的整体表示。这就创建了一个更丰富、更复杂的图表示,而不是通过其他方式学习到的。
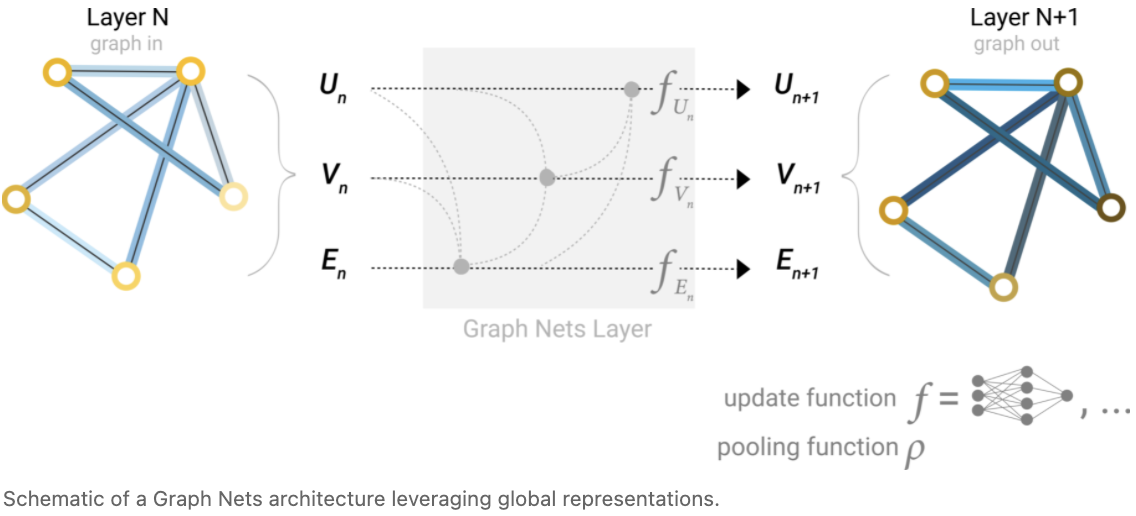
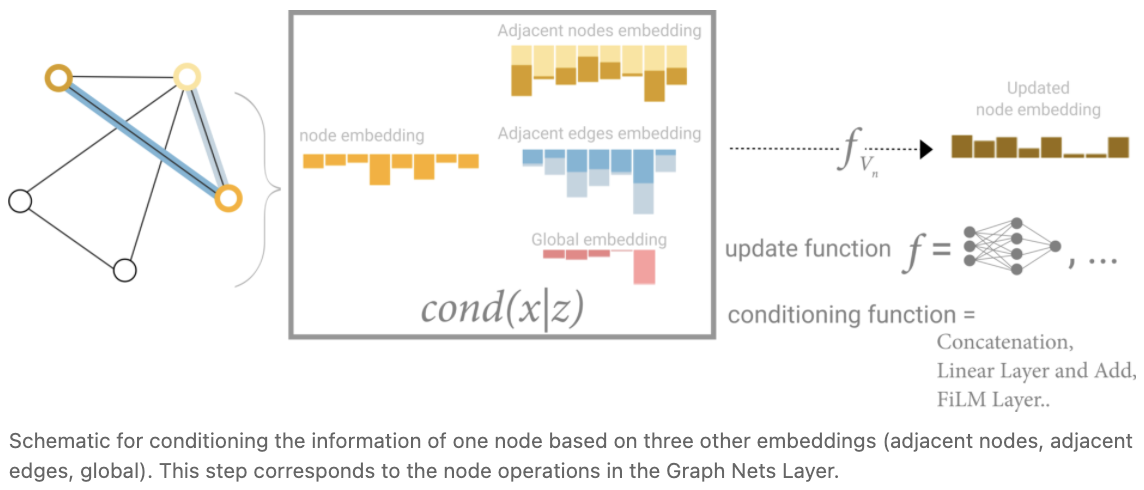
在这个视图中,所有的图属性都已经学到了表示,所以我们可以在 pooling 中利用它们,方法是将我们感兴趣的属性的信息与其他属性相关联。例如,对于一个节点,我们可以考虑来自相邻节点、连接边和全局信息的信息。要使新节点嵌入在所有这些可能的信息源上,我们只需将它们连接起来。此外,我们还可以通过线性映射将它们映射到相同的空间,并添加它们或应用 feature-wise modulation 层,这可以被视为一种 featurize-wise attention 机制。
GNN playground
我们在这里描述了各种各样的GNN组件,但是它们在实践中究竟有什么不同呢? 这个GNN playground 允许您了解这些不同的组件和体系结构如何有助于 GNN 学习实际任务的能力。
我们的 playground 展示了一个带有小分子图的图级预测任务。我们使用 Leffingwell 气味数据集,它由与 odor percepts (labels) 相关的分子组成。预测分子结构(图)与其气味的关系是一个跨越化学、物理、神经科学和机器学习的百年难题。
为了简化这个问题,我们只考虑每个分子有一个单独的二元标签,根据专业调香师的标签来区分分子图闻起来是否有刺激性。如果一个分子有强烈的、引人注目的气味,我们就说它有刺鼻的气味。例如,大蒜和芥末,它们可能含有烯丙醇分子,就有这种特性。胡椒酮分子,经常用于薄荷味的糖果,也被描述为具有刺激性的气味。
我们将每个分子表示为一个图,其中原子是节点,包含一个对其原子特性的独热编码(碳、氮、氧、氟),键是边,包含一个对其键类型的独热编码(单键、双键、三键或芳香键)。
我们将使用顺序GNN层建立这个问题的通用建模模板,然后使用一个sigmoid激活的线性模型进行分类。我们的GNN的设计空间有许多可以定制模型:
- GNN层数,也称为深度。
- 更新时每个属性的维度。更新函数是一个带有 relu 激活函数和层规范化的 1-layer MLP。
- pooling 中使用的聚合函数: max, mean 或 sum。
- 更新的图属性,或者消息传递的样式:节点、边和全局表示。我们通过布尔值控制它。 基线模型将是一个独立于图的GNN(所有消息传递),它在最后将所有数据聚合到一个单一的全局属性中。切换所有的消息传递函数会产生一个GraphNets架构。
为了更好地理解 GNN 是如何学习任务优化的图表示的,我们还将研究GNN的倒数第二层激活。这些 graph embeddings 是 GNN模型 在预测之前的输出。由于我们使用线性模型进行预测,线性映射足以让我们看到我们是如何学习决策边界附近的表示的。
由于这些是高维向量,我们通过主成分分析(PCA)将它们还原为2D。一个完美的模型将可见性分离标记数据,但由于我们正在降低维度,也有不完美的模型,这个边界可能很难看到。
Some empirical GNN design lessons
在探索上面的架构选择时,您可能会发现一些模型的性能比其他模型更好。是否有一些明确的 GNN 设计选择可以给我们带来更好的性能? 例如,深度GNN模型比浅层GNN模型性能更好吗? 或者在 pooling 函数之间是否有明确的选择? 答案将取决于数据,甚至不同的特征化和构造图的方法也会给出不同的答案。
通过下面的交互式图,我们通过几个主要的设计选择来探索GNN架构的空间和该任务的性能:Style of message passing, the dimensionality of embeddings, number of layers 和 aggregation operation type。
散点图中的每个点代表一个模型:x轴是可训练变量的数量,y轴是性能。
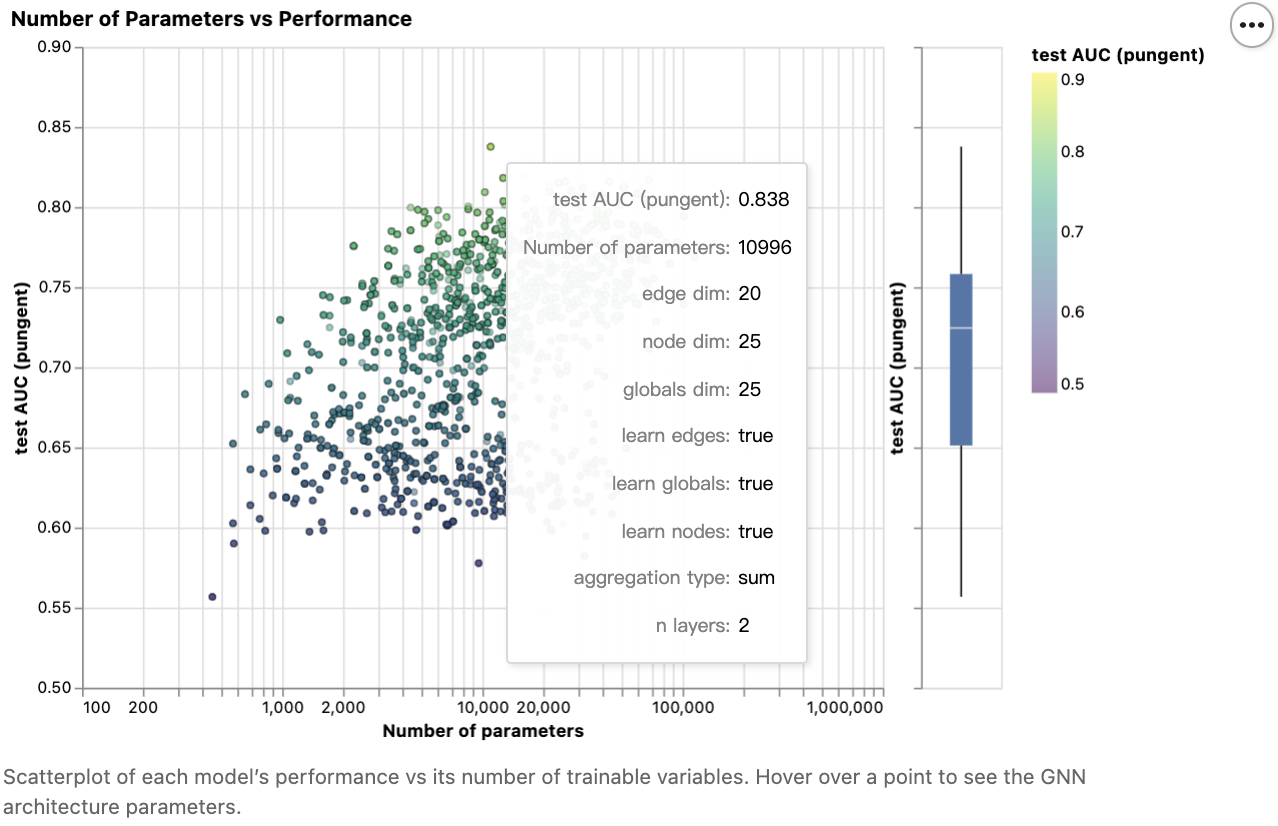
首先要注意的是,令人惊讶的是,参数的数量越多,性能越好。GNN 是一种非常有效的参数模型类型:即使是少量的参数(3k),我们也可以找到高性能的模型。
接下来,我们可以看看基于学习到的不同图属性表示维数聚合的性能分布。
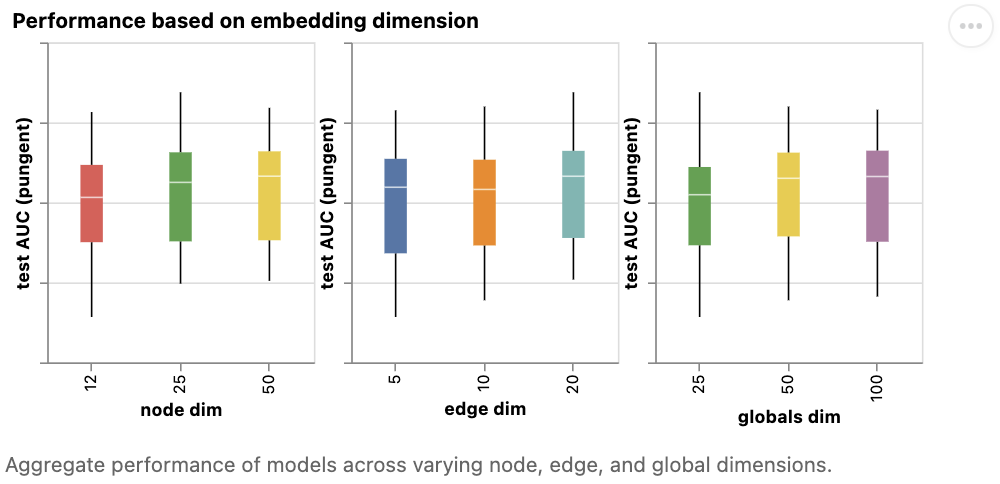 我们可以注意到,更高维度的模型往往有更好的平均值和下限性能,但在最大值上没有发现同样的趋势。一些性能最好的模型可以用于更小的尺寸。因为更高的维度也将涉及更多的参数,这些观察结果与前面的图相关联。
我们可以注意到,更高维度的模型往往有更好的平均值和下限性能,但在最大值上没有发现同样的趋势。一些性能最好的模型可以用于更小的尺寸。因为更高的维度也将涉及更多的参数,这些观察结果与前面的图相关联。
接下来,我们可以看到基于GNN层数的性能分解。
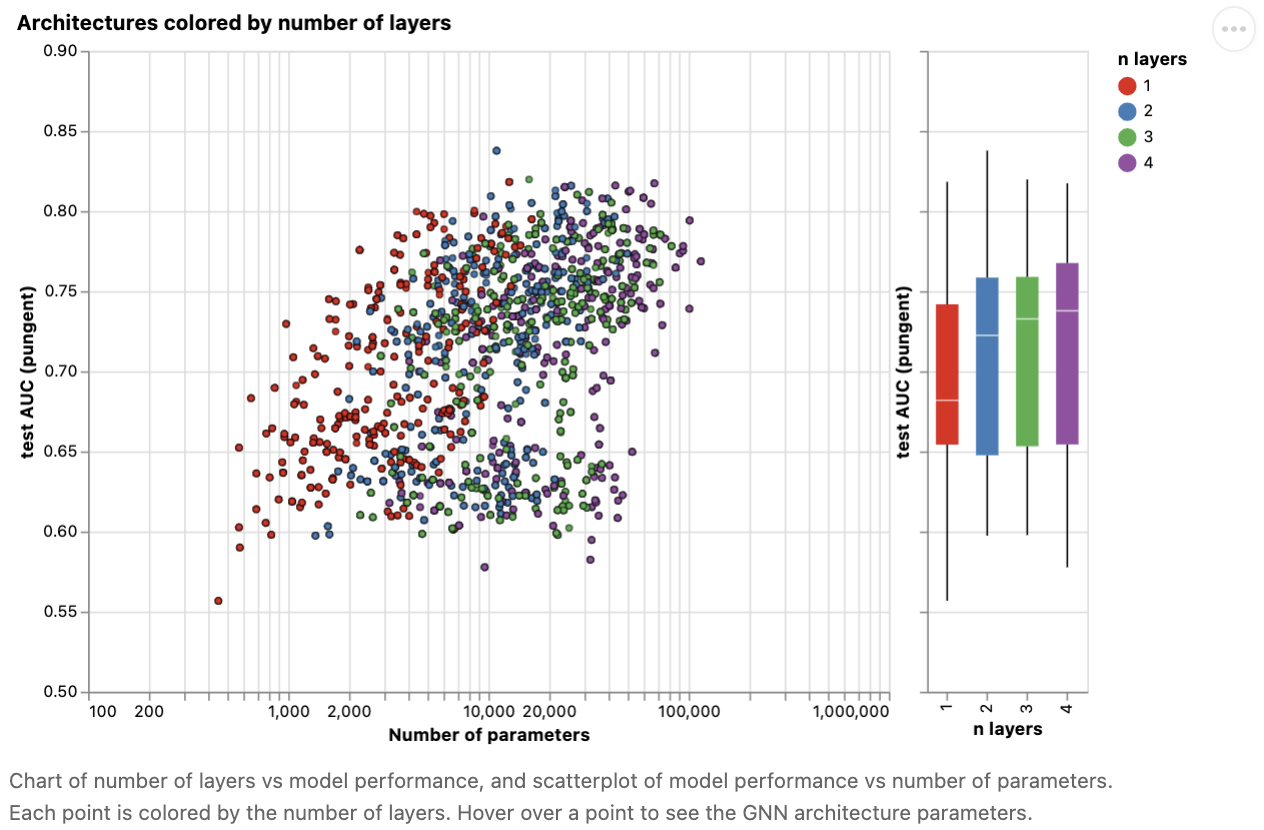 box plot 显示了类似的趋势,虽然平均性能倾向于随着层数的增加而增加,但性能最好的模型不是有三层或四层,而是两层。此外,性能的下界到了四层会降低。这种影响以前已经观察到,层数越多的GNN将在更高的距离广播信息,并且可能会有节点表示因多次迭代而被稀释的风险。
box plot 显示了类似的趋势,虽然平均性能倾向于随着层数的增加而增加,但性能最好的模型不是有三层或四层,而是两层。此外,性能的下界到了四层会降低。这种影响以前已经观察到,层数越多的GNN将在更高的距离广播信息,并且可能会有节点表示因多次迭代而被稀释的风险。
我们的数据集是否有首选的 aggregation operation? 下图根据 aggregation operation 对性能进行了分解。
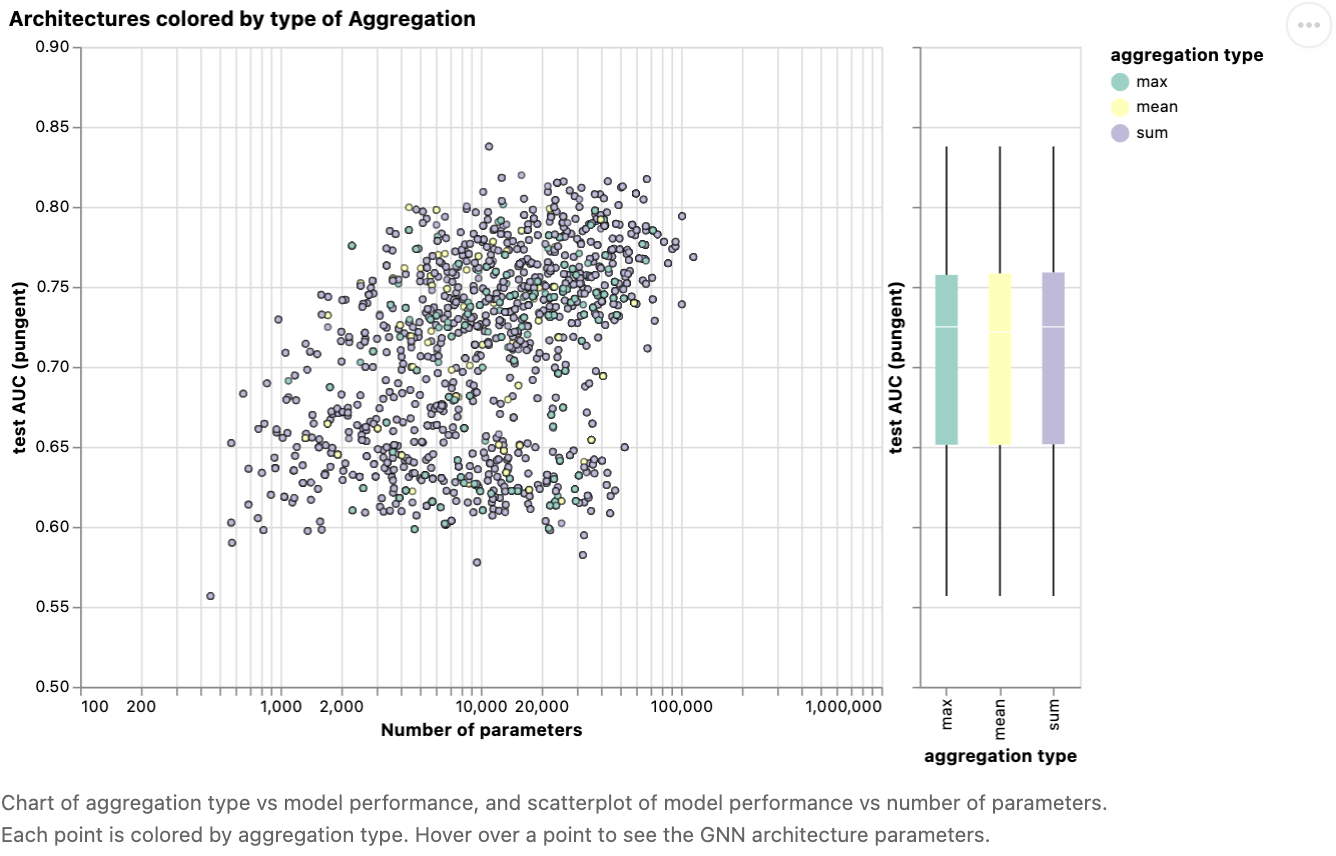 总的来说,sum 的性能比 mean 的性能有很小的提高,但是 max 或 mean 可以给出同样好的模型。
总的来说,sum 的性能比 mean 的性能有很小的提高,但是 max 或 mean 可以给出同样好的模型。
之前的探索给出了复杂的信息。我们可以找到平均趋势,其中复杂性越高性能越好,但我们也可以找到明确的反例,其中参数、层数或维度更少的模型性能更好。一个更清晰的趋势是相互传递信息的属性的数量。
这里,我们根据消息传递的风格对性能进行了分析。在这两个极端,我们考虑不在图实体之间通信的模型和在节点、边和全局之间传递消息的模型。
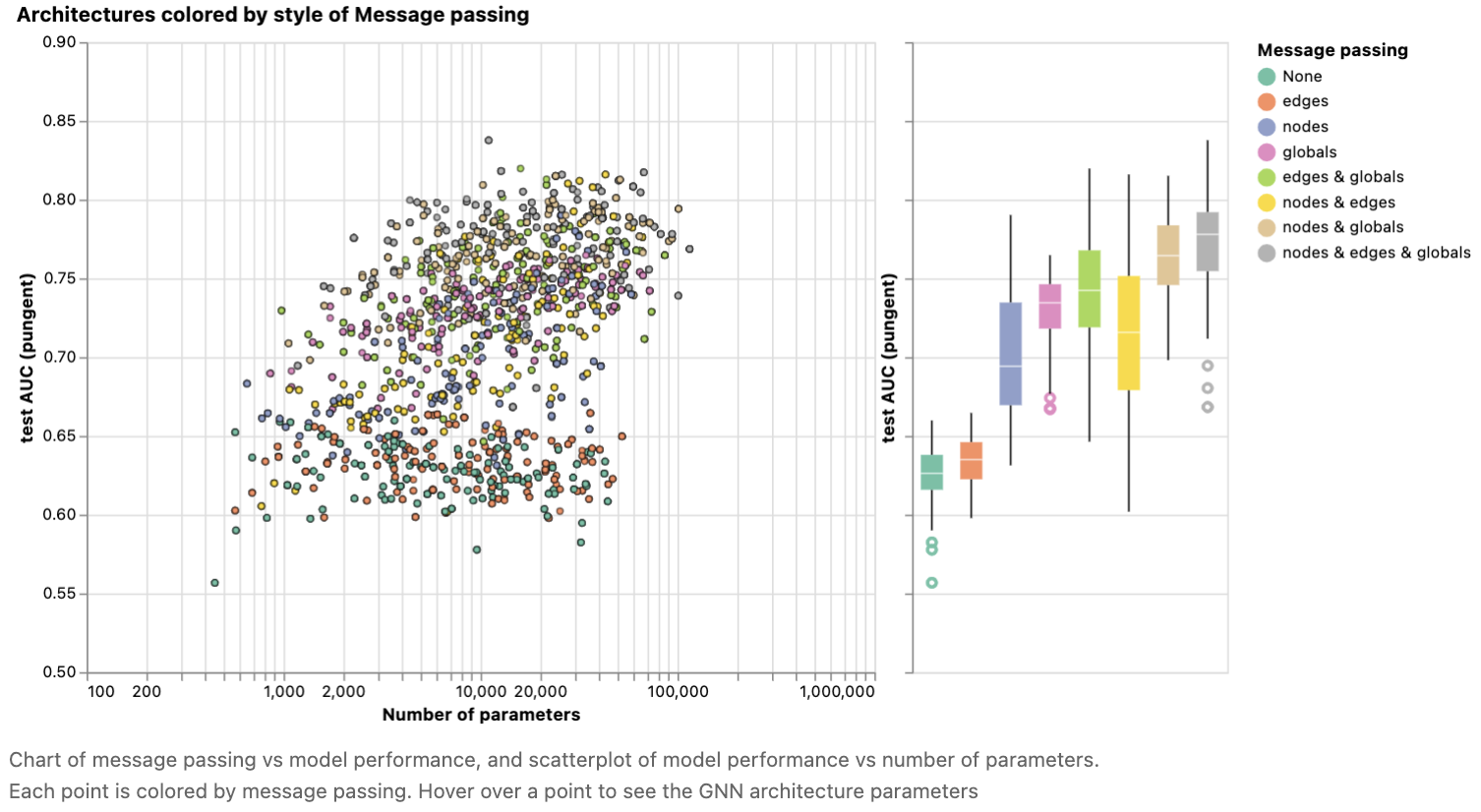
总的来说,我们可以看到,图属性的通信越多,模型的平均性能就越好。我们的任务以全局表示为中心,因此明确地学习这个属性也有助于提高性能。我们的节点表示似乎比边表示更有用,这是有意义的,因为在这些属性中加载了更多的信息。
为了获得更好的性能,您可以从这里选择许多方向。我们希望两个重点突出两个总体方向,一个与更复杂的图算法有关,另一个与图本身有关。
到目前为止,我们的GNN是基于基于邻域的 pooling 操作的。有些图概念很难用这种方式表达,例如线性图路径(连接的节点链)。在GNN中设计新的图信息提取、执行和传播机制是当前研究的热点之一。
GNN 研究的前沿领域之一不是创建新的模型和架构,而是如何构建图,更准确地说,是向图中注入可以利用的额外结构或关系。正如我们看到的,图属性的交流越多,我们更容易得到更好的模型。在这种特殊的情况下,我们可以考虑通过在节点之间添加额外的空间关系、添加 not bond 的边或子图之间显式的可学习关系,使分子图的特征更丰富。
Into the Weeds
接下来,我们将用几个小节讨论与 GNN 相关的图相关主题。
Other types of graphs (multigraphs, hypergraphs, hypernodes, hierarchical graphs)
虽然我们只对每个属性使用向量化信息描述图,但图结构更灵活,可以容纳其他类型的信息。幸运的是,消息传递框架足够灵活,使 GNN 适应更复杂的图结构通常是关于定义如何通过新的图属性传递和更新信息。
例如,我们可以考虑 multi-edge graphs 或 multigraphs,其中一对节点可以共享多种类型的边,当我们想根据节点的类型对它们之间的交互建立不同的模型时,就会发生这种情况。例如,对于一个社交网络,我们可以根据关系的类型(熟人、朋友、家人)指定边类型。可以通过为每个边类型设置不同类型的消息传递步骤来调整GNN。我们还可以考虑 nested graph,其中一个节点表示一个图,也称为 hypernode 图。Nested Graph 对于表示分层信息很有用。例如,我们可以考虑一个分子网络,其中一个节点代表一个分子,如果我们有一种将一个分子转化为另一个分子的方式(反应),则两个分子之间共享一条边。 在这种情况下,我们可以在一个 nested 的图上学习,通过一个 GNN 在分子水平上学习表示,另一个在 reaction network level上学习表示,并在训练期间交替使用它们。
另一种类型的图是 hypergraph ,其中一条边可以连接到多个节点,而不是只有两个节点。对于一个给定的图,我们可以通过识别节点的社区,并分配一个连接到社区中所有节点的 hyper-edge 来构建一个 hypergraph。
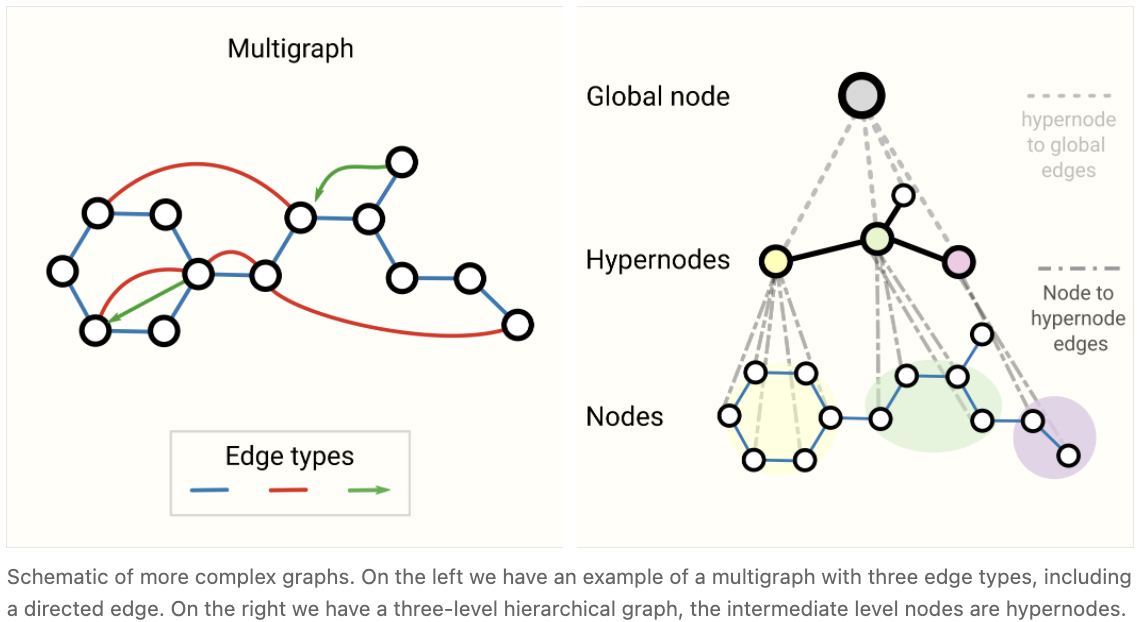
如何训练和设计具有多种图属性的 GNN 是当前研究的热点。
Sampling Graphs and Batching in GNNs
训练神经网络的一种常见做法是使用在训练数据的随机常数大小(批大小)子集(小批量)上计算的梯度来更新网络参数。由于邻接节点和边的数量的可变性,这一实践对图提出了挑战,这意味着我们不能有固定的批处理大小。图批处理的主要思想是创建保留较大图基本属性的子图。图的采样操作高度依赖于上下文,包括从图中选择节点和边。这些操作在某些情况下可能是有意义的(citation networks),但在其他情况下,这些操作可能太强大了(分子,其中一个子图只是代表一个新的更小的分子)。如何对一个图进行采样是一个开放的研究问题。如果我们关心在邻域水平上保持结构,一种方法是随机抽样均匀数量的节点,我们的 node-set。然后向节点集添加距离为 k 的相邻节点,包括它们的边。 每个邻域可以被认为是一个单独的图,一个 GNN 可以在这些子图的批上训练。由于所有相邻节点都具有不完整的邻域,因此可以将损失 masked 只考虑 node-set。一个更有效的策略可能是,首先随机抽样一个节点,将其邻域扩展到距离k,然后在扩展集内选择另一个节点。一旦构造了一定数量的节点、边或子图,这些操作就可以终止。如果环境允许,我们可以通过选择一个初始节点集,然后对固定数量的节点进行子采样(例如随机采样,或通过 random walk 或 Metropolis 算法)来构建恒定大小的邻域。
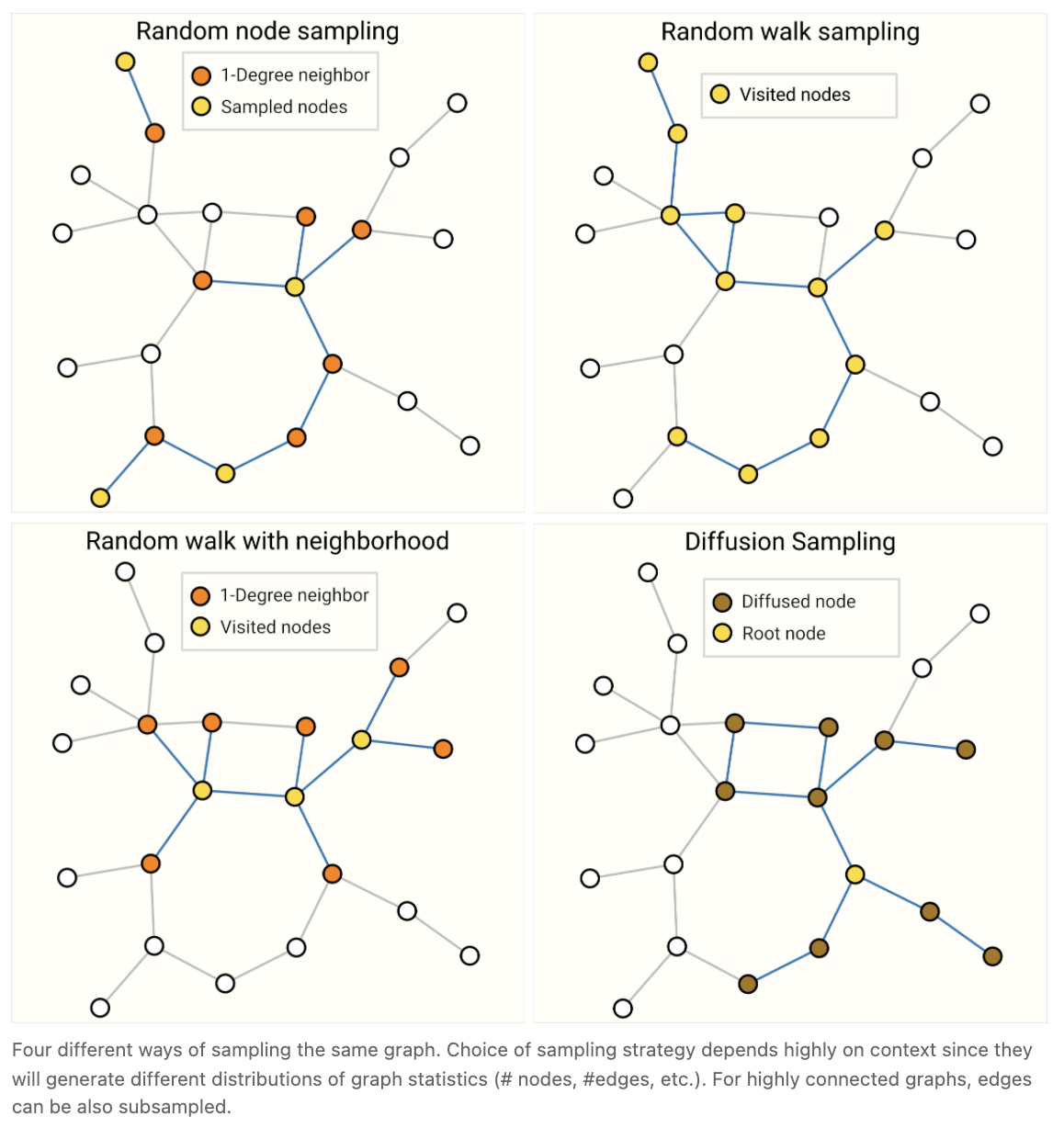 当一个图足够大,无法放入内存中时,对图进行采样尤为重要。有一些鼓舞人心的新结构和训练策略,如 Cluster-GCN 和 GraphSaint。 我们预计未来图数据集的规模将继续增长。
当一个图足够大,无法放入内存中时,对图进行采样尤为重要。有一些鼓舞人心的新结构和训练策略,如 Cluster-GCN 和 GraphSaint。 我们预计未来图数据集的规模将继续增长。
Inductive biases
在构建模型以解决特定类型数据的问题时,我们希望将模型 specialize,以利用该数据的特征。当成功地做到这一点时,我们通常会看到更好的预测性能、更短的训练时间、更少的参数和更好的泛化。
