Data modes
当样本具有不同形状时,创建 mini-batches 可能很棘手。
在传统的神经网络中,我们习惯于拉伸、裁剪或填充数据,以便所有输入到模型的数据都是标准化的。例如,可以修改不同大小的图像,使其适合于形状 [batch,width,height,channel] 张量。序列可以填充,以便他们有形状 [batch,time,channels]。等等…
对于图,情况就有点不同了。
例如,定义 “cropping” 或 “stretching” 图的含义并不容易,因为这些都是假设像素的 “spatial closeness” 的 transformations (通常我们对图没有这种假设)。
此外,我们的数据集中并不总是有很多图。有时候,我们只是对一个大图的节点分类感兴趣。有时,我们可能有一个大的图,但它的节点特征有许多实例(图像的分类就是这样的一种情况:一个网格,多个像素值的实例)。
为了使 Spektral 在所有这些情况下都能工作,并考虑到处理不同大小的图的困难,我们引入了 data modes 的概念。
在 Spektral 中, 有四种 data modes:
single mode: 我们只有一个图。节点分类任务通常采用该模式。disjoint mode: 我们表示了一批具有不相交并集的图。这给了我们一个大图,类似于single mode,尽管有一些不同(见下文)。batch mode: 我们对图进行零填充,这样我们就可以将它们放入形状[batch,nodes,…]的密集张量中。这可能会更昂贵,但可以更容易地与传统 NNs 进行交互。mixed mode: 我们有一个邻接矩阵被许多图共享。我们将邻接矩阵保持在single mode(为了性能,不需要为每个图重复它),节点属性保持在batch mode。
在所有数据模式中,我们的目标是通过将各自的 x、a 和 e 矩阵分组为单个张量 x 、a 和e 来表示一个或多个图。不同数据模式下这些张量的形状总结在下表中。

在上表中,batch 是批大小,nodes 是节点的数量,edges 是边的数量,n_feat 和 e_feat 分别是节点和边特征的数量。
请务必阅读入门教程,以理解这些矩阵代表的一般图。
在下面的部分中,我们将更详细地描述这四种模式。特别地,我们讨论在每种情况下使用哪个 data Loader。
Single mode
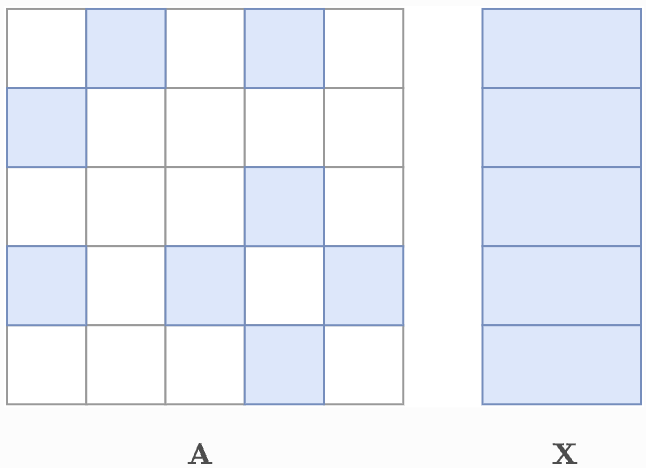
在 single mode 下,我们只有一个图:
A是形状为[nodes, nodes]的矩阵X是形状为[nodes, n_feat]的矩阵E是形状为[edges, e_feat],A的每个非零条目对应一行,按行为主排序
一个非常常见的 single mode 数据集是Cora引文网络。
1
2
3
4
>>> from spektral.datasets import Cora
>>> dataset = Cora()
>>> dataset
Cora(n_graphs=1)
正如所料,我们只有一个图
1
2
3
4
5
6
7
8
>>> dataset[0]
Graph(n_nodes=2708, n_node_features=1433, n_edge_features=None, n_labels=7)
>>> dataset[0].a.shape
(2708, 2708)
>>> dataset[0].x.shape
(2708, 1433)
当在 single mode 下训练GNN时,我们可以使用 SingleLoader,它将从图中提取特征矩阵,并返回一个 tf.data.Dataset 来提供给我们的模型:
1
2
3
4
>>> from spektral.data import SingleLoader
>>> loader = SingleLoader(dataset)
>>> loader.load()
<RepeatDataset shapes: (((2708, 1433), (2708, 2708)), (2708, 7)), types: ((tf.float32, tf.int64), tf.int32)>
Disjoint mode
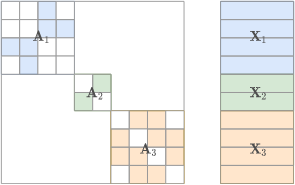
在 disjoint mode 下,我们将一组图表示为单个图,即它们的 “disjoint union”,其中:
A是一个稀疏分块对角矩阵,其中每个分块是第i个图的邻接矩阵a_i。X通过将节点属性x_i堆叠得到。E通过边e_i堆叠得到。
三个矩阵的形状与单模态相同,但 nodes 是图集合中所有节点的累计数量。类似地,边特征以稀疏COOrdinate format 和相对于每个图的行主排序表示(参见入门教程), edges 表示 disjoint union 的边的累计数量。
为了跟踪 disjoint union 中的不同图,我们使用了一个由从零开始的索引 I 组成的额外数组来标识哪个节点属于哪个图。例如: 如果节点8属于第三个图,则 I[8] == 2。在上面的例子中,蓝色代表0,绿色代表1,橙色代表2。
在卷积层中,disjoint mode 与 single mode 是不可区分的,因为不可能在图的 disjoint components 之间交换消息,所以 I 不需要计算输出。
另一方面,池化层要求 I 知道哪些节点可以被池化在一起。
让我们加载一个包含许多小图的数据集,看看前三个
1
2
3
4
5
6
7
8
9
10
11
12
13
>>> from spektral.datasets import TUDataset
>>> dataset = TUDataset('PROTEINS')
Successfully loaded PROTEINS.
>>> dataset = dataset[:3]
>>> dataset[0]
Graph(n_nodes=42, n_node_features=4, n_edge_features=None, n_labels=2)
>>> dataset[1]
Graph(n_nodes=27, n_node_features=4, n_edge_features=None, n_labels=2)
>>> dataset[2]
Graph(n_nodes=10, n_node_features=4, n_edge_features=None, n_labels=2)
要以 disjoint mode 创建 batches,可以使用 DisjointLoader:
1
2
3
4
5
6
7
8
9
10
11
>>> batch = loader.__next__()
>>> inputs, target = batch
>>> x, a, i = inputs
>>> x.shape
(79, 4) # 79 == 42 + 27 + 10
>>> a.shape
(79, 79)
>>> i.shape
(79, )
注意,因为我们的数据集中没有边属性,所以加载器没有创建 E 矩阵。
Batch mode
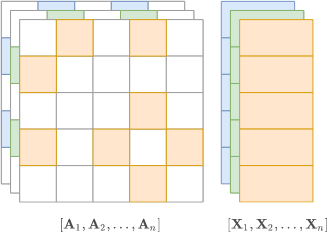
在批处理模式中,图被零填充,以便它们适合形状 [batch, N,…] 的张量。由于 Scipy 和 TensorFlow 普遍缺乏对稀疏高阶张量的支持,所以 X、A 和 E 将是密集张量:
A的形状为[batch, nodes, nodes]X的形状为[batch, nodes, n_feat]E的形状为[batch, nodes, nodes, e_feat](注意现在它是 dense/np.array格式, 不存在边的属性都是零)。
如果图的节点数量是可变的,那么 nodes 的大小就是批中最大的图的大小。
如果您不想用零填充图形或处理密集输入,那么最好使用 disjoint mode 。然而,请注意一些 pooling 层,如 DiffPool 和 MinCutPool 只能在 batch mode 下工作。
让我们重新使用上面示例中的数据集。我们可以使用 BatchLoader,如下所示:
1
2
3
4
5
6
7
8
9
>>> from spektral.data import BatchLoader
>>> loader = BatchLoader(dataset, batch_size=3)
>>> inputs, target = loader.__next__()
>>> inputs[0].shape
(3, 42, 4)
>>> inputs[1].shape
(3, 42, 42)
在本例中, loader 只创建了两个输入,因为我们不需要索引 I。还要注意, batch 被填充了,因此所有图都有42个节点,这是三个图中最大的一个。
BatchLoader 单独对 batch 中每个样本进行零填充,这样我们就不会浪费内存。如果您希望消除填充每个 batch 的开销,可以使用 PackedBatchLoader,它将在生成 batch 之前预填充所有图。当然,这意味着所有图的节点数量与数据集中最大的图的节点数量相同(不仅仅是 batch)。
Mixed mode
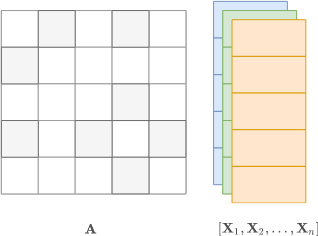
在 mixed mode 中,我们使用单个图来支持不同的节点属性(有时也称为 “graph signals”)。
在这个例子中,我们有这个:
A是形状[nodes,nodes]的矩阵X是batch mode的张量, 形状为[batch, nodes, n_feat]E是[batch, edges, e_feat], 我们再次表示每个边特征矩阵E[b],对于b = 0,…,batch - 1,以稀疏格式。
注意,由于所有图的节点和边都是相同的,我们在高阶张量中堆叠了 x_i 和 e_i ,类似于 batch mode。
mixed mode 数据集的一个例子是 MNIST 随机网格(Defferrard等人,2016)。
1
2
3
4
>>> from spektral.datasets import MNIST
>>> dataset = MNIST()
>>> dataset
MNIST(n_graphs=70000)
mixed-mode 数据集有一个特殊的 a 的属性, 其存储了邻接矩阵, 有的数据集的图仅由 node/edge 特征组成。
1
2
3
4
5
6
7
8
9
>>>dataset.a
<784x784 sparse matrix of type '<class 'numpy.float64'>'
with 6396 stored elements in Compressed Sparse Row format>
>>> dataset[0]
Graph(n_nodes=784, n_node_features=1, n_edge_features=None, n_labels=1)
>>>dataset[0].a
# None
我们可以使用 MixedLoader 来处理数据集中的图之间的邻接矩阵共享
1
2
3
4
5
6
7
8
9
>>> from spektral.data import MixedLoader
>>> loader = MixedLoader(dataset, batch_size=3)
>>> inputs, target = loader.__next__()
>>> inputs[0].shape
(3, 784, 1)
>>> inputs[1].shape # Only one adjacency matrix
(784, 784)
Mixed mode 比其他三种模式需要更多的工作。特别是,不能使用 loader.load() 在这种模式下训练模型。
-
Previous
【深度学习】Spektral Creating a dataset -
Next
【深度学习】DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection