Abstract
现有的光谱重建方法主要集中在设计更深或更宽的卷积神经网络(CNNs)来学习从RGB图像到其高光谱图像(HSI)的端到端映射。
这些基于CNN的方法实现了令人印象深刻的恢复性能,同时显示在捕获远程依赖和自相似性之前的局限性。
为了解决这一问题, 这篇文章提出了一种新的基于 Transformer 的方法,Multi-stage Spectral-wise Transformer (MST ++ ),用于高效的光谱重建。
特别地,这篇文章采用了基于 HSI 空间稀疏而光谱自相似特性的 Spectral-wise Multi-head Self-Attention (S-MSA) 组成基本单元—— Spectral-wise Attention Block(SAB)。
然后,SABs构建 Single-stage Spectral-wise Transformer (SST),利用 u 形结构提取多分辨率上下文信息。
最后,MST++ 由多个 SST 级联,从粗到细逐步提高重建质量。
综合实验表明,MST++ 明显优于其他先进的方法。在NTIRE 2022光谱重建挑战中,该方法获得了第一名。
Introduction
解决该问题一种方法是发展一种快照压缩成像(SCI)系统和计算重构算法从 2D 观测恢复 3D HSI 立方体。这些方法依赖于昂贵的硬件设备。为了降低成本,提出了一种基于RGB相机的光谱重建算法,该算法可以对给定的RGB图像进行光谱重建。
传统的SR方法主要基于稀疏编码或相对较浅的学习模型。然而,这些基于模型的方法表征能力有限且泛化能力差。近年来,随着深度学习的发展,SR取得了显著的进步。利用深度卷积神经网络(CNNs)学习RGB图像到HSI立方体的端到端映射函数。尽管已经取得了令人印象深刻的性能,这些基于 CNN 的方法在捕获远程依赖性和谱间自相似性方面显示出局限性。
近年来,自然语言处理 (natural language processing, NLP) 模型 Transformer 被应用于计算机视觉,并取得了很大的成功。直接应用 Transformer 到 SR 有两个主要问题:
1) 全局和局部 Transformer 捕获空间区域之间的交互。 然而 HSI 表征是空间稀疏的且具有谱间的高相似性。 2) 标准全局 MSA 的计算复杂度是空间维度的二次方倍,是难以承受的巨大负担
另一方面,基于窗口的局部MSA 在位置特定窗口中只有有限的感受野。
为了解决上述限制,这篇文章提出了第一个基于 Transformer 的框架,Multi-stage Spectral-wise Transformer (MST++ ),用于从RGB图像高效的光谱重建。值得注意的是,MST++ 是基于之前的工作MST,它是为光谱压缩成像恢复定制的。首先,注意到HSI信号在空间上是稀疏的,而在光谱上是自相似的。基于这一特性,采用 Spectral-wise Multi-head Self-attention (S-MSA)组成基本单元,即 Spectral-wise Attention Block(SAB)。S-MSA将每个 spectral feature map 作为 token,沿 spectral dimension 计算自注意力。其次,SABs 构建了 Single-stage Spectral-wise Transformer (SST),该 Transformer 利用 u 形结构提取多分辨率光谱背景信息,这对HSI恢复至关重要。最后,MST++ 由多个 SST 级联,开发了一个多阶段学习方案,从粗到细逐步提高重建质量,显著提高了性能。
