Abstract
尽管近年来图像恢复领域取得了长足的进步,但目前最先进的SOTA方法的系统复杂性也在不断增加,这可能会阻碍方法的方便分析和比较。
这篇文章提出了一个简单的基线,它超过了SOTA方法,并在计算上是有效的。
为了进一步简化基线,这篇文章揭示了非线性激活函数,如Sigmoid, ReLU, GELU, Softmax等是不必要的:它们可以用乘法或删除来替代。
因此,从基线推导出一个 Nonlinear Activation Free 网络,即NAFNet。
SOTA结果是在各种具有挑战性的基准上实现的,例如GoPro上33.69 dB PSNR(用于图像去模糊),仅以8.4%的计算成本超过了之前的SOTA 0.38 dB;在SIDD上40.30 dB的PSNR(用于图像去噪),超过了之前的SOTA 0.28 dB,计算成本不到它的一半。
Introduction
随着深度学习的发展,图像恢复方法的性能显著提高。
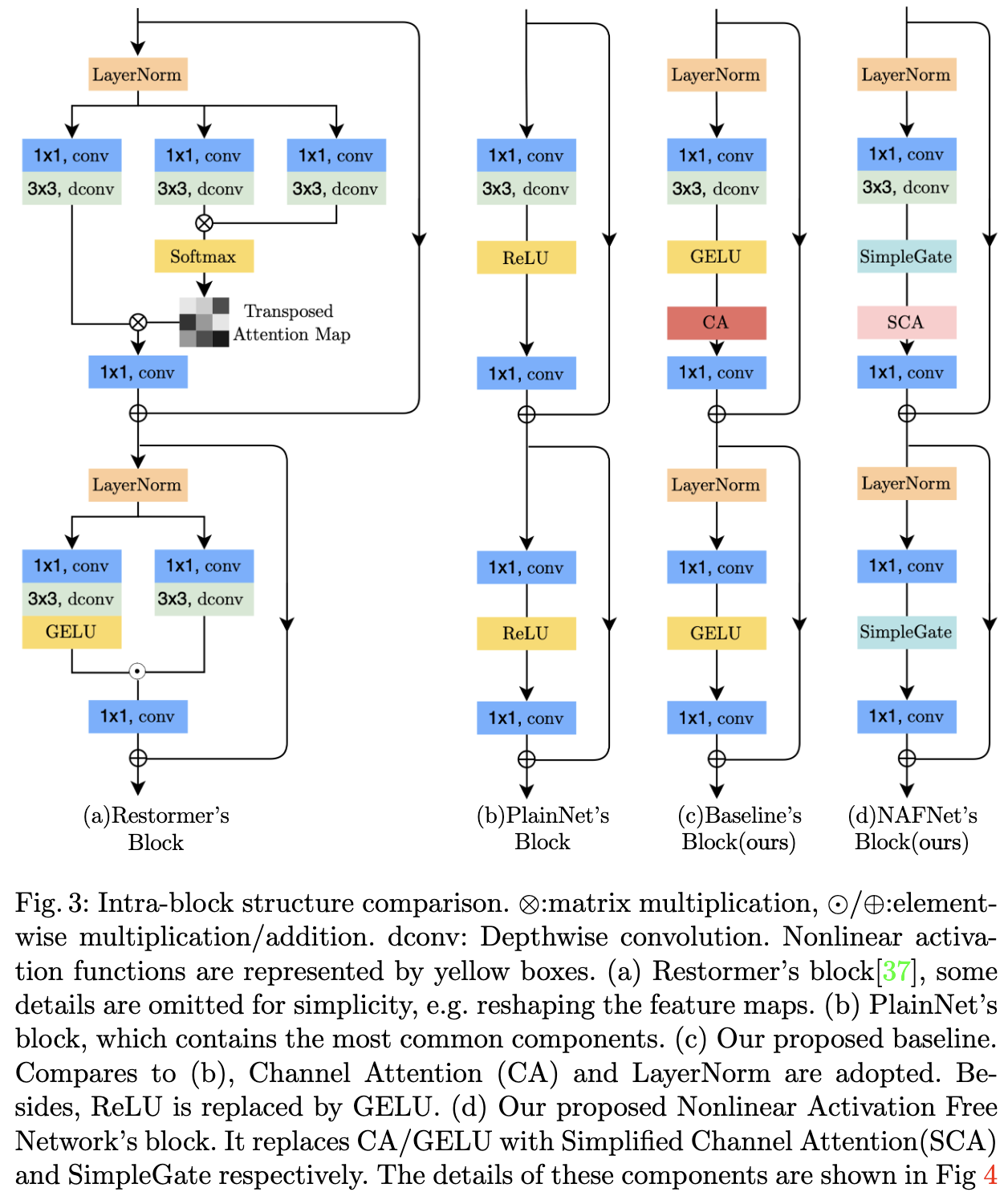
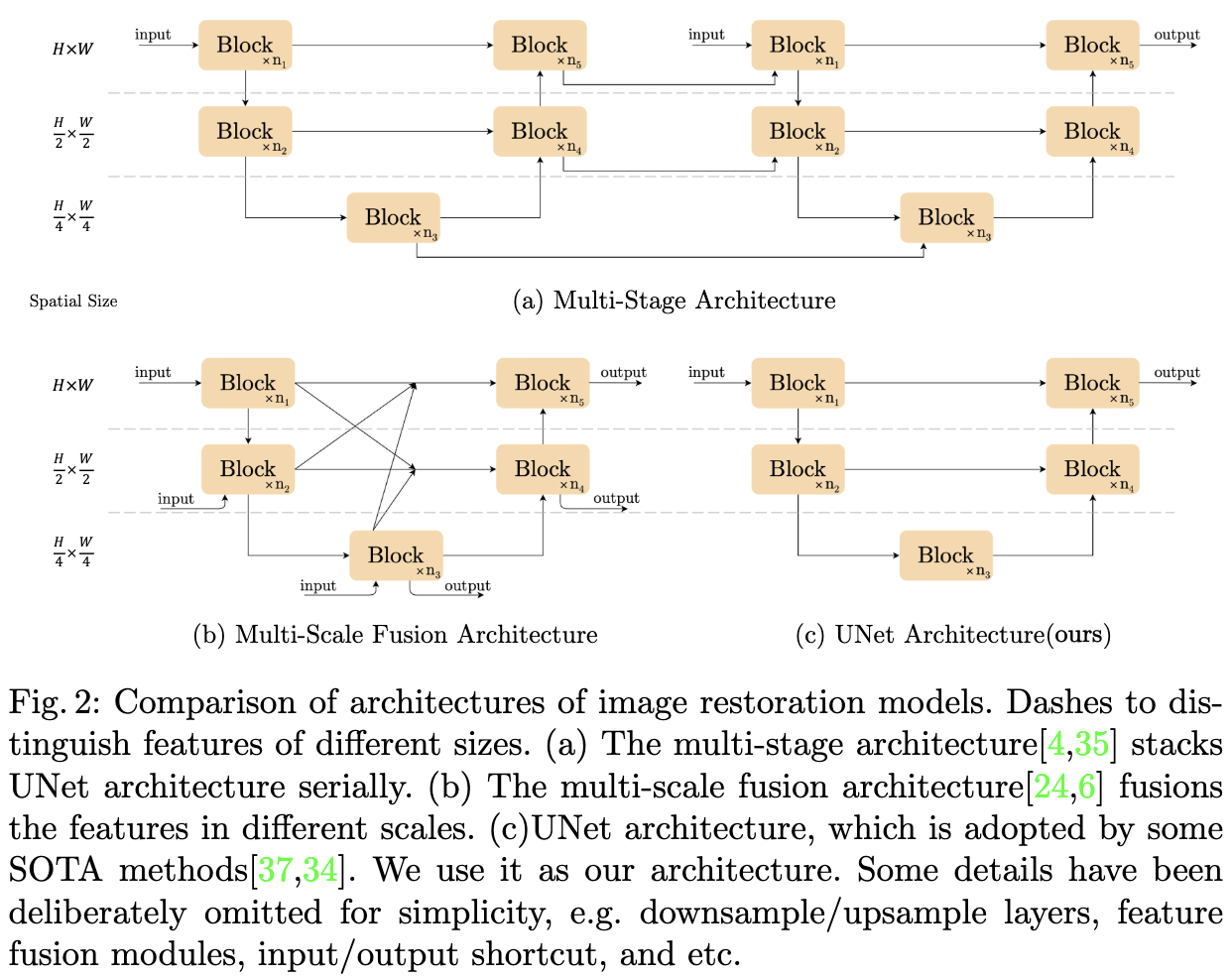
这些方法虽然性能良好,但系统复杂度较高。为了更清晰地讨论,将系统复杂度分解为两个部分: inter-block 复杂度和 intra-block 复杂度。首先,inter-block 复杂度,如图2所示。[6,24]引入了不同大小的特征图之间的连接。[4,35]是多阶段网络,后一阶段对前一阶段的结果进行细化。第二,inter-block 复杂度,即块内部的各种设计选择。例如[37]中的Multi-Dconv Head Transposed 注意力模块和 Gated Dconv Feed-Forward 网络(如图3a所示),[21]中的Swin Transformer 块,[4] 中的 HINBlock等等。
基于上述事实,一个自然的问题出现了:具有低 inter 和 intra 复杂度的网络是否可能实现SOTA性能。为了实现第一个条件(低 inter-block 复杂度),这篇文章采用单级UNet作为体系结构(遵循一些SOTA方法[37,34]),重点关注第二个条件。为此,我们从一个包含最常见组件的 plain block 开始,即 convolution、ReLU 和 shortcut[13]。对于plain block, 我们添加替换掉 SOTA 的组件, 并且验证该组件带来了多少性能的提升。通过广泛的消融研究,提出了一个简单的基线,如图3c所示,它超过了SOTA方法,并且计算效率很高。包含 GELU 和 通道注意力模块(CA) 的基线可以进一步简化: 揭示了基线中的 GELU 可以被视为门控线性单元(GLU)的特殊情况,由此实验证明了它可以被一个简单的门代替,即特征图的 element-wise product。此外,还揭示了CA与GLU在形式上的相似性,并且可以去除CA中的非线性激活函数。总之,简单的基线可以进一步简化为 nonlinear activation-free 网络,即NAFNet。大量的定量实验证明了所提出的基线的有效性。
 这篇文章的贡献总结如下:
这篇文章的贡献总结如下:
- 通过分解SOTA方法并提取它们的基本组件,形成了一个系统复杂度较低的基线(如图3c),它可以超过以前的SOTA方法,并具有较低的计算成本
- 通过揭示门控线性单元到通道注意力(Channel Attention to Gated Linear Unit)之间的联系,通过移除或替换非线性激活函数(如Sigmoid、ReLU和GELU)进一步简化基线,并提出一个 nonlinear activation-free 网络,即NAFNet。
Related Works
Image Restoration
图像恢复任务的目的是将退化的图像(如有噪声、模糊)恢复为干净的图像。最近,基于深度学习的方法[4,35,37,34,5,6,30,7,24]在这些任务上实现了SOTA结果,并且大多数方法可以被视为经典解UNet[28]的变体。它通过跳跃连接将 block 堆叠成 u 型结构。这些变体带来了性能提升,同时也带来了系统复杂度,这里将复杂度大致分为块间复杂度和块内复杂度。
Inter-block Complexity [35,4]是多阶段网络,即后一阶段对前一阶段的结果进行细化,每一阶段都是一个u型结构。这种设计基于这样的假设:将困难的图像恢复任务分解为多个子任务有助于提高性能。不同的是,[6,24]采用单阶段设计,获得竞争性结果,但引入了各种大小特征图之间的复杂连接。其他SOTA方法,如[37,34]保持了单级UNet的简单结构,但它们引入了块内复杂度,这一点将在下文中讨论。
Intra-block Complexity 有许多不同的 inter-block 的设计方案,我们在这里挑选一些例子。[37]通过通道注意力映射而不是空间注意力映射来降低自注意力[32]的内存和时间复杂度。前馈网络采用门控线性单元[9]和 depth-wise 卷积。[34]引入了基于windows的多头自注意力,类似于[21]。 此外,在模块中引入局部增强前馈网络,在前馈网络中加入depthwise 卷积,增强了局部信息捕获能力。不同的是,这篇文章揭示增加系统复杂性并不是提高性能的唯一方法:SOTA性能可以通过一个简单的基线来实现。
Gated Linear Units
门控线性单元9可以通过两个线性变换层的单元生成来解释,其中一个线性变换层是被非线性激活的。GLU及其变体已经在NLP中验证了其有效性[29,9,8],在计算机视觉中也有发展的趋势[30,37,16,19]。这篇文章揭示了GLU带来的 non-trivial 的改进。与[29]不同的是,去掉了GLU中的非线性激活函数,但性能没有下降。此外,基于无非线性激活的GLU本身包含非线性(由于两个线性变换的乘积产生了非线性)的事实,基线可以通过用两个特征映射的乘法替换非线性激活函数来简化。
Build A Simple Baseline
Architecture
为了降低块间复杂度,采用了经典的单级u型结构,带有跳跃连接,如图2c所示[37,34]。
A Plain Block
神经网络是由块堆叠起来的。我们已经确定了上述区块的堆叠方式(即堆叠在一个UNet架构中),但是块的内部结构如何设计仍然是一个问题。我们从一个普通的块开始,它包含了最常见的组件,例如convolution, ReLU, and shortcut[13],这些组件的排列顺序如下[12,21],如图3a所示。使用卷积网络而不是 Transformer 是基于以下考虑。首先,尽管 Transformer 在计算机视觉中表现出良好的性能,但一些作品[12,22]声称 Transformer 对于实现SOTA结果可能不是必需的。其次,depthwise 卷积比自注意力[32]机制更简单。第三,这篇文章不打算讨论 Transformer 和 卷积神经网络的优点和缺点,只是提供一个简单的基线。
Normalization
归一化在高级计算机视觉任务中被广泛采用,在低级视觉中也有流行趋势。虽然[25]放弃了Batch Normalization[17],因为小批量可能会带来不稳定的统计信息[36],但[4]重新引入了Instance Normalization[31],避免了小批量问题。但是,[4]表明添加实例规范化并不总是带来性能提高,需要手动调优。不同的是,在 Transformer 的繁荣下,越来越多的方法使用层归一化[2],包括SOTA方法[30,37,34,22,21]。基于这些事实推测层归一化可能对SOTA恢复至关重要,因此将层归一化添加到上面描述的 PlainBlock。即使学习率提高了10倍,这种改变也能使训练变得顺利。综上所述,在 plain block 上加入了层归一化,因为它可以稳定训练过程。
Activation
plain block 中的激活函数 Rectified Linear Unit27在计算机视觉中得到了广泛的应用。然而,在SOTA方法中,有一种用GELU代替ReLU的趋势。在plain block 中使用 GELU 代替ReLU,在保持图像去噪性能的同时对图像去模糊带来 non-trivial 增益。
Attention
考虑到近年来 Transformer 在计算机视觉中的流行,其注意力机制在 Block 内部结构设计中是一个不可回避的话题。原始的的自注意力机制[32],将所有特征线性组合生成目标特征,并以它们之间的相似度加权。因此,每个特征都包含全局信息,但随着特征图的大小增大,其计算复杂度呈二次方倍增大。一些图像恢复任务需要处理高分辨率的数据,这使得传统的自注意力方法不实用。或者,只在固定大小的本地窗口中应用自注意力,以缓解增加计算复杂度的问题。而它缺乏全局信息。我们不采用基于窗口的注意力,因为在 PlainBlock 中深度卷积[12,22]可以很好地捕获局部信息。
不同的是,[37]将空间注意力修改为通道注意力,避免了计算问题,同时在每个特征中保持全局信息。在[37]的启发下,我们意识到原始通道注意力满足计算效率的要求,并将全局信息引入特征图。此外,通道注意力的有效性在图像恢复任务中得到了验证[35,7],因此将通道注意力添加到 PlainBlock 中。
Summary
到目前为止,我们从头构建了一个简单的基线,如表1所示。结构和模块分别如图2c和图3c所示。基线中的每个组件都是 trivial 的,例如层归一化、卷积、GELU和通道注意力。但是,这些微不足道的组件的组合产生了一个强大的基线:它可以超越 SIDD 和 GoPro 数据集上以前的SOTA结果,只需要一小部分的计算成本,正如在图1和表5、6中所示。
Nonlinear Activation Free Network
上面描述的基准简单且具有竞争力,但是是否有可能在确保简单性的同时进一步提高性能? 在不损失性能的情况下,它能更简单吗?我们试图通过从一些SOTA方法中寻找共性来回答这些问题[30,37,19,16]。 我们发现在这些方法中,都采用了门控线性单元9。这表示GLU可能很有前景。
Gated Linear Units 门控线性单元可以表示为:
\(Gate(X, f, g, \sigma) = f(X) \odot \sigma(g(X))\) 其中, $X$ 表示特征图, f 和 g 是非线性变换, $\sigma$ 是非线性激活函数, 如果 Sigmoid, $\odot$ 表示按元素乘积。如上所述,将 GLU 添加到我们的基线可能会提高性能,但块内复杂度也在增加。这不是我们所期望的。为了解决这个问题,我们重新看一下基线中的激活函数, 如 GELU:
\(GELU(x) = x \Phi(x)\) 其中 $\Phi$ 为标准正态分布的累积分布函数。在[14]的基础上,GELU可以逼近和实现:
\[0.5x(1 + \tanh[\sqrt{2/\pi}(x + 0.044715x^3)])\]从等式1 和 等式2 可以看出, GELU 是 GLU 的一种特殊情况, 例如 f, g 是恒等映射, 将 $\sigma$ 看为 $\Phi$。通过相似性,我们从另一个角度推测,GLU可以看作是激活函数的一种推广,它可以代替非线性激活函数。进一步,我们注意到GLU本身包含非线性并且不依赖于$\sigma$:即使去掉 $\sigma$, $Gate(X) = f(X) g(X)$ 包含非线性。在此基础上,提出了一种简单的GLU变体:在通道维度上直接将特征图分成两部分并相乘,如图4c所示,称为SimpleGate。与Eqn.3中GELU的复杂实现相比, SimpleGate 可以通过元素级乘法实现:
\[SimpleGate(X, Y) = X \odot Y\]通过将基线中的GELU替换为提出的SimpleGate,图像去噪(在SIDD[1])和图像去模糊(在GoPro[25]数据集)的性能分别提高0.08 dB (39.85 dB到39.93 dB)和0.41 dB (32.35 dB到32.76 dB)。此时,网络中只剩下少数几种非线性激活:通道注意力模块[15]中的Sigmoid和ReLU,我们将在接下来讨论它的简化。
Simplified Channel Attention 在第3节中,我们将通道注意力[15]引入到 PlainBlock 中,因为它捕获了全局信息,并且它是计算效率高效的。如图4a所示,它首先将空间信息挤压到通道中,然后对其进行多层感知计算通道注意力,并将其用于特征图的权重。
\(CA(X) = X * \sigma(W_2 \max(0, W_1 pool(X)))\) 其中X表示特征映射,pool表示全局平均池化操作,将空间信息聚合为通道。$\sigma$ 是非线性激活函数, Sigmoid, $W_1$, $W_2$ 是全连接层, ReLU 在两个全连接层之间。最后, * 是 channelwise 乘积操作。如果我们将通道注意计算力视为一个函数,记为输入X的 $\Psi$。
\(CA(X) = X * \Psi(X)\) 可以注意到,Eqn. 6与Eqn. 1非常相似。这启发我们把通道注意力看作 GLU 的一个特例,可以像上一节的 GLU 一样简化。通过保留通道注意力的两个最重要的作用,即聚合全局信息和通道信息交互,提出了简化通道注意力。
\[SCA(X) = X * W pool(X)\]Summary: 从第3节中提出的基线开始,我们通过将 GELU 替换为 SimpleGate 和将 Channel Attention 替换为 Simplified Channel Attention 来进一步简化它,而不损失性能。简化后,网络中不存在非线性激活函数(如ReLU、GELU、Sigmoid等)。所以称这个基线 Nonlinear Activation Free 网络,即NAFNet。
Conclusion
通过对SOTA方法的分解,提取出SOTA的基本组成部分,并在PlainNet 上采用。
得到的基线在图像去噪和图像去模糊任务中达到SOTA性能。
通过分析基线揭示了它可以进一步简化:它中的非线性激活函数可以完全替代或删除。
在此基础上提出了一个 nonlinear activation network, NAFNet。
虽然简化了,但它的性能等于或优于基线。
所提出的基线可能有助于研究人员评估他们的想法。
此外,这项工作有可能影响未来的计算机视觉模型设计,因为证明了非线性激活函数不是实现SOTA性能所必需的。
-
Previous
【深度学习】Restormer:Efficient Transformer for High-Resolution Image Restoration -
Next
【深度学习】Twins: Revisiting the Design of Spatial Attention in Vision Transformers