例如,当我们给图片贴上标签时,我们想要利用这样一个事实: 不管它是在图片的左上角还是右下角,它仍然是一只狗。因此,大多数图像模型使用卷积,它是 translation invariant 的。对于文本,token 的顺序非常重要,因此循环神经网络按顺序处理数据。此外,一个标记(例如单词not)的出现会影响句子其余部分的含义,因此我们需要能够处理文本其他部分的组件,像 BERT 和 GPT-3 这样的 Transformer 模型就可以做到这一点。这些是 inductive biases 的一些例子,在这些例子中,我们识别数据中的对称性或规律性,并添加利用这些特性的建模组件。
在图的情况下,我们关心每个图组件(边、节点、全局)是如何相互关联的,因此我们寻找具有关系 Inductive biases 的模型。 一个模型应该保持实体之间的显式关系( adjacency matrix ) 和 保持图的对称性( permutation invariance )。我们希望实体之间的交互很重要的问题将从图结构中受益。具体来说,这意味着在集合上设计变换: 节点或边的操作顺序不应该是重要的,操作应该在可变数量的输入上起作用。
Comparing aggregation operations
在任何相当强大的 GNN 结构中,从相邻节点和边收集信息都是一个关键步骤。因为每个节点的邻居数量是可变的,而且因为我们需要一种可微分的方法来聚合这些信息,所以我们希望使用一种平滑的聚合操作,该操作与节点顺序和所提供的节点数量无关。
最优聚合操作的选择与设计是一个开放的研究课题。聚合操作的一个理想属性是相似的输入提供相似的聚合输出,反之亦然。一些非常简单的候选 permutation-invariant 操作有和、均值和最大值。像方差这样的汇总统计也可以工作。所有这些都采用可变数量的输入,并提供相同的输出,无论输入顺序如何。让我们探讨一下这些操作之间的区别。
