Abstract
给定退化的输入图像,图像恢复旨在恢复丢失的高质量图像内容。
大量的应用需要有效的图像恢复,如计算摄影、监视、自动驾驶汽车和遥感。
近年来,以卷积神经网络(convolutional neural networks, CNNs)为代表的图像恢复技术取得了长足的进步。
广泛使用的基于cnn的方法通常在全分辨率或逐步低分辨率表示上操作。
在前一种情况下,空间细节被保留,但上下文信息不能被精确编码。
在后一种情况下,生成的输出在语义上可靠,但在空间上不那么精确。
这篇文章提出了一种新的架构,其整体目标是通过整个网络保持空间精确的高分辨率表示,并从低分辨率表示中接收互补的上下文信息。
该方法的核心是一个多尺度残差块,包含以下关键元素:
(a)用于提取多尺度特征的并行多分辨率卷积流
(b)跨多分辨率流的信息交换
(c)用于捕获上下文信息的非局部注意力机制
(d)基于注意力的多尺度特征聚合
该方法学习了一套丰富的特征,结合了来自多个尺度的上下文信息,同时保留了高分辨率的空间细节。
在六个真实的图像基准数据集上的广泛实验表明,该方法MIRNet-v2,在各种图像处理任务中取得了最先进的结果,包括去模糊、图像去噪、超分辨率和图像增强。
Proposed Method
MIRNet-v2 的整体结构如图 1 所示。作者首先介绍MIRNet-v2用于图像恢复和增强的总览。然后,作者提供了多尺度残差块的细节,这是该方法的基本构建块,包含几个关键元素:
a. 并行多分辨率卷积流,提取(从精细到粗)语义丰富和(从粗到细)空间精确的特征表示
b. 跨多分辨率流的信息交换
c. 来自不同信息流的基于注意力的特征聚合
d. 残差上下文块提取基于注意的特征。
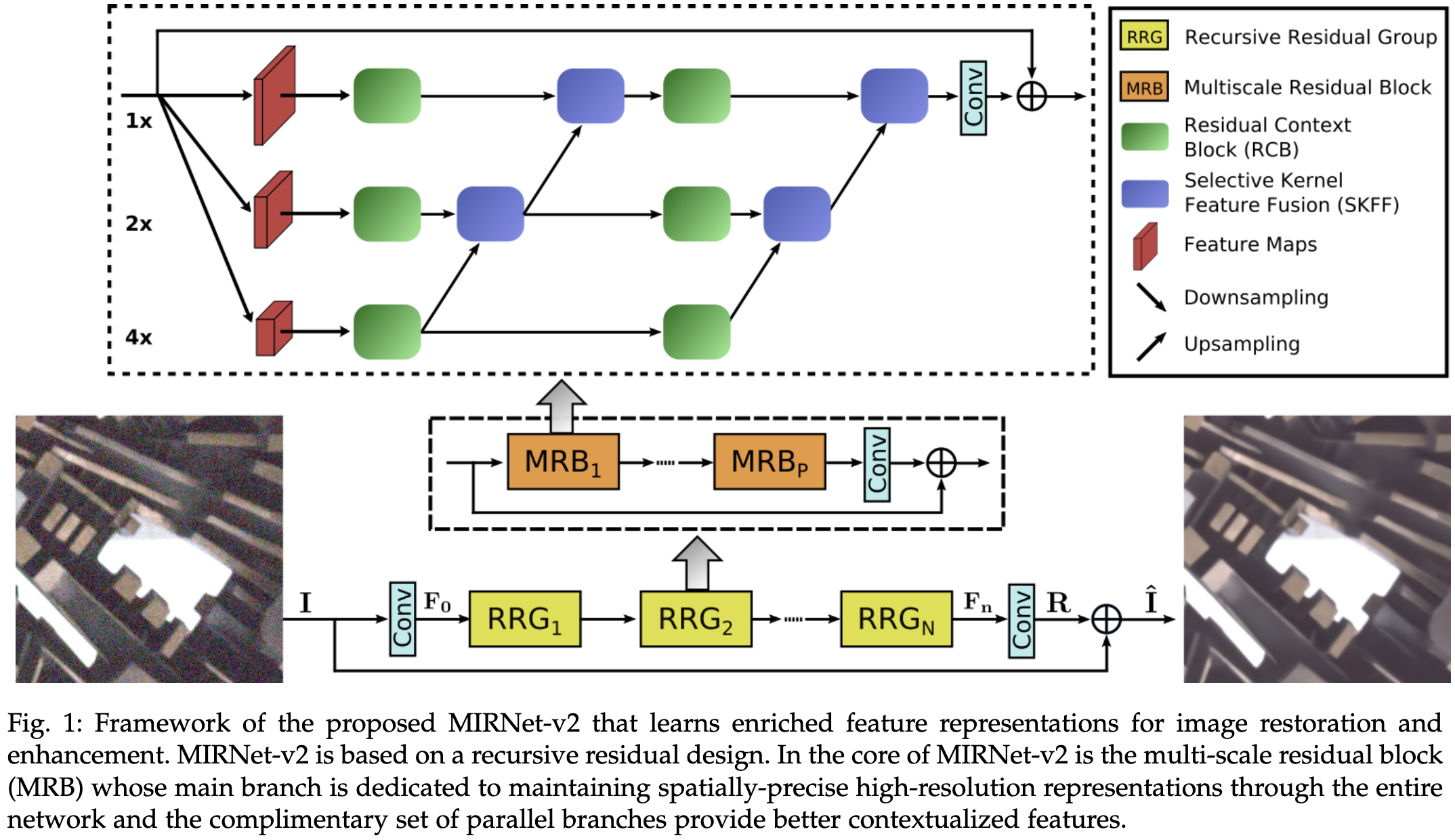
Overall Pipeline. 给定图像 $I \in \mathbb{R}^{H \times W \times 3}$, 首先应用一个卷积提取浅层特征 $F_0 \in \mathbb{R}^{H \times W \times C }$。然后, 特征图 $F_0$ 通过 $N$ 个 recursive residual groups(RRGs), 生成深层特征 $F_n \in \mathbb{R}^{H \times W \times C}$。 每个 RRG 包含几个 multi-scale residual blocks。 然后应用卷积层到深层特征 $F_n$ 得到残差图像 $R \in \mathbb{R}^{H \times W \times 3}$。 最终的复原图像得到: $\hat I = I + R$。 使用 Charbonnier 损失优化网络:
\[L( \hat I, I^* ) = \sqrt{ \| \hat I - I^* \|^2 + \epsilon^2}\]Multi-Scale Residual Block
Selective Kernel Feature Fusion
