Abstract
这篇文章探讨了 Instance Normalization 在低级视觉任务中的作用。
具体地说,这篇文章提出了一种新的块: Half Instance Normalization Block(HIN Block),以提高图像恢复网络的性能。
在HIN Block的基础上,作者设计了一个简单而强大的多级网络HINet,它由两个子网络组成。
在HIN Block的帮助下,HINet在各种图像恢复任务上都超越了最先进的方法(SOTA)。
对于图像去噪,在SIDD数据集上的PSNR分别超过0.11dB和0.28 dB,其 multiplier-accumulator operations(MACs)仅为7.5%和30%,速度分别为6.8x 和 2.9x。
对于图像去模糊,在REDS和GoPro数据集上, 性能相当的情况下, 仅使用22.5% macs, 加速 3.3x。
对于图像去雨,在加速 1.4x 的情况下,对多个数据集的平均结果的PSNR超过了0.3 dB。
使用HINet,赢得了NTIRE 2021图像去模糊挑战- Track2的第一名。JPEG Artifacts,PSNR为29.70。
Approach
HINet
这篇文章提出的半实例规范化网络(HINet)的架构如图2所示。HINet由两个子网络组成,每个子网络是一个U-Net[36]。对于每个阶段的U-Net,我们使用一个 $3 \times 3$ 卷积层来提取初始特征。然后,这些特征被输入到一个编码器-解码器结构,有四个下采样和上采样。使用 kernel 大小为 4 的卷积进行下采样, 使用 kernel 大小为 2 的转置卷积上采样。在编码器部分,设计了半实例规范化块来提取每个尺度上的特征,并在降采样时将特征通道加倍。在解码器部分,使用ResBlocks[15]提取高级特征,并从编码器组件中融合特征,以补偿降采样造成的信息丢失。对于ResBlock,使用负斜率为0.2的LeakyReLU[29],并去除批规范化。最后通过一个 $3\times3$ 卷积得到重建图像的残差输出。
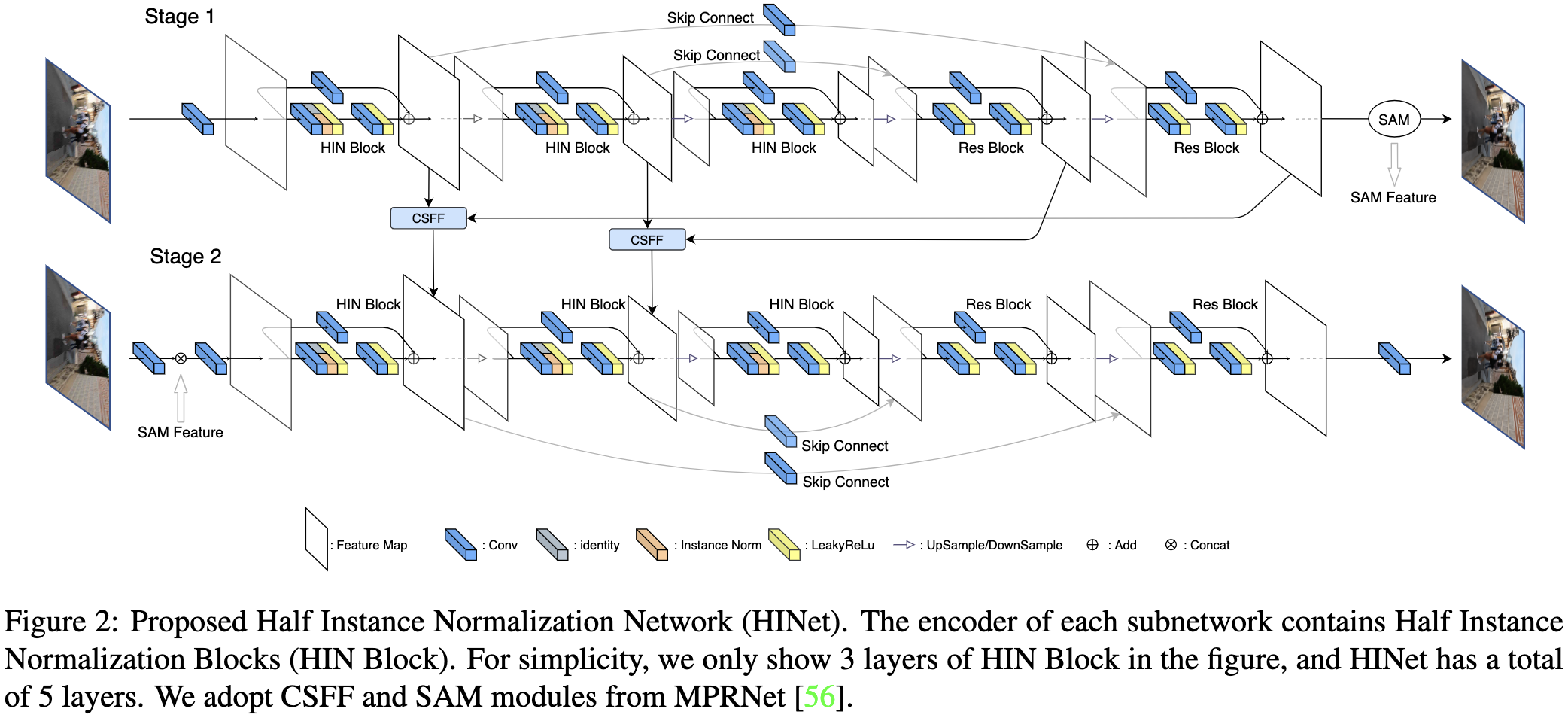
作者使用跨阶段特征融合(CSFF)模块和 supervised attention module(SAM)来连接这两个模块所在的两个子网络。在CSFF模块中,使用 $3 \times 3$ 卷积将特征从一个阶段转换到下一个阶段进行聚合,这有助于丰富下一阶段的多尺度特征。对于SAM,将原模块中的 $1 \times 1$ 卷积替换为 $3 \times 3$ 卷积,并在每个卷积中添加偏置。通过引入SAM,当前阶段有用的特征可以传播到下一阶段,而信息较少的特征则会被 attention mask [55]所抑制。
除了网络结构,作者还使用峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)作为损失函数,即PSNR loss。令 $X_i \in \mathbb{R}^{N \times C \times H \times W}$ 表示子网络的输入 $i$, 其中 $N$ 是数据的批量大小, $C$ 是通道数量, $H$ 和 $W$ 是空间大小。$R_i \in \mathbb{R}^{N \times C \times H \times W}$ 表示子网络 $i$ 的最终预测, $Y \in \mathbb{R}^{N \times C \times H \times W}$ 是每个阶段的真实图像。
\(Loss = - \sum_{i=1}^2 PSNR((R_i + X_i), Y)\)
Half Instance Normalization Block
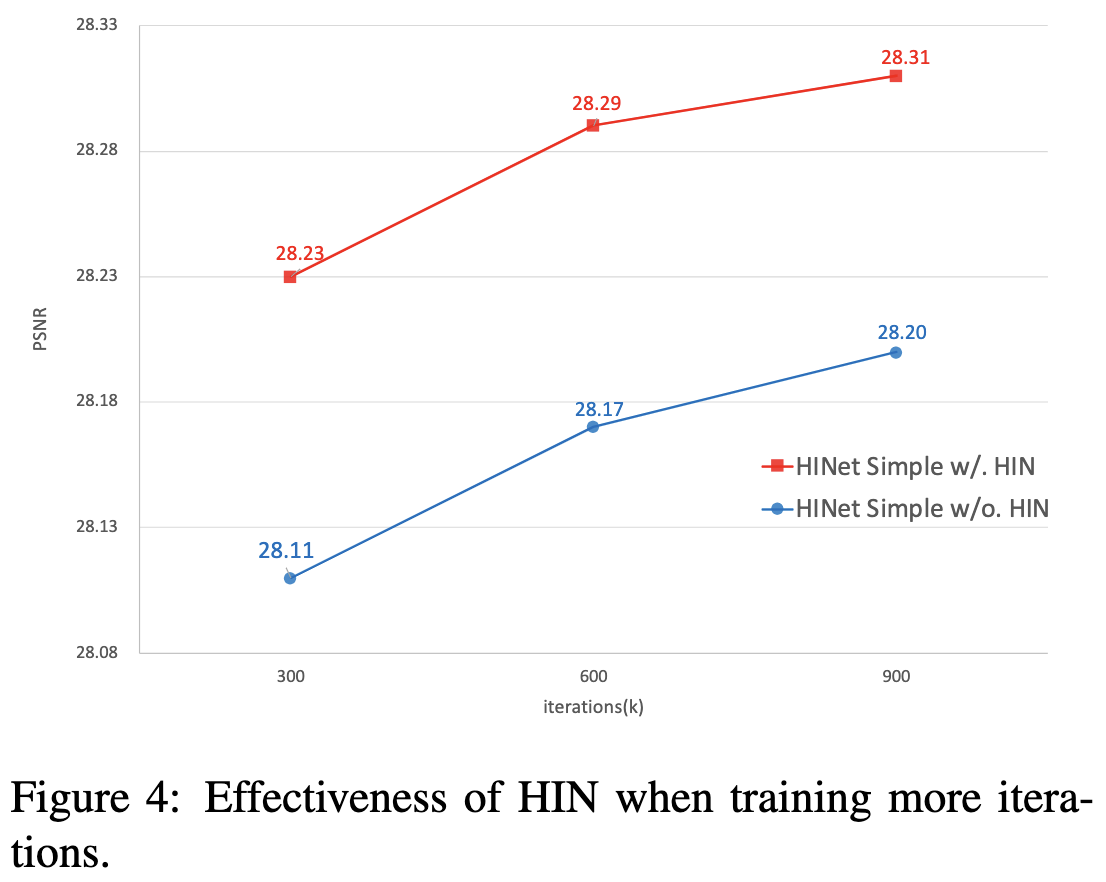
由于小批量的图像小 patch 的方差差异较大,训练和测试[51]的不同,BN[18]在 low-level 任务中不常用[23,26]。实例归一化(Instance Normalization, IN)在训练和推理中保持相同的归一化过程。在不受批维数影响的情况下,IN对特征的均值和方差进行了重新标定,比BN保留了更多的尺度信息。作者使用IN构建半实例规范化块(HIN块)。通过引入HIN块,提高了HINet的建模能力(如图4所示)。此外,IN引入的额外参数和计算开销可以忽略不计。
如图 3a 所示, HIN block 首先对输入特征 $F_{in} \in \mathbb{R}^{C_{in} \times H \times W}$ 使用 $3 \times 3$ 然后 生成的中间特征 $F_{mid} \in \mathbb{C_{out} \times H \times W}$ , 其中 $C_{in} / C_{out}$ 是 HIN block 的输入/输出通道数量。然后, $F_{mid}$ 特征被分为两部分 ($F_{mid_1} / F_{mid_2} \in \mathbb{R}^{C_{out} / 2 \times H \times W}$)。第一部分 $F_{mid_1}$ 被带有可学习仿射参数的 IN 进行归一化,然后与 $F_{mid_2}$ 通道维进行连接。HIN块在一半通道上使用IN,并在另一半通道上保存上下文信息。后续的实验也表明,这种设计对网络的浅层特征更加友好。在 concat 操作之后, 残差特征 $R_{out} \in \mathbb{R}^{C_{out} \times H \times W}$ 通过传入一个 $3 \times 3$ 卷积层和两个 Leaky ReLU 层得到, 如图 3a 所示。最后,HIN block 通过添加具有 shortcut 特征的 $R_{out}$ (通过 $1 \times 1$ 卷积得到)来得到输出 $F_{out}$。
Conclusion
这项工作中在图像恢复任务中重用归一化。
具体地,在残差块中引入实例规范化,并设计了一个有效且高效的块:半实例规范化块(HIN块)。
在HIN块中,对一半的中间特征进行实例归一化,同时保留内容信息。
在HIN Block的基础上,进一步提出了一种多级网络HINet。
在每个阶段之间,使用特征融合和 attention-guided map 跨阶段简化信息流动,增强多尺度特征表达。
所提出的HINet在各种图像恢复任务上超过了SOTA。
-
Previous
【深度学习】MPRNet:Multi-Stage Progressive Image Restoration -
Next
【深度学习】MIMO-UNet:Rethinking Coarse-to-Fine Approach in Single Image Deblurring