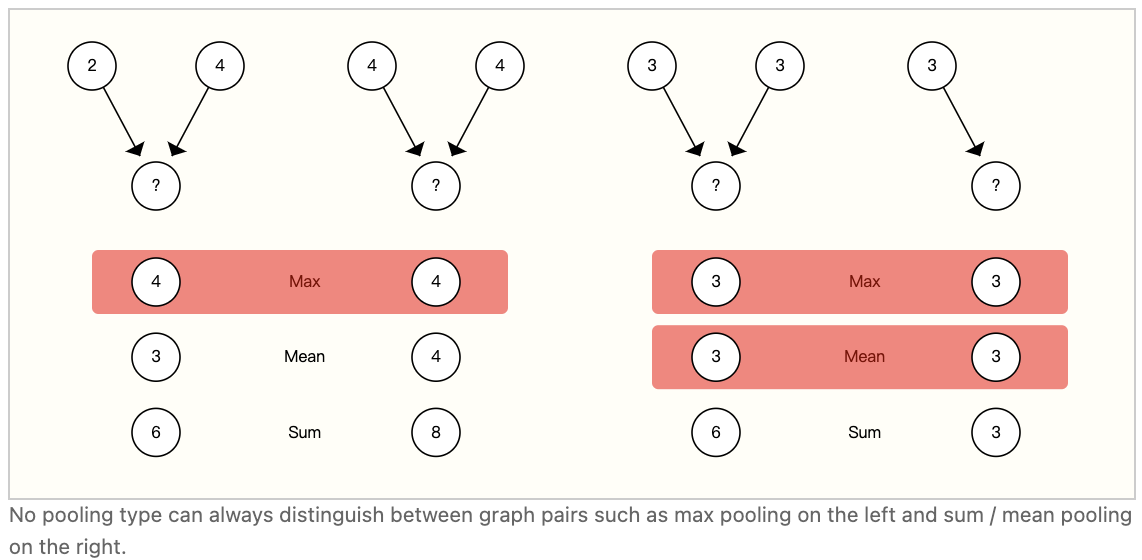
没有一种操作是统一的最佳选择。当节点有大量可变的邻居,或者需要一个局部邻居特征的标准化视图时,均值操作可能很有用。当您想要突出显示局部邻域的单个显著特征时,max操作可能很有用。通过提供特征的局部分布的快照,Sum提供了这两者之间的平衡,但由于它不是 normalized 的,也可以突出显示异常值。在实践中,求和是常用的。
聚合运算的设计是一个与集合上的机器学习相交叉的开放研究问题。Principal Neighborhood聚合等新方法考虑了几种聚合操作,将它们连接起来,并添加一个依赖于要聚合的实体的连通性程度的 scaling 函数。同时,还可以设计特定于域的聚合操作。一个例子是 “Tetrahedral Chirality” 聚合算子。
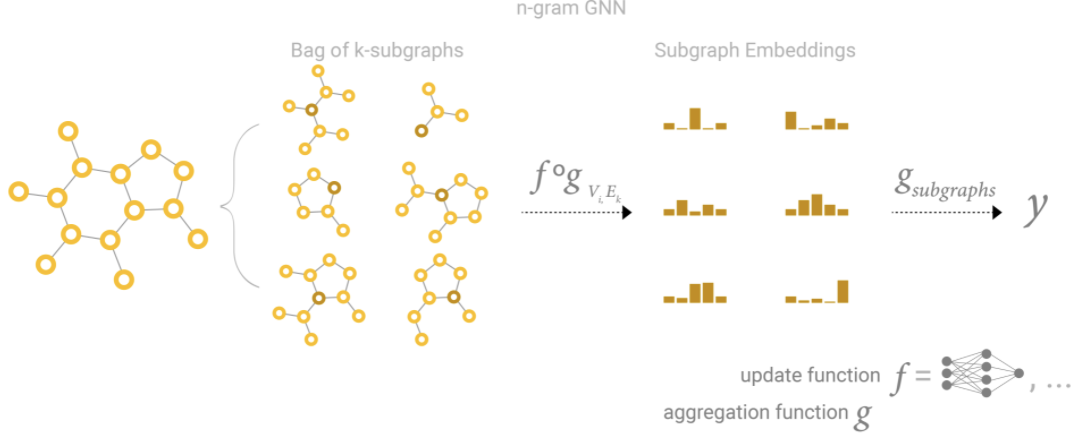
GCN as subgraph function approximators
另一种看待具有 1-degree neighbor lookup 的 k 层的GCN(和MPNN)的方法是,将其视为一个对大小为 k的子图进行学习 embeddings 的神经网络。
当关注一个节点时,经过 k 层后,更新的节点表示对 k-距离 以内的所有邻居有一个有限的视角,本质上是一个子图表示。边的表示也是如此。
所以 GCN 收集所有大小为 k 的可能子图,并从一个节点或边的有利位置学习向量表示。可能的子图的数量可以组合增长,因此从一开始枚举这些子图与在GCN中动态构建它们相比,可能是不允许的。
Reference
-
Previous
【深度学习】Understanding Graph Convolutional Networks for Node Classification -
Next
【机器学习】Understanding AUC - ROC Curve