视觉皮层神经元的一个基本特性是它们能够根据刺激改变感受野[111]。这种自适应调整感受野的机制可以通过多尺度特征生成(在同一层),然后进行特征聚合和选择的方式融入到CNN中。最常用的特性聚合方法包括简单的 concat 或 sum。然而,正如文献[111]所报道的那样,这些选择对网络的表达能力有限。在MRB中,作者引入了一种非线性方法,利用自注意力机制来融合来自不同分辨率的特征。
SKFF 模块执行两个操作来动态调整感受野 - Fuse 和 Select, 如图2所示。fuse 操作通过从多尺度流中结合信息生成全局 feature descriptors。select 操作使用这些 descriptor 重新校准(不同流的)特征图及其聚合。
- Fuse: SKFF接收来自两个并行卷积流的输入,这些卷积流携带不同尺度的信息。首先使用 element-wise 求和来组合这些多尺度特征: $L = L_1 + L_2$。然后在 $L \in \mathbb{R}^{H \times W \times C}$ 的空间维度应用 global average pool(GAP) 计算 channel-wise 的数据 $s \in \mathbb{1 \times 1 \times C}$。然后使用一个 channel-downscaling 卷积层生成一个 compact feature representation $z \in \mathbb{R}^{1 \times 1 \times 4}$, 在所有实验中 $r = \frac{C}{8}$。最后,特征向量 $z$ 通过两个并行 channel-upscaling 卷积层(每个分辨率流一个),并提供两个 feature descriptors $v_1$ 和 $v_2$,每个维度为 $1 \times 1 \times C$。
- Select:这个操作应用 softmax 函数到 $v_1$ 和 $v_2$, 生成注意力激活 $s_1$ 和 $s_2$, 其可以分别自适应地校准多尺度特征。特征校准和聚合的所有过程可以定义为: $U = s_1 · L_1 + s_2 · L_2$。
Conclusion
传统的图像复原或增强流程坚持整个网络全分辨率或者使用编码器-解码器结构。
第一种方法有助于保留精确的空间细节,而后一种方法提供了更好的上下文表示。
然而,这些方法只能满足上述两种需求中的一种,尽管现实世界的图像恢复任务需要在给定的输入样本条件下结合这两种需求。
这项工作中提出了一种新的架构,其主要分支致力于全分辨率处理,而并行分支的互补集提供了更好的上下文特征。
这篇文章提出了新的机制来学习每个分支以及跨多尺度分支的特征之间的关系。
特征融合策略保证了感受野在不牺牲原始特征细节的情况下进行动态调整。
在4个图像复原和增强任务的6个数据集上的大量 SOTA 实验证明了方法的有效性。
-
Previous
【深度学习】GAP-CCoT:Snapshot spectral compressive imaging reconstruction using convolution and contextual Transformer -
Next
【深度学习】MPRNet:Multi-Stage Progressive Image Restoration