Abstract
局部窗口自注意力在视觉任务中表现突出,但存在感受野有限和建模能力弱的问题。
这主要是因为它在非重叠窗口中执行自注意力,并共享通道维度上的权重。
这篇文章提出 MixFormer 解决该问题。
首先,将局部窗口自注意力与深度卷积并行设计相结合,建跨窗口连接,以扩大感受野。
其次,这篇文章提出跨分支的双向交互,在通道和空间维度上提供互补线索。
这两种设计集成在一起,实现窗口和维度之间的高效特征混合。
MixFormer在图像分类上提供了与 EfficientNet 有竞争力的结果,并显示了比 RegNet 和 Swin Transformer 更好的结果。
Method
The Mixing Block
Mixing Block(图1)在标准的基于窗口的注意力块的基础上增加了两个关键设计:
(1)采用并行设计来结合局部窗口的自注意力和 depth-wise convlution
(2)引入跨分支的双向交互。
它们被提出用来解决感受野有限和局部窗口自注意力弱建模能力的缺点。
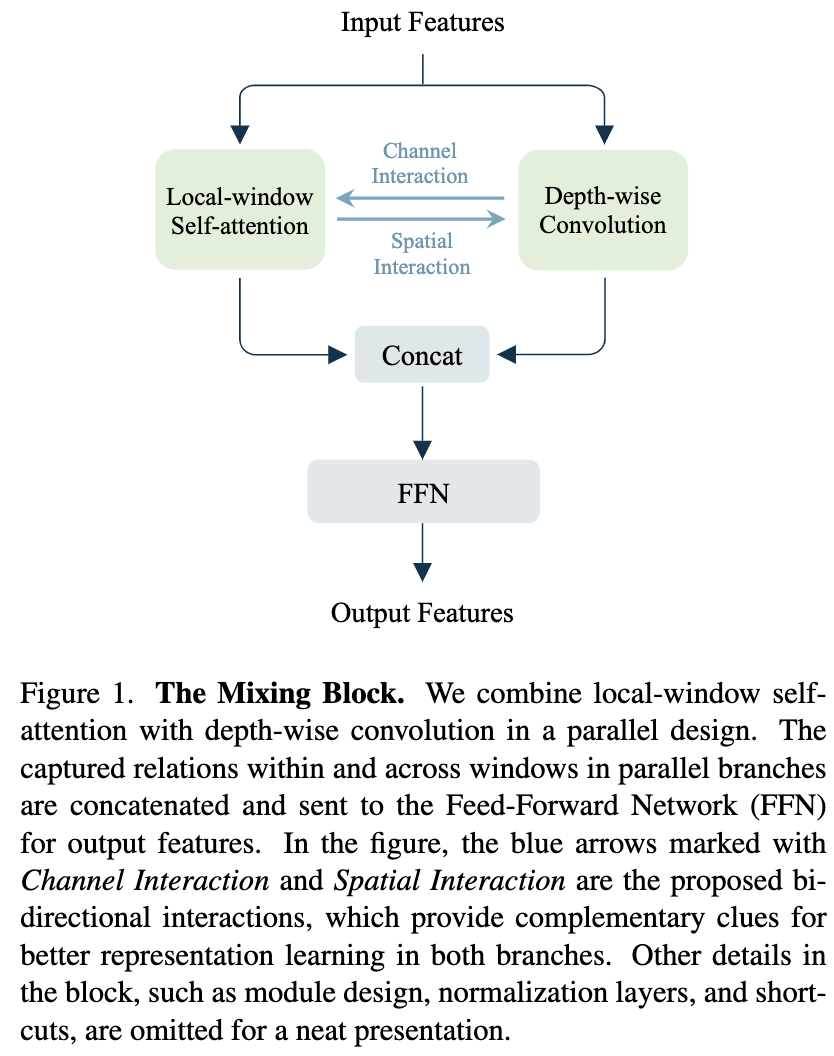
The Parallel Design: 虽然在非重叠窗口内执行自注意力可以提高计算效率,但由于没有跨窗口连接,它会导致感受野有限。考虑到卷积层的设计是为了模拟局部关系,这篇文章选择了 Depth-wise Convolution 作为一个有效的连接窗口的方式。
然后,采用一种适当的方法来结合局部窗口自注意力和DW卷积。这篇文章提出了一种并行设计,通过同时建模窗口内和窗口间的关系来扩大感受野。具体来说,它们使用不同的窗口大小。局部窗口自注意力遵循前人的研究采用7 x 7窗口。而在深度卷积中,考虑到效率,采用了更小的核大小 3 x 3。考虑到他们的 FLOPs 不同, 根据表1中的 FLOPs 比例来调整通道的数量。然后,它们的输出被不同的归一化层归一化,并通过 concat 进行合并。合并后的特征被发送到后续的FFN,跨通道混合学习到的关系,产生最终的输出特征。
并行设计有两个好处: 首先,将局部窗口自注意力与跨分支的DW卷积结合起来,跨窗口建模连接,解决感受野有限的问题。第二,并行设计同时建模窗口内和窗口间的关系,为跨分支的特征交互提供机会,实现更好的特征表示学习。
Bi-directional Interactions: 通常,共享权重限制了共享维度的建模能力。局部窗口自注意力在空间维度上动态计算权重,而在通道维度上共享权重,导致通道维度建模能力弱的问题。
为了增强局部窗口自注意力在通道维度上的建模能力,尝试生成通道动态权重。考虑到 DW 卷积在关注通道的同时在空间维度上共享权重。它可以为局部窗口的自注意力提供补充线索,反之亦然。因此, 提出双向交互来分别为自注意力和DW卷积提升通道和空间维度的建模能力。
平行支路之间的双向交互包括通道交互和空间交互。DW 卷积分支中的信息通过通道交互流向另一个分支,增强了通道维度上的建模能力。同时,空间交互使得空间关系从局部窗口的自注意力分支流向另一个分支。因此,所提出的双向交互为彼此提供了互补的线索。
For the channel interaction: 遵循SE层的设计,如图2所示。通道交互包含一个全局平均池化层,然后是两个连续的1x1个卷积层,它们之间的归一化(BN)和激活(GELU)。最后,在通道维度上使用sigmoid来生成注意力。虽然通道交互与SE层具有相同的设计,但它们在两个方面有所不同:
(1)注意力模块的输入不同。通道交互的输入来自另一个并行分支,而SE层在同一个分支中执行。
(2)只将通道交互作用应用于局部窗口自注意力的 value,而不是像SE层那样将其应用于模块的输出。
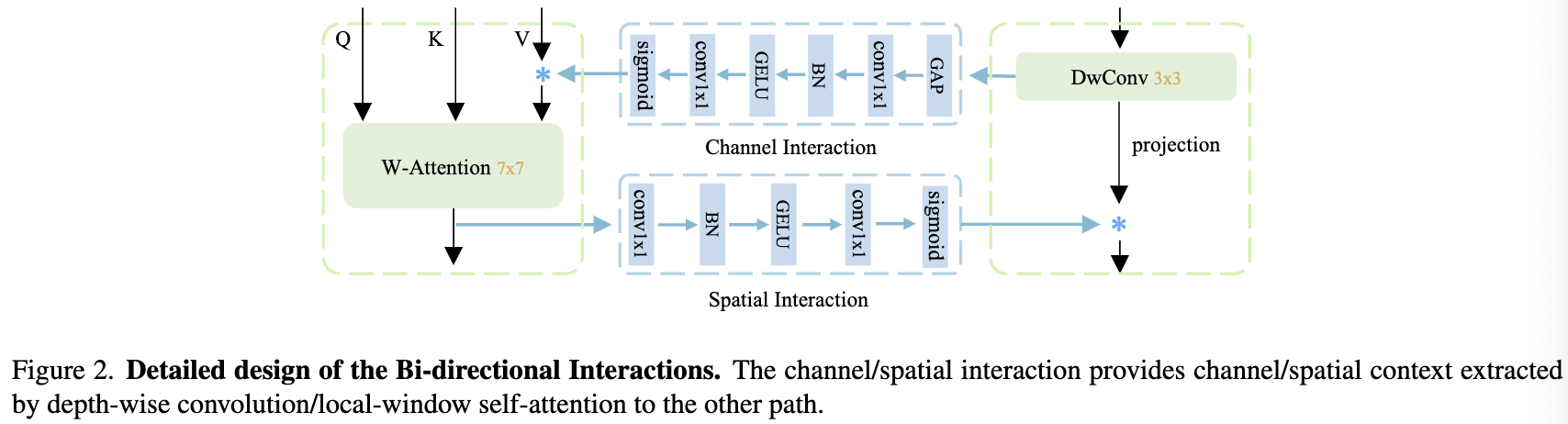 For the spatial interaction: 对于空间交互,也采用了一种简单的设计,即由两个带有 BN 和GELU的 1x1 卷积层组成。这两层将通道的数量减少到一。最后,利用sigmoid层生成空间注意力。和通道交互一样, 空间注意力有另一个分支生成, 其使用局部窗口自注意力模块。它的核大小 (7x7) 比 depth-wise 3x3 卷积更大,并且侧重于空间维度,这为 depth-wise convolution 分支提供了强有力的空间线索。
For the spatial interaction: 对于空间交互,也采用了一种简单的设计,即由两个带有 BN 和GELU的 1x1 卷积层组成。这两层将通道的数量减少到一。最后,利用sigmoid层生成空间注意力。和通道交互一样, 空间注意力有另一个分支生成, 其使用局部窗口自注意力模块。它的核大小 (7x7) 比 depth-wise 3x3 卷积更大,并且侧重于空间维度,这为 depth-wise convolution 分支提供了强有力的空间线索。
The Mixing Block 由于上述两种设计,减轻了局部窗口自注意力的两个核心问题。将它们集成为一个新的 Transformer Block,其可以公式化为如下:
\[\hat X^{l+1} = MIX(LN(X^l), W-MSA, CONV) + X^l \tag{1} \\ \hat X^{l+1} = FFN(LN(\hat X^{l+1}))) + \hat X^{l+1}\]MIX 表示得到 W-MSA 分支和 CONV(DW卷积) 分支混合后的特征。 MIX函数首先通过两个线性投影层和两个规范化层将输入特征投影到并行分支上。然后按照图1和图2所示的步骤混合这些特征。对于FFN, 遵循之前的工作,这是一个MLP,由两个线性层组成,其中一个GELU在它们之间。
MixFormer
Overall Architecture. 在 Block 基础上,设计了一种具有金字塔特征映射的高效通用视觉 Transformer MixFormer。MixFormer是一种混合视觉 Transformer,它在 stem 层和下采样层中都使用了卷积层。此外, 在 stages 的最后引入了投影层。投影层将特征通道增加到1280个,线性层之后是激活层,目的是在分类头之前的通道中保留更多的细节。它具有较高的分类性能,尤其适用于较小的模型。同样的设计可以在以前的高效网络中找到,如 MobileNets 和 EfficeintNets 。
Architecture Variants 将每个阶段的 blocks 堆叠,并格式化不同大小的几个模型,其计算复杂度从0.7G (B1)到3.6 G(B4)。
Conclusion
这篇文章提出 MixFormer 作为一种高效的通用视觉 Transformer。
为了解决基于 windows 的 Vision Transformer 中的问题,寻求缓解有限的感受野和通道维度上薄弱的建模能力。
MixFormer 在不移动或变换窗口的情况下有效地扩大了感受野,这要归功于结合局部窗口和深度卷积的并行设计。
这种双向交互提高了局部窗口自注意力和深度卷积在通道和空间维度上的建模能力。
大量实验表明,MixFormer在图像分类和各种下游视觉任务方面优于其他方法。
-
Previous
【深度学习】KAIST:High-quality hyperspectral reconstruction using a spectral prior -
Next
【Research & Writing】draw.io Tutorial - Exerciese 1:添加 draw.io diagram 到 Confluence page