这项工作的贡献点如下:
- 为 SR 提出了一个新的框架,MST++ 。这可能是探索Transformer 在这项任务中的潜力的第一次尝试。
- 在 SR 任务上验证了一系列自然图像恢复模型。针对这些问题,提出了一种Top-K多模型集成策略来改进 SR 表现。
- 定量和定性实验表明,MST++ 在需要更少的参数和 FLOPS 时显著优于SOTA方法。
Related Work
2.1 Hyperspectral Image Aquisition
传统的图像采集系统通常采用分光计沿空间或光谱维度扫描场景。用于捕获 HSI 的 scanners 主要有三种: whiskbroom scannner、pushroom scanner 和 band sequential scanner。几十年来,这些扫描仪已广泛应用于探测、遥感、医学成像和环境监测。例如, pushbroom scanner 和 whiskbroom scanner 被用于卫星遥感。但由于扫描过程耗时较长,不适合用于动态场景的测量。此外,成像设备通常体积太大,无法插在便携式平台上。为了解决这些限制,研究人员开发了 SCI 系统来捕获HSI,其中3D HSI立方体被压缩成单一的2D measurement。在这些SCI系统中,编码孔径快照光谱成像(CASSI) 脱颖而出,形成了一个很有前景的研究方向。尽管如此,到目前为止,SCI系统对于消费级的使用仍然是非常昂贵的。即使是低成本的SCI系统也经常在1万到10万美元之间。
2.2. Spectral Reconstruction from RGB
传统的SR方法主要基于手工制作的高光谱先验。例如,Paramar等提出了一种用于HSI重构的数据稀疏性扩展方法。Arad等人提出了一种稀疏编码方法,该方法创建了HSI信号及其RGB投影的字典。Aeschbacher等人使用一个相对较浅的学习模型从指定光谱先验学习以填满光谱拆分辨率。然而,这些基于模型的方法表示能力有限,泛化能力较差。
最近,受深度学习在自然图像恢复中的巨大成功的启发,CNN被用来学习从RGB到HSI的底层映射函数。例如,Xiong等提出了一种统一的HSCNN框架,用于从RGB图像和压缩 measurement 重建HSI。Shi等人利用自适应残差块构建了用于SR的深度残差网络HSCNN-R。Zhang等人定制了一个 pixel-aware 的深度函数混合网络,用于建模 rgb-hsi 映射。这些基于 CNN 的 SR 方法取得了令人印象深刻的结果,但在捕获非局部自相似性和长期相互依赖方面存在局限性。
2.3. Vision Transformer
近年来,Transformer 被引入到计算机视觉中,并因其在捕获空间区域之间的远程相关性方面的优势而受到广泛的欢迎。Caiet al 提出了第一个基于 Transformer 的端到端框架MST,用于从压缩测量数据重建HSI。Lin等人将 HSI 稀疏性嵌入到 Transformer 中,建立了光谱压缩成像的粗到细学习方案。之前的工作 Uformer 采用Swin Transformer 块构建的 U 型结构进行自然图像恢复。
Method
3.1. Network Architecture
图2(a)描述了提出的 Multi-stage Spectral-wise Transformer(MST++ ),它由 $N_s$ 个级联的 Single-stage Spectral-wise Transformers (SSTs)组成。MST++ 以RGB图像作为输入,并重建其HSI对应的图像。利用 long identity mapping 简化训练过程。图2 (b)显示了由encoder、bottleneck 和 decoder 组成的 U-shaped SST。embedding 和 mapping 块是单个 conv 3x3层。编码器中的特征映射依次经历一个下采样操作(一个 strided conv4x4 层)、N_1个 Spectral-wise Attention Blocks (SABs)、一个下采样操作和 N_2 个SABs。Bottleneck 由 N_3 个 SABs 组成。解码器采用对称的结构。 上采样操作是一个 strided deconv 2x2 层。为了避免下采样过程中的信息丢失,编码器和解码器之间采用跳跃连接。图2 (c)说明了SAB的组成成分,即前馈网络(FFN,如图2 (d)所示)、光谱多头自注意(S-MSA)和两层归一化。S-MSA的细节如图2 (e)所示。
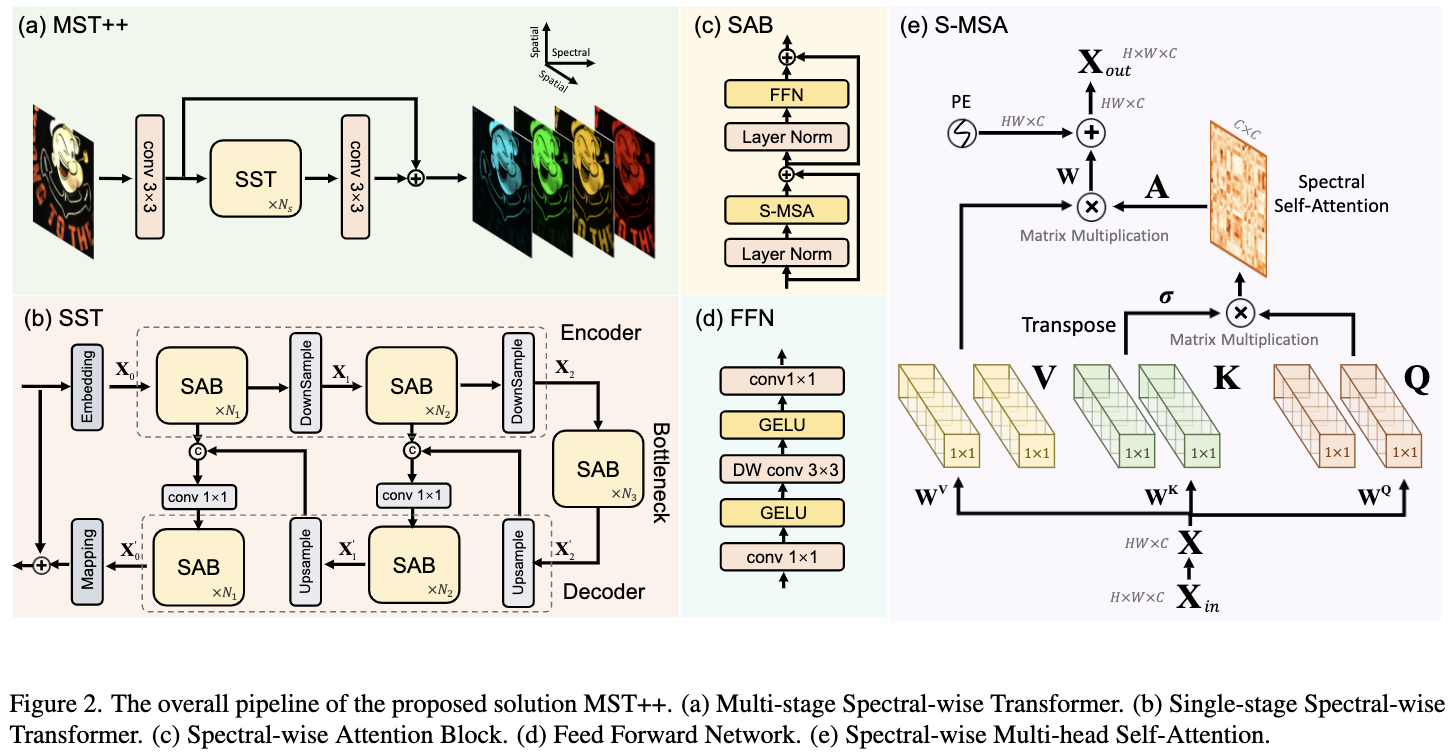
3.2. Spectral-wise Multi-head Self-Attention
与原始的 MSAs 不同, S-MSA 将每个光谱表征视为一个 token 并且计算每个 $head_j$ 的自注意力。
HSI 按波长沿 Spectral Dimention 排序。因此,利用这种嵌入来编码不同光谱通道的位置信息。
3.3. Discussion with Original Transformers
3.3.1 General Paradigm of MSA
在 spatial-wise MSAs 中, n 表示 tokens 的数量。 在 S-MSA 中, n 表示 token 的维度。
3.3.2 Spatial-wise MSA
spatial-wise 的 MSA 将每个像素向量视为一个 token 计算自注意力。
spatial-wise 的 MSA 主要分为两种: global MSA 和 local window-based MSA。
3.3.3 S-MSA
S-MSA 将每个光谱特征图视为 token 并且计算自注意力。
Conclusion
这篇文章提出了第一个基于 Transformer 用于RGB光谱重构的框架,MST++ 。
基于HSI空间稀疏而光谱自相似的特性,采用S-MSA,将每个光谱特征图作为 self-attention 计算的 token,组成基本单元SAB。然后 SABs 组成 SST。最终,MST++ 被几个 SST 级联。
MST++ 采用多阶段学习方案,从粗到细逐步提高重建质量。
定量和定性实验表明,MST++ 在需要更低的内存和计算成本时大大超过了SOTA方法。
令人印象深刻的是,MST++ 赢得了NTIRE 2022年RGB光谱重建挑战的第一名。
-
Previous
【深度学习】Learning Tensor Low-Rank Prior for Hyperspectral Image Reconstruction -
Next
【深度学习】DAUHST: Degradation-Aware Unfolding Half-Shuffle Transformer for Spectral Compressive